







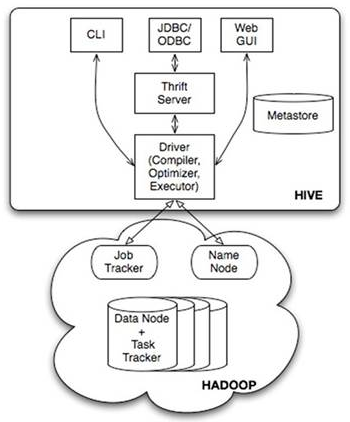
Hive
Hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换成MapReduce任务进行运行。
HQL
数据定义语言DDL
DDL是SQL语言集中对数据库内部的对象结构进行创建、删除和修改等操作语言,数据库对象包括database、table等。DDL的核心语法有CREATE、DROP和ALTER所组成。DDL不涉及表内部数据操作。
建库操作
CREATE DATABASE 数据库名
[COMMENT 注解]
[LOCATION hdfs_路径]
[WITH DBPROPERTIES (property_name=属性配置, ...)]
选择特定的数据库
USE 数据库名
删除数据库,默认RESTRICT仅在数据库为空时才删除,CASCADE能删除带表的数据库
DROP DATABASE 数据库名 [RESTRICT|CASCADE]
建表操作
每个表有一个名字标识,表包含带有数据的记录
CREATE TABLE 表名 (字段名 数据类型 [COMMENT 注解], ...)
[COMMENT 注解]
[ROW FORMAT DELIMITED
fields terminated by 分隔符 --字段之间的分隔符
collection items terminated by 分隔符 --集合元素之间的分隔符
map keys terminated by 分隔符 --Map映射kv之间的分隔符
lines terminated by 分隔符 --行数据之间的分隔符]
数据类型分为原生数据类型和复杂数据类型
原生数据类型有:
- 整型:tinyint、smallint、int、bigint
- 浮点型:float、double
- 布尔:boolean
- 字符串:string
- 时间戳:timestamp
复杂数据类型有: - array<类型>
- map<类型,类型>
- struct<属性名1:类型,属性名2:类型,…>
显示数据库信息
SHOW DATABASES --显示所有数据库
SHOW SCHEMAS
SHOW TABLES [IN 数据库名] --显示当前数据库所有表
DESC FORMATTED 表名 --查询显示一张表的元数据信息
数据操纵语言DML
加载数据
LOAD DATA [LOCAL] INPATH 路径 [OVERWRITE] INTO TABLE 表名
插入数据
INSERT INTO TABLE 表名 VALUES (值1, 值2, ...)
INSERT INTO TABLE 表名
SELECT select_statement FROM from_statement
查询数据
执行顺序:from > where > group > having > order > select
SELECT [ALL|DISTINCT] 字段名1,字段名2,... FROM 表名
[WHERE 布尔表达式]
[GROUP BY 字段名]
[ORDER BY 字段名]
[LIMIT [偏移量,] 行数]
默认值ALL表示不进行去重,DISTINCT会进行数据去重
WHERE 后面的布尔表达式支持:
- 比较运算:=,>,<,>=,<=,!=,<>(不等于)
- 逻辑运算:and,or
- 空值判断:xxx is null
- between:xxx between v1 and v2
- in:xxx in (v1, v2, v3)
聚合操作
- AVG(column):某列的平均值
- COUNT(column):某列的行数
- COUNT(*):被选行数
- MAX(column):某列的最高值
- MIN(column):某列的最低值
- SUM(column):某列的总和
SELECT COUNT([DISTINCT] field_name) AS name_cnt FROM table_name --as 可以给返回数据字段起别名
分组 使用group by 所查找出的字段 必须是group by 后面的字段名 或者 被聚合函数应用的字段
SELECT field_name2, COUNT([DISTINCT] field_name1) AS name_cnt FROM table_name
WHERE 布尔条件
GROUP BY field_name2
HAVING过滤,WHERE关键字无法与聚合函数一起使用,HAVING子句可以筛选分组后的各组数据。
SELECT field_name2, COUNT([DISTINCT] field_name1) AS name_cnt FROM table_name
WHERE 布尔条件
GROUP BY field_name2
HAVING name_cnt > 0
ORDER BY 控制返回结果升序或降序,默认升序
SELECT * FROM table_name ORDER BY field_name [ASC|DESC]
LIMIT 限制SELECT语句返回的行数,接受一个或两个数字参数,必须为非负整数常量
SELECT * FROM table_name LIMIT [offset,]line_num
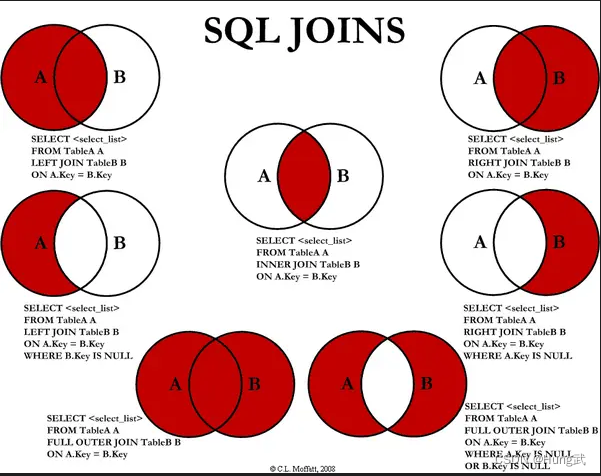
关联查询
最常用的两种join分别是inner join(内连接)和left join(左连接)
table1 [INNER] JOIN table2 [CONDITION]
table1 {LEFT} [OUTER] JOIN table2 CONDITION
内连接只有进行连接的两个表都存在与连接条件相匹配的数据才会保留
SELECT t1.a,t1.b,t2.c
FROM table1 t1 INNER JOIN table2 t2
ON t1.a = t2.a
左连接在连接时以左表的全部数据为准,右表与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null。
SELECT t1.a,t1.b,t2.c
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.a
UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集
UNION 操作符选取不同的值,而UNION ALL允许重复的值
SELECT column_name(s) FROM table_name1
UNION [ALL]
SELECT column_name(s) FROM table_name2
Hive函数
Hive函数分为两大类:内置函数和用户定义函数UDF 官方教程
内置函数
内置函数主要分为:
- 数学函数:round()、rand()
- 日期函数:current_date()、unix_timestamp()、from_unixtime()、datediff()、date_add()、date_sub()
- 字符串函数:length()、reverse()、concat()、concat_ws()、substr()、split()
- 集合函数:size(Map<K.V>)、map_keys(Map<K.V>)、array_contains(Array, value)、sort_array(Array)
- 条件函数:if()、nvl()、case 字段 when 条件1 then 值1 [when 条件2 then 值2 …] [else 值n] end
- 类型转换函数
- 数据脱敏函数
- 其他杂项函数
用户定义函数UDF
用户定义函数根据输入输出行数分为:
- UDF:普通函数,一进一出
- UDAF:聚合函数,多进一出
- UDTF:表生成函数,一进多出
使用UDF
--添加jar包到hive中
add jar hdfs:///apps/resource/udf/udf_jar/master/platform/bigdata-hive-udfs/1.6/bigdata-hive-udfs-1.6-jar-with-dependencies.jar;
--创建临时UDF
CREATE TEMPORARY FUNCTION func_name as 'com.pinduoduo.bigdata.dwarch.udf.MaxPartition';
SELECT field_name
FROM table_name
WHERE field_name2=func_name(parameters)
注意事项
- 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。可以节省读取开销,中间表存储开销和数据整合开销。
- 可以在查询的过程中减少不必要的分区。分区操作和limit操作要注意加上。
- 在使用写有 Join 操作的查询语句时,应该将条目少的表/子查询放在 Join 操作符的左边。左表会被加载进内存,这样可以减少内存溢出的可能。
- 对jobs数比较多的作业运行效率相对比较低,比如即使是很小的表,如果多次关联多次汇总,产生十几个jobs。map reduce作业初始化的时间是比较长的。
- 不怕数据多,就怕数据倾斜
- 对sum,count来说,不存在数据倾斜问题
- 对count(distinct ),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低
Hive SQL 书写优化
- 使用group by 代替count(distinct)
优化前:
select count(distinct name)
from student;
优化后:
select count(*)
from (
select name, count(*)
from student
group by name
);
说明:distinct 在reduce阶段会把所有的任务都分配一个reduce task执行,如果数据量过大会很慢,所以建议先分组然后再count(*)
用group by方式同时统计多个列
select t.a, sum(t.b), count(t.c), count(t.d)
from (
select a, b, null c, null d from some_table
union all
select a, 0 b, c, null d from some_table group by a,c
union all
select a, 0 b, null c, d from some_table group by a,d
) t;
- 使用sort by 和distribute by 代替order by
优化前:
select name,score,age
from student
order by score desc;
优化后:
select name,score,age
from student
distribute by score
sort by age desc;
说明:使用order by 和distinct 类似,在reduce阶段都会把所有的任务集中到有一个reduce task中去就算,如果数据量过大就容易出现跑数时间过长的问题。使用sort by和distribute by后MR会根据情况启动多个reduce来排序,如果不加distribute by 的话map后的数据会随机分配到每个reducer中,如果加上的话会根据指定的分区键来对map后的数据分区,保证每个reducer中的数据是有序的。
- 谓词下推,把where条件前置,提前过滤掉不需要的数据
优化前:
select t1.name,t2.city_name
from t1 left join t2 on t1.city_id=t2.id
where t1.age>=18 and t2.city_name<>'北京';
优化后:
select t1.name,t2.city_name
from (
select city_id, name
from studet
where age>=18
) t1 left join (
select city_name,id
from city
where city_name<>'北京'
);
说明:使用谓词下推可以提前把不需要数据剔除减少join的数据,进而减少执行消耗的时间。
- map join,多表join时小表写在最前面,关联条件满足时尽量各表使用同一键进行关联。
优化前:
select t1.goods_id,t1.price,t2.city_name
from goods t1 left join dim_city t2
on t1.city_id=t2.id;
优化后:
select t2.order_id,t2.price,t1.city_name
from dim_city t1 left join goods t2
on t1.id=t2.city_id;
说明:MR在执行的过程中会默认把第一个表加载到内存中然后逐条跟后面的表匹配,如果第一个表数据量过大加载到内存中就会有OOM的风险,所以在多表关联且明确知道哪个表数据量更小的情况下建议把数据量的表写在最左边。
- 多表join时,key相同会将多个join合并为一个MR job来处理,可使用不同的join条件
select a.event_type,a.event_code,a.event_desc,b.upload_time
from calendar_event_code a inner join (
select event_type,upload_time
from calendar_record_log
where pt_date = 20190225
) b on a.event_type = b.event_type inner join (
select event_type,upload_time
from calendar_record_log_2
where pt_date = 20190225
) c on a.event_type = c.event_type;
若改成a.event_code = c.event_code,就会拆成两个MR job计算。
- 优化SQL处理join数据倾斜
提前过滤空值或无意义值。当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid, a.event_type, b.nickname, b.age
from (
select
(case when uid is null then cast(rand()*-10240 as int) else uid end) as uid,
event_type
from calendar_record_log
where pt_date >= 20190201
) a left outer join (
select uid, nickname, age
from user_info
where status = 4
) b on a.uid = b.uid;
Hive参数
本地模式
set hive.exec.mode.local.auto=true;
hive简单地读取存储目录下的文件,然后输出格式化后的内容到控制台,不会触发MapReduce任务。对于WHERE语句中的过滤条件是分区字段的情况也无需MapReduce过程。
map任务的数是根据这个map_num = MIN(split_num, MAX(default_num, mapred.map.tasks))计算的,也就是说根据分片数和设置的map task的数目的最小值,所以如果想减少mapper数,就适当调高mapred.min.split.size,split数就减少了。如果想增大mapper数,除了降低mapred.min.split.size之外,也可以调高mapred.map.tasks。
mapred.min.split.size;--最小分片大小
mapred.max.split.size;--最大分片大小
mapred.map.tasks;--设置map task任务数
调整reducer数,这是一个有利有害的参数,一般来说增加reducer数可以提高执行速度,但是会增加大量的小文件,小文件过多的话会影响map的执行速度。
mapred.reduce.tasks;--设置reducer的数量
hive.exec.reducers.bytes.per.reducer;--设置每个reducer能处理的最大数据量 默认是1G
hive.exec.reducers.max;--设置每个job最大的reducer的数量
合并小文件
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;--输入阶段合并小文件
hive.merge.mapfiles=true;hive.merge.mapredfiles=true;--输出阶段小文件合并
启用压缩:压缩可以减少数据量,进而减少磁盘和网络IO
hive.exec.compress.intermediate;--开启压缩
hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;--使用Snappy压缩
hive.intermediate.compression.type;--配置压缩对象 快或者记录
设置并行模式和本地模式,并行模型主要针对uoion 操作,本地模式主要针对数据量小,操作不复杂的SQL
hive.exec.parallel=true;--开启多个mapreduce作业的并行模式
hive.exec.parallel.thread.number;--设置并行执行的线程数
hive.exec.mode.local.auto;--开启本地执行模模式
设置合适的数据存储格式,hive默认的存储格式是TextFile,但是这种文件格式不使用压缩,会占用比较大空间,目前支持的存储格式有SequenceFile、RCFile、Avro、ORC、Parquet,这些存储格式基本都会采用压缩方式,而且是列式存储,使用这些格式的话文件不能直接导入。设置存储格式一般在建表时指定,如:
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
指定只用orc存储格式
使用严格模式,严格模式主要是防范用户的不规范操作造成集群压力过大,甚至是不可用的情况,只对三种情况起左右,分别是查询分区表是不指定分区;两表join时产生笛卡尔积;使用了order by 排序但是没有limit关键字。具体配置如下:
hive.mapred.mode=strict;--开启严格模式
调大hive.tez.cpu.vcores(比如2); 对map任务帮助很大
调大mapreduce.job.reduces(比如3000); 对reduce任务帮助很大
hql任务设置变量
#set($k=4);
#set($top=1400);
#set($beta=0.15);
#set($min_weight=1);















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









