







一、特征提取
深度学习,就是把我们的输入转换成一个高维的向量,这个向量就是被提取出的特征。一定程度上,可以理解这个提取的过程为编码或者压缩。
然后,我们才可以用这个特征去分类,回归或者其他任务。
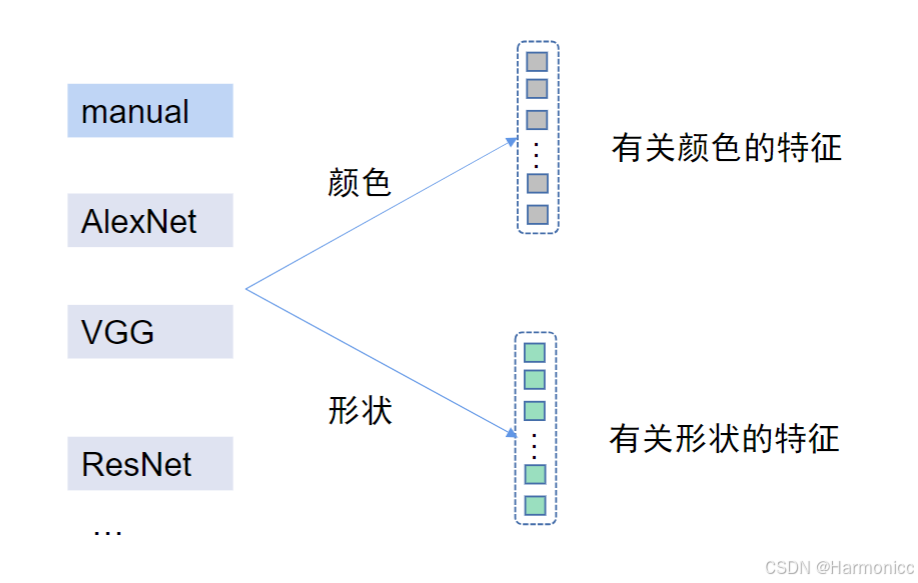
你的模型朝着哪个方向压缩特征,由你的标签(颜色或形状)来决定。
二、无监督学习
现实情况中的大部分数据都是没有标签的,比如食物分类的无标签数据,你不可能说下图的某张图片就是汉堡或者鸡腿。

2.1 无监督方法
机器学习上的无监督算法有降维算法(PCA),例如,使用PCA对mnist数据集进行数据预处理后再进行聚类。今天我们主要谈谈深度学习上的无监督方法——让机器自监督学习(对比学习和生成式自监督)。
2.1.1 对比学习
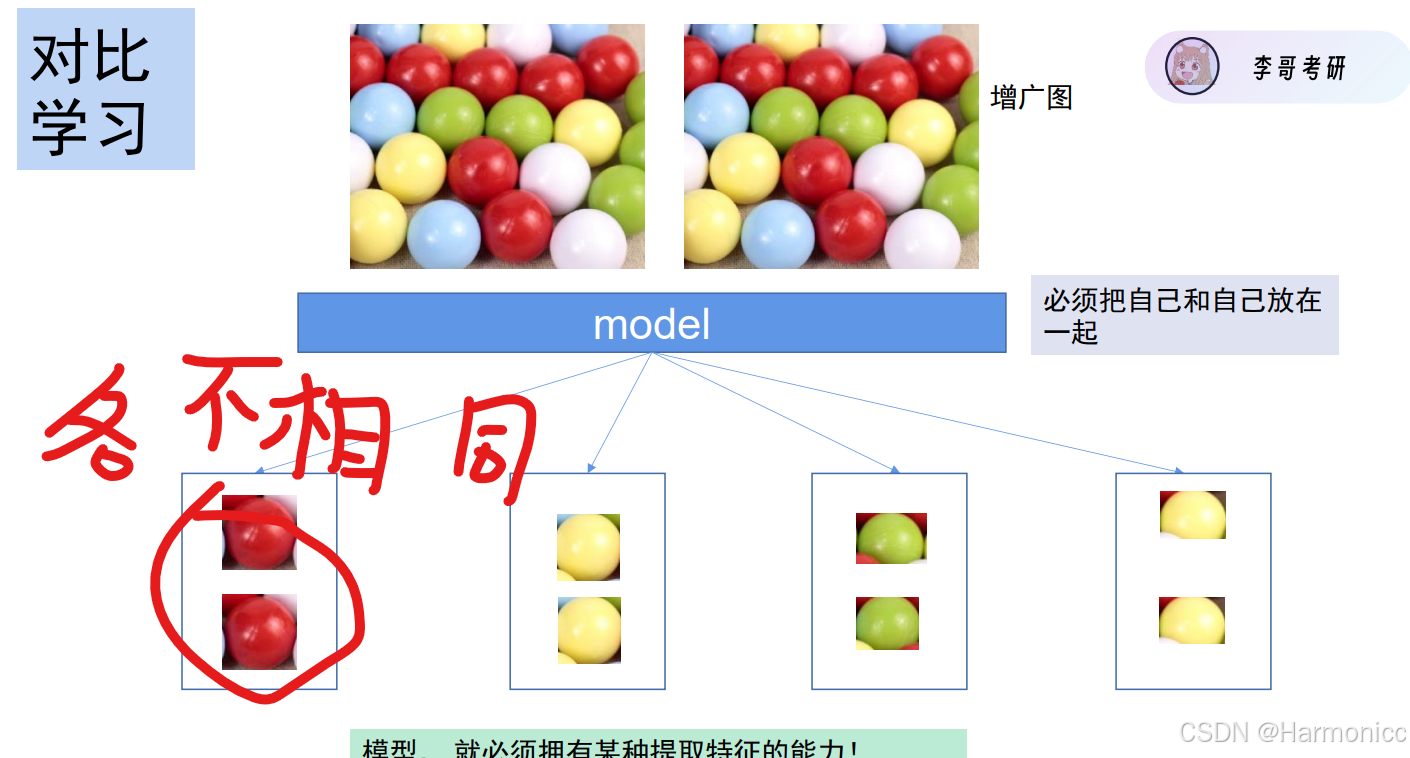
旨在学习一个特征表示,使得相似的样本在特征空间中距离较近,不相似的样本距离较远。说人话就是把自己和自己的增广图像当作一对, 把别人当作敌人。亲近自己, 远离别人。
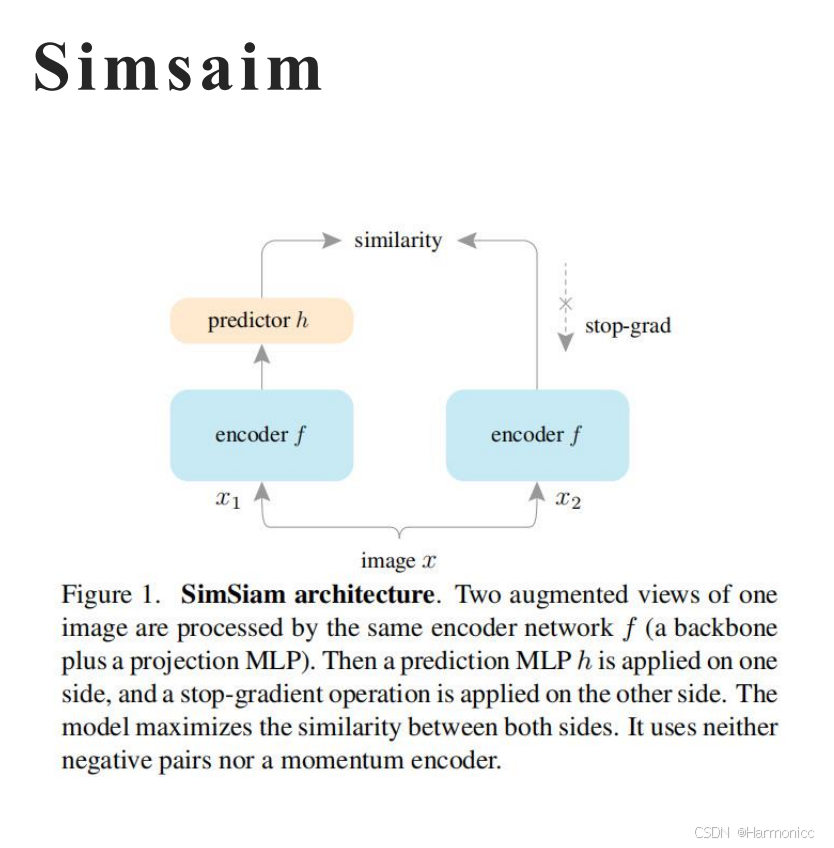
以SimSaim模型为例,一张原始图片经过数据增广变成这张图片的不同变形版本,
,然后
,
经过同一个编码器
得到两个一维特征向量,这时让其中的某个分支
经过预测器去试图预测另一条分支的特征。
-
关键技巧:
-
停止梯度:在反向传播时,其中一条分支的特征会被固定(像“参考答案”一样不更新),防止模型偷懒直接复制结果。
-
不对称预测:“预测器”只在一条分支上工作,强制模型通过不同视角学习一致的特征。
-
2.1.2 生成式自监督学习
2.1.2.1 对抗生成网络(GAN)

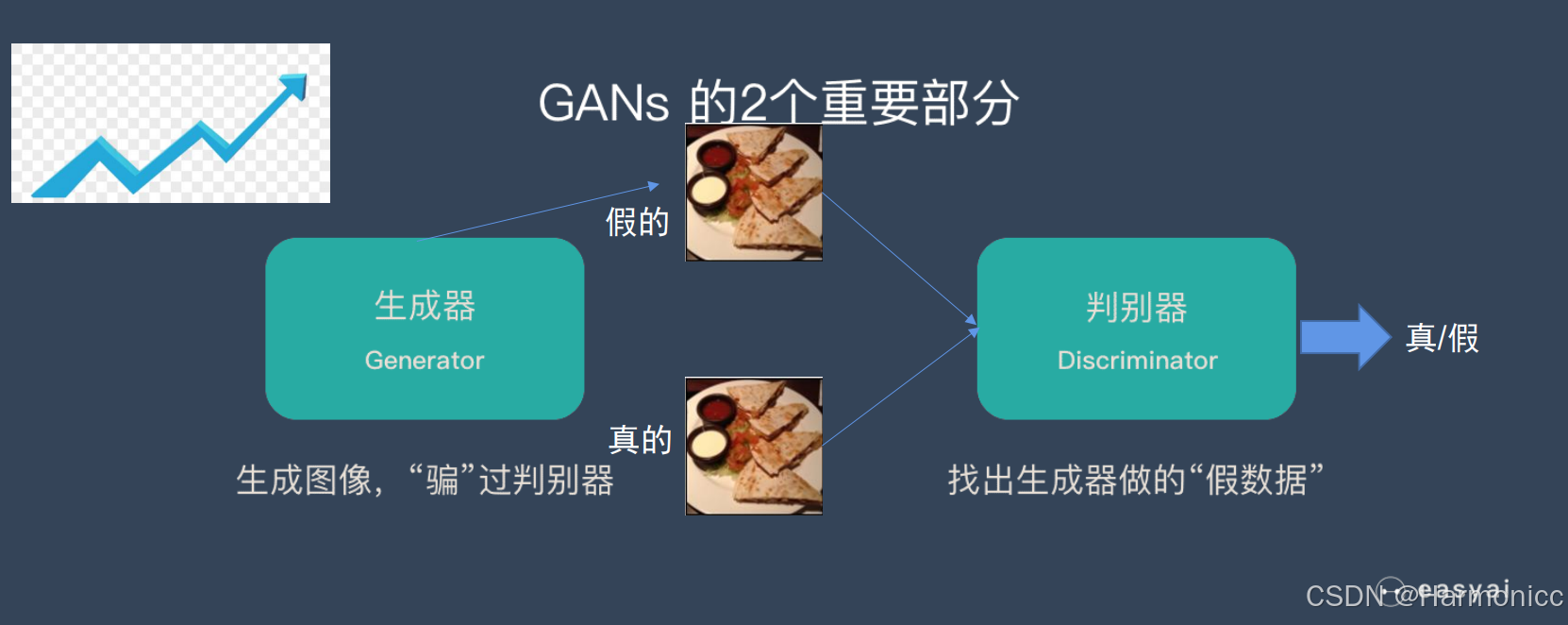
启动大名鼎鼎的GAN(Generative Adversarial Networks),讲讲原理,其实就GAN中的两个部分生成器(Generater)和判别器(Discriminator)相互内卷,生成器专门负责“造假”,比如生成假图片,一开始它水平很烂,生成的图片可能是一团乱码。判别器负责分辨输入是“真实的”还是“生成器造的假货”。比如给它看一张真实的猫图片和生成器造的假猫图,它要判断哪个是真的。
-
对抗过程:
-
第一阶段:生成器造出一批假货,判别器通过对比真实数据(比如真实的猫图)和假货,学习如何鉴别。
-
第二阶段:生成器根据判别器的反馈改进造假技术,目标是让假货骗过判别器。
-
反复循环这个过程,直到生成器的假货连判别器都难辨真假。
-
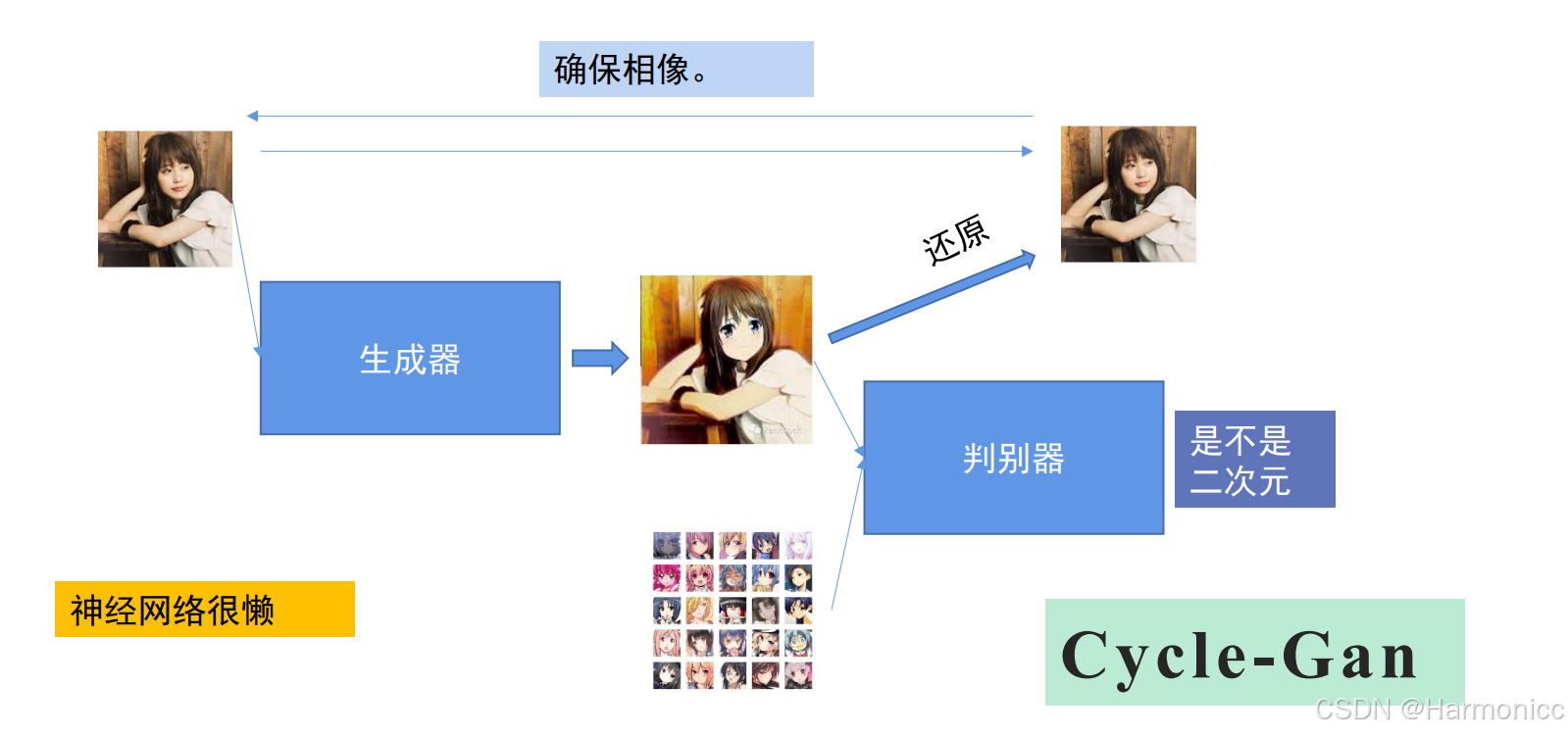
讲一讲Cycle-Gan,CycleGAN 是“既要马变斑马,又要斑马变回马”的循环式生成对抗网络,靠“来回还原”保证转换不跑偏。
现在有比GAN更强的模型了——扩散模型,有空看看写下blog.
2.1.2.2 自编码器
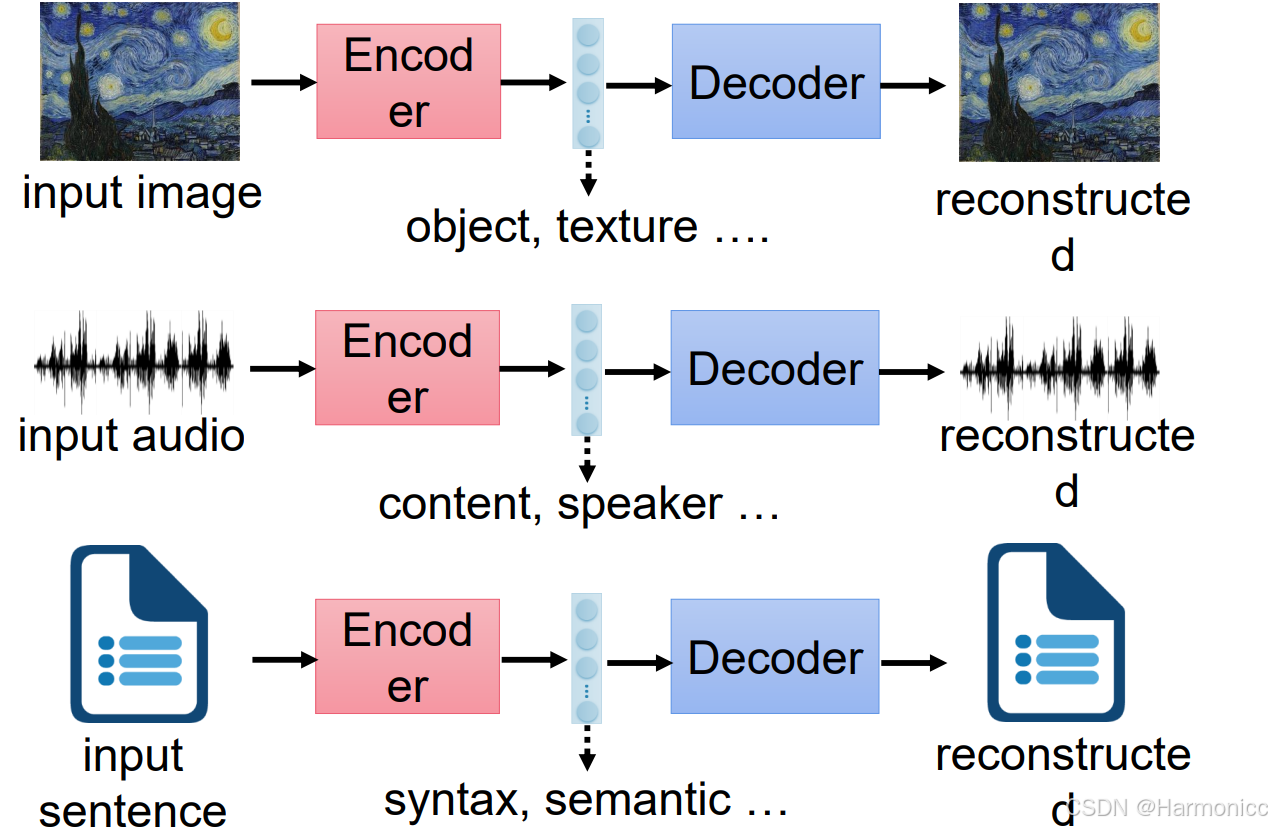
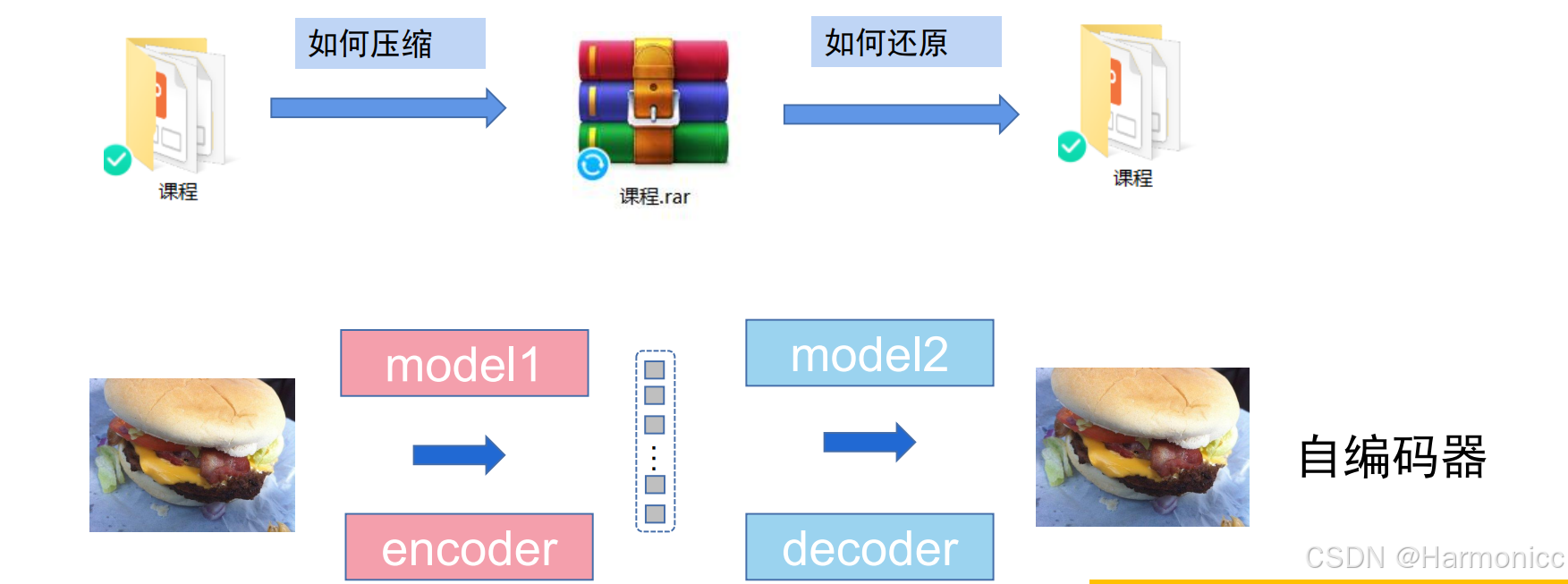
核心思想:像一台“压缩与解压机器”,目标是学习如何高效地压缩数据,再完整还原回来。
类比理解:
假设你有一篇长文章,自编码器的工作是:
-
压缩:用一个简短的摘要(编码)概括全文内容。
-
解压:根据这个摘要,重新写出和原文几乎一样的文章(解码)。
实际用途:
-
数据降维(比如将高清图片压缩成小文件)。
-
去噪(给一张模糊的图片,还原出清晰版本)。
-
特征提取(从数据中提炼关键信息,用于其他任务)。
缺点:
如果压缩得太狠(比如摘要太短),可能丢失重要细节,导致还原结果模糊或失真。
2.1.2.3 Masked Autoencoder(MAE)
其核心思想是通过随机遮盖输入图像的一部分(比如用矩形块遮盖),然后让模型预测被遮盖的部分。这种方法类似于自然语言处理中的BERT模型,通过遮盖部分输入来迫使模型学习上下文信息。像一场“图片拼图游戏”,随机遮盖大部分画面,让模型根据剩余部分猜出被遮住的内容。

具体应用可参见凯文大神的论文——

还有篇文章,可以看看公式之类的
https://arxiv.org/pdf/1603.08511v5
三、补充
3.1 无监督以后做什么
-
无监督预训练:模型从海量无标签数据中学习“什么是猫/狗/汽车”——本质是掌握视觉规律。
-
特征迁移:预训练后的编码器可以提取图像中的关键特征(如边缘、形状、纹理)。
-
下游任务适配:针对具体分类任务(11类),只需用少量标注数据调整分类头,无需重新训练整个模型。
*预训练工作一般是大佬们弄的(海量数据集和足够好的模型)
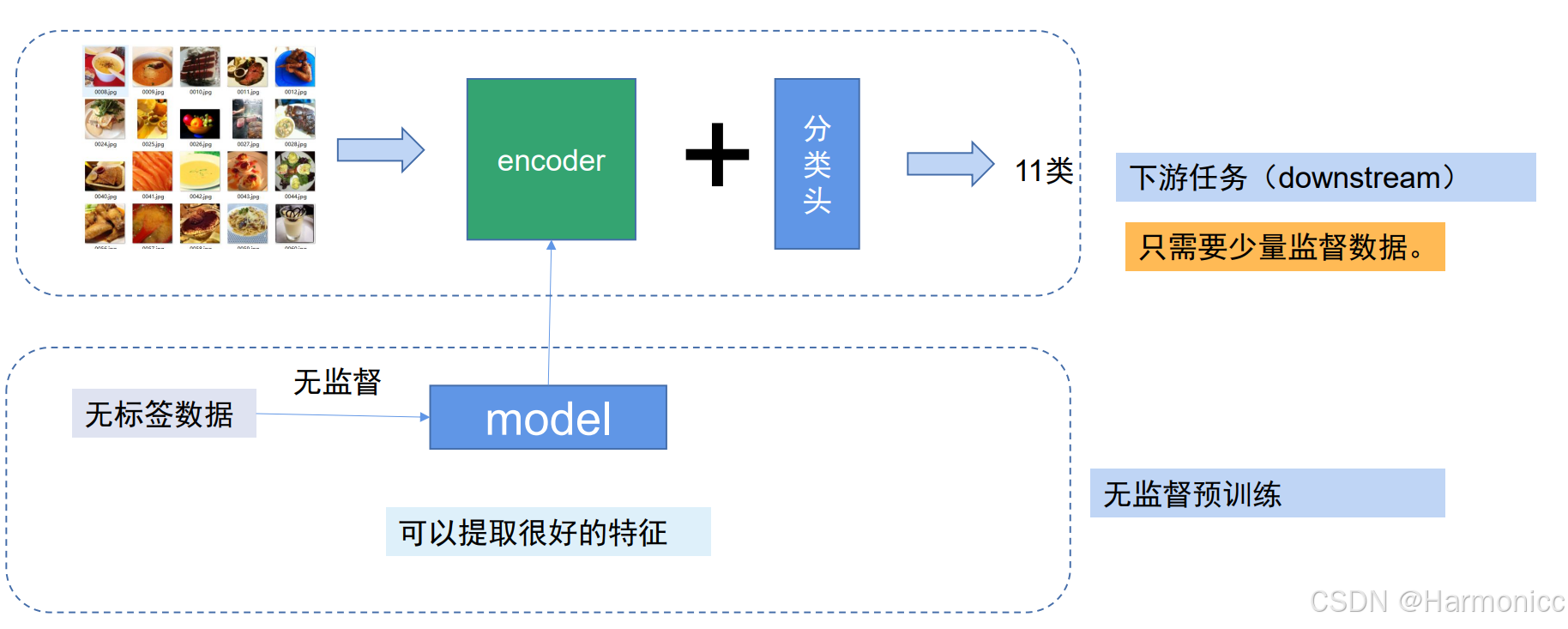
即
-
预训练:像让学生先通过大量“无答案练习题”自学物理规律(如力学、电磁学)。
-
下游任务:考试时只需做几道带答案的练习题(少量监督数据),就能快速掌握具体题型(11类分类)。
分类头是什么?
“分类头” 可以理解为模型的 “决策官”,专门负责根据学到的特征对数据进行分类。它的作用类似于一个 “选择题考官”,把模型提取到的信息转化成具体的类别判断。
-
结构:
-
分类头通常是神经网络的最后几层,比如 全连接层 + Softmax 激活函数。
-
全连接层负责将特征“压扁”成一组数值,Softmax 将这些数值变成概率(例如:这张图 80% 是猫,20% 是狗)。
-
-
功能:
-
假设模型前半部分(编码器)从图片中提取了“耳朵、胡须、毛茸茸”等特征,分类头则根据这些特征判断:“符合猫的特征,所以是猫”。
-
如果是 11 类分类任务,分类头会输出 11 个概率值,代表属于每一类的可能性。
-
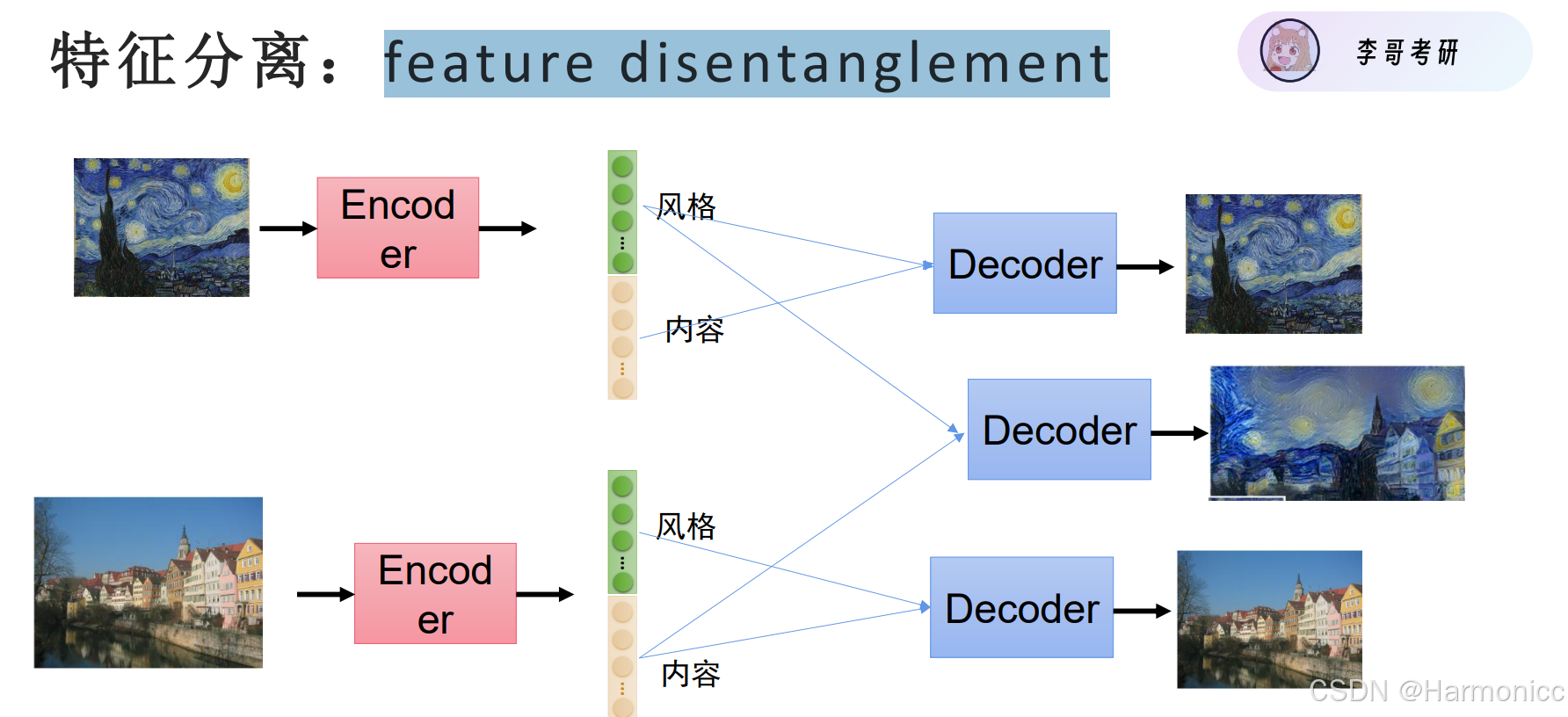
3.2 特征分离(feature disentanglement)
核心目标是 将数据中的“内容”和“风格”分离开,让模型能独立控制这两部分特征。
-
编码器像“拆解专家”,把数据拆成“内容”和“风格”。
-
解码器像“合成大师”,按需组合两者,生成新作品。
https://download.arxiv.org/pdf/1508.06576v2
https://zhuanlan.zhihu.com/p/26746283
本小节结束.
名词解释&问题示例
有时间再整理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









