







一、序
该项目源自Kaggle ML2021Spring-hw1
一段话概述:
本项目基于COVID - 19 数据集,构建回归模型预测新冠病毒检测阳性病人数量。首先,项目导入了多种必要的库,如用于绘图的matplotlib、深度学习框架PyTorch、数值计算的NumPy等。
数据预处理方面,定义了get_feature_importance函数,利用卡方检验进行特征选择,挑选出较重要的特征。同时创建了自定义的CovidDataset类,用于读取 CSV 格式的 COVID - 19 数据,将数据分为训练集、验证集和测试集,并对数据进行归一化处理。
模型搭建上,构建了一个简单的两层全连接神经网络MyModel,包含一个输入层、一个隐藏层和一个输出层,使用 ReLU 作为激活函数。
训练和验证部分,定义了train_val函数,采用带 L2 正则化的均方误差损失函数mseLoss,使用 SGD 优化器,在训练过程中记录训练损失和验证损失,绘制损失曲线,并且保存验证损失最小的模型。
最后,通过evaluate函数对测试集进行评估,将预测结果保存到 CSV 文件中。
训练集,验证集,测试集
联想训练集(题集),验证集(模拟卷),测试集(真题)
*验证集类比模拟卷的话写完记好分数就忘记题目,因为验证集只是验证效果不能更新模型
二、通用神经网络的训练框架

仅供参考.
2.1 导库
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体为微软雅黑
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题
import torch
import numpy as np
import csv
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import torch.nn as nn
from torch import optim
import time
from sklearn.feature_selection import SelectKBest,chi22.2 数据预处理
2.2.1 利用卡方检验进行特征选择
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。2.2.2 加载和处理COVID-19数据集
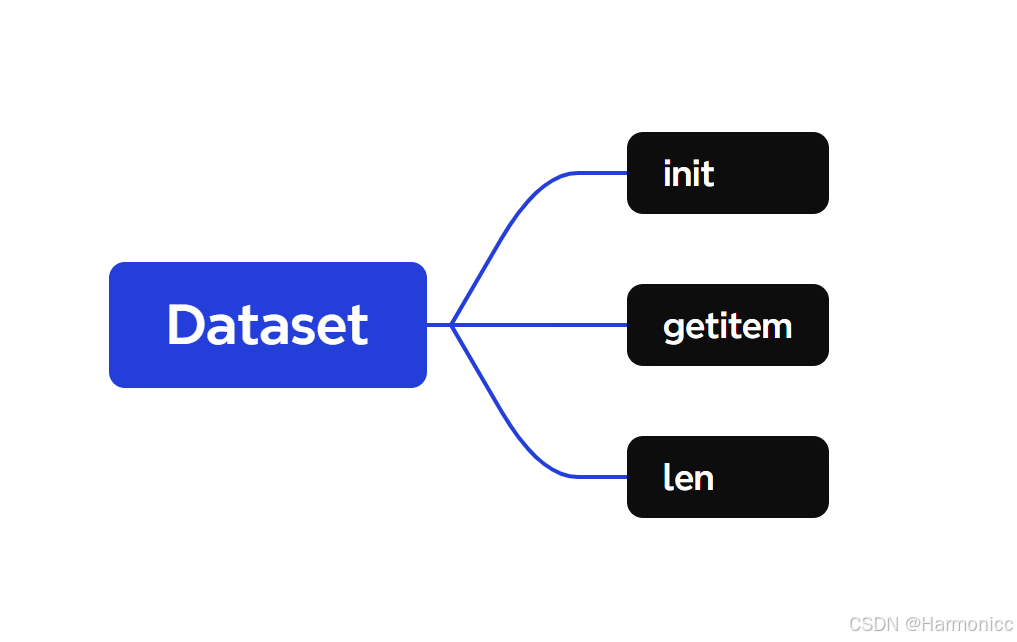
Dataset部分:
class CovidDataset(Dataset):
def __init__(self, path, mode="train", feature_dim=5, all_feature=False):
with open(path,'r') as f:
csv_data = list(csv.reader(f))
column = csv_data[0]
x = np.array(csv_data)[1:,1:-1]
y = np.array(csv_data)[1:,-1]
if all_feature:
col_indices = np.array([i for i in range(0,93)]) # 若全选,则选中所有列。
else:
_, col_indices = get_feature_importance(x, y, feature_dim, column) # 选重要的dim列。
# X_new = get_feature_importance_with_pca(x, feature_dim, column) # 选重要的特征
col_indices = col_indices.tolist() # col_indices 从array 转为列表。
csv_data = np.array(csv_data[1:])[:,1:].astype(float) #取csvdata从第二行开始, 第二列开始的数据,并转为float
if mode == 'train': # 训练数据逢5选4, 记录他们的所在行
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices,-1]) # 训练标签是csvdata的最后一列。 要转化为tensor型
elif mode == 'val': # 验证数据逢5选1, 记录他们的所在列
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
# data = torch.tensor(csv_data[indices,col_indices])
self.y = torch.tensor(csv_data[indices,-1]) # 验证标签是csvdata的最后一列。 要转化为tensor型
else:
indices = [i for i in range(len(csv_data))] # 测试机只有数据
# data = torch.tensor(csv_data[indices,col_indices])
data = torch.tensor(csv_data[indices, :]) # 根据选中行取 X , 即模型的输入特征
self.data = data[:, col_indices] # col_indices 表示了重要的K列, 根据重要性, 选中k列。
self.mode = mode # 表示当前数据集的模式
self.data = (self.data - self.data.mean(dim=0,keepdim=True)) / self.data.std(dim=0,keepdim=True) # 对数据进行列归一化
assert feature_dim == self.data.shape[1] # 判断数据的列数是否为规定的dim列, 要不然就报错。
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), feature_dim)) # 打印读了多少数据
def __getitem__(self, item): # getitem 需要完成读下标为item的数据
if self.mode == 'test': # 测试集没标签。 注意data要转为模型需要的float32型
return self.data[item].float()
else : # 否则要返回带标签数据
return self.data[item].float(), self.y[item].float()
def __len__(self):
return len(self.data) # 返回数据长度。 定义一个名为CovidDataset的类,它继承自torch.utils.data.Dataset,用于加载和处理COVID-19数据集。
init部分负责类的初始化方法,接受文件路径和数据集模式(训练、验证或测试)作为参数。
getitem部分定义如何获取单个数据项。
len部分返回数据集的长度。
2.3 模型搭建
Model部分:
# 搭建模型框架(包含初始化init(即搭建网络框架)和前向连接forward)
class MyModel(nn.Module):
def __init__(self, inDim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(inDim, 64)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(64, 1)
# 迭代?
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x
定义一个名为MyModel的神经网络模型类。
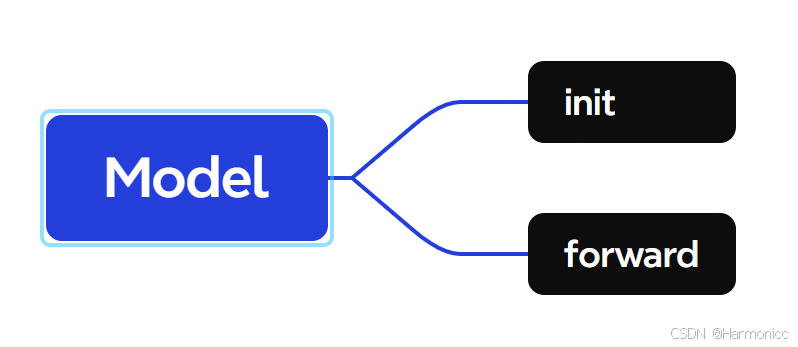
init部分模型初始化方法,包含一个输入层到64个神经元的线性层,一个ReLU激活函数,以及一个从64个神经元到1个神经元的线性层。
forward部分定义前向传播过程。
2.4 训练及验证
训练(train_val)及验证部分:
# 启动
def train_val(model, train_loader, val_loader,opt,loss,epochs, device, save_path):
model = model.to(device)
plt_train_loss = []
plt_val_loss = []
val_rel = []
min_val_loss = 9999999
# 启动
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
start_time = time.time()
# 模型(训练版)
model.train()
for data in train_loader: # 从训练集取一个batch的数据
opt.zero_grad() # 梯度清0
x , target = data[0].to(device), data[1].to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
bat_loss = loss(pred, target, model) # 计算loss
bat_loss.backward() # 梯度回传, 反向传播。
opt.step() #用优化器更新模型。
train_loss += bat_loss.detach().cpu().item() #记录loss和
plt_train_loss. append(train_loss/train_loader.dataset.__len__())
#记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
# 模型(验证版) 只是验证效果不能更新模型
model.eval()
with torch.no_grad():
for data in val_loader: # 从验证集取一个batch的数据
val_x, val_target = data[0].to(device), data[1].to(device) # 将数据放到设备上
val_pred = model(val_x) # 用模型预测数据
val_bat_loss = loss(val_pred, val_target, model) # 计算loss
val_loss += val_bat_loss.detach().cpu().item() # 计算loss
val_rel.append(val_pred) # 记录预测结果
if val_loss < min_val_loss:
torch.save(model, save_path) # 如果loss比之前的最小值小, 说明模型更优, 保存这个模型
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
print('[%03d/%03d] %2.2f sec(s) trainloss: %.6f | valloss: %.6f' % \
(epoch + 1, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1]))
#前缀加plt是用来画图的
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('loss图')
plt.legend(['train','val'])
plt.show()
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体
# plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题2.5 评估
def evaluate(save_path,test_loader,rel_path,device): #得出测试结果文件
model = torch.load(save_path).to(device)
testloader = DataLoader(test_loader, batch_size=1, shuffle=False) # 将验证数据放入loader 验证时, 一般batch为1
rel = [] #放进来
model.eval()
with torch.no_grad():
for data in testloader: # 从测试集取一个batch的数据
x = data.to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
rel.append(pred.item()) #记录预测结果
print(rel)
with open(rel_path,'w',newline='') as f:
csvWriter = csv.writer(f)
csvWriter.writerow(['id','tested_positive'])
for i in range(len(test_loader)): # 把测试结果的每一行放入输出的excel表中。
csvWriter.writerow([str(i), str(rel[i])])
print("rel已经保存到" + rel_path)2.6 启动
# 实例化模型并移动到指定设备上
model = MyModel(feature_dim).to(device)
# 创建训练集的 DataLoader
trainloader = DataLoader(train_dataset, batch_size=config['batch_size'],shuffle=True)
# 创建验证集的 DataLoader
valloader = DataLoader(val_dataset, batch_size=config['batch_size'],shuffle=True)
# 进行训练
train_val(model, trainloader, valloader, opt, loss, config['epochs'], device,save_path=config['save_path'])
# 进行评估
evaluate(config['save_path'], test_dataset, config['rel_path'], device)三、加点trick(改进模型性能的方法)
3.1 对loss正则(L2正则,矩阵分析)
#对loss正则
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失。
凡是能减少过拟合的方法,都是正则化方法,L1范数和L2范数是向量(或矩阵)的两种不同的范数计算方式。
针对权重w的正则化是L1&L2正则化,还有其他的正则化方法(Dropout)
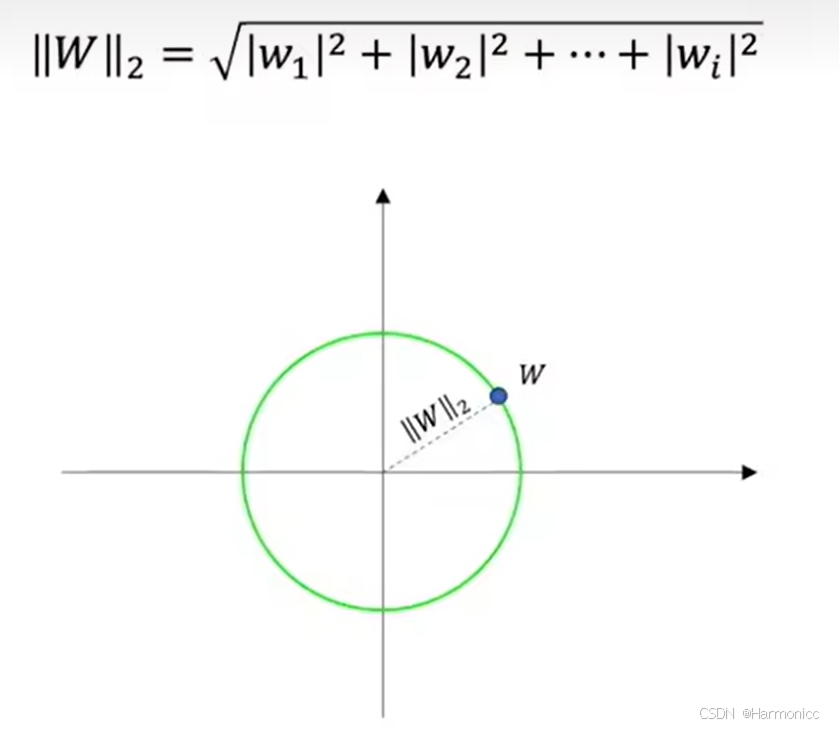
w理解成高维空间的一个点的话,w到原点的欧几里得距离就是L2范数。
一些论文中的L2范数长这样,我们暂时不去深究公式背后的意义
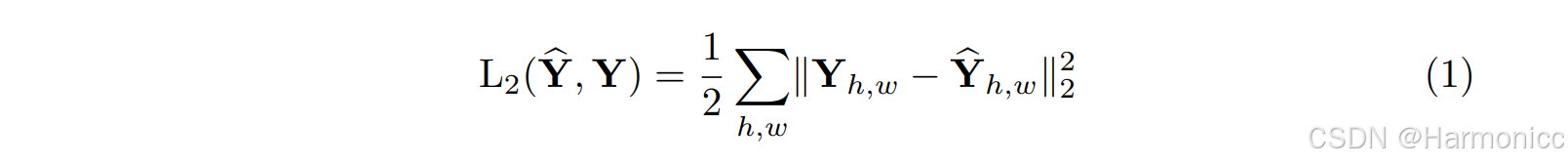
。
L1范数类似,两种范数的计算方法不同。
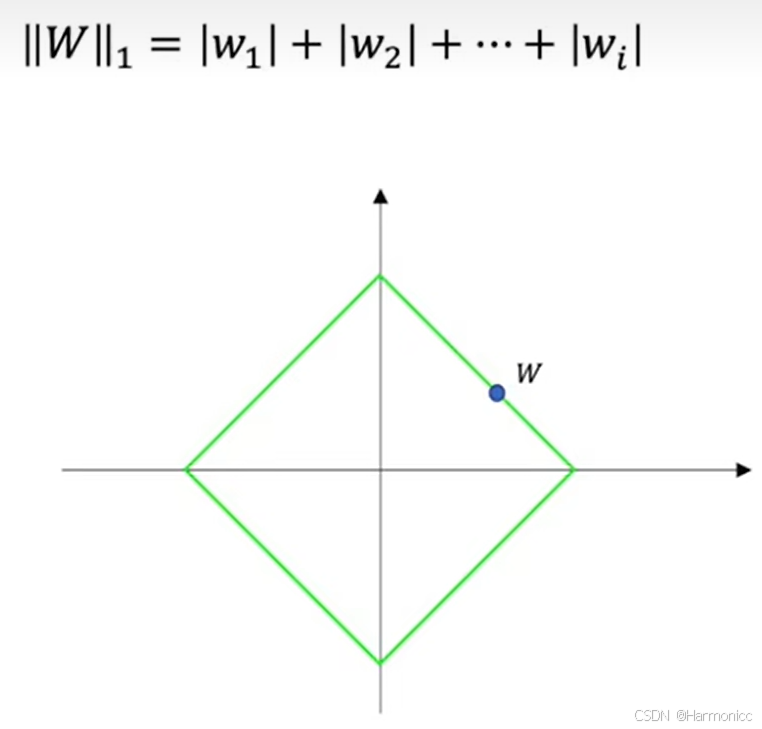
从拉格朗日乘数法的角度去做大致了解

3.2 降噪(通过计算相关系数把一些没用的列数去掉)
3.3 PCA
# def get_feature_importance_with_pca(feature_data, k=4, column=None):
# """
# 使用PCA进行特征降维,并找出对前k个主成分影响最大的原始特征。
#
# 参数:
# feature_data (pd.DataFrame or np.ndarray): 特征数据。
# k (int): 选择的主成分数目,默认为4。
# column (list, optional): 特征名称列表。如果feature_data是DataFrame,则可以省略此参数。
#
# 返回:
# X_new (np.ndarray): 降维后的特征数据。
# selected_features (list of lists): 对每个主成分影响最大的原始特征及其载荷。
# """
# # 如果提供了列名或feature_data是DataFrame,获取列名
# if column is None and hasattr(feature_data, 'columns'):
# column = feature_data.columns.tolist()
# elif column is None:
# raise ValueError("Column names must be provided if feature_data is not a DataFrame.")
#
# # 数据标准化
# scaler = StandardScaler()
# feature_data_scaled = scaler.fit_transform(feature_data)
#
# # 应用PCA
# pca = PCA(n_components=k)
# X_new = pca.fit_transform(feature_data_scaled)
# return X_new四、结果展示(部分)
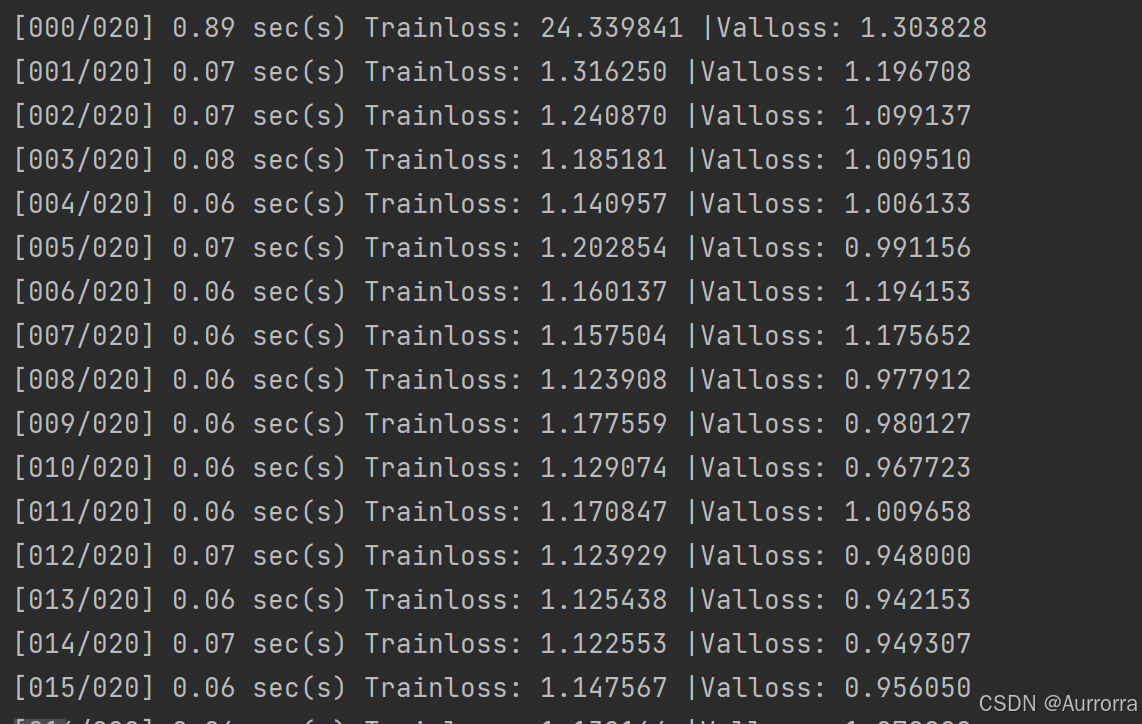
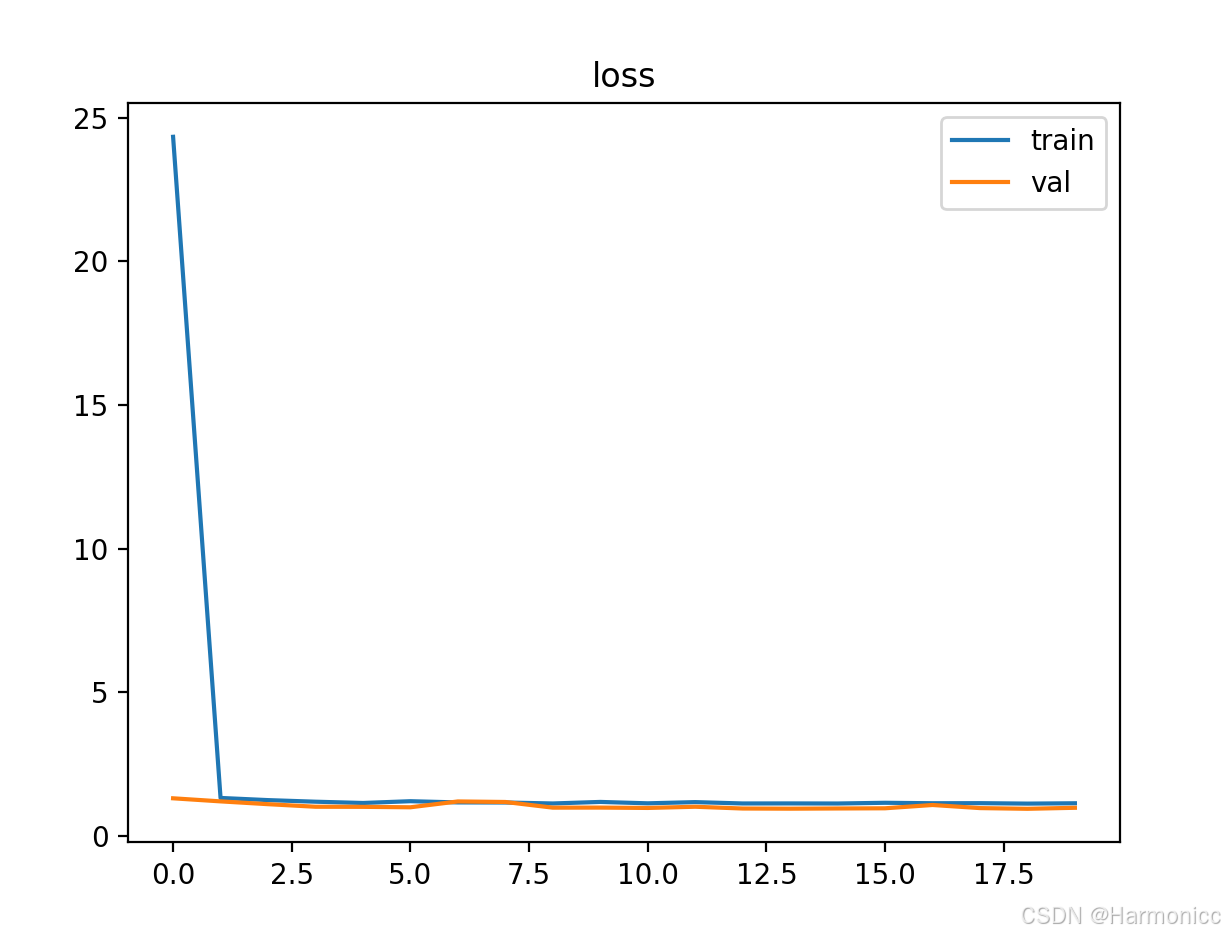
全部代码见资源绑定.
名词解释&问题示例
1.训练集,验证集,测试集
2.归一化处理
3.一段话概述项目
4.范数
5.优化器
6.正则化方法,为什么现在大多数对Loss函数都是L2正则而不是L1正则?
7.全连接
本小节结束。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









