






Kinetica 集成了 ChatGPT,可以将自然语言直接转化成SQL,刚测试了下,能够理解比较复杂的查询,可以按照中文语意自动找字段,挺好用的。但是该功能需要联网才能使用,应该是需要把相关的数据发给 ChatGPT,对数据安全会比较在意。
测试环境
- Kinetica 开发版
测试数据
使用 jafgen 生成的测试数据,直接导入 Kinetica

使用 raw_orders 表进行测试,表结构如下
CREATE TABLE "my_test"."raw_orders"
(
"id" VARCHAR (256) NOT NULL,
"customer" VARCHAR (256, dict) NOT NULL,
"ordered_at" DATETIME NOT NULL,
"store_id" VARCHAR (256, dict) NOT NULL,
"subtotal" INTEGER NOT NULL,
"tax_paid" INTEGER NOT NULL,
"order_total" INTEGER NOT NULL
)
TIER STRATEGY (
( ( VRAM 1, RAM 5, PERSIST 5 ) )
);
测试过程
- 创建新 workbook
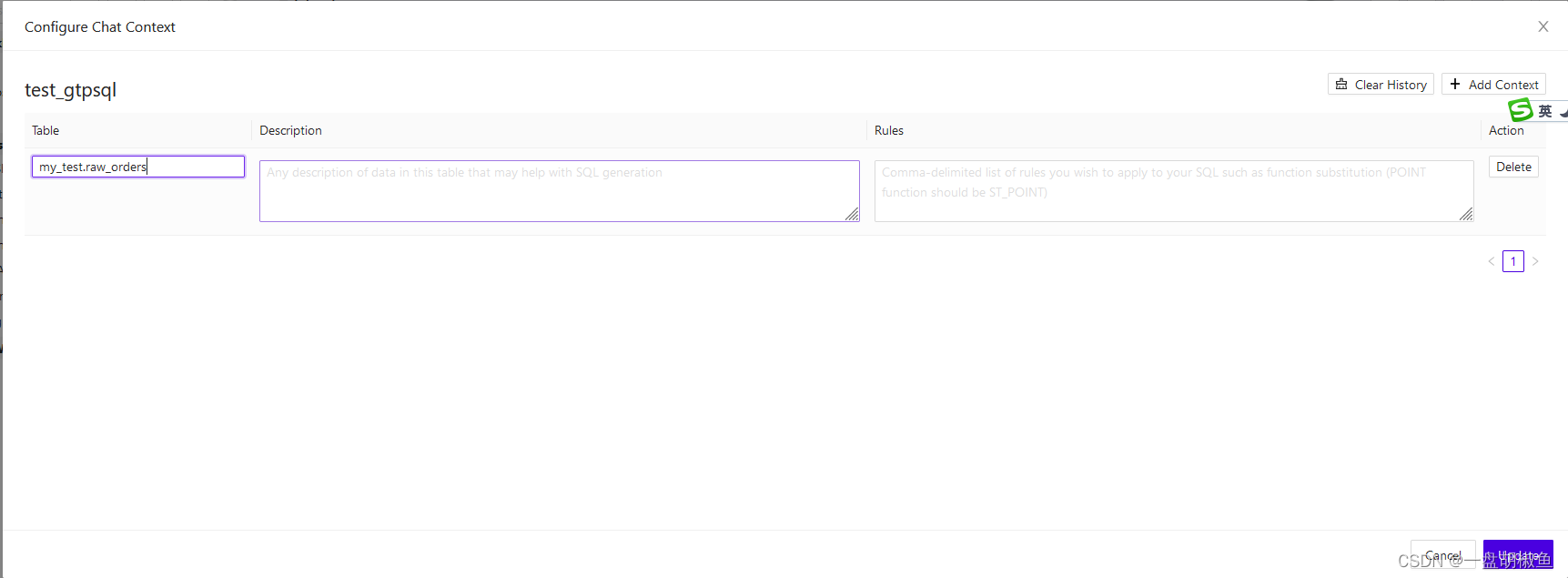
2.配置工作薄的关联表
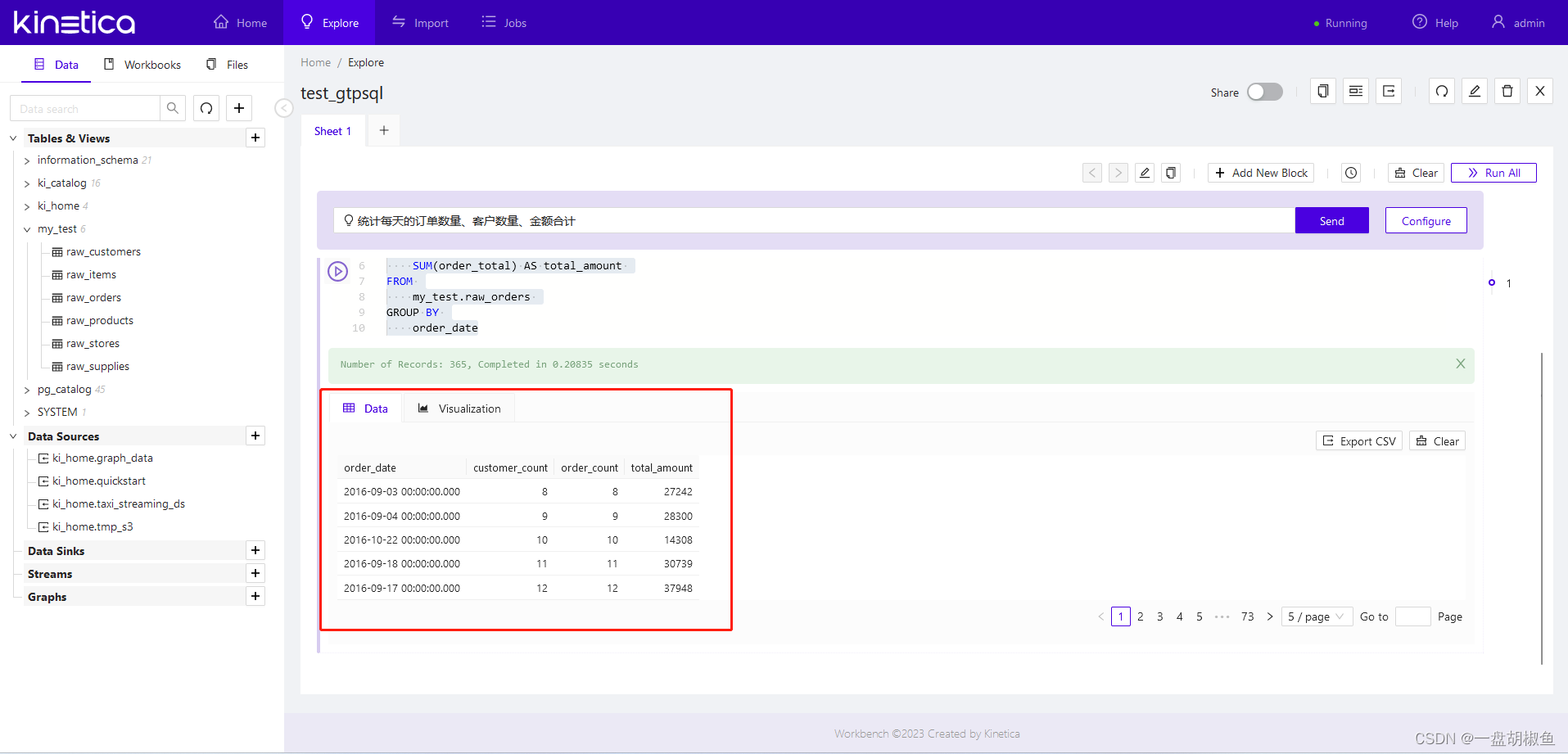
3.先上个简单的,输入【统计每天的订单数量、客户数量、金额合计】。点击【send】后,在下方生成了SQL代码,注意原表raw_orders有7个字段,并且没有字段注释,但找到的字段还是很准确的。
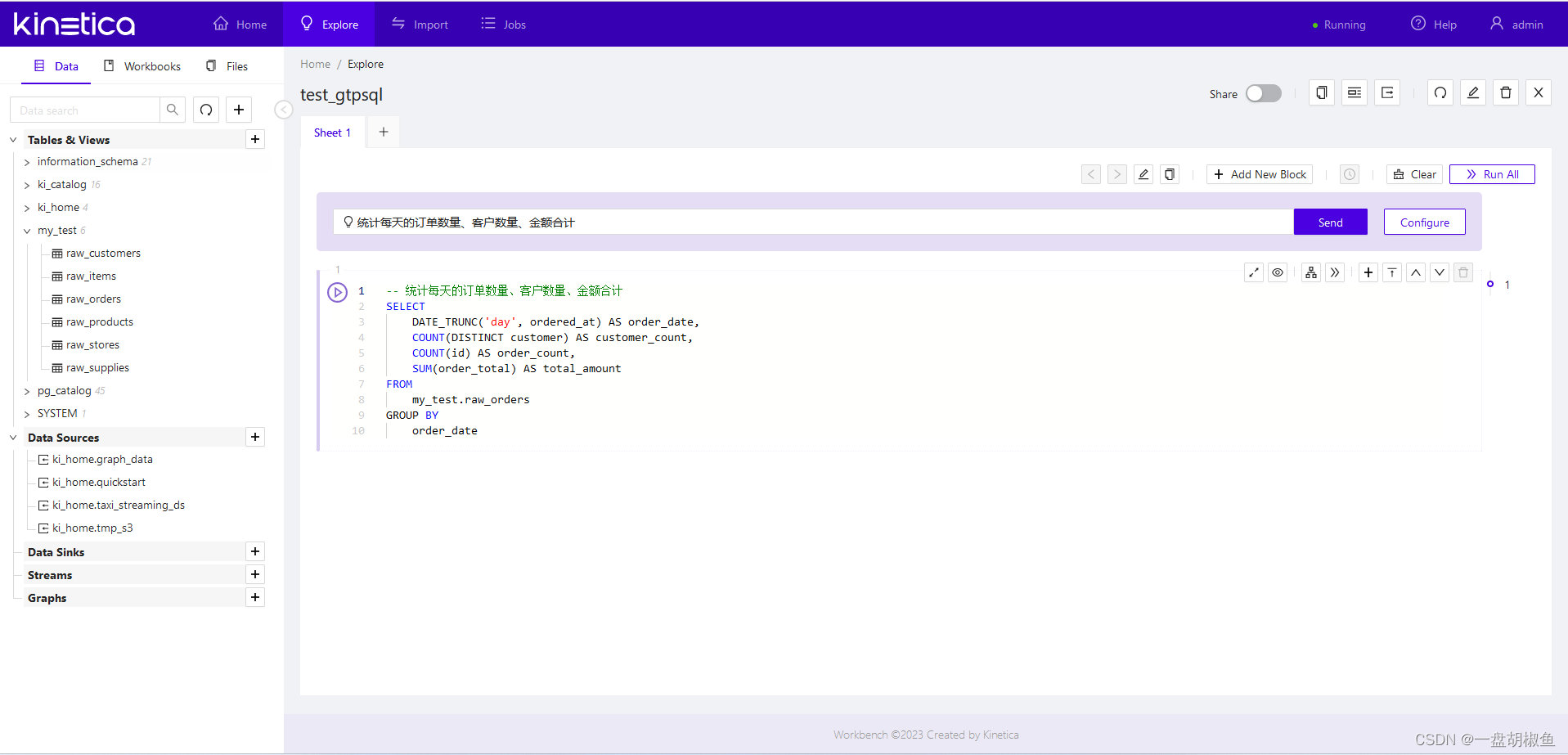
生成的sql:
-- 统计每天的订单数量、客户数量、金额合计
SELECT
DATE_TRUNC('day', ordered_at) AS order_date,
COUNT(DISTINCT customer) AS customer_count,
COUNT(id) AS order_count,
SUM(order_total) AS total_amount
FROM
my_test.raw_orders
GROUP BY
order_date
运行结果
- 再上个比较复杂的,输入
1.统计每天的订单数量、客户数量、金额合计;2.以第一步的查询结果进作为子表,进行列转行,date字段保存日期,key字段保存字段名称,value字段保存对应的值。点击【send】,生成sql如下:
-- 1.统计每天的订单数量、客户数量、金额合计;2.以第一步的查询结果进作为子表,进行列转行,date字段保存日期,key字段保存字段名称,value字段保存对应的值
SELECT
DATE_TRUNC('day', ordered_at) AS date,
COUNT(DISTINCT customer) AS customer_count,
COUNT(id) AS order_count,
SUM(order_total) AS total_amount
FROM
my_test.raw_orders
GROUP BY
DATE_TRUNC('day', ordered_at);
WITH daily_order_stats AS (
SELECT
DATE_TRUNC('day', ordered_at) AS date,
COUNT(DISTINCT customer) AS customer_count,
COUNT(id) AS order_count,
SUM(order_total) AS total_amount
FROM
my_test.raw_orders
GROUP BY
DATE_TRUNC('day', ordered_at)
)
SELECT
date,
'customer_count' AS key,
CAST(customer_count AS VARCHAR) AS value
FROM
daily_order_stats
UNION ALL
SELECT
date,
'order_count' AS key,
CAST(order_count AS VARCHAR) AS value
FROM
daily_order_stats
UNION ALL
SELECT
date,
'total_amount' AS key,
CAST(total_amount AS VARCHAR) AS value
FROM
daily_order_stats;
查询结果
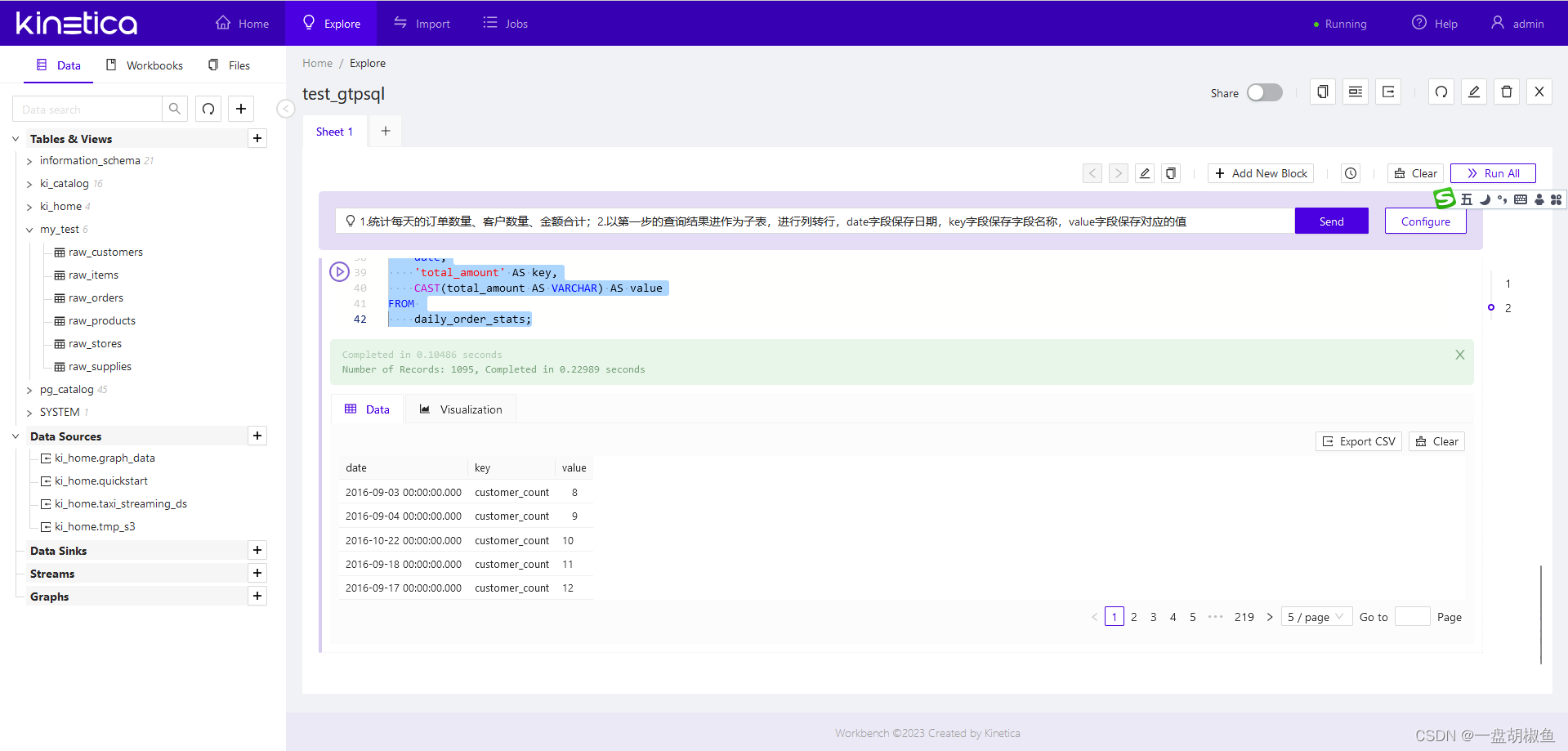
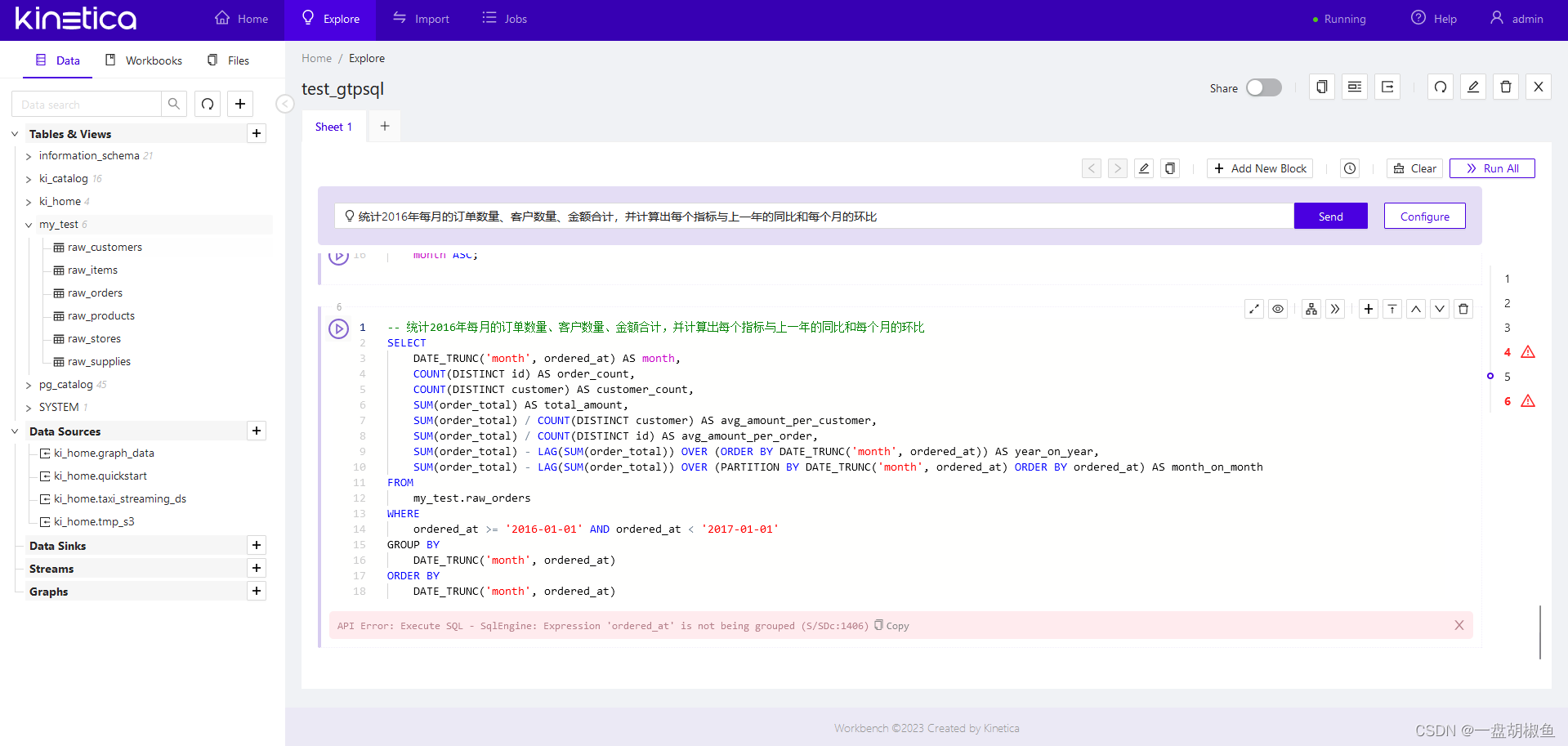
- 再来个比较不容易理解的需求,
统计2016年每月的订单数量、客户数量、金额合计,并计算出每个指标与上一年的同比和每个月的环比,结果有点摸不着头脑了。
-- 统计2016年每月的订单数量、客户数量、金额合计,并计算出每个指标与上一年的同比和每个月的环比
SELECT
DATE_TRUNC('month', ordered_at) AS month,
COUNT(DISTINCT id) AS order_count,
COUNT(DISTINCT customer) AS customer_count,
SUM(order_total) AS total_amount,
SUM(order_total) / COUNT(DISTINCT customer) AS avg_amount_per_customer,
SUM(order_total) / COUNT(DISTINCT id) AS avg_amount_per_order,
SUM(order_total) - LAG(SUM(order_total)) OVER (ORDER BY DATE_TRUNC('month', ordered_at)) AS year_on_year,
SUM(order_total) - LAG(SUM(order_total)) OVER (PARTITION BY DATE_TRUNC('month', ordered_at) ORDER BY ordered_at) AS month_on_month
FROM
my_test.raw_orders
WHERE
ordered_at >= '2016-01-01' AND ordered_at < '2017-01-01'
GROUP BY
DATE_TRUNC('month', ordered_at)
ORDER BY
DATE_TRUNC('month', ordered_at)
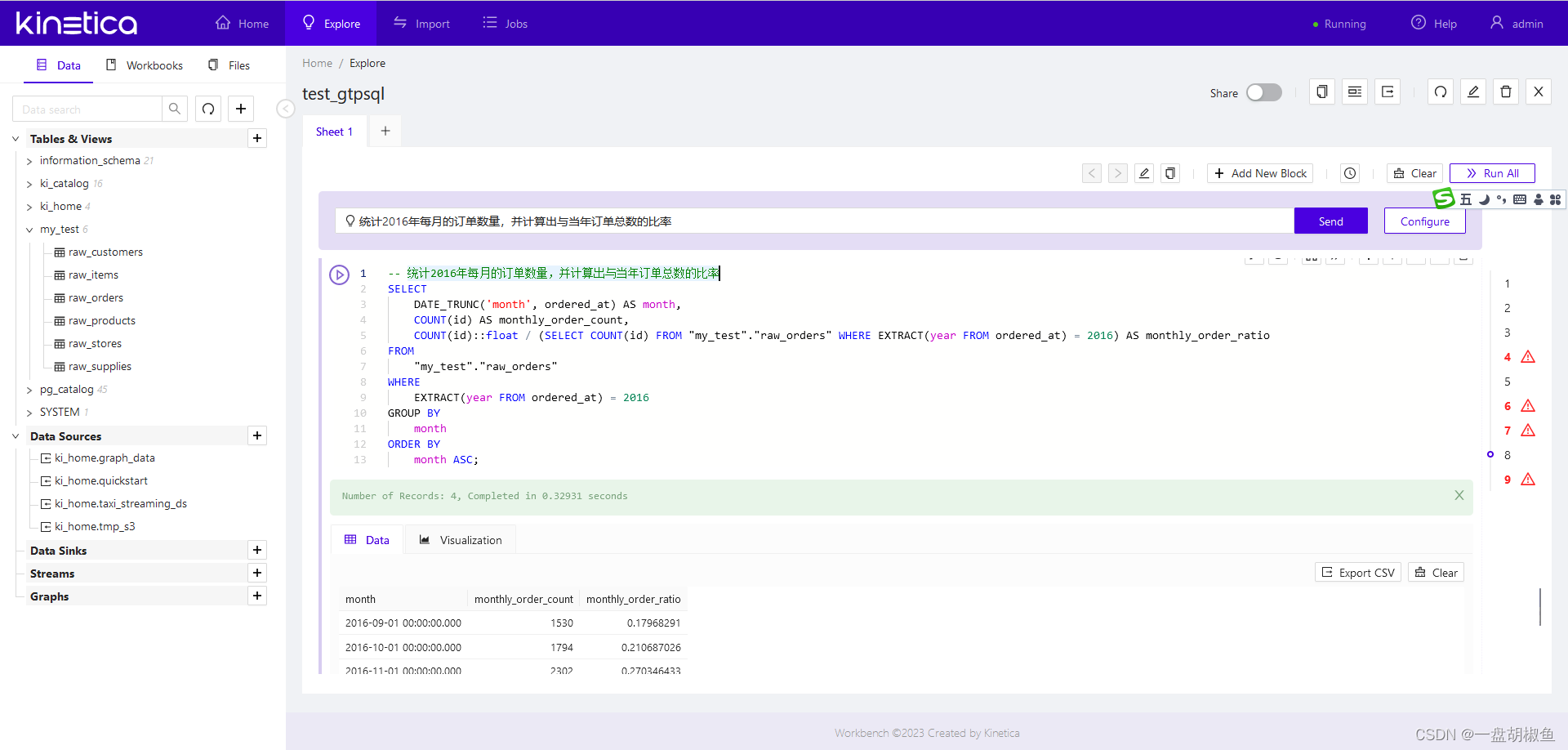
6.降低一点难度 统计2016年每月的订单数量,并计算出与当年订单总数的比率,结果不错。
-- 统计2016年每月的订单数量,并计算出与当年订单总数的比率
SELECT
DATE_TRUNC('month', ordered_at) AS month,
COUNT(id) AS monthly_order_count,
COUNT(id)::float / (SELECT COUNT(id) FROM "my_test"."raw_orders" WHERE EXTRACT(year FROM ordered_at) = 2016) AS monthly_order_ratio
FROM
"my_test"."raw_orders"
WHERE
EXTRACT(year FROM ordered_at) = 2016
GROUP BY
month
ORDER BY
month ASC;















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









