






学习笔记
1、常用预测评价指标
一种训练集一种算法
分类算法常见的评估指标如下:
1、混淆矩阵
- (1)如果一个实例是正类,且被预测为正类,即为真正类TP(True Positive)
- (2)如果一个实例是正类,且被预测为负类,即为假负类FN(False Negative)
- (3)如果一个实例是负类,且被预测为正类,即为假正类FP(False Positive)
- (4)如果一个实例是负类,且被预测为负类,即为真负类TN(True Negative)
2、准确率(Accuracy)
常用的评价指标,但是不适合样本不均衡的情况下
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
Accuracy=TP+TN+FP+FNTP+TN
3、精确率(Precision)
又称查准率,正确预测为正样本(TP)占预测为正样本(TP+FP)的百分比
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
4、召回率(Recall)
又称查全率,正确预测为正样本(TP)占实际为正样本(TP+FN)的百分比
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP}{TP+FN}
Recall=TP+FNTP
5、 F1-Score
精确率和召回率相互影响,当精确率升高时召回率下降,召回率上升是精确率下降,如果需要兼顾二者,就需要将精确率和召回率相结合起来,得到F1-Score
F1-Score实际上是调和平均数:
1
F
1
=
(
1
p
r
e
c
i
s
i
o
n
+
1
r
e
c
a
l
l
)
∗
1
2
\frac{1}{F1}=(\frac{1}{precision}+\frac{1}{recall})*\frac{1}{2}
F11=(precision1+recall1)∗21
1
F
1
=
(
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
2
∗
p
r
e
c
i
s
i
o
n
∗
r
e
c
a
l
l
)
\frac{1}{F1}=(\frac{precision+recall}{2*precision*recall})
F11=(2∗precision∗recallprecision+recall)
F
1
=
(
2
∗
p
r
e
c
i
s
i
o
n
∗
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
)
F1=(\frac{2*precision*recall}{precision+recall})
F1=(precision+recall2∗precision∗recall)
F
1
=
(
2
1
p
r
e
c
i
s
i
o
n
+
1
r
e
c
a
l
l
)
F1=(\frac{2}{\frac{1}{precision}+\frac{1}{recall}})
F1=(precision1+recall12)
一种训练集多种算法
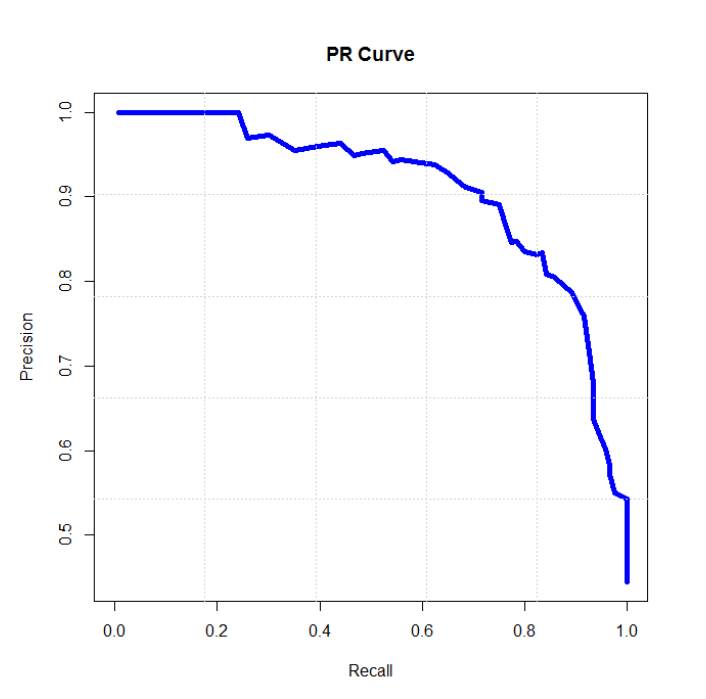
1、P-R曲线
每次计算出当前的查全率、查准率,以查全率为横轴、查准率为纵轴,就得到了P-R曲线图
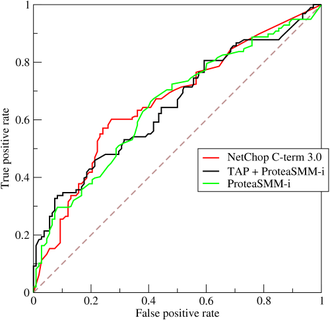
2、ROC曲线
ROC曲线将假正例率(FPR)定义为横轴,真正例率(TPR)定义为纵轴
F
P
R
=
F
P
F
P
+
T
N
FPR = \frac{FP}{FP+TN}
FPR=FP+TNFP
T
P
F
=
T
P
T
P
+
F
N
TPF = \frac{TP}{TP+FN}
TPF=TP+FNTP
若一个学习器的ROC曲线被另一个学习器的ROC完全包住,则可以断言,后者的性能优于前者;若两个学习器的ROC曲线发生交叉,则需要比较曲线与坐标轴所围成的面积(AUC)
3、AUC(Area Under Curve)
AUC被定义为ROC曲线与坐标轴所围成的面积,显然这个面积的数值不会大于1
又因为ROC曲线一般在y=x的上方,因此AUC的取值范围在0.5-1之间,越接近1则表明检测方法真实性越高,等于0.5时则真实性最低,无参考价值
2、数据探索
(1) 总体分布
1、导入数据并查看数据分布
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
import warnings
warnings.filterwarnings('ignore')
data_train = pd.read_csv(r'./train.csv')
data_test = pd.read_csv(r'./testA.csv')
data_test.shape
data_train.shape
data_train.columns #查看所有字段名称

查看一下具体的列名,赛题理解部分已经给出具体的特征含义,这里方便阅读再给一下:
- id 为贷款清单分配的唯一信用证标识
- loanAmnt 贷款金额
- term 贷款期限(year)
- interestRate 贷款利率
- installment 分期付款金额
- grade 贷款等级
- subGrade 贷款等级之子级
- employmentTitle 就业职称
- employmentLength 就业年限(年)
- homeOwnership 借款人在登记时提供的房屋所有权状况
- annualIncome 年收入
- verificationStatus 验证状态
- issueDate 贷款发放的月份
- purpose 借款人在贷款申请时的贷款用途类别
- postCode 借款人在贷款申请中提供的邮政编码的前3位数字
- regionCode 地区编码
- dti 债务收入比
- delinquency_2years 借款人过去2年信用档案中逾期30天以上的违约事件数
- ficoRangeLow 借款人在贷款发放时的fico所属的下限范围
- ficoRangeHigh 借款人在贷款发放时的fico所属的上限范围
- openAcc 借款人信用档案中未结信用额度的数量
- pubRec 贬损公共记录的数量
- pubRecBankruptcies 公开记录清除的数量
- revolBal 信贷周转余额合计
- revolUtil 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额
- totalAcc 借款人信用档案中当前的信用额度总数
- initialListStatus 贷款的初始列表状态
- applicationType 表明贷款是个人申请还是与两个共同借款人的联合申请
- earliesCreditLine 借款人最早报告的信用额度开立的月份
- title 借款人提供的贷款名称
- policyCode 公开可用的策略_代码=1新产品不公开可用的策略_代码=2
- n系列匿名特征 匿名特征n0-n14,为一些贷款人行为计数特征的处理
2、查看总体数据集各个特征的基本统计量及具体数据
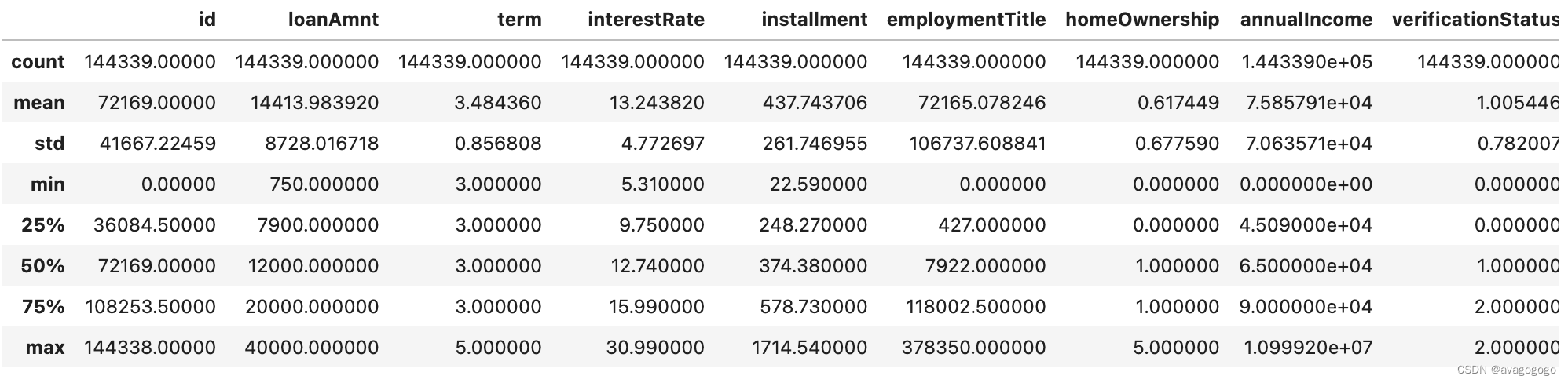
## 总体粗略看下各个特征的统计量
data_train.describe()
## 看下开头和结尾的具体数据明细
data_train.head(3).append(data_train.tail(3))
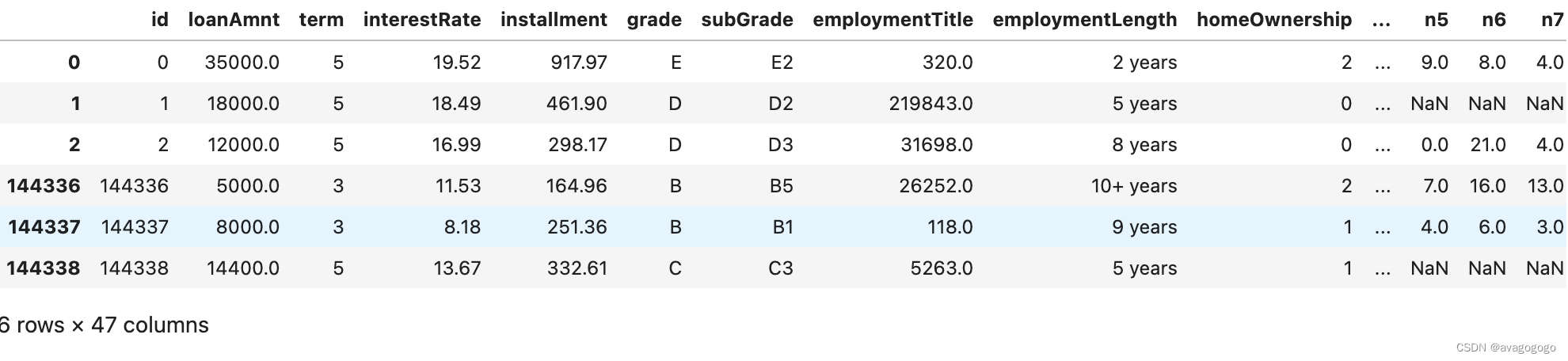
(2) 缺失值和唯一值
1、特征缺失情况
##查看缺失值
## 1、缺失的字段数
print(f'There are {data_train.isnull().any().sum()} columns in train dataset withing missing value')
## 2、有26个字段具有缺失值,下一步具体查看26个中缺失值占比大于50%的字段
have_null_fea_dict = (data_train.isnull().sum()/len(data_train)).to_dict()
fea_null_morethanhalf = {}
for key,value in have_null_fea_dict.items():
if value>0.5:
fea_null_morethanhalf[key] = value
## 3、26个含有缺失值的字段的缺失率均在50%以下,具体来看每个字段的缺失率,作图来看
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing>0]
missing = missing.sort_values()
missing.plot.bar()
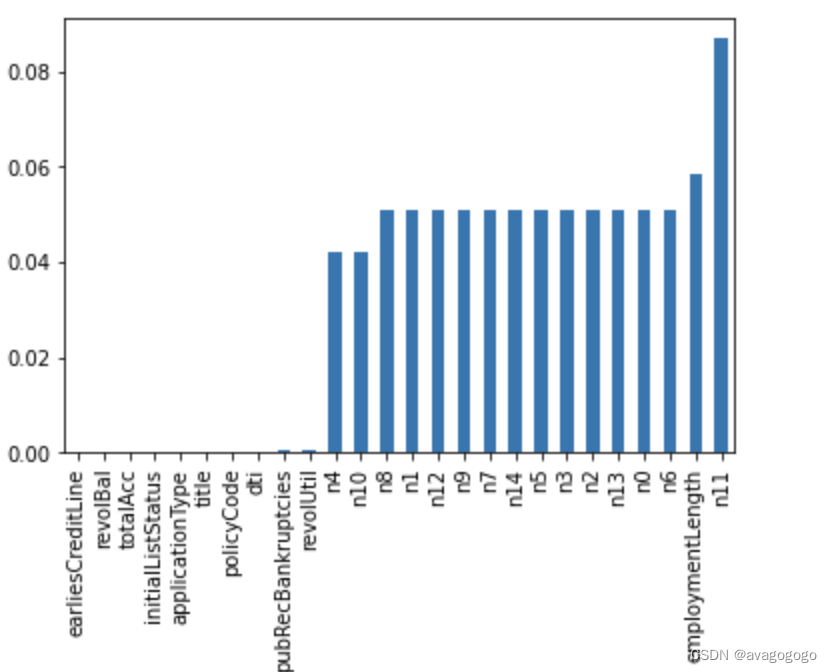
- 纵向了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于查看某一列nan存在的个数是否真的很大,如果nan存在的过多,说明这一列对label的影响几乎不起作用了,可以考虑删掉。如果缺失值很小一般可以选择填充。
- 另外可以横向比较,如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
2、唯一值情况
#查看唯一值的情况
one_value_fea = [col for col in data_train.columns if data_train[col].nunique()<=1]
one_value_fea
one_value_fea_test = [col for col in data_test.columns if data_test[col].nunique()<=1]
one_value_fea_test

‘policyCode’具有一个唯一值(或全部缺失)。有很多连续变量和一些分类变量。
(3)查看特征的数据类型
- 特征一般由数值型特征和类别型特征组成,其中数据值型特征又分为:连续性变量和离散型变量
- 类别型变量有时具有数据特征有时具有非数据特征,例如:‘grade’等级枚举值有ABC,是否是单纯分类,还是说A>B>C
- 数值型特征可以直接入模,但是风控人员往往要对其做分箱,转化为WOE编码进而做标准评分卡等操作。从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度,从而使模型更加稳定
#1、划分数值型数据和分类型数据
numerical_fea = list(data_train.select_dtypes(exclude= ['object']).columns)
category_fea = list(data_train.select_dtypes(include = ['object']).columns)
print(f'分类型变量有{len(category_fea)}个')
print(f'数值型变量有{len(numerical_fea)}个')
分类型变量有5个,数值型变量有42个
##划分数值型变量中的离散型变量和连续性变量
def get_numerical_series_fea(data,feas):
numerical_series_fea = []
numerical_noseries_fea = []
for fea in feas:
df = data[fea].nunique()
if df<=10:
numerical_noseries_fea.append(fea)
else:
numerical_series_fea.append(fea)
return numerical_noseries_fea,numerical_series_fea
numerical_noseries_fea,numerical_series_fea = get_numerical_series_fea(data_train,numerical_fea)
numerical_noseries_fea
数值型变量分析
分类型数值变量

查看分类型变量的数据
data_train['initialListStatus'].value_counts() #离散型变量
data_train['applicationType'].value_counts() #离散型变量
data_train['policyCode'].value_counts() #离散型变量
data_train['n11'].value_counts() #离散型变量
data_train['n12'].value_counts() #离散型变量
连续性数值变量

查看连续性变量的分布
#连续性数值变量
#查看连续变量的分布
f = pd.melt(data_train,value_vars = numerical_series_fea)
g = sns.FacetGrid(f,col = "variable", col_wrap=2, sharex=False, sharey=False)
g.map(sns.distplot,"value")
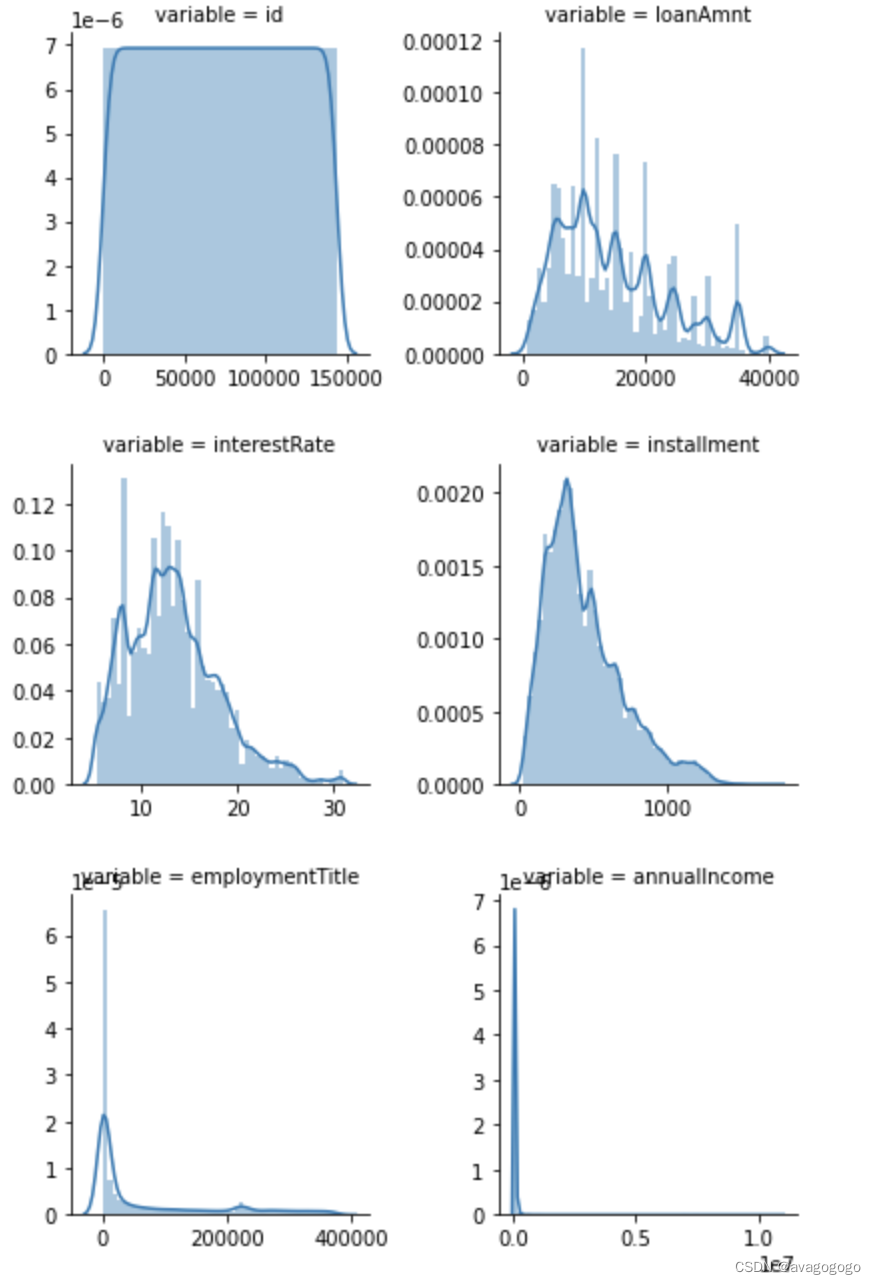
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
- 如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
- 正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
#将贷款金额对数化之后,绘制图像
plt.figure(figsize=(16,20))
plt.suptitle("Transaction Values Distribution",fontsize = 22)
plt.subplot(221)
sub_plot_1 = sns.distplot(data_train['loanAmnt'])
sub_plot_1.set_title("loanAmnt distribution",fontsize = 22)
sub_plot_1.set_xlabel('')
sub_plot_1.set_ylabel('probability',fontsize = 22)
plt.subplot(222)
sub_plot_2 = sns.distplot(np.log(data_train['loanAmnt']))
sub_plot_2.set_title("loanAmnt(Log) distribution",fontsize = 22)
sub_plot_2.set_xlabel('')
sub_plot_2.set_ylabel('probability',fontsize=22)

分类型数据分析
查看分类型变量数据分布
#查看分类型变量数据分布
data_train['grade'].value_counts()
data_train['subGrade'].value_counts()
data_train['employmentLength'].value_counts()
data_train['issueDate'].value_counts()
data_train['earliesCreditLine'].value_counts()
变量分布可视化
单一变量分布可视化
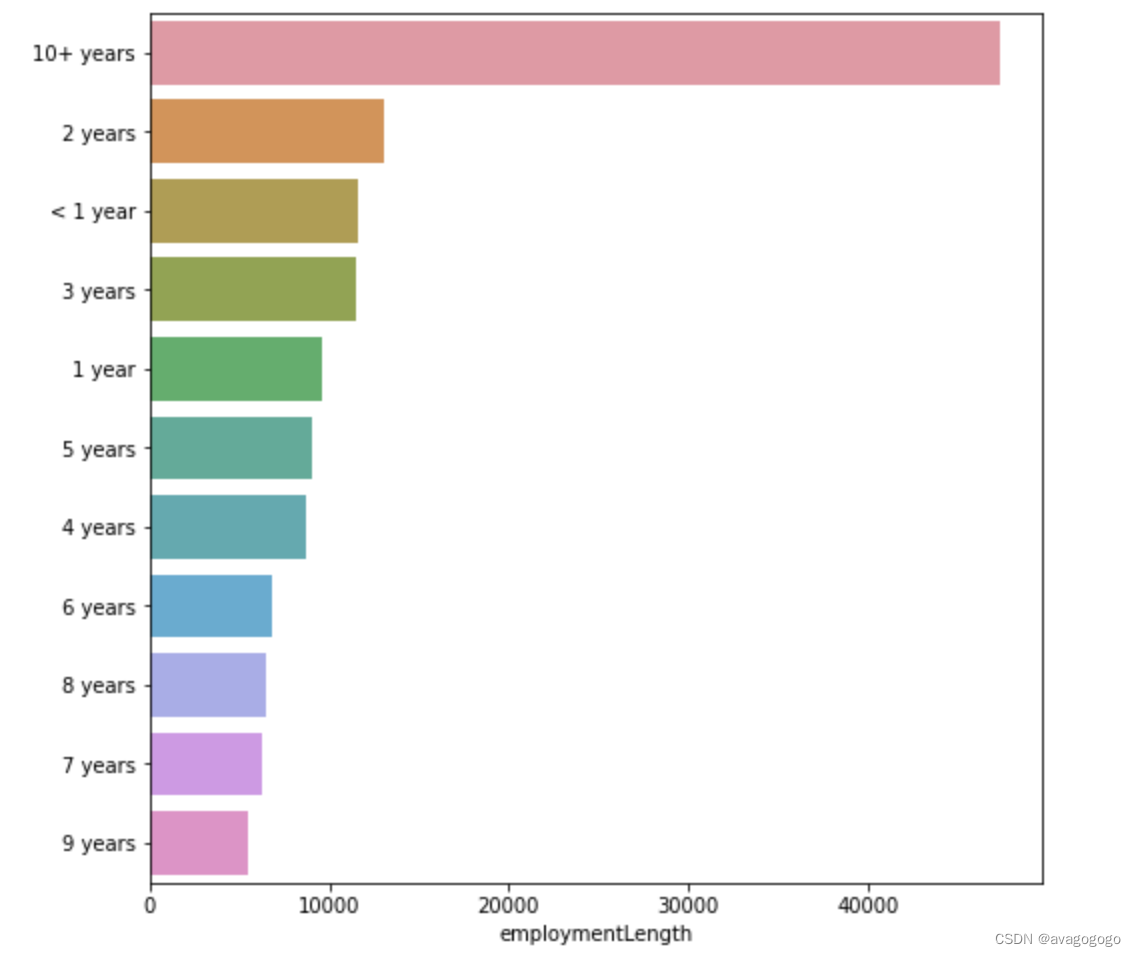
#单一变量分布可视化
plt.figure(figsize = (8,8))
sns.barplot(data_train["employmentLength"].value_counts(dropna = False)[:20],
data_train["employmentLength"].value_counts(dropna = False).keys()[:20])
plt.show()
 根据不同的y值可视化x某个特征分布
根据不同的y值可视化x某个特征分布
#首先查看类别型变量在不同y值上的分布
train_loan_fr = data_train.loc[data_train["isDefault"]==1]
train_loan_nofr = data_train.loc[data_train["isDefault"]==0]
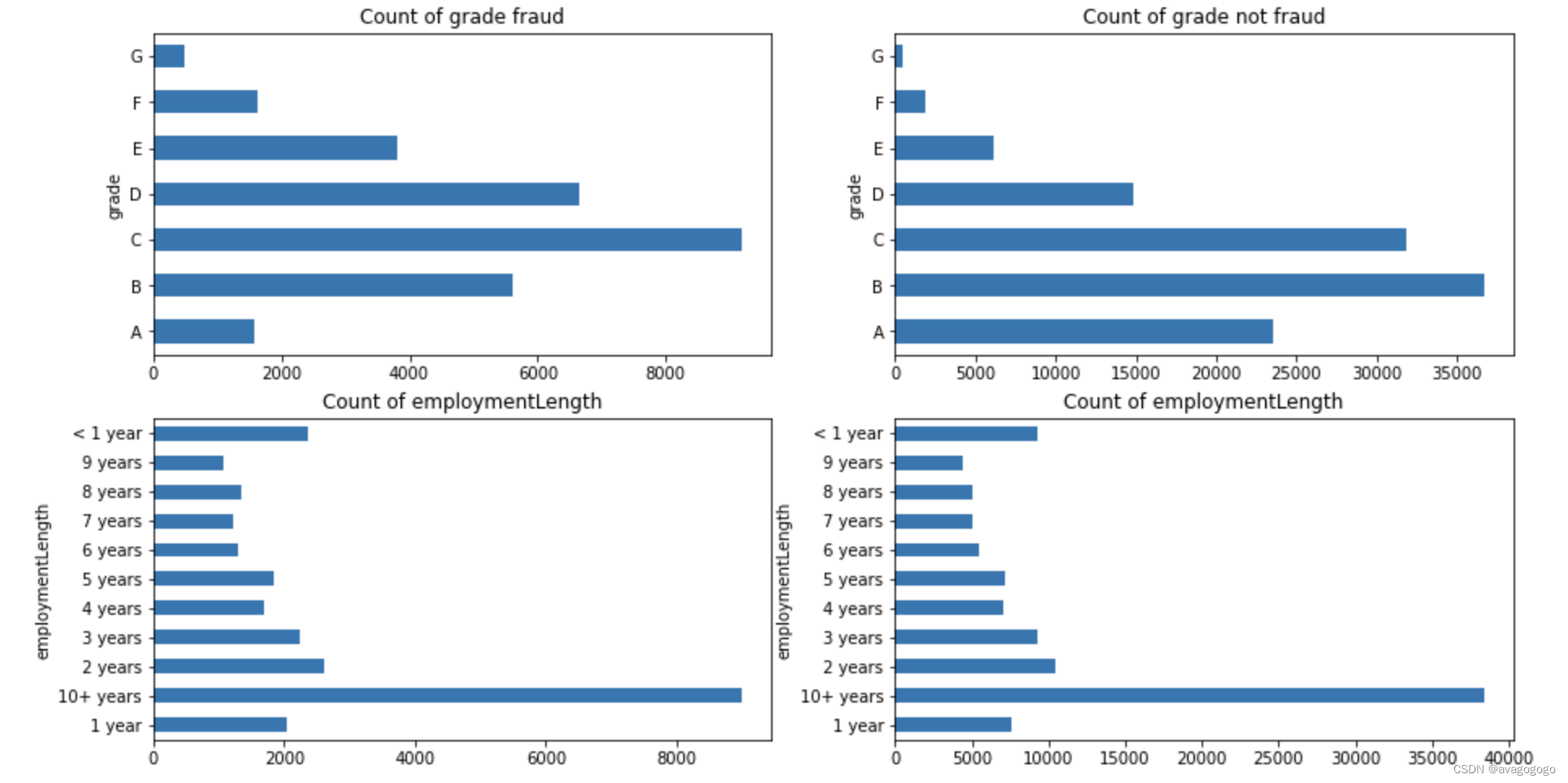
fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(2,2,figsize=(15,8))
train_loan_fr.groupby(["grade"])["grade"].count().plot(kind = 'barh',ax = ax1,title = 'Count of grade fraud')
train_loan_nofr.groupby("grade")["grade"].count().plot(kind= 'barh',ax=ax2,title = 'Count of grade not fraud')
train_loan_fr.groupby("employmentLength")["employmentLength"].count().plot(kind = "barh",ax= ax3,title = "Count of employmentLength")
train_loan_nofr.groupby("employmentLength")["employmentLength"].count().plot(kind = "barh",ax= ax4,title = "Count of employmentLength")
plt.show()
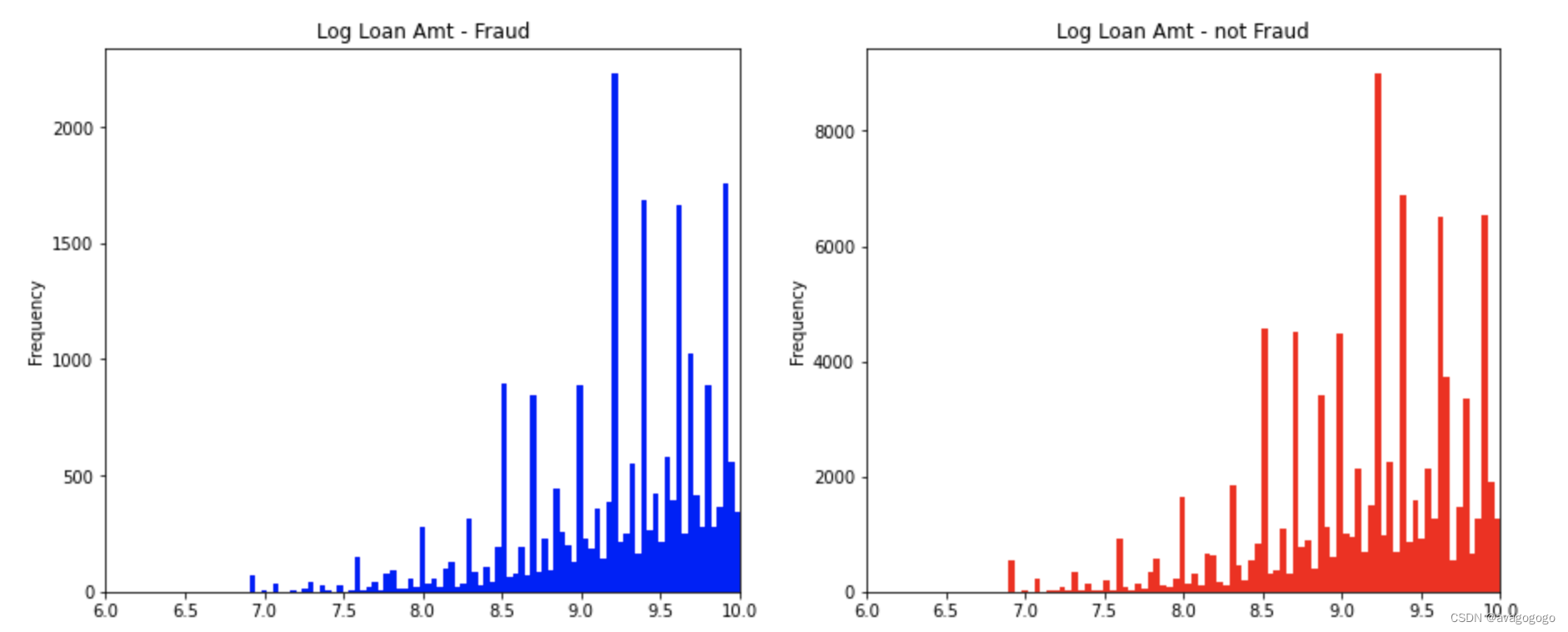
#其次是看连续性变量的趋势
fig,((ax1,ax2)) = plt.subplots(1,2,figsize= (15,6))
data_train.loc[data_train["isDefault"]==1]["loanAmnt"].apply(np.log)\
.plot(
kind = 'hist',
bins=100,
ax=ax1,
title = 'Log Loan Amt - Fraud',
color = 'b',
xlim = (6,10)
)
data_train.loc[data_train["isDefault"]==0]["loanAmnt"].apply(np.log)\
.plot(
kind = 'hist'
,bins = 100
,ax= ax2
,title = 'Log Loan Amt - not Fraud'
,color = 'r'
,xlim = (6,10)
)
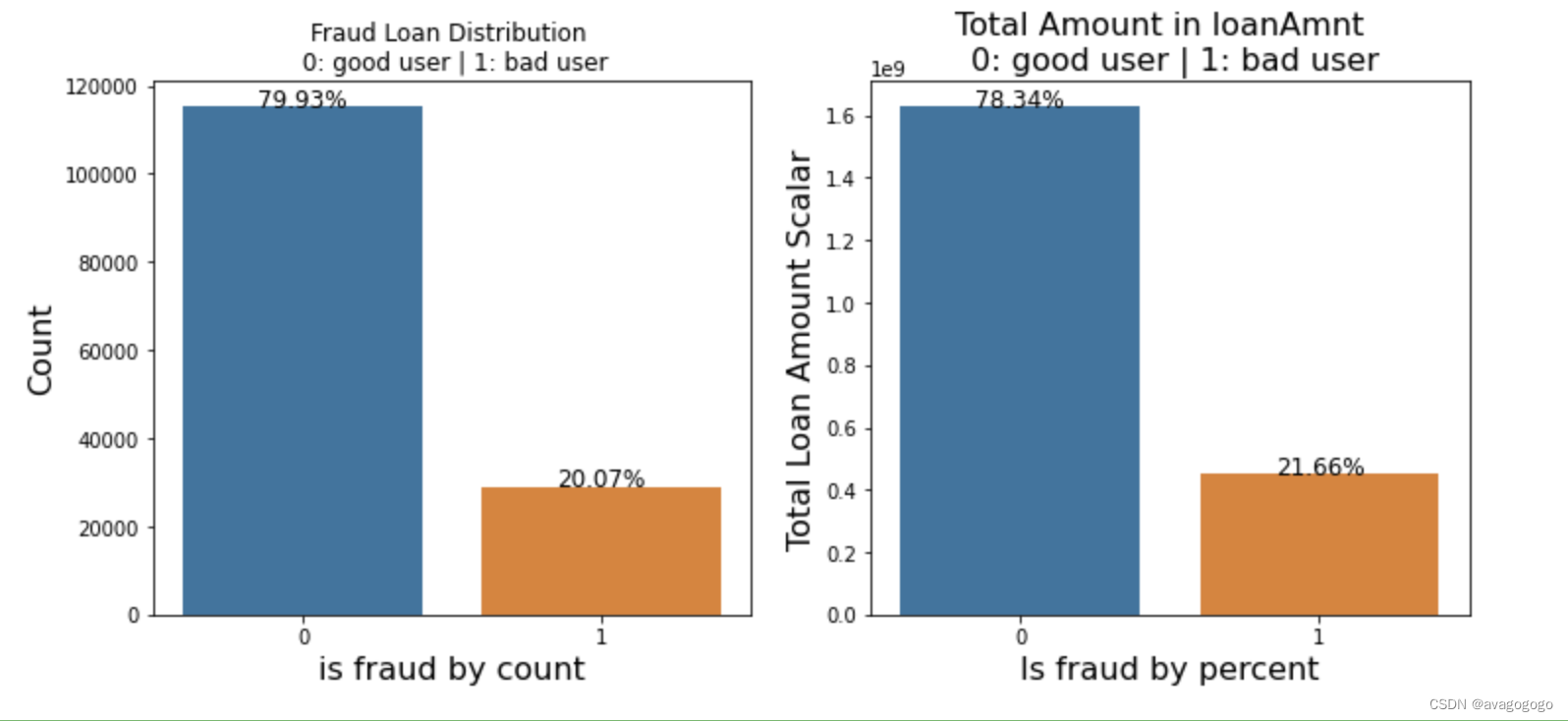
total = len(data_train)
total_amt = data_train.groupby(['isDefault'])['loanAmnt'].sum().sum()
plt.figure(figsize=(12,5))
plt.subplot(121)
plot_tr = sns.countplot(x= 'isDefault',data=data_train)
plot_tr.set_title("Fraud Loan Distribution \n 0: good user | 1: bad user")
plot_tr.set_xlabel("is fraud by count",fontsize =16)
plot_tr.set_ylabel("Count",fontsize = 16)
for p in plot_tr.patches:
height = p.get_height()
plot_tr.text(p.get_x()+p.get_width()/2.0,height,"{:1.2f}%".format(height/total*100),ha="center",fontsize = 12)
plt.subplot(122)
percent_amt = data_train.groupby(['isDefault'])['loanAmnt'].sum().reset_index()
plot_tr_2 = sns.barplot(x='isDefault',y='loanAmnt',data=percent_amt)
plot_tr_2.set_title('Total Amount in loanAmnt \n 0: good user | 1: bad user',fontsize=16)
plot_tr_2.set_xlabel("Is fraud by percent",fontsize = 16)
plot_tr_2.set_ylabel("Total Loan Amount Scalar",fontsize=16)
for p in plot_tr_2.patches:
height = p.get_height()
plot_tr_2.text(p.get_x()+p.get_width()/2.0,height,"{:1.2f}%".format(height/total_amt*100),ha="center",fontsize=12)















 1318
1318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









