







在《条件随机场(Conditional Random Field)简介》中我们了解了条件随机场的基本原理,但是通篇都是数学公式,对于奋战在一线的兄弟估计有点看不爽,并且里面对feature function仅仅只是一笔带过,这通常在实际应用中恰恰相反,一般工作应用在feature engineering上会大费周章,而在算法模型上只是简单套用。为了更好地掌握和运用CRF,本篇将带领大家解读CRF一个非常流行的实现——CRF++,是Taku Kudo于2005年用C++实现并开源。让我们一起来欣赏这优雅的工程实现:-),也希望通过本篇可以让您对CRF有更加深入的理解。
CRF++的使用方式
在了解一个工具是如何被练成之前,一般先了解它的使用方法,这样可以更快更友好地初步掌握工具的方方面面,为后面的深入理解打好基础。
和许多机器学习工具一样,CRF++的使用分为两个过程,一个是训练过程,一个是测试过程,我们先来照搬翻译官方的使用教程:
数据格式
先来看看工具需要的训练数据和测试数据的格式:
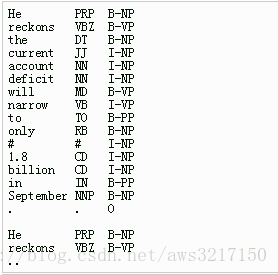
如上所示,”He reckons the current account deficit will narrow to only #1.8 billion in September .”代表一个训练句子
x
,而CRF++要求将这样的句子拆成每一个词一行并且是固定列数的数据,其中列除了原始输入,还可以包含一些其他信息,比如上面的例子第二列就包含了POS信息,最后一列是Label信息,也就是标准答案
特征模版
CRF++训练的时候,要求我们提供特征模版,什么是特征模版呢,先来看如下图片:

“%x[row, column]” 代表获得当前指向位置向上或向下偏移|row|行,并指向第column列的值。比如上图中,当前指向位置为 “the DT B-NP”,那么”%x[0,0]”代表获得当前指向偏移0行,第0列的值,也就是”the”,而”%x[0,1]”代表获得当前指向偏移0行,第1列的值,也就是”DT”,”%x[-2,1]”则代表获得当前指向向上偏移2行,第1列的值,也就是”PRP”,如此类推。
CRF++中主要有两种特征模版,Unigram和Bigram 模版,注意Unigram和Bigram是相对于输出序列而言,而不是相对于输入序列。对于”U01:%x[0,1]”这样一个模版,上面例子的输入数据会产生如下的特征函数:

假如输出序列的集合大小为:
L
,那么训练数据的每一行都会产生

这样组合下将会产生
N∗L∗L
个特征函数。
理论回顾
CRF++的实现理论基础都是依赖于Lafferty的原始论文,这和我们上一篇介绍的形式上稍有不同。这里我们简要回顾一下原始论文的阐述形式。
CRF是一种概率图模型,而一幅图可以由它的边和节点表达,也就是:
其中 V 是图的节点集合,
有同学可能会指出这和我们上一篇介绍的形式上有很大的差异!上一篇中我们对输入序列 x⃗ 和输出序列 y⃗ 建立模型如下:
其中我们并没有显示将边和节点区分开来,而只是写出了边的特征函数,因为从某种程度上边包含的信息已经涵盖了节点所拥有的信息,将两者统一起来可以有利于我们数学公式表达的方便性,另一方面,将边和节点进行单独讨论,从理论上可能有一点冗余,但是从实际效果中,节点信息可以充当一种backoff,起到一定的平滑效果(Smoothing)。
由于上述的形式改动,上一篇中我们推导的对数似然函数梯度求解公式也要相应地做一些修改,(因为CRF++的实现是最小化目标函数,而我们上一节推导的是最大化,为了保持一致,我们在前面加一个负号):
对图节点参数求导如下:
对于边参数求导如下:
注意到上述的 ψ 是我们上一篇定义的:
ϕ 是特征函数,节点特征函数一般由Unigram模板产生,边特征函数由Bigram模板自动产生, α , β 的计算用上一篇我们介绍的forward-backward算法既可高效求解。
CRF++
CRF++是一个比较小巧的工具,并且具有跨平台性,代码量也不大,程序分为两个大模块,分别是Encoder和Decoder,Encoder对应于训练阶段,而Decoder对应于测试或者使用阶段。和许多机器学习工具套路一样,Encoder会根据训练数据和模板文件,训练产生一个模型文件,然后Decoder利用模型文件来做对应的实际序列输出。接下来我们将着重介绍Encoder,也就是训练过程,只要您理解了Encoder,Decoder便是小菜一碟了:-)。
CRF++类设计
CRF++抽象并不多,代码也相对精简,逻辑上我们需要关注的类有如下:
- Encoder
- Decoder
- FeatureIndex
- Allocator
- FeatureCache
- Tagger
- Path
- Node
- CRFEncoderThread
下面我们逐一介绍,下面举到的具体训练例子,都来源于crf++源码中,example目录下的basenp例子。
Encoder
Encoder:作为训练的入口,负责组织各个成分协调运作,它对外只提供如下接口:

FeatureIndex
我们照着Encoder::learn函数接着往下看,除了一些参数校验,接下来定义了一个变量:
EncoderFeatureIndex feature_index;EncoderFeatureIndex继承自FeatureIndex,它负责将训练数据和模板文件转化为特征存储,并提供特征的索引。我们先来看看它到底维护了那些数据:

基本上FeatureIndex维护了权重,还有特征相关定义的信息,我们可以将它理解为算法的字典,需要什么定义信息都可以从它那里快速获得。
Allocator
代码紧接着出现了一个新面孔:
Allocator allocator(thread_num);它是算法的内存管理者,负责一切内存管理工作,这是C/C++程序员必须尽责的事情。同样的我们也来一睹它的风貌:

Tagger
继续往下读,主角不知不觉就登场了,所有具体的算法运算工作都由Tagger完成,CRF++每一个训练序列都由一个Tagger负责,也就是说一个Tagger只负责一个训练例子,这也是为什么代码接下来定义了一个tagger集合:
std::vector<TaggerImpl* > x;//这里吐槽一下命名同样,我们来看看Tagger具体维护了什么信息:

代码紧接着便从训练文件和模板文件中将标签集合和模板定义读入到featureIndex中存储:
feature_index.open(templfile, trainfile)再接着进入一个循环,这里开始读取训练数据,将训练数据文件中,每一个序列抽出来,分配给一个Tagger,由Tagger掌握标准答案信息,具体如下:

FeatureCache
上面代码中,tagger调用了一个shrink方法,从名字上看不出什么名堂,进去一看里面主要操作是调用了:
feature_index_->buildFeatures(this)其具体操作如下:

这样操作之后,实际的FeatureCache就是如下的存储结构:

回到Encoder::learn方法,我们接着往下看,代码接下来调用了
feature_index.shrink(freq, &allocator);作用是将模板提取出来的特征中,计数少于freq的特征删除,此时真正做到“shrink”。
有了特征数,我们可以真正为特征权重数组分配内存,并设置到featureIndex里面:
std::vector <double> alpha(feature_index.size());
std::fill(alpha.begin(), alpha.end(), 0.0);
feature_index.set_alpha(&alpha[0]);有了上述准备工作,算法终于可以进入主流程了,接下来是算法选择,我们就拿CRF_L2来分析即可。
CRFEncoderThread
普通的CRF算法,对于每一个训练数据计算梯度时候,可以完全并行,并不涉及到资源共享问题,那么很自然,CRF++支持多线程训练操作,CRF++根据用户指定的线程数,将训练数据均匀分配到每一个Tagger中,然后又均匀地为每一个线程分配一定量的Tagger。其具体内存架构如下所示:

CRFEncoderThread代码并不多,我们同样来了解它维护的信息:

主线程为线程分配好任务之后,接下来就交由线程自己去跑,每个线程跑完之后,再将各个线程的信息汇总,获得模型总的目标值,梯度,然后交由给L-BFGS进行优化参数就完成了参数更新任务,然后重复迭代这个过程,直到收敛。
Tagger梯度求解
整个算法的高潮部分就落在Tagger中的gradient方法了!我们先看其定义:
double TaggerImpl::gradient(double *expected);该方法运行后,会将梯度信息存储于expected中,并返回目标值,也就是负对数似然函数目标值。
buildLattice
进入gradient方法,一开始便调用了buildLattice方法,而buildLattice中又执行了:
feature_index_->rebuildFeatures(this);我们具体来看看rebuildFeatures干了什么。在rebuildFeatures中,其实它就干了一件事情,将训练序列构建成一个网络图:

比如basenp里面的一个小片段“Confidence in the pound …”会构造如上网格图,圆圈为节点Node,边即是Path。我们依次来看,首先看看Node维护了什么信息:

再来看看Path维护了什么信息:

buildLattice接下来的工作就是将构建好的网络图,计算每一个节点的cost,每一条边的cost,这样就做好前提准备工作了。
forwardbackward
构建完网格图之后,程序便可以跑forwardbackward算法了,由于上面的准备工作,forwardbackward跑起来比较简单:

我们窥探一下calcAlpha具体细节:

calcBeta计算类似,便不再赘述。
计算了
α
,
β
各个值还有常数
Z
之后,程序可以真正计算梯度和目标值了,我们接着往下看。
计算梯度与目标值
程序接下来遍历网格所有节点,并调用calcExpectation方法:

将expected数组填充完相应的边缘概率之后,相当于我们计算完了梯度的一部分,由上面的公式推导得知,我们必须减去实际的标准答案计数,由于特征函数

结语
至此我们已经剖析了CRF++训练阶段的整个流程,对于测试阶段的viterbi算法,其实非常简单,基本上照着文章中介绍的算法即可得出。CRF++还支持NBest输出,其原理是利用
viterbi A*,该算法在《Iterative Viterbi A* Algorithm for K-Best Sequential Decoding》中有详细介绍,具体可以参考CRF++中的实现,这里就不再讨论。
参考引用
CRF++: Yet Another CRF toolkit
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
Iterative Viterbi A* Algorithm for K-Best Sequential Decoding

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









