







本文作者
Pavan Kumar Rao Navule
亚马逊云科技解决方案架构师
Sudhanshu Hate
亚马逊云科技首席人工智能与机器学习专家
随着生成式 AI 应用被迅速采用,相关技术的应用程序需要及时响应以减少感知延迟并提高吞吐量。基础模型(FM)通常在大规模语料库上进行预训练,参数规模从数百万到数十亿甚至更多。大型语言模型(LLM)是 FM 的一种类型,可生成作为用户推理的响应文本。使用不同的推理参数配置对这些模型进行推理可能会导致延迟不一致。这种不一致可能是因为您期望从模型获得的响应标记数量不同,或者是因为模型部署在不同类型的加速器上。
无论哪种情况,您都可以采用响应流式传输的方法进行推理,而不是等待完整响应。这种方法会立即发送生成的信息块,从而创建交互式体验,让您实时查看流式传输的部分响应,而不是延迟的完整响应。
随着 Amazon SageMaker 实时推理已支持响应流式传输,您可以在使用 Amazon SageMaker 实时推理时持续将推理响应流式传输回客户端。该解决方案将帮助您为各种生成式 AI 应用程序(如聊天机器人、虚拟助手和音乐生成器)构建交互式体验。本文将向您展示如何在推理 Llama 2 模型时实现更快的响应时间(以首字节时间 TTFB 为准)并减少整体感知延迟。
为了实现该解决方案,我们使用 Amazon SageMaker,这是一项全面托管的服务,可为任何用例准备数据、构建、训练和部署机器学习(ML)模型,并提供完全托管的基础设施、工具和工作流程。有关 Amazon SageMaker 提供的各种部署选项的更多信息,请参阅 Amazon SageMaker 模型托管常见问题解答。让我们了解如何使用实时推理和响应流式传输来解决延迟问题。

基于亚马逊云科技的
生成式AI构建
扫码了解更多

响应流式传输
扫码了解更多

Amazon SageMaker
扫码了解更多

模型托管常见问题解答
扫码了解更多
左右滑动查看更多
解决方案概述
因为我们希望解决与大型语言模型实时推理相关的上述延迟问题,让我们首先了解如何利用响应流式传输支持来进行 Llama 2 的实时推理。但是,任何大型语言模型都可以利用实时推理的响应流式传输支持。
Llama 2 是一系列预训练和微调的生成式文本模型,参数规模从 70 亿到 700 亿不等。Llama 2 模型是仅有解码器架构的自回归模型。当提供提示和推理参数时,Llama 2 模型能够生成文本响应。这些模型可用于翻译、摘要、问答和聊天。
在本文中,我们将在 Amazon SageMaker 上部署 Llama 2 Chat 模型 meta-llama/Llama-2-13b-chat-hf,用于实时推理和响应流式传输。
在将模型部署到 Amazon SageMaker 端点时,您可以使用为流行开源库提供的专门的 Amazon DLC(深度学习容器)镜像对模型进行容器化。Llama 2 模型是文本生成模型;您可以使用由 Hugging Face 文本生成推理(TGI)提供支持的 Amazon SageMaker 上的 Hugging Face LLM 推理容器,或者使用 Amazon DLC 的 大模型推理(LMI)。
在本文中,我们使用 DLC 在 Amazon SageMaker Hosting 上部署 Llama 2 13B Chat 模型,用于由 G5 实例支持的实时推理。G5 实例是针对图形密集型应用程序和机器学习推理的高性能 GPU 实例。您也可以使用受支持的实例类型 p4d、p3、g5 和 g4dn,并根据实例配置进行适当更改。

Amaozn 深度学习容器
扫码了解更多

文本生成推理
扫码了解更多

Hugging Face LLM 推理容器
扫码了解更多

大模型推理
扫码了解更多
左右滑动查看更多
先决条件
要实现此解决方案,您应具备以下条件:
一个亚马逊云科技账户,并拥有 Amazon Identity and Access Management(IAM)角色的权限来管理作为解决方案一部分创建的资源。
如果这是您第一次使用 Amazon SageMaker Studio,您首先需要创建一个 Amazon SageMaker Domain。
一个 Hugging Face 账户。如果您还没有账户,请注册并使用您的电子邮件。
为了无缝访问 Hugging Face 上可用的模型, 以用于微调和推理,您应该拥有一个 Hugging Face 账户来获取读取访问令牌。注册 Hugging Face 账户后,登录并访问 https://huggingface.co/settings/tokens 创建一个读取访问令牌。
使用与您注册 Hugging Face 时相同的电子邮件 ID 访问 Llama 2。
Llama 模型的使用受 Meta 许可证约束。要下载模型权重和标记器,请求访问 Llama 并接受他们的许可协议。
获得访问权限后(通常在几天内),您将收到一封电子邮件确认。在本例中,我们使用模型 Llama-2-13b-chat-hf,但您也应该能够访问其他变种模型。

Amazon Identity and Access Management
扫码了解更多

Amazon SageMaker Studio
扫码了解更多

请求访问 Llama
扫码了解更多
左右滑动查看更多
方法 1:Hugging Face TGI
在本节中,我们向您展示如何使用 Hugging Face TGI 将 meta-llama/Llama-2-13b-chat-hf 模型部署到支持响应流式传输的 Amazon SageMaker 实时端点。下表概述了此部署的规格。

部署模型
首先,您需要检索要部署的 LLM 的基础镜像。然后在基础镜像上构建模型。最后,将模型部署到 ML 实例,以便在 Amazon SageMaker Hosting 上进行实时推理。
让我们观察如何以编程方式实现部署。为简洁起见,本节仅讨论有助于部署步骤的代码。完整的部署源代码可在笔记本 llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb 中找到。
通过预构建的 Amazon SageMaker DLC 检索由 TGI 支持的最新 Hugging Face LLM DLC。您将使用此镜像在 Amazon SageMaker 上部署 meta-llama/Llama-2-13b-chat-hf 模型。请参阅以下代码:
from sagemaker.huggingface import get_huggingface_llm_image_uri
# 检索llm镜像uri
llm_image = get_huggingface_llm_image_uri(
"huggingface",
version="1.0.3"
)左右滑动查看更多
使用如下定义的配置参数定义模型的环境:
instance_type = "ml.g5.12xlarge"
number_of_gpu = 4
config = {
'HF_MODEL_ID': "meta-llama/Llama-2-13b-chat-hf", # 来自hf.co/models的模型ID
'SM_NUM_GPUS': json.dumps(number_of_gpu), # 每个副本使用的GPU数量
'MAX_INPUT_LENGTH': json.dumps(2048), # 输入文本的最大长度
'MAX_TOTAL_TOKENS': json.dumps(4096), # 生成的最大长度(包括输入文本)
'MAX_BATCH_TOTAL_TOKENS': json.dumps(8192), # 限制并行生成时可处理的令牌数
'HUGGING_FACE_HUB_TOKEN': "<YOUR_HUGGING_FACE_READ_ACCESS_TOKEN>"
}左右滑动查看更多
将配置参数 HUGGING_FACE_HUB_TOKEN 的值替换为您从 Hugging Face 个人资料中获取的令牌值,如本文先决条件部分所述。在配置中,您将每个模型副本使用的 GPU 数量定义为 4 SM_NUM_GPUS。然后,您可以在配备 4 个 GPU 的 ml.g5.12xlarge 实例上部署 meta-llama/Llama-2-13b-chat-hf 模型。
现在,您可以使用上述环境配置构建 HuggingFaceModel 的实例:
llm_model = HuggingFaceModel(
role=role,
image_uri=llm_image,
env=config
)最后,通过为模型上的 deploy 方法提供参数值(如 endpoint_name、initial_instance_count 和 instance_type)来部署模型:
llm = llm_model.deploy(
endpoint_name=endpoint_name,
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout,
)左右滑动查看更多
执行推理(Perform inference)
很好,Hugging Face TGI DLC 自带响应流式传输功能,无需对模型进行任何定制或代码更改。如果您使用 Boto3,可以使用 invoke_endpoint_with_response_stream,如果使用 Amazon SageMaker Python SDK 进行编程,则可以使用 InvokeEndpointWithResponseStream。
Amazon SageMaker 的 InvokeEndpointWithResponseStream API 允许开发人员从 Amazon SageMaker 模型流式传输响应,这可以通过减少感知延迟来提高客户满意度。这对于使用生成式 AI 模型构建的应用程序尤其重要,因为立即处理比等待整个响应更重要。
在此示例中,我们使用 Boto3 对模型进行推理,并使用 Amazon SageMaker API invoke_endpoint_with_response_stream 如下:
def get_realtime_response_stream(sagemaker_runtime, endpoint_name, payload):
response_stream = sagemaker_runtime.invoke_endpoint_with_response_stream(
EndpointName=endpoint_name,
Body=json.dumps(payload),
ContentType="application/json",
CustomAttributes='accept_eula=false'
)
return response_stream左右滑动查看更多
参数 CustomAttributes 设置为值 accept_eula=false。必须将 accept_eula 参数设置为 true 才能成功获取 Llama 2 模型的响应。成功调用 invoke_endpoint_with_response_stream 后,该方法将返回字节流响应流。
下图说明了此工作流程。
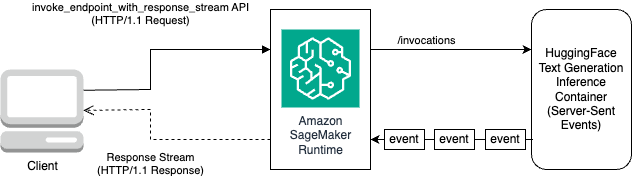
您需要一个迭代器来循环字节流并将其解析为可读文本。LineIterator 实现可在 llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py 中找到。现在您可以准备提示和说明,以便在对模型进行推理时将它们用作有效负载。
准备提示和说明
在此步骤中,您为 LLM 准备提示和说明。要提示 Llama 2,您应该有以下提示模板:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]您以编程方式构建提示模板,该模板在 build_llama2_prompt 方法中定义,与上述提示模板一致。然后,根据用例定义说明。在本例中,我们指示模型为营销活动生成一封电子邮件,如 get_instructions 方法所述。这些方法的代码位于笔记本中。将说明与要执行的任务 user_ask_1 结合起来构建,如下所示:

代码笔记本
扫码了解更多
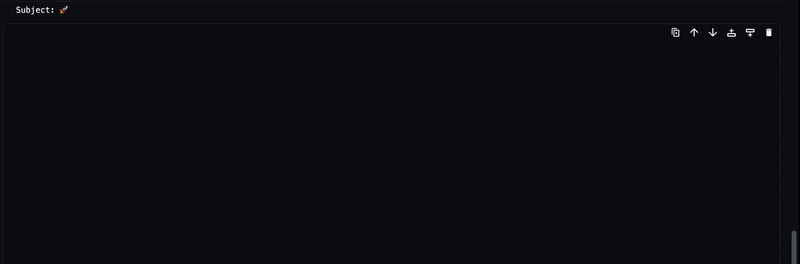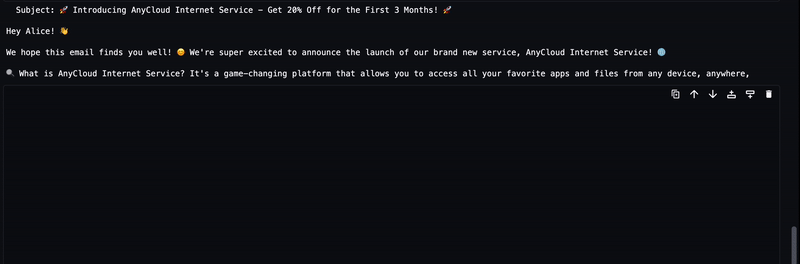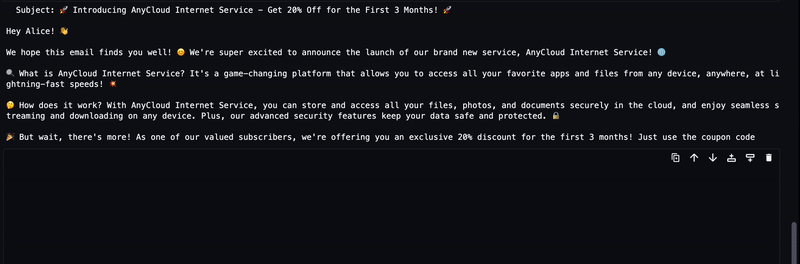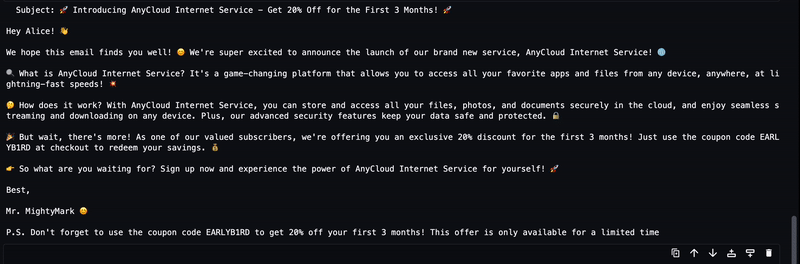
user_ask_1 = f'''
AnyCompany recently announced new service launch named AnyCloud Internet Service.
Write a short email about the product launch with Call to action to Alice Smith, whose email is alice.smith@example.com
Mention the Coupon Code: EARLYB1RD to get 20% for 1st 3 months.
'''
instructions = get_instructions(user_ask_1)
prompt = build_llama2_prompt(instructions)左右滑动查看更多
我们将说明传递给 build_llama2_prompt 以根据提示模板生成提示。
nference_params = {
"do_sample": True,
"top_p": 0.6,
"temperature": 0.9,
"top_k": 50,
"max_new_tokens": 512,
"repetition_penalty": 1.03,
"stop": ["</s>"],
"return_full_text": False
}
payload = {
"inputs": prompt,
"parameters": inference_params,
"stream": True ## <-- 启用响应流式传输
}左右滑动查看更多
我们将推理参数与提示一起使用键 stream(值为 True)形成最终有效负载。将有效负载发送到 get_realtime_response_stream,它将用于调用支持响应流式传输的端点:
resp = get_realtime_response_stream(sagemaker_runtime, endpoint_name, payload)
print_response_stream(resp)
LLM 生成的文本将流式传输到输出,如下动画所示。
方法 2:使用 DJL Serving 的 LMI
在本节中,我们演示如何使用 DJL Serving 的 LMI 将 meta-llama/Llama-2-13b-chat-hf 模型部署到支持响应流式传输的 Amazon SageMaker 实时端点。下表概述了此部署的规格。

您首先需要下载模型并将其存储在 Amazon Simple Storage Service (Amazon S3) 中。然后在 serving.properties 文件中指定模型在 S3 上的前缀 URI。接下来,您需要获取要部署的大型语言模型的基础镜像,之后在基础镜像上构建模型。最后,将模型部署到 Amazon SageMaker Hosting 的 ML 实例上,以进行实时推理。
让我们观察如何以编程方式实现上述部署步骤。为了简洁起见,本节只详细介绍了有助于部署步骤的代码。此部署的完整源代码可在笔记本 llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb 中找到。

Amazon Simple Storage Service (Amazon S3)
扫码了解更多

代码笔记本2
扫码了解更多
左右滑动查看更多
从 Hugging Face 下载模型快照
并将模型工件上传到 Amazon S3
根据上述先决条件,在 Amazon SageMaker 笔记本实例上下载模型,然后将其上传到 S3 存储桶以进一步部署:
model_name = 'meta-llama/Llama-2-13b-chat-hf'
# 仅下载 pytorch 检查点文件
allow_patterns = ["*.json", "*.txt", "*.model", "*.safetensors", "*.bin", "*.chk", "*.pth"]
# 下载模型快照
model_download_path = snapshot_download(
repo_id=model_name,
cache_dir=local_model_path,
allow_patterns=allow_patterns,
token='<YOUR_HUGGING_FACE_READ_ACCESS_TOKEN>'
)左右滑动查看更多
注意,即使您没有提供有效的访问令牌,模型也会下载。但是,当您部署这样的模型时,模型服务将无法成功。因此,建议将替换为从您的 Hugging Face 个人资料中获取的令牌值,如先决条件中所详述的那样,用于 token 参数。在本文中,我们使用在 Hugging Face 上标识的 Llama 2 官方模型名称 meta-llama/Llama-2-13b-chat-hf。运行上述代码后,未压缩的模型将被下载到 local_model_path。
将文件上传到 Amazon S3 并获取 URI,稍后将在 serving.properties 中使用该 URI。
您将使用 DJL Serving 在 LMI 容器镜像上打包 meta-llama/Llama-2-13b-chat-hf 模型,并通过 serving.properties 指定配置。然后,您将在 Amazon SageMaker ML 实例 ml.g5.12xlarge 上部署打包在容器镜像上的模型及模型工件。接下来,您将使用此 ML 实例进行 Amazon SageMaker 托管,以实现实时推理。
为 DJL Serving 准备模型工件
通过创建 serving.properties 配置文件来准备模型工件:
%%writefile chat_llama2_13b_hf/serving.properties
engine = MPI
option.entryPoint=djl_python.huggingface
option.tensor_parallel_degree=4
option.low_cpu_mem_usage=TRUE
option.rolling_batch=lmi-dist
option.max_rolling_batch_size=64
option.model_loading_timeout=900
option.model_id={{model_id}}
option.paged_attention=true左右滑动查看更多
我们在此配置文件中使用以下设置:
engine – 这指定了DJL要使用的运行时引擎。可能的值包括 Python、DeepSpeed、FasterTransformer 和 MPI。在这种情况下,我们将其设置为 MPI。模型并行化和推理(MPI)可以跨所有可用的 GPU 划分模型,从而加速推理。
entryPoint – 此选项指定您希望使用 DJL Serving 提供的哪个处理程序。可能的值包括 djl_python.huggingface、djl_python.deepspeed 和 djl_python.stable-diffusion。我们使用 djl_python.huggingface 来支持 Hugging Face Accelerate。
tensor_parallel_degree – 此选项指定对模型执行的张量并行分区数量。您可以将其设置为 Accelerate 需要在其上划分模型的 GPU 设备数量。此参数还控制了 DJL 服务运行时将启动的每个模型的工作线程数量。例如,如果我们有一台 4 卡 GPU 机器并创建了四个分区,那么我们将有一个工作线程用于为每个模型提供服务请求。
low_cpu_mem_usage – 这可以在加载模型时减少 CPU 内存使用量。我们建议将其设置为 TRUE。
rolling_batch – 这使用受支持的策略之一启用迭代级别的批处理。值包括 auto、scheduler 和 lmi-dist。我们使用 lmi-dist 为 Llama 2 启用连续批处理。
max_rolling_batch_size – 这限制了连续批处理中并发请求的数量。默认值为 32。
model_id – 您应该将 {{model_id}} 替换为托管在 Hugging Face 上的模型存储库中的预训练模型的模型 ID,或者替换为指向模型工件的 S3 路径。
更多配置选项可以在配置和设置中找到。

模型存储库
扫码了解更多

配置和设置
扫码了解更多
左右滑动查看更多
由于 DJL Serving 期望模型工件被打包并格式化为 .tar 文件,因此运行以下代码片段来压缩并将 .tar 文件上传到 Amazon S3:
s3_code_prefix = f"{s3_prefix}/code" # 存放代码工件的存储桶内文件夹
s3_code_artifact = sess.upload_data("model.tar.gz", bucket, s3_code_prefix)左右滑动查看更多
检索带有 DJL Serving 的
最新 LMI 容器镜像
接下来,您将使用 Amazon SageMaker 提供的 LMI DLCs 来部署模型。使用以下代码以编程方式检索 djl-deepspeed 容器的 Amazon SageMaker 镜像 URI:
from sagemaker import image_uris
inference_image_uri = image_uris.retrieve(
framework="djl-deepspeed", region=region, version="0.25.0"
)左右滑动查看更多
您可以使用上述镜像在 Amazon SageMaker 上部署 meta-llama/Llama-2-13b-chat-hf 模型。现在您可以继续创建模型了。
创建模型
您可以使用 inference_image_uri 创建模型容器,并使用位于 S3 URI s3_code_artifact 处的模型服务代码:
from sagemaker.utils import name_from_base
model_name = name_from_base(f"Llama-2-13b-chat-lmi-streaming")
create_model_response = sm_client.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer={
"Image": inference_image_uri,
"ModelDataUrl": s3_code_artifact,
"Environment": {"MODEL_LOADING_TIMEOUT": "3600"},
},
)左右滑动查看更多
现在您可以为端点配置创建模型配置,其中包含所有详细信息。
创建模型配置
使用以下代码为由 model_name 标识的模型创建模型配置:
endpoint_config_name = f"{model_name}-config"
endpoint_name = name_from_base(model_name)
endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "variant1",
"ModelName": model_name,
"InstanceType": "ml.g5.12xlarge",
"InitialInstanceCount": 1,
"ModelDataDownloadTimeoutInSeconds": 3600,
"ContainerStartupHealthCheckTimeoutInSeconds": 3600,
},
],
)左右滑动查看更多
模型配置为 ProductionVariants 参数 InstanceType 定义了 ML 实例 ml.g5.12xlarge。您还使用与之前创建模型时相同的名称提供 ModelName,从而在模型和端点配置之间建立关系。
现在您已经定义了模型和模型配置,就可以创建 Amazon SageMaker 端点了。
创建 Amazon SageMaker 端点
使用以下代码片段创建端点以部署模型:
create_endpoint_response = sm_client.create_endpoint(
EndpointName=f"{endpoint_name}", EndpointConfigName=endpoint_config_name
)左右滑动查看更多
您可以使用以下代码片段查看部署进度:
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]左右滑动查看更多
部署成功后,端点状态将为 InService。现在端点已准备就绪,让我们执行响应流式传输推理。
实时推理与响应流式传输
正如我们在之前的 Hugging Face TGI 方法中所涉及的,您可以使用相同的方法 get_realtime_response_stream 从Amazon SageMaker 端点调用响应流式传输。使用 LMI 方法进行推理的代码位于 llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb 笔记本中。LineIterator 的实现位于 llama-2-lmi/utils/LineIterator.py。请注意,在 LMI 容器上部署的 Llama 2 Chat 模型的 LineIterator 与 Hugging Face TGI 部分中引用的 LineIterator 不同。LineIterator 循环遍历使用 djl-deepspeed 版本 0.25.0 推理的 Llama 2 Chat 模型的字节流。以下辅助函数将解析通过 invoke_endpoint_with_response_stream API 发出的推理请求收到的响应流:

代码笔记本3
扫码了解更多

实现位置
扫码了解更多
左右滑动查看更多
from utils.LineIterator import LineIterator
def print_response_stream(response_stream):
event_stream = response_stream.get('Body')
for line in LineIterator(event_stream):
print(line, end='')左右滑动查看更多
前面的方法以人类可读的格式打印由 LineIterator 读取的数据流。
让我们探讨如何准备提示和说明,以便在推理模型时将它们用作有效负载。
由于您在 Hugging Face TGI 和 LMI 中推理相同的模型,因此准备提示和说明的过程是相同的。因此,您可以使用方法 get_instructions 和 build_llama2_prompt 进行推理。
get_instructions 方法返回说明。根据 user_ask_2 中详述的要执行的任务,构建结合说明的提示,如下所示:
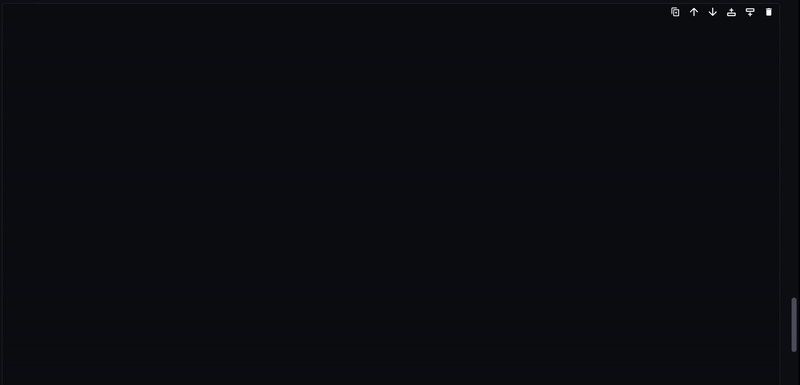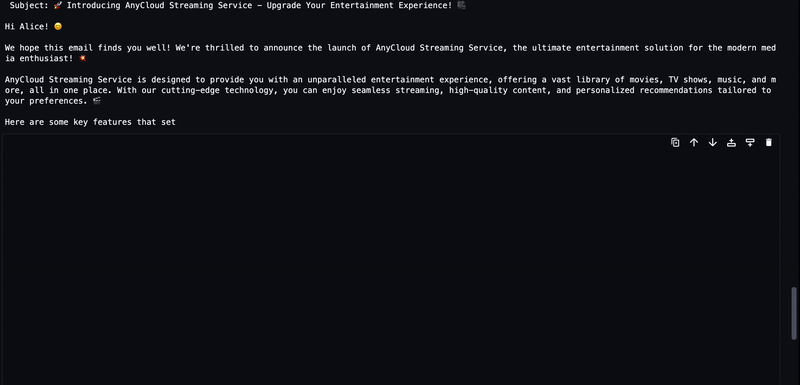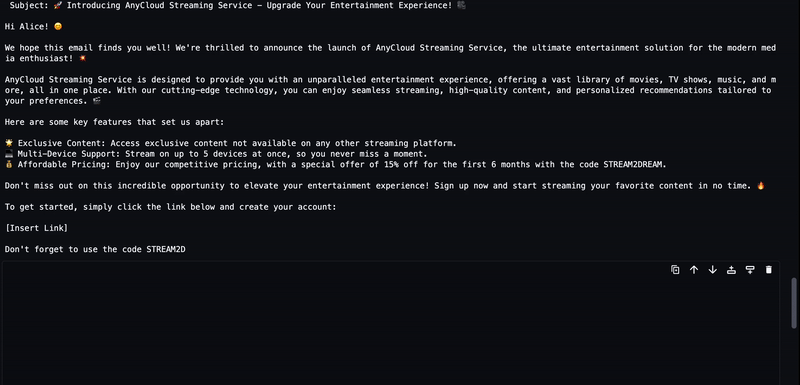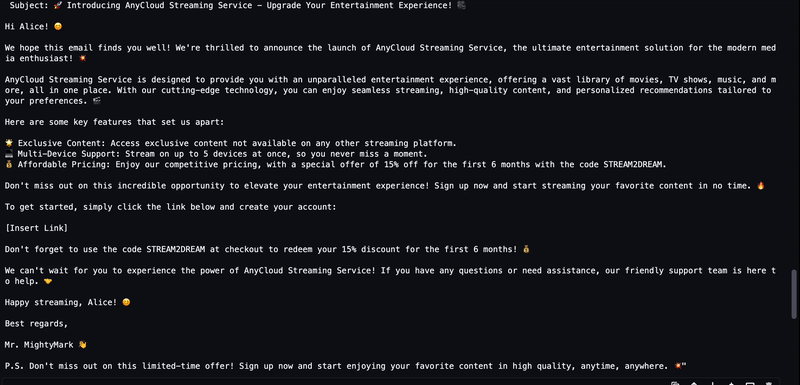
user_ask_2 = f'''
AnyCompany recently announced new service launch named AnyCloud Streaming Service.
Write a short email about the product launch with Call to action to Alice Smith, whose email is alice.smith@example.com
Mention the Coupon Code: STREAM2DREAM to get 15% for 1st 6 months.
'''
instructions = get_instructions(user_ask_2)
prompt = build_llama2_prompt(instructions)左右滑动查看更多
根据 build_llama2_prompt 生成的提示模板,传递说明以构建提示:
inference_params = {
"do_sample": True,
"top_p": 0.6,
"temperature": 0.9,
"top_k": 50,
"max_new_tokens": 512,
"return_full_text": False,
}
payload = {
"inputs": prompt,
"parameters": inference_params
}我们将推理参数与提示结合,形成最终有效负载。然后您将有效负载发送到 get_realtime_response_stream,用于调用具有响应流式传输的端点:
resp = get_realtime_response_stream(sagemaker_runtime, endpoint_name, payload)
print_response_stream(resp)左右滑动查看更多
LLM 生成的文本将被流式传输到输出,如下动画所示。
清理
为避免产生不必要的费用,请使用亚马逊云科技管理控制台删除在运行本文中提到的方法时创建的端点及其关联资源。对于两种部署方法,请执行以下清理例程:
import boto3
sm_client = boto3.client('sagemaker')
endpoint_name="<SageMaker_Real-time_Endpoint_Name>"
endpoint = sm_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_config_name = endpoint['EndpointConfigName']
endpoint_config = sm_client.describe_endpoint_config(EndpointConfigName=endpoint_config_name)
model_name = endpoint_config['ProductionVariants'][0]['ModelName']
print(f"""
About to delete the following sagemaker resources:
Endpoint: {endpoint_name}
Endpoint Config: {endpoint_config_name}
Model: {model_name}
""")
# delete endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# delete endpoint config
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# delete model
sm_client.delete_model(ModelName=model_name)左右滑动查看更多

亚马逊云科技控制台
扫码了解更多
将变量 endpoint_name 中的替换为实际端点。
对于第二种方法,我们将模型和代码工件存储在 Amazon S3 上。您可以使用以下代码清理 S3 存储桶:
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(bucket)
s3_bucket.objects.filter(Prefix=s3_prefix).delete()左右滑动查看更多
结论
在本文中,我们讨论了响应令牌数量的变化或不同的推理参数如何影响与 LLM 相关的延迟。我们展示了如何借助响应流式传输来解决这个问题。然后,我们确定了使用 Amazon DLCs(LMI 和 Hugging Face TGI)部署和推理 Llama 2 Chat 模型的两种方法。
您现在应该了解流式响应的重要性以及它如何减少感知延迟。流式响应可以改善用户体验,否则您将不得不等待 LLM 构建整个响应。此外,使用响应流式传输部署 Llama 2 Chat 模型可以改善用户体验并让您的客户满意。
您可以参考如下信息,其中涵盖了其他 Llama 2 模型变体的部署。

代码部署示意
扫码了解更多


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容


















 9439
9439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









