







ClickHouse 介绍
ClickHouse 是⼀个⽤于联机分析(OLAP)的列式数据库管理系统(DBMS)。根据其官⽅⽹站介绍,ClickHouse 作为⼀款⾼性能列式分析数据库,通过列式存储、向量化执行、压缩编码、分布式查询处理等手段实现了出色的写和查询吞吐能力、低延迟、高可扩展性。适⽤于⼤规模实时数据分析、事件⽇志处理、在线分析等应⽤场景。
ClickHouse 实时数据摄取
在许多业务场景下,如⼴告推荐、金融交易、⽹络监控、⽇志分析等,都对数据分析有很强的实时性需求。ClickHouse 作为具有实时数据摄⼊能⼒的⾯向 OLAP 的分析型数据库,实时数据摄取与分析是其重要应⽤场景之⼀。
在这篇⽂章中,我们会介绍通过 Amazon MSK、Amazon MSK Connect ClickHouse Kafka Connector 以及 Amazon Glue Schema Registry 来搭建端到端的全托管⽆服务器架构的实时数据摄取能⼒,并且通过 ClickHouse 与 Amazon S3 的集成来降低海量实时数据存储的成本。
整体架构
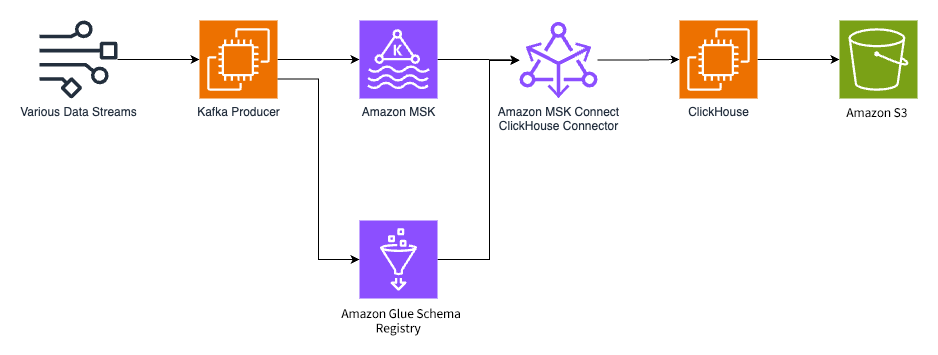
在整体架构中,我们要求数据⽣产者从数据源获取数据与 schema,并将 schema(Apache Avro 格式)注册到 Amazon Glue Schema Registry 中,然后将带有 schema 信息的数据发送到 Amazon MSK 中。
在数据消费端,我们在 ClickHouse Kafka Connector 中增加了对于 Amazon Glue Schema Registry 以及 Apache Avro 格式的⽀持,并将其部署在 Amazon MSK Connect 上。
ClickHouse Connector 从 Amazon MSK 中批量拉取消息并进⾏处理,然后插⼊到 ClickHouse 中。ClickHouse 使⽤ Amazon S3 作为持久存储。
ClickHouse 部署
我们可以根据官⽅⽂档将 ClickHouse 以单机⽅式或者集群⽅式部署到 Amazon EC2 上,并且参考⽂档将数据存储到 Amazon S3 上。需要注意,ClickHouse 需要的端⼝较多,需要在安全组中对应地打开。

参考文档
扫码了解更多

文档
扫码了解更多

端口
扫码了解更多
左右滑动查看更多
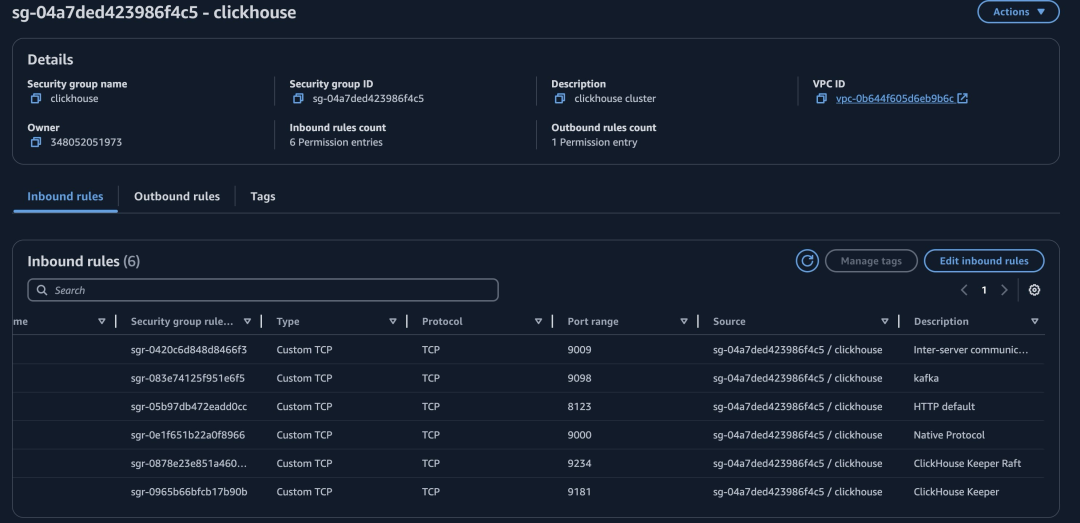
安全组样例
也可以从亚马逊云科技 Marketplace 上搜索订阅 ClickHouse Cloud 、ByteHouse 等托管版本,或者使用基于亚马逊云科技的 ClickHouse Cluster ⼀键部署⽅案。

基于亚马逊云科技的 ClickHouse Cluster
扫码了解更多
Amazon MSK 以及
Amazon Glue Schema Registry 部署
Amazon MSK 是亚马逊云科技上提供的全托管的 Kafka 服务,其中 Amazon MSK Serverless 是其⽆服务器版本。MSK Connect 是 Amazon MSK 上的基于 Kafka Connect 的⼀项功能。通过不同的 Connector,MSK Connect 可以从不同的数据源抽取数据到 MSK 以及写⼊到不同的数据源。
Amazon Glue Schema Registry 是亚⻢逊云科技上托管的 schema 注册发现中⼼,⽬前⽀持 Avro、JSON 以及 Protobuf 等格式。
具体步骤:
1.这⾥我们选⽤ Amazon MSK Serverless。Amazon MSK Serverless 配置相对简单,我们可以选择与 ClickHouse 联通的⼦⽹以及安全组。
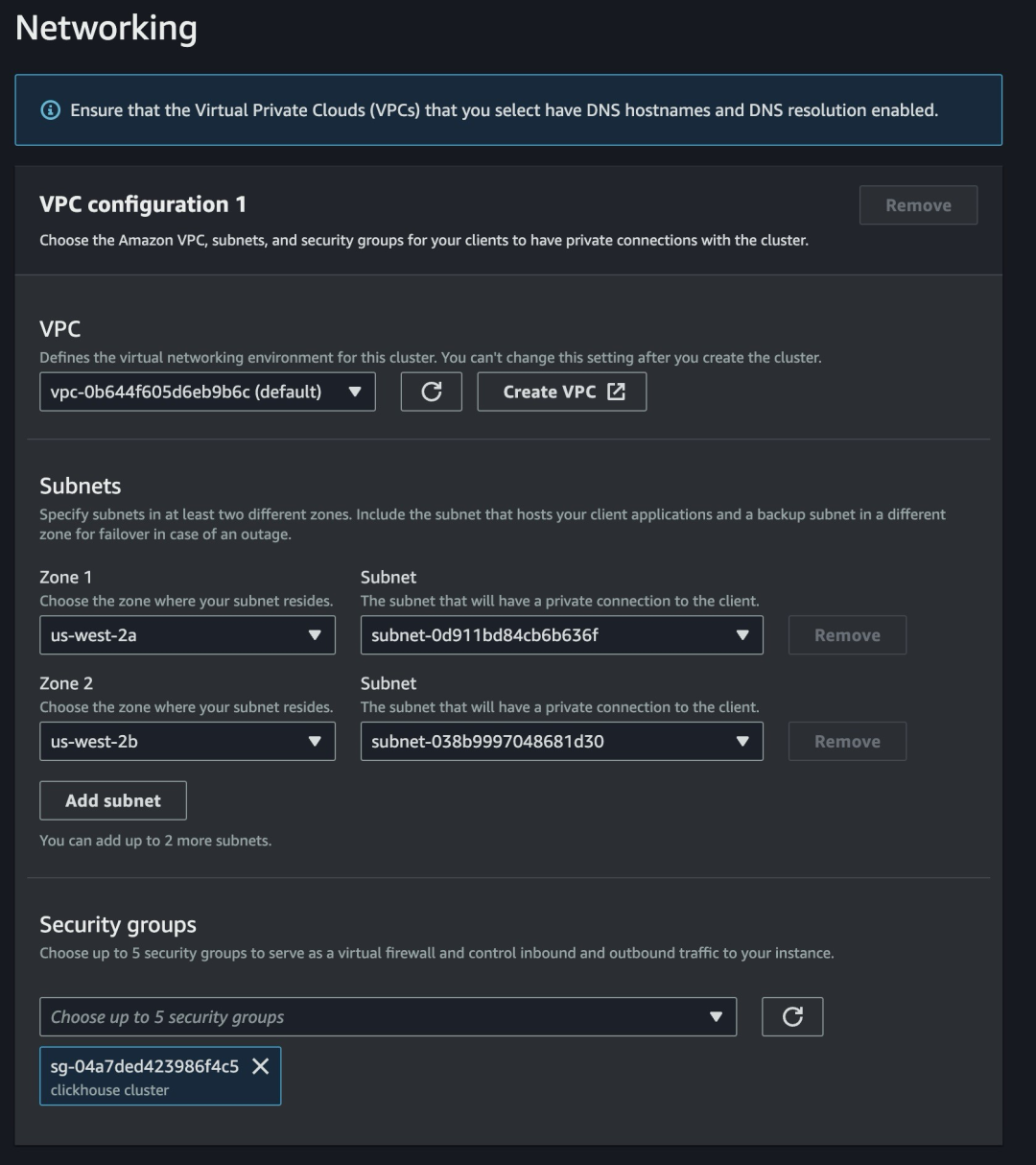
Amazon MSK Serverless ⽹络配置样例
2.获取连接信息。

3.在 MSK Serverless 选⽤的⼦⽹内为 Glue Schema Registry 创建 VPCE(即使⼦⽹已经有通往 IGW/NATGW 的路由)。


4.在 MSK Connect 下创建 Worker Configuration,注意 value.converter.endpoint 的值为 Glue Schema Registry 的 VPCE,其他配置根据消息内容调整。
offset.storage.partitions=5
status.storage.partitions=2
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter.schemas.enable=true
value.converter=com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter
value.converter.region=us-west-2
value.converter.registry.name=default-registry
value.converter.schemaAutoRegistrationEnabled=true
value.converter.compatibility=BACKWARD
value.converter.avroRecordType=GENERIC_RECORD
value.converter.endpoint=https://vpce-YOUR_VPCE_DNS_NAME.glue.us-west-2.vpce.amazonaws.com左右滑动查看更多
ClickHouse Kafka Connector 构建
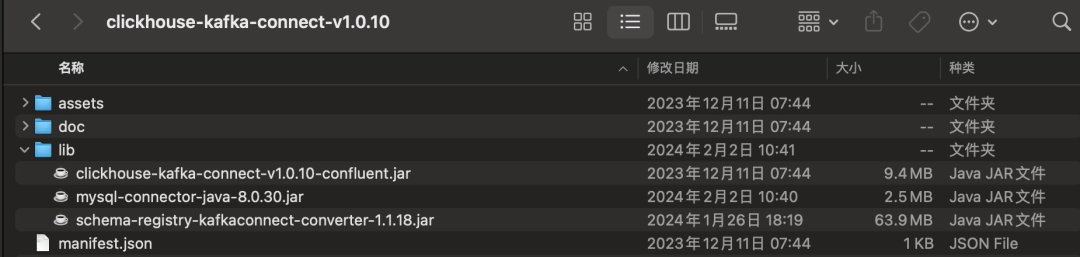
ClickHouse Kafka Connector 是官⽅的从 Kafka Topic 中读取数据并写⼊ ClickHouse 的 Kafka Connect 插件。由于我们的 Apache Avro Schema 存储在 Glue Schema Registry 中,因此需要在官⽅ zip 包中增加两个 JAR。
1.从 https://gcom/awslabs/aws-glue-schema-registry 下载源码,执⾏:

官方 zip 包
扫码了解更多

下载源码
扫码了解更多
左右滑动查看更多
mvn clean install得到 schema-registry-kafkaconnect-converter-1.1.18.jar。
2.下载 mysql jdbc。
3.unzip ClickHouse Kafka Connector,添加上述 jar,然后再次 zip。
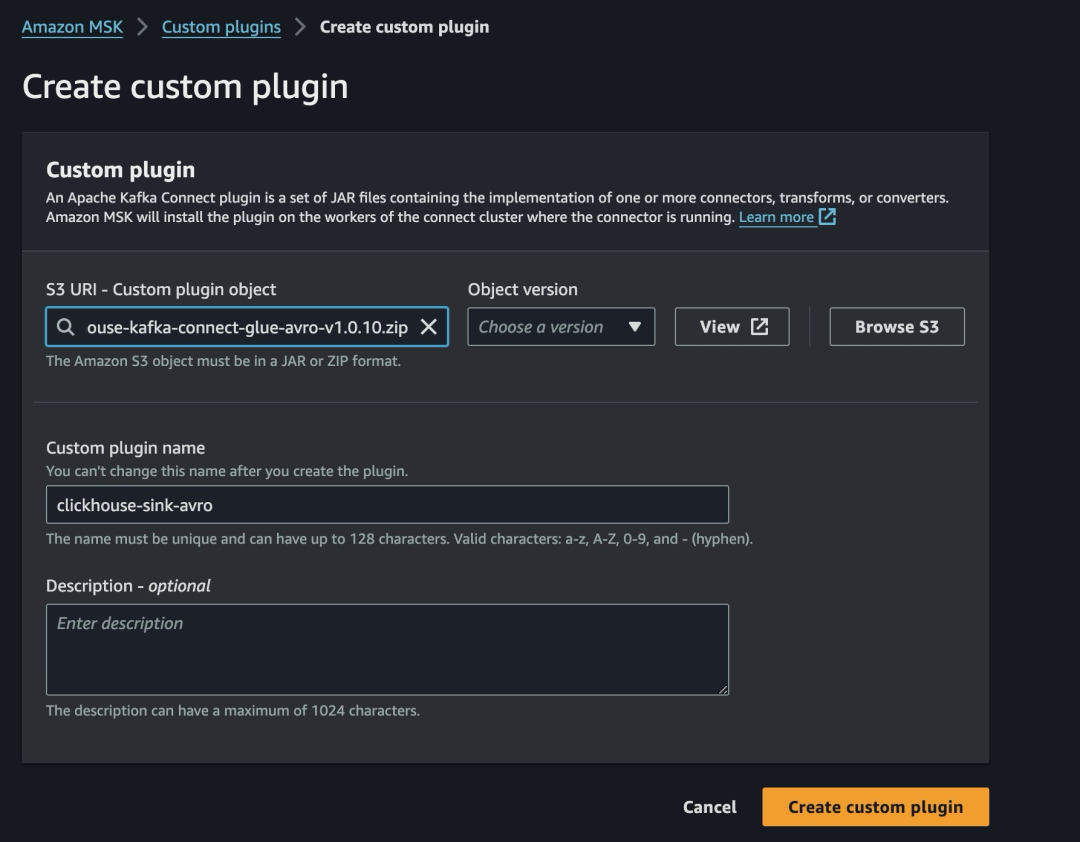
4.上传到 Amazon S3 并且创建 MSK Connect Plugin。
测试与验证
我们使⽤ ClickStream Kafka Producer 来进⾏测试。
1.创建可以连通 MSK Serverless 以及 ClickHouse 的 EC2(Kafka Producer)。
2.⽤于连接 MSK Serverless 的 IAM Policy 并附加到 Kafka Producer 对应的 IAM Role 上。
IAM Policy msk-serverless ⽰例
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": "arn:aws:kafka:us-west-2:YOUR_ACCOUNT_ID:cluster/*"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:DescribeTopic",
"kafka-cluster:CreateTopic",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": "arn:aws:kafka:us-west-2:YOUR_ACCOUNT_ID:topic/*"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": "arn:aws:kafka:us-west-2:YOUR_ACCOUNT_ID:group/*"
}
]
}左右滑动查看更多
在 Kafka Producer 上使⽤ Kafka 客户端(例如 https://gcom/dpkp/kafkapython)创建 Topic。

Kafka 客户端
扫码了解更多
#!/usr/bin/python
# create_topic.py
from kafka import KafkaProducer, KafkaAdminClient
from kafka.admin import NewTopic
from kafka.errors import KafkaError
import socket
import time
from aws_msk_iam_sasl_signer import MSKAuthTokenProvider
class MSKTokenProvider():
def token(self):
token, _ = MSKAuthTokenProvider.generate_auth_token('us-west-2')
return token
tp = MSKTokenProvider()
client = KafkaAdminClient(
bootstrap_servers='YOUR_MSK_SERVERLESS_CONNECTION_INFO',
security_protocol='SASL_SSL',
sasl_mechanism='OAUTHBEARER',
sasl_oauth_token_provider=tp,
client_id=socket.gethostname(),
)
client.create_topics([NewTopic('ClickStream2',2,2)])左右滑动查看更多
4.在 Kafka Producer 上安装 clickhouse-client 并创建表。

clickhouse-client
扫码了解更多
CREATE TABLE ClickStream2
(
`ip` String,
`eventtimestamp` Int64,
`devicetype` String,
`event_type` String,
`product_type` String,
`userid` Int32,
`globalseq` Int64,
`prevglobalseq` Int64
)
ENGINE = MergeTree
ORDER BY globalseq
SETTINGS storage_policy = 's3_main';5.参考 Amazon Service Role For Kafka Connect,创建 MSK Connect 需要的 Execution Role。由于我们需要使⽤ Glue Schema Registry 和 MSK Serverless,因此也添加相应权限。
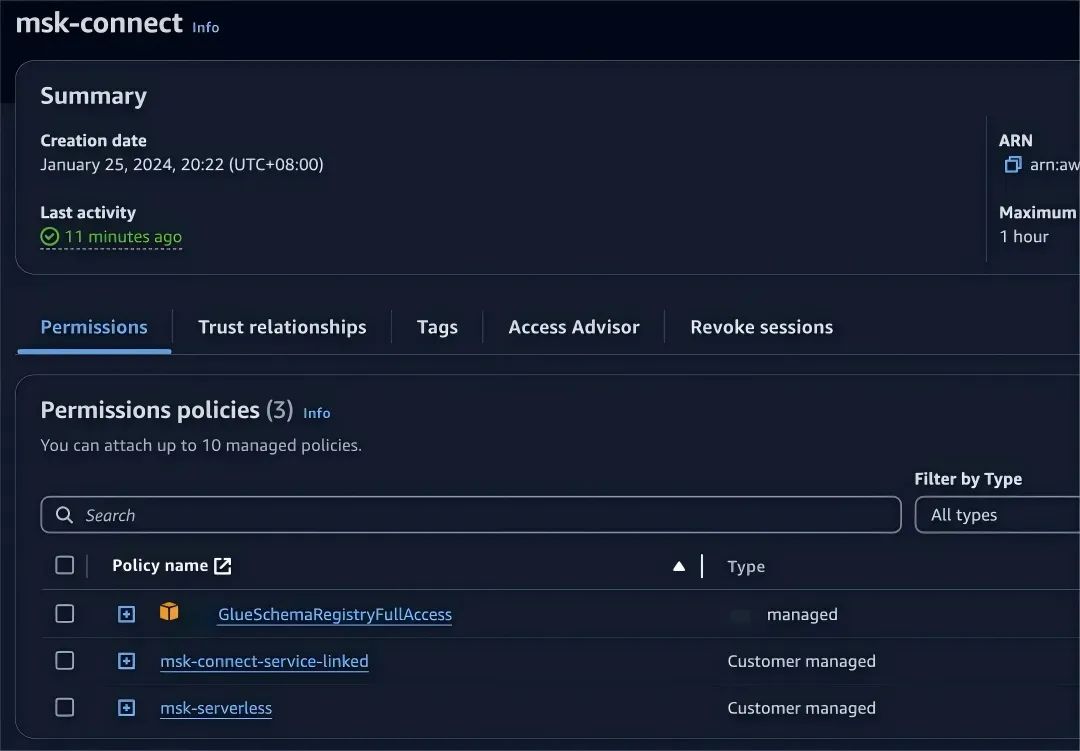
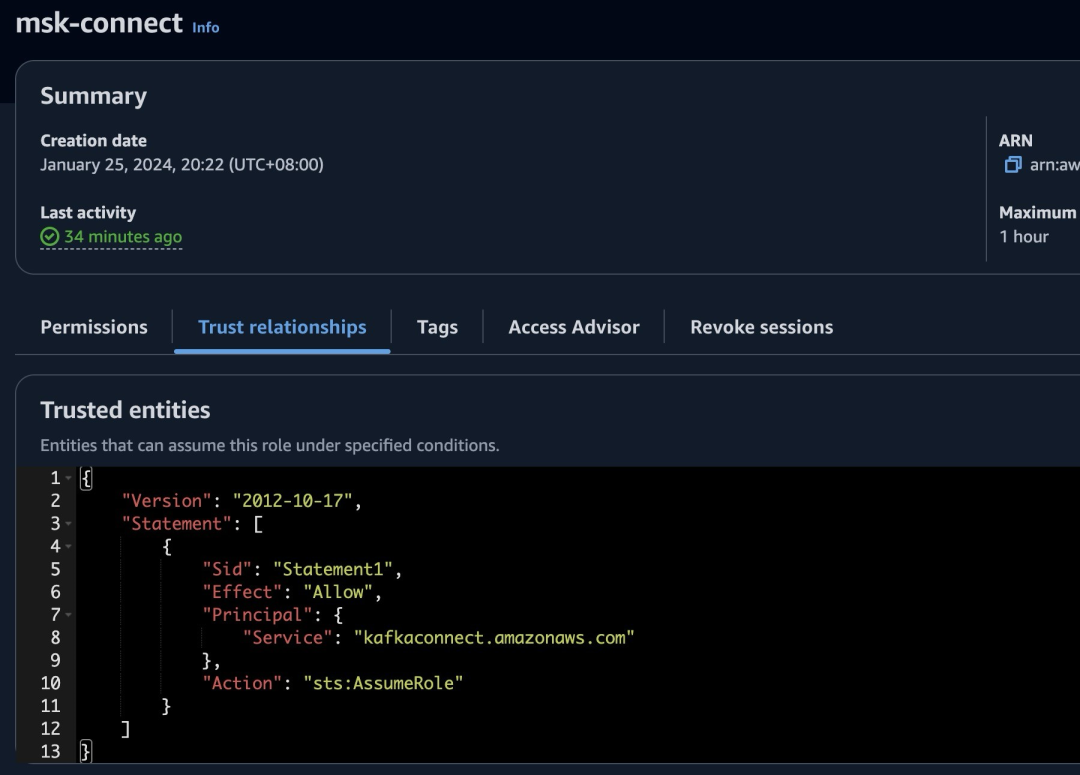
IAM Policy msk-connect-service-linked 示例
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface"
],
"Resource": "arn:aws:ec2:*:*:network-interface/*",
"Condition": {
"StringEquals": {
"aws:RequestTag/AmazonMSKConnectManaged": "true"
},
"ForAllValues:StringEquals": {
"aws:TagKeys": "AmazonMSKConnectManaged"
}
}
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface"
],
"Resource": [
"arn:aws:ec2:*:*:subnet/*",
"arn:aws:ec2:*:*:security-group/*"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateTags"
],
"Resource": "arn:aws:ec2:*:*:network-interface/*",
"Condition": {
"StringEquals": {
"ec2:CreateAction": "CreateNetworkInterface"
}
}
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeNetworkInterfaces",
"ec2:CreateNetworkInterfacePermission",
"ec2:AttachNetworkInterface",
"ec2:DetachNetworkInterface",
"ec2:DeleteNetworkInterface"
],
"Resource": "arn:aws:ec2:*:*:network-interface/*",
"Condition": {
"StringEquals": {
"ec2:ResourceTag/AmazonMSKConnectManaged": "true"
}
}
}
]
}左右滑动查看更多
6.创建 MSK Connect,注意截图中的选项。其他可以保持默认。

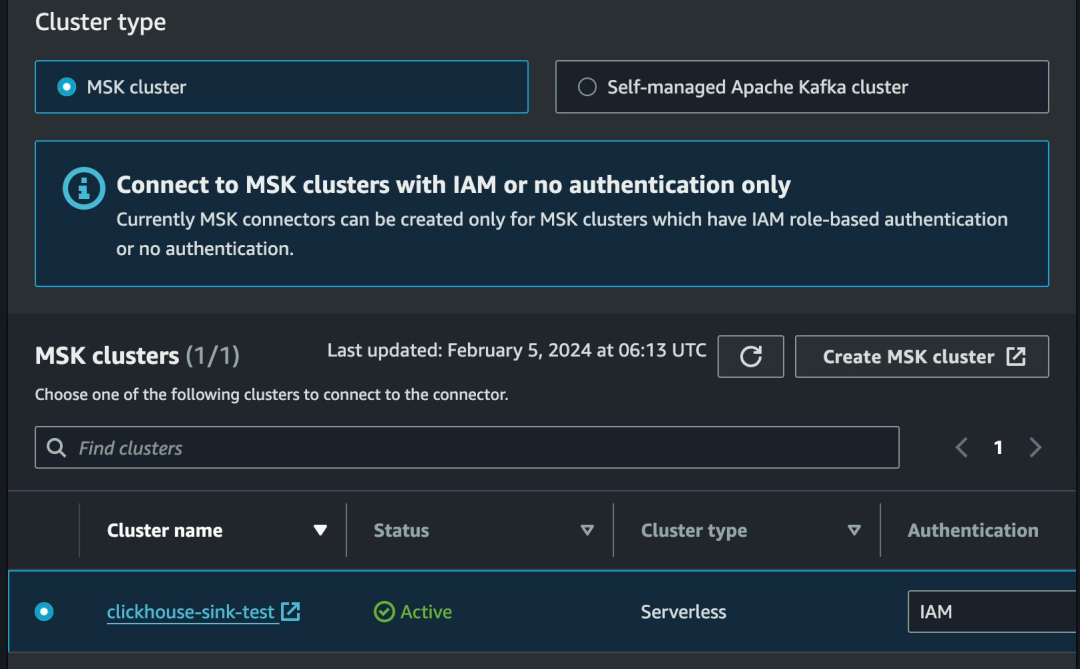
#Configuration settings
connector.class=com.clickhouse.kafka.connect.ClickHouseSinkConnector
hostname=HOST_NAME_OR_IP
database=default
password=CLICKHOUSE_CLIENT_PASSWORD
port=8123
tasks.max=1
topics=ClickStream2
errors.tolerance=all
exactlyOnce=false
ssl=false
username=default左右滑动查看更多
选择上⼀章创建的 Worker configuration。
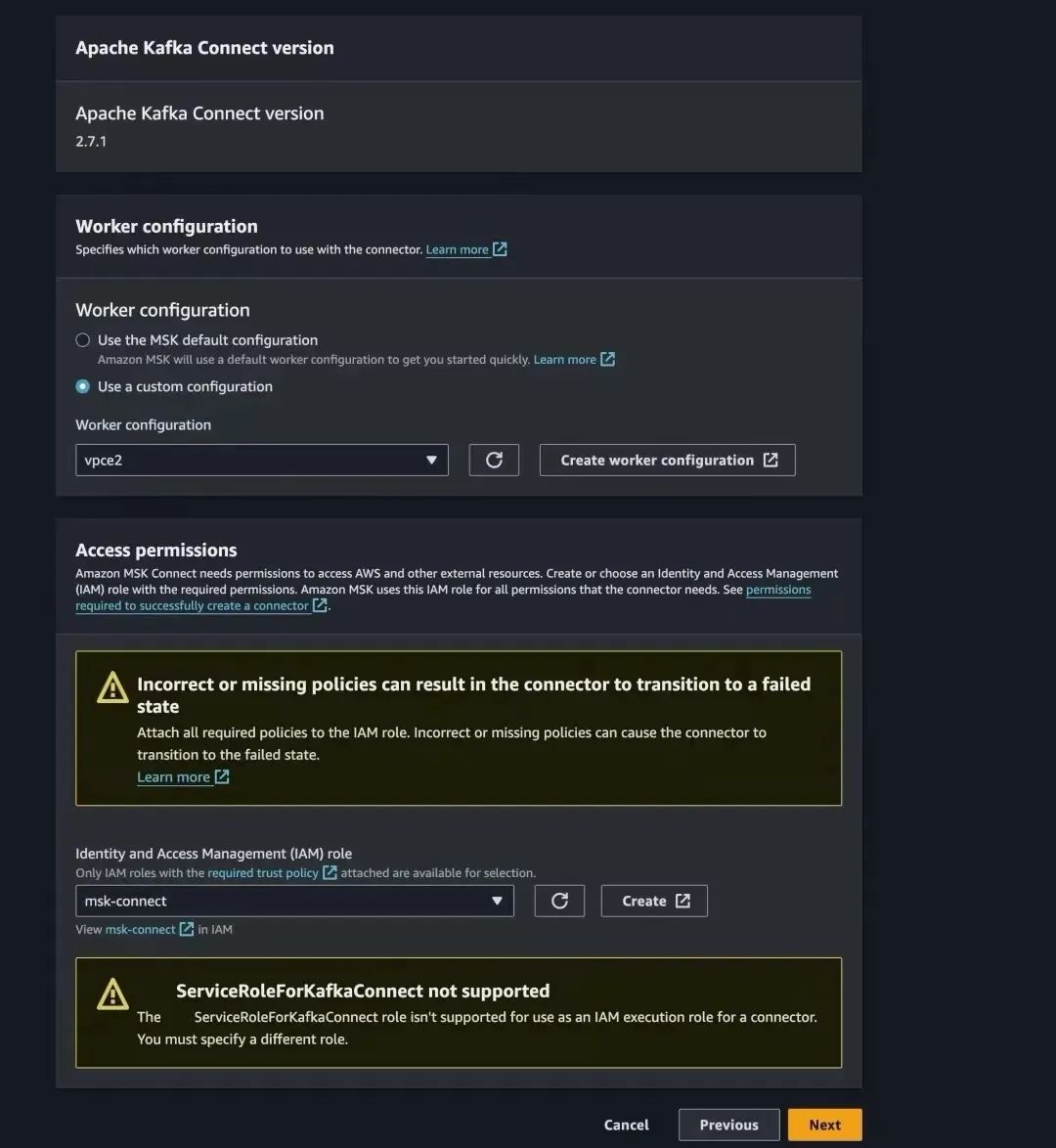
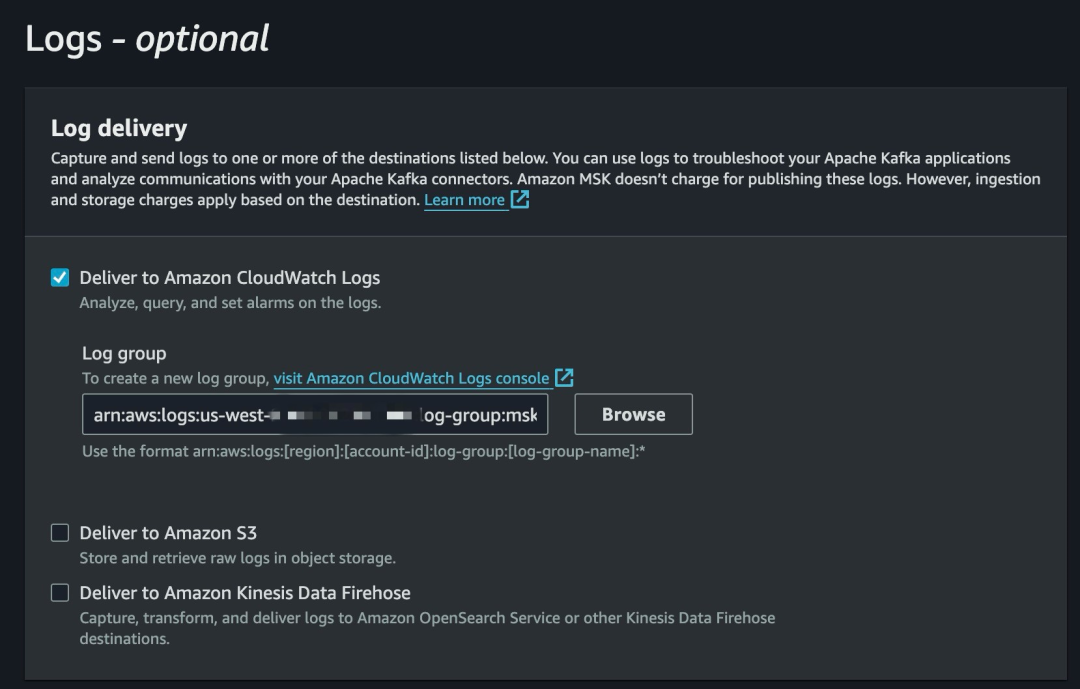
7.等待 MSK Connect 创建成功并且 CloudWatch Logs 中没有报错信息。
8.在 Kafka Producer 上下载并编译 ClickStream Producer,修改 clickstreamproducer-for-apache-kafka/producer.properties。

ClickStream Producer
扫码了解更多
# producer.properties
BOOTSTRAP_SERVERS_CONFIG=YOUR_MSK_SERVERLESS_CONNECTION_INFO左右滑动查看更多
9.执⾏命令开始⽣产数据。
java -jar clickstream-producer-for-apache-kafka/target/KafkaClickstreamClient-1.0-SNAPSHOT.jar -t ClickStream2 -pfp /home/ubuntu/clickstream-producer-for-apache-kafka/producer.properties -nt 8 -rf 300 -iam --region us-west-2 -gsr -gsrr us-west-2 -gar左右滑动查看更多
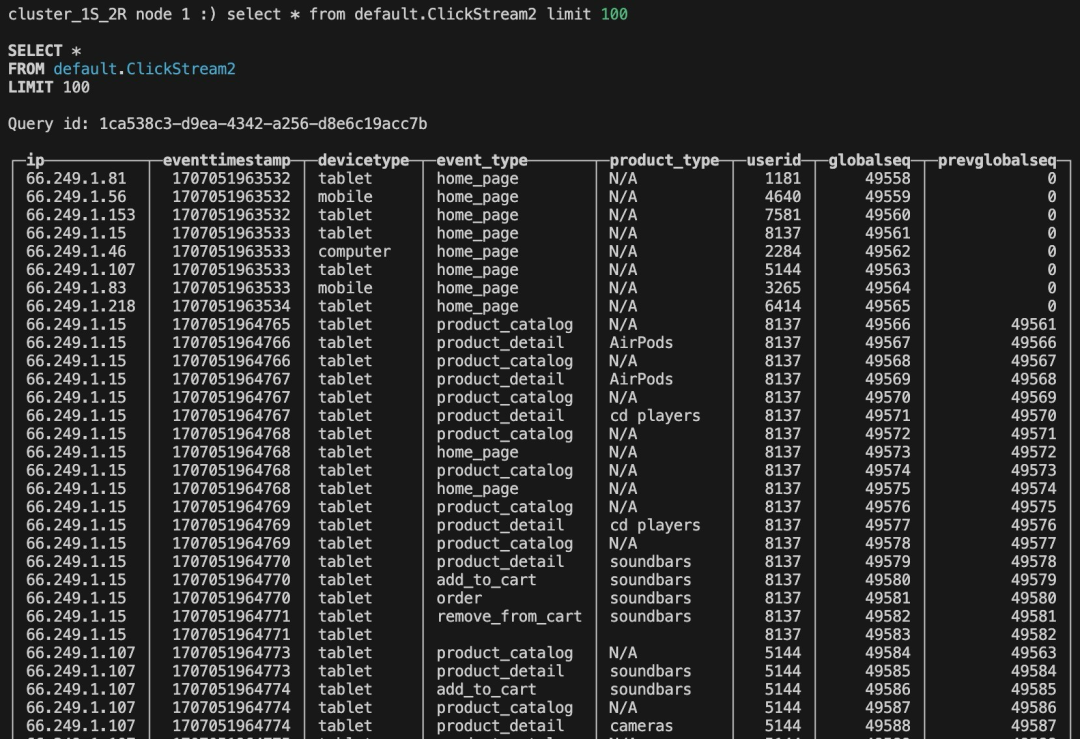
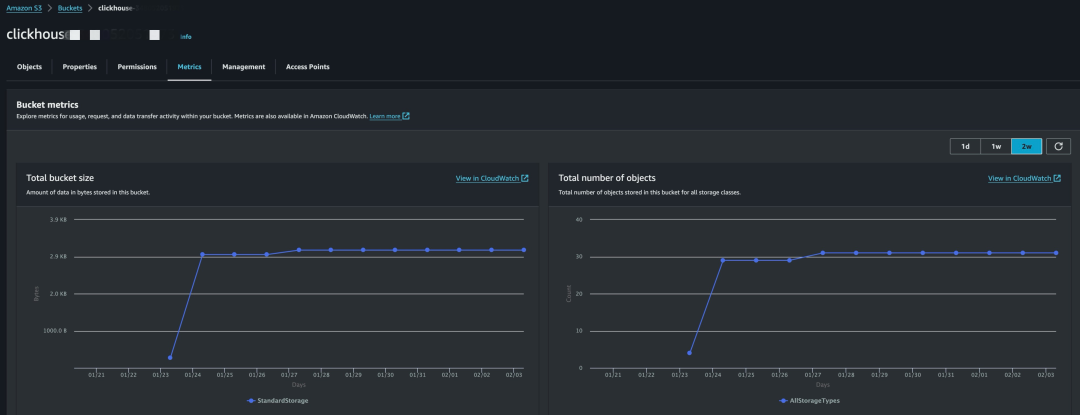
10.查看 CloudWatch Logs,ClickHouse 以及对应的 Amazon S3 路径,可以看到数据成功写⼊。
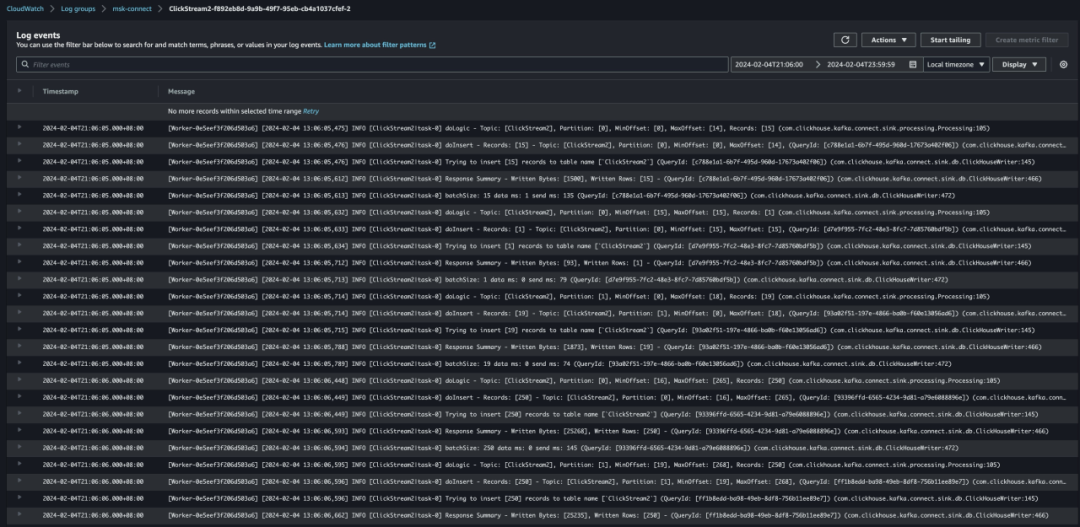
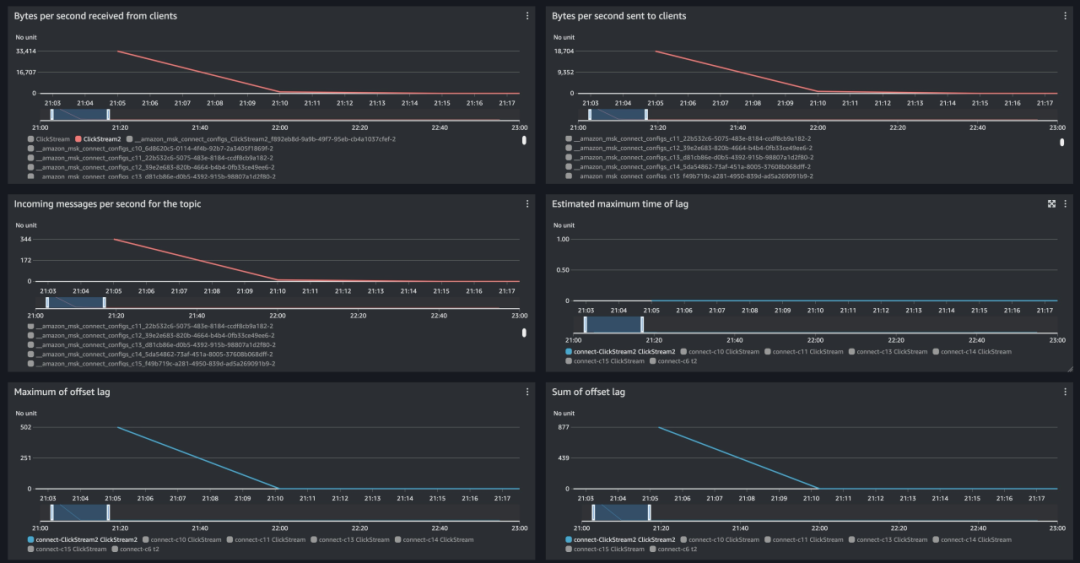
11.观察⼀段时间后可以暂停 Kafka Producer。通过观察 MSK Serverless 的指标,可以看到数据⽣产和消费⼏乎没有延迟。
总结
ClickHouse 在实时数据摄取及分析上具有强⼤的功能,但是整体端到端的部署和运维具有⼀定的难度。通过 Amazon MSK、Amazon MSK Connect 以及 Amazon Glue Schema Registry 等托管服务,可以在很⼤程度上减轻运维的复杂度,使得⽤户能够更轻松地发掘数据的价值。
本篇作者

施俊
亚马逊云科技解决方案架构师,主要负责数字金融客户和企业级客户在亚马逊云科技上的架构设计与实施。10 余年金融软件研发和机器学习经验。

Michael Song
亚马逊云科技技术客户经理,负责金融、制造业和智能手机等企业级客户架构设计、优化和深度技术支持。具有十年以上的企业信息技术运维管理与服务设计经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9272
9272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









