







在 Amazon SageMaker HyperPod 存储设计与实践(一)中我们实现了 Amazon SageMaker HyperPod 对 Amazon Elastic File System (Amazon EFS)的支持,利用 Access Point 实现不同用户的目录的安全隔离,接下来我们通过启动配置,实现在集群创建时自动化地对 Mountpoint for Amazon S3 接入。
Amazon SageMaker HyperPod 存储设计与实践(一)
https://aws.amazon.com/ec2/capacityblocks/https://aws.amazon.com/cn/blogs/china/amazon-sagemaker-hyperpod-storage-design-and-practice-part-one/
在 Amazon SageMaker HyperPod 中
实现 MountPoint for Amazon S3 支持
针对中小规模训练任务,计算节点可以通过 MountPoint for Amazon S3 来快速从 Amazon S3 上按需读取数据进行训练。以下展示在 Amazon SageMaker HyperPod 集群创建时,针对 MountPoint for Amazon S3 的核心配置,其他过程参考示例。
示例
https://github.com/aws-samples/cluster-infra-quick-launch
1.安装 MountPoint for Amazon S3 客户端程序,参考 Github Mountpoint for Amazon S3 官方安装指导。
2.创建 mount_s3.sh 文件,执行如下 mount 操作:
mount_fs() {
if [[ ! -d $MOUNT_POINT ]]; then
sudo mkdir -p $MOUNT_POINT
sudo chmod 777 $MOUNT_POINT
fi
/usr/bin/mount-s3 $BUCKET_NAME $MOUNT_POINT
mount | grep mountpoint-s3
}左右滑动查看完整示意
官方安装指导
https://github.com/awslabs/mountpoint-s3
3.创建 check_mount_s3 服务,用于检查 Amazon S3 桶的挂载状态,如果没有挂载,则执行 mount 操作。关键代码如下:
cat > $CHECK_MOUNT_FILE << EOF
#!/bin/bash
if ! grep -qs "mountpoint-s3" /proc/mounts; then
/usr/bin/mount-s3 --allow-other --allow-delete --allow-overwrite --maximum-throughput-gbps 100 --dir-mode 777 $BUCKET_NAME $MOUNT_POINT
echo "mount-s3 mounted by check_service"
else
systemctl stop check_mount_mount-s3.timer
echo "mount-s3 already mounted"
fi
EOF
chmod +x $CHECK_MOUNT_FILE
cat > /etc/systemd/system/check_mount_mount-s3.service << EOF
[Unit]
Description=Mountpoint for Amazon S3 mount
Wants=network.target
AssertPathIsDirectory=$MOUNT_POINT
[Service]
Type=forking
User=root
Group=root
ExecStart=$CHECK_MOUNT_FILE
ExecStop=/usr/bin/fusermount -u $MOUNT_POINT
[Install]
WantedBy=remote-fs.target
EOF左右滑动查看完整示意
4.在 lifecycle_script.py 中执行 mount_s3.sh 脚本,bucketname 从 provisioning_parameters.json 中获得。
bucketname = params.bucketname
ExecuteBashScript("./mount_s3.sh").run(bucketname)左右滑动查看完整示意
5.待集群创建完毕后,检查 Amazon S3 桶的挂载状态,以下命令中可以看到 Amazon S3 桶已经被 Mountpoint for Amazon S3 正确挂载。
root@ip-10-1-41-18:/usr/bin# mount|grep -i mountpoint
mountpoint-s3 on /mount-s3 type fuse (rw,nosuid,nodev,noatime,user_id=0,group_id=0,default_permissions,allow_other)
root@ip-10-1-41-18:/usr/bin# ls /mount-s3/
file1 job-bb523bf0-9d28-43a1-b346-8aa0f22b24fc左右滑动查看完整示意
通过以上主要步骤,实现了 Amazon SageMaker HyperPod 集群中对于 Amazon S3 对象存储的流式读写的自动化支持。
集群启动时进行存储挂载的必要性
在前面的过程中,我们实现了 Amazon EFS、 Mountpoint for Amazon S3 通过 Lifecycle 脚本的创建时配置及挂载过程。从实现上看,不同存储类型的配置及挂载仍然可以在集群建立好后,通过 slurm 进行 batch 任务提交的方式实现 Amazon EFS、Mountpoint for Amazon S3 的挂载。
但考虑到 Amazon SageMaker HyperPod 的集群 Self-Healing 及任务 Auto-Resume 的特性,如果集群中的计算节点由于某些原因发生异常,在 Amazon SageMaker HyperPod 的恢复机制的托管下完成了计算节点的自动化替换或重启后,使用 Lifecycle 脚本则会自动挂载 Amazon EFS、Mountpoint for Amazon S3 存储,而无需专门登入替换后的节点,进行手动存储挂载,即使得前序训练任务无缝地继续执行。
以上的自动化链路保证了训练任务中断到集群自动修复,再到任务自动延续执行的整体连续性,因此对于长耗时的大型训练任务,建议以上述 Lifecycle 配置的方式实现不同存储类型的自动化配置及挂载。
不同规模场景下的存储选择与实践
在 Amazon SageMaker FFM 流式训练,Amazon S3 Connector 在训练中流式读取,Mountpoint for Amazon S3 加速 K8s 训练等文章中,我们探讨了训练数据存储选型方面的一系列最佳实践。Amazon SageMaker HyperPod 除了提供集群托管能力之外,具备的巨大优势在于其全托管集群的 Self-Healing 及自动的任务 Auto-Resume 机制。
当大型集群由于各种原因,如代码异常或者底层驱动所引起的一些偶发问题,导致训练任务发生中断。则当集群恢复后,需要从最近的一个检查点(checkpoint)继续进行被中断的训练任务。无论何种恢复机制均强依赖于模型训练的 checkpoint 过程,同时 checkpoint 的存取性能及触发频率也对大规模训练时长有不可忽略的影响。
Amazon SageMaker FFM 流式训练
https://aws.amazon.com/cn/blogs/china/build-llm-streaming-training-based-on-sagemaker-ffm/
Amazon S3 Connector 在训练中流式读取
https://aws.amazon.com/cn/blogs/china/use-s3-connector-for-pytorch-to-implement-s3-streaming-reading-in-training-code/
Mountpoint for Amazon S3 加速 K8s 训练
https://aws.amazon.com/cn/blogs/china/accelerate-llm-training-on-kubernetes-with-mountpoint-for-s3/
测试配置如下:
模型选取 Llama-3-8B,2K 上下文长度。
训练基础设施为 Amazon SageMaker HyperPod 托管 1 * ml.g5.48xlarge (8 * A10g GPU) 计算节点。
模型训练的并行方式选取 Torch Fully Sharded Data Parallel (FSDP) 和 Hybrid Sharded Data Parallel (HSDP)。
checkpoint 写入过程基于不同的训练并行方式,分别采用集中写入及分布式写入。
这里选取了 Torch 的 FSDP 及 HSDP 两种并行训练策略来分别实现不同的 checkpoint 写入策略。相比于 FSDP,HSDP 在原有模型分片的基础上,进一步增加了层级分片的特性,即可以实现在节点内进行 Full Shard,节点间进行数据并行。
对于中大参数量模型且集群规模较大的场景,使用 HSDP 对模型分片的粒度进行干预,避免在所有 GPU 进程上进行模型分片,从而进一步的降低训练过程的跨节点通信开销,提升整体训练吞吐。
Llama-3-8B
https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct
FSDP
https://pytorch.org/docs/stable/fsdp.html#module-torch.distributed.fsdp
HSDP
https://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.ShardingStrategy,%20https://github.com/meta-llama/llama-recipes
集中式存储
对于模型在 FULL_SHARD 策略下的 checkpoint 存储,参考代码如下:
fullstate_save_policy = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
with FSDP.state_dict_type(
model, StateDictType.FULL_STATE_DICT, fullstate_save_policy):
# On All Ranks
model_state = model.state_dict()
# On Rank0 Only
torch.save(model_state, <save_path>)
# On All Ranks
optim_state = FSDP.optim_state_dict(model, optimizer)
# On Rank0 Only
torch.save(optim_state, <save_path>)左右滑动查看完整示意
使用 FULL_STATE_DICT 模式来保存模型 checkpoint。首先,指定 FullStateDictConfig,指定仅在 Rank 0 上填充 state_dict,并将其卸载到 CPU 上。FSDP 将在 Rank 0 上汇总模型参数,避免了对于大于单个 GPU 显存的模型可能发生的 CUDA OOM 问题,但单个 checkpoint 受限于当前算力节点的可用 CPU 内存大小。
分布式分片存储
对于模型在 HYBRID_SHARD 策略下的 checkpoint 分片存储,参考代码如下。
from torch.distributed.checkpoint.default_planner import DefaultSavePlanner
import torch.distributed._shard.checkpoint as dist_cp
# On All Ranks of a shard group (Node)
distributed_writer = dist_cp.FileSystemWriter(<save_path>)
with FSDP.state_dict_type(model, StateDictType.SHARDED_STATE_DICT):
state_dict = {}
state_dict["model"] = model.state_dict()
state_dict["optim"] = FSDP.optim_state_dict(model, optim)
dist_cp.save_state_dict(
state_dict=state_dict,
storage_writer=distributed_writer,
planner=DefaultSavePlanner(),
)左右滑动查看完整示意
参考代码
https://pytorch.org/docs/stable/distributed.checkpoint.html
当模型训练分片策略使用 HYBRID_SHARD 时,由于单个 shard group 持有完整的模型副本,因此仅需单个 shard group 进行写入,torch.distributed 会通过 NCCL 集合操作对于同时跨越多个 Rank 间的交互进行协调 ,具体参考 FSDP。
结果与分析
针对训练过程中模型参数及优化器的状态保存,以下表格汇总了不同分片策略及其在不同的存储方案上的 checkpoint 写入性能:
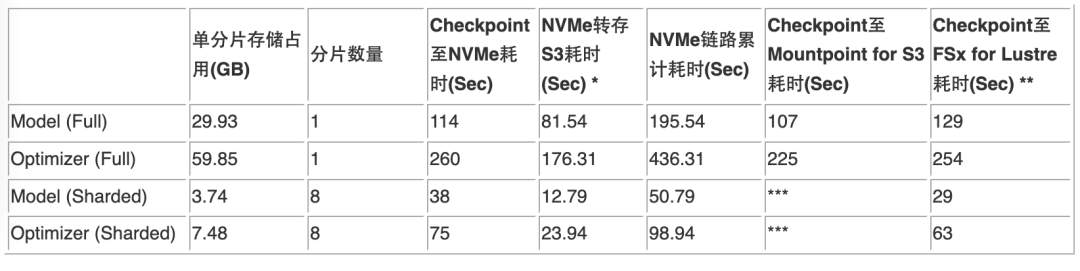
*计算节点的实例 NVMe 存储转存至 Amazon S3 使用高性能 Amazon S3 存取工具 s5cmd。
**FSx for Lustre 共预置 60TiB 存储容量,单位吞吐能力 250 MB/s/TiB,累计吞吐能力 15,000 MB/s。
***Mountpoint for Amazon S3 暂不支持完整的 POSIX 接口,无法支持在分片存储时需要的 rename 操作。
s5cmd
https://github.com/peak/s5cmd
基于以上数据,该场景中对于 8B 参数量模型训练时的 checkpoint 保存,其 checkpoint 的存储消耗累计达到了 90GB (其中的 Optimizer 占用约 60GB)。同时,评估了其在 FULL_SHARD 及 HYBRID_SHARD 两种训练策略下的 checkpoint 分片策略,在计算实例的本地 NVMe 存储,挂载 Mountpoint for Amazon S3 及 FSX for Lustre 存储上的性能。
可以看出,使用分片形式进行模型 checkpoint 存储,由于多个 GPU 进程可以进行并发写操作,因此整体的时间消耗小于写入一个完整的 checkpoint。另外,可以观察到,在本测试场景中,FSx for Lustre 对于 checkpoint 分片的存储形式可以有极大的性能提升。因此,对于一般的训练场景的 checkpoint 存储选型,有如下最佳实践建议:
1.需要根据实际需要来选取合适的 checkpoint 保存频率及保存范围,如训练代码的容错策略,或模型评估频率等。
2.对于较小参数量模型(如 8B 及以下)的 checkpoint存储场景,建议直接使用 Mountpoint for S3 进行全量的 checkpoint 存储。优势有:
高通用性的 checkpoint 存储形式,具备极低的代码复杂度;且可以直接以文件形式直接写入 Amazon S3 对象存储,进行持久化保存。
checkpoint 写入的性能及成本有较好的平衡,且 Amazon S3 容量无需预置。
3.对于中大参数量模型(如 70B 及以上)且集群规模较大,需要相对高频进行 checkpoint 存储的场景,建议使用 FSx for Lustre 结合分片并发 checkpoint 存储。优势有:
当使用分片存储策略时,一个模型副本中有多个 GPU 进程并发执行分片的存储,性能提升的同时,减少了对于单计算节点的 CPU RAM 依赖。
在 FSx for Lustre 预置一定规模的存储容量(如测试示例中的 60TiB)时,其具备较高的并发能力(如测试示例中的 60 个可并发的 250MB/s 的存储单元)。分片进行 checkpoint 写入时间有大幅度的降低,避免了 GPU 集群的等待开销。
除去以上介绍的基于 torch.save() 以及 torch.distributed 的不同存储形式,主流并行框架也内置了不同的 checkpoint 存储策略,如 deepspeed 中的 save_checkpoint实现方式,或 megatron.core 中的 dist_checkpointing 实现方式等。建议针对实际的训练任务及训练方案选型,以及根据不同方案或方案组合的性能测试结果进行实际生产场景的选型。
实现方式
https://deepspeed.readthedocs.io/en/latest/model-checkpointing.html#deepspeed.DeepSpeedEngine.save_checkpoint
方案总结
本文在 Amazon SageMaker HyperPod 存储设计与实践的基础上进一步探讨了在 Amazon SageMaker HyperPod 中实现 Mountpoint for Amazon S3 支持的方法,包括 Client 安装、创建挂载和检查挂载状态的脚本等。通过进行 Lifecycle 配置,可以在集群创建时自动挂载 Mountpoint for Amazon S3。
文中还阐述了在 Amazon SageMaker HyperPod 的 Self-healing 特性下,通过 Lifecycle 脚本实现自动存储挂载的必要性,以确保在计算节点发生故障及自动的算力节点替换后,使得训练任务可以无缝继续。最后,文章基于实际训练场景 checkpoint 存储的性能测试,对不同规模的模型训练场景,给出了存储选择的最佳实践建议。
对于小规模模型训练,建议使用 Mountpoint for Amazon S3 进行 checkpoint 全量存储;对于大规模模型高频 checkpoint 场景,建议使用 FSx for Lustre 分片存储 checkpoint,以提高写入性能。
本篇作者

郑昊
亚马逊云科技人工智能和机器学习解决方案架构师。主要专注于基础模型的训练、推理及性能优化、广告、排序算法等及其基于亚马逊云科技人工智能和机器学习技术栈的相关优化及方案构建。

王大伟
亚马逊云科技高级存储解决方案架构师,负责数据与存储架构设计。具有十五年从事数据与存储相关经验,目前主要关注在人工智能和机器学习、高性能计算领域,如 EDA、自动驾驶、基因分析等领域的存储设计与优化。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9269
9269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









