







在到处都是大模型的今天,如果这些大模型不能根据企业的具体需求进行定制化调整,它们的优势可能就要大打折扣,甚至在特定的业务场景中显得"食之无味弃之可惜"。因此,如何将这些大模型灵活地融入到实际业务中,通过定制化的模型和数据驱动的策略来推动业务的持续增长和创新,已经成为每位业务决策者必须深思熟虑并积极解决的关键问题。这不仅关乎技术的运用,更涉及到战略的布局和创新的实践。
亚马逊云科技宣布Amazon Bedrock自定义模型导入新功能正式可用。通过该项新功能,客户可以使用统一API导入企业的自定义模型,并与现有基础模型一起使用,从部署和扩展模型的复杂性中真正解放,降低基础架构或模型生命周期的管理成本。
Amazon Bedrock是亚马逊云科技一项完全托管的服务,通过单一API提供来自AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI和亚马逊等领先人工智能公司的高性能基础模型,用于构建具有安全性、隐私性和负责任的人工智能应用程序。通过Amazon Bedrock支持的Meta Llama、Mistral Mixtral、IBM Granite等微调模型和基于开源架构开发的专有模型,搭配无服务器按需访问模式,客户可以快速上手,使用企业数据高效定制模型,并将Amazon Bedrock的服务和功能集成,加速生成式AI应用开发,实现统一且连贯的开发体验。
Amazon Bedrock
https://aws.amazon.com/bedrock/
新功能的优势
更灵活地使用现有微调模型:无需重新创建或训练模型,避免浪费之前前期投入,有效加快开发进程。
与Amazon Bedrock功能的一体化集成: 导入的自定义模型可集成Amazon Bedrock的内置服务和功能(如知识库、Guardrails、Agent、模型评估等),实现基础模型与自定义模型间的无缝切换。
基于无服务器的按需访问:无需花费精力在基础设施管理或扩展问题,帮助客户专注生成式AI应用开发。
广泛的兼容性,提供更多模型选择:不止于Meta Llama(v.2、3、3.1 和 3.2)、Mistral 7B、Mixtral 8x7B、Flan和IBM Granite模型(如Granite 3B-Code、8B-Code、20B-Code和34B-Code),Amazon Bedrock支持导入流行的模型架构,客户可以根据特定需求和用例,从Amazon SageMaker和Amazon S3 中导入Hugging Face Safetensors等格式的自定义权重文件。
Amazon SageMaker
https://aws.amazon.com/sagemaker
Amazon S3
https://aws.amazon.com/s3/
Safetensors
https://huggingface.co/docs/safetensors/en/index
通过API简化访问方式:将企业的微调模型与Amazon Bedrock Converse API结合使用,简化并统一模型的访问方式。
Amazon Bedrock Converse API
https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference-call.html
立即体验新功能
亚马逊云科技深知客户的关键需求是使用自己的数据定制模型,并保留微调模型及其部署过程的所有权和使用权。即使客户能通过多种高效、低成本的方式微调模型,但托管模型阶段会有一系列挑战,客户非常关注以下五个方面。
利用现有定制模型的投资,精细化把控定制过程;
通过Amazon Bedrock的API访问自定义模型或基本模型时,获得一致的开发体验;
通过全托管的无服务器服务实现轻松部署;
使用按需推理,尽可能降低生成式AI工作负载的成本;
获得企业级安全和隐私工具的支持。
Amazon Bedrock自定义模型导入功能就是为了解决这些问题。
导入模型时需要注意
模型必须以Safetensors格式序列化。
如果使用的是其他格式,可通过Llama转换脚本或Mistral转换脚本将模型转换为支持的格式。
Llama转换脚本
https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
Mistral转换脚本
https://github.com/huggingface/transformers/blob/main/src/transformers/models/mistral/convert_mistral_weights_to_hf.py
导入过程至少需要以下文件:.safetensors,json,tokenizer_config.json,tokenizer.json, 和tokenizer.model 。
支持的模型权重精度为FP32、FP16 和 BF16。
对于创建适配器(如LoRA-PEFT适配器)的微调作业,导入过程需要将适配器合并到主要基础模型权重中,如模型合并中所述。
模型合并
https://huggingface.co/docs/peft/en/developer_guides/model_merging
通过Amazon Bedrock控制台
导入模型
1.进入Amazon Bedrock控制台,从左侧导航窗格中选择基础模型,然后选择导入模型,即可进入模型页面
2.点击 “导入模型”配置导入流程。
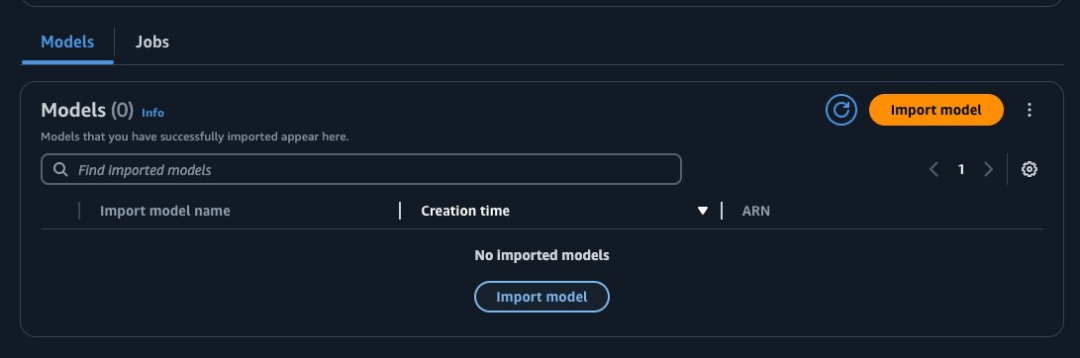
3.配置模型
输入模型权重:这些权重可以在Amazon S3,也可以指向Amazon SageMaker模型的ARN对象。
模型的ARN对象
https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateModel.html
输入任务名称。这里建议以模型版本作为后缀。目前,需要在此功能外管理生成式AI操作。
配置用于加密的亚马逊云科技密钥管理服务 (Amazon KMS)。默认情况下,将设置为亚马逊云科技拥有和管理密钥。
Amazon KMS
https://aws.amazon.com/kms
服务访问角色。您可以创建一个新角色或使用一个现有角色,该角色将拥有运行导入流程所需的权限。如果通过Amazon S3指定模型权重,则权限必须包括访问Amazon S3的权限。
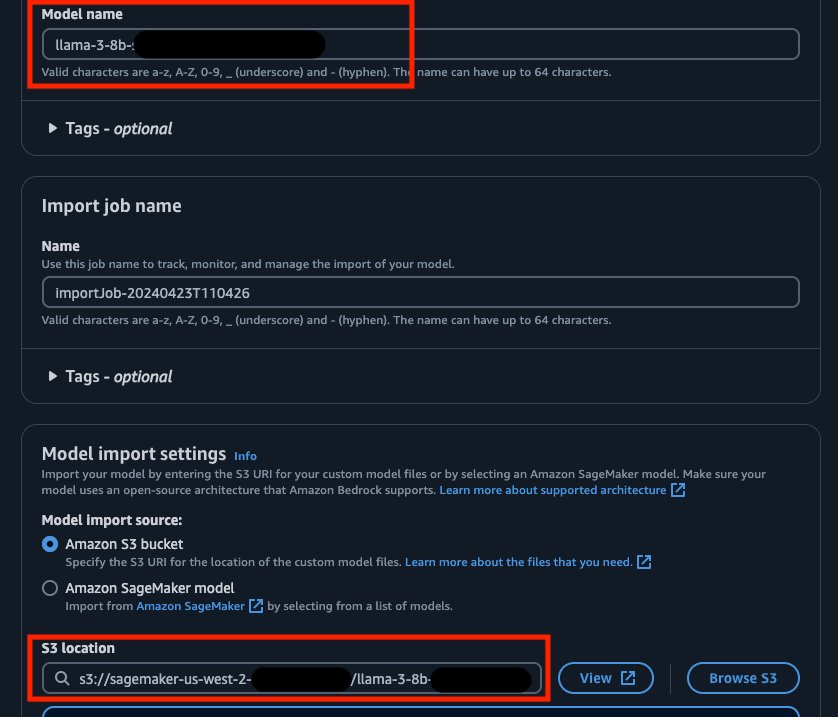
4.导入模型任务完成后,您将看到模型和模型ARN。记下ARN以备日后使用。
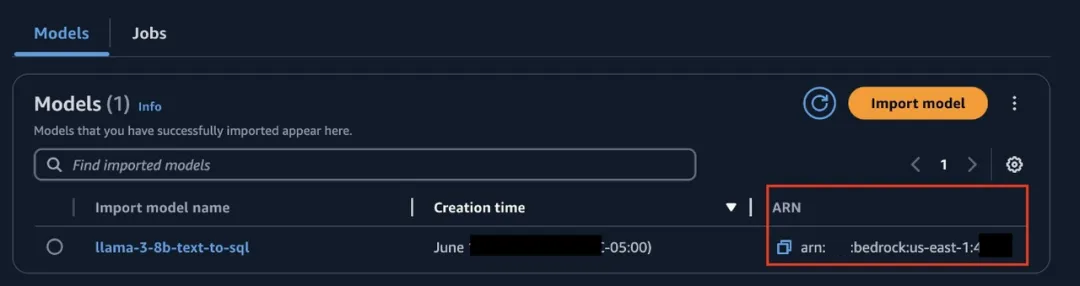
5.使用Text playground中的按需功能测试模型。
导入过程通过读取config.json文件验证模型配置是否符合该模型的指定架构,并验证模型架构值,如最大序列长度和其他相关细节。它还会检查模型权重是否符合Safetensors格式。该验证可确认导入的模型符合必要的要求并与系统兼容。
在Amazon SageMaker上
微调Meta Llama模型
Meta Llama 3.2提供了多模态视觉和轻量级模型,拥有更强大的功能和更广泛的适用性。
Amazon SageMaker JumpStart通过两个主要界面提供基础模型:Amazon SageMaker Studio和Amazon SageMaker Python SDK,方便用户选择数百个模型来满足使用需求。
下文将展示如何使用Amazon SageMaker JumpStart微调Llama 3.2 3B Instruct模型,以及Amazon SageMaker JumpStart中可用的Llama 3.2模型支持的实例类型和上下文信息。在官方页面,但您还可以找到其他可使用Amazon SageMaker JumpStart进行微调的Llama 3.2模型变体。
指令微调
文本生成模型可以对任何文本数据上进行指令微调,前提是数据必须是特定格式。经过指令微调的模型可以进一步部署用于推理。训练数据的格式必须是JSON Lines (.jsonl) 格式,其中每一行都是一个代表单个数据样本的字典。所有训练数据必须放在一个文件夹中,但也可以保存在多个JSON Lines文件中。训练文件夹还可以包含一个template.json文件,描述输入和输出格式。
合成数据集
对于此用例,我们将使用一个名为amazon10Ksynth.jsonl的指令微调数据集,该数据集以指令调整格式设计。这个数据集包含大约200条条目,专为在金融领域训练和微调基础模型设计。
以下是数据格式的示例:
instruction_sample = {
"question": "What is Amazon's plan for expanding their physical store footprint and how will that impact their overall revenue?",
"context": "The 10-K report mentions that Amazon is continuing to expand their physical store network, including 611 North America stores and 32 International stores as of the end of 2022. This physical store expansion is expected to contribute to increased product sales and overall revenue growth.",
"answer": "Amazon is expanding their physical store footprint, with 611 North America stores and 32 International stores as of the end of 2022. This physical store expansion is expected to contribute to increased product sales and overall revenue growth."
}
print(instruction_sample)左右滑动查看完整示意
提示模板
接下来,我们创建一个提示模板,用于在训练任务中使用指令输入格式的数据(本示例中对模型进行指令微调),并用于推断已部署的终端。
import json
prompt_template = {
"prompt": "question: {question} context: {context}",
"completion": "{answer}"
}
with open("prompt_template.json", "w") as f:
json.dump(prompt_template, f)左右滑动查看完整示意
在创建了提示模板之后,将用于微调的数据集上传到Amazon S3。
from sagemaker.s3 import S3Uploader
import sagemaker
output_bucket = sagemaker.Session().default_bucket()
local_data_file = "amazon10Ksynth.jsonl"
train_data_location = f"s3://{output_bucket}/amazon10Ksynth_dataset"
S3Uploader.upload(local_data_file, train_data_location)
S3Uploader.upload("prompt_template.json", train_data_location)
print(f"Training data: {train_data_location}")左右滑动查看完整示意
微调Meta Llama 3.2 3B模型
现在,我们将在金融数据集上微调Llama 3.2 3B模型,微调脚本基于Llama微调仓库提供的版本。
from sagemaker.jumpstart.estimator import JumpStartEstimator
estimator = JumpStartEstimator(
model_id=model_id,
model_version=model_version,
environment={"accept_eula": "true"},
disable_output_compression=True,
instance_type="ml.g5.12xlarge",
)
# Set the hyperparameters for instruction tuning
estimator.set_hyperparameters(
instruction_tuned="True", epoch="5", max_input_length="1024"
)
# Fit the model on the training data
estimator.fit({"training": train_data_location})左右滑动查看完整示意
将自定义模型从Amazon SageMaker
导入到Amazon Bedrock
本部分将使用Python SDK创建模型导入任务,获取导入模型ID,并最终生成推理结果。关于如何使用Amazon Bedrock控制台导入模型,可参考前面章节控制台截图。
前面章节
https://quip-amazon.com/L7IhATl9oYmv/Custom-Model-Import-launch-Blog#temp:C:WUYbd68d74a722241fead00bc60f
参数和辅助函数设置
首先创建辅助函数并设置参数,以创建导入任务。导入任务负责从Amazon SageMaker收集模型并将其部署到Amazon Bedrock。这是通过使用create_model_import_job函数来完成的。
导入任务
https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-import-model.html
存储的Safetensors需要进行格式化,使Amazon S3位置成为置顶文件夹。配置文件和Safetensors将按照下图所示的方式存储。
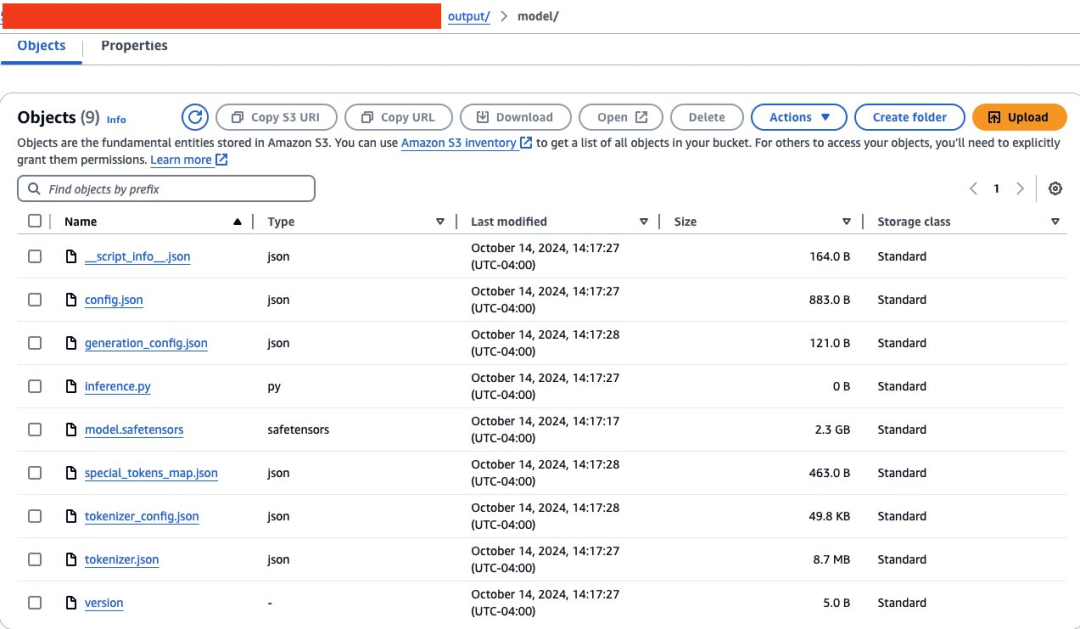
import json
import boto3
from botocore.exceptions import ClientError
bedrock = boto3.client('bedrock', region_name='us-east-1')
job_name = 'fine-tuned-model-import-demo'
sagemaker_model_name = 'meta-textgeneration-llama-3-2-3b-2024-10-12-23-29-57-373'
model_url = {'s3DataSource':
{'s3Uri':
"s3://sagemaker-{REGION}-{AWS_ACCOUNT}/meta-textgeneration-llama-3-2-3b-2024-10-12-23-19-53-906/output/model/"
}
}左右滑动查看完整示意
从响应中检查状态并获取任务ARN
接下来模型将被导入,可以使用get_model_import_job检查任务状态。使用任务ARN来获取导入模型ARN,用它生成推理。
def get_import_model_from_job(job_name):
response = bedrock.get_model_import_job(jobIdentifier=job_name)
return response['importedModelArn']
job_arn = response['jobArn']
import_model_arn = get_import_model_from_job(job_arn)左右滑动查看完整示意
使用导入的自定义模型生成推理
使用invoke_model和Converse API来调用模型。以下是一个支持函数,用于调用模型并从整体输出中提取生成文本。
from botocore.exceptions import ClientError
client = boto3.client('bedrock-runtime', region_name='us-east-1')
def generate_conversation_with_imported_model(native_request, model_id):
request = json.dumps(native_request)
try:
# Invoke the model with the request.
response = client.invoke_model(modelId=model_id, body=request)
model_response = json.loads(response["body"].read())
response_text = model_response["outputs"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)左右滑动查看完整示意
设置上下文和模型响应
最后,可以使用自定义模型。
1、将询问格式化以匹配微调后的提示结构,这将确保生成响应与微调阶段使用的格式匹配,且更符合需求。
2、使用用于格式化微调数据的模板,它来自RAG的解决方案,如Amazon Bedrock知识库。
以下,采用一个示例添加并演示这一概念。
input_output_demarkation_key = "\n\n### Response:\n"
question = "Tell me what was the improved inflow value of cash?"
context = "Amazons free cash flow less principal repayments of finance leases and financing obligations improved to an inflow of $46.1 billion for the trailing twelve months, compared with an outflow of $10.1 billion for the trailing twelve months ended March 31, 2023."
payload = {
"prompt": template[0]["prompt"].format(
question=question, # user query
context=context
+ input_output_demarkation_key # rag context
),
"max_tokens": 100,
"temperature": 0.01
}
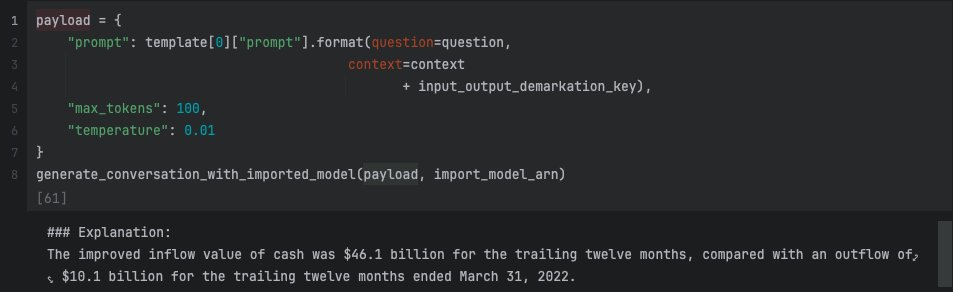
generate_conversation_with_imported_model(payload, import_model_arn)左右滑动查看完整示意
输出将得到以下结果:
将模型完成微调并导入到Amazon Bedrock后,您可向模型发送不同的问题和上下文来进行实验并生成响应,如下例所示:
question: """How did Amazon's international segment operating income change
in Q4 2022 compared to the prior year?"""
context: """Amazon's international segment reported an operating loss of
$1.1 billion in Q4 2022, an improvement from a $1.7 billion
operating loss in Q4 2021."""
response:左右滑动查看完整示意
注意事项
以上示例旨在演示自定义模型导入过程如何代替直接生产(该模型仅针对200个合成数据样本进行训练,因此仅用于测试目的)。
理想情况下,您将拥有更多样化的数据集和更多样本,并针对各自用例使用超参数调整进行持续实验,从而引导模型生成更理想的输出。对于本文示例,请确保将模型temperature参数设置为0,并将max_tokens运行时参数设置为较低值(例如100-150个标记),以生成简洁的响应。您可以尝试使用其他参数来生成理想的结果。有关更多示例,请参阅Amazon Bedrock Recipes和GitHub 。
Amazon Bedrock Recipes
https://aws-samples.github.io/amazon-bedrock-samples/
GitHub
https://github.com/aws-samples/amazon-bedrock-samples/tree/main/custom-models/import_models
使用须知
此功能通过微调模型,为高效托管带来了显著优势。为更好的使用此功能,建议了解以下内容:
在开始任务前,需定义测试套件和验收指标,自动化流程有助于节省时间和精力。
目前需全部包含模型权重(包括适配器权重)。合并模型有多种方法,建议通过实验确定合适选项。自定义模型导入功能可帮助您按需测试模型。
创建导入时,请在任务名称中添加版本控制,以快速跟踪模型状态。目前暂不提供模型版本控制。请注意每次导入都是一系列单独步骤,并会创建单独模型。
模型权重支持的精度为FP32、FP16和BF16,需要分别测试以验证是否适合您的用例。
模型最大并发数为每个帐户16个模型,更高并发请求将导致服务扩展并增加模型副本数。
您使用的模型副本由Amazon CloudWatch提供,有关更多信息,请参阅将自定义模型导入Amazon Bedrock 。
Amazon CloudWatch
https://aws.amazon.com/cloudwatch
将自定义模型导入Amazon Bedrock
https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-import-model.html
截至撰写本文时,该功能仅在US-EAST-1和US-WEST-2亚马逊云科技区域可用。更多区域的上线情况请关注亚马逊云科技区域的模型支持,获取最新动态。
区域的模型支持
https://docs.aws.amazon.com/bedrock/latest/userguide/models-regions.html
每个帐户的默认导入配额为3个模型。如果您的用例需要更多模型,请与您的帐户团队合作以增加帐户配额。
此功能的默认限制为每个帐户/每秒100次调用。
您可以使用sample notebook对导入模型进行性能测试(此方法仅供参考,建议运行完整性能测试、端到端测试及功能和评估测试)。
sample notebook
https://aws.amazon.com/ec2/capacityblocks/
现已正式可用
Amazon Bedrock自定义模型导入功能现已在US-East-1(弗吉尼亚北部)和US-West-2(俄勒冈) 亚马逊云科技区域的Amazon Bedrock中正式推出。请参阅完整区域列表获取最新动态。
完整区域列表
https://docs.aws.amazon.com/bedrock/latest/userguide/models-regions.html
扫码下方二维码,立即体验Amazon Bedrock提供的各类基础模型!

本文作者
Paras Mehra,亚马逊云科技高级产品经理
Jay Pillai,亚马逊云科技首席解决方案架构师
Shikhar Kwatra,亚马逊云科技高级合作伙伴解决方案架构师
Claudio Mazzoni,亚马逊云科技高级生成式AI解决方案架构师
Yanyan Zhang,亚马逊云科技高级生成式AI数据科学家
Simon Zamarin,亚马逊云科技人工智能与机器学习解决方案架构师
Rupinder Grewal,亚马逊云科技高级人工智能与机器学习解决方案架构师


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!



















 9437
9437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









