







针对之前学到的所有知识,针对心脏病项目的数据集来完成数据的预处理。
一、数据的读取与查看
import pandas as pd
# 读取数据,查看特征
data = pd.read_csv(r'heart.csv')
data.columns.to_list()
# 原名不容易理解,换个名
data.columns = ['age',
'sex',
'chest_pain_type',
'resting_blood_pressure',
'cholesterol',
'fasting_blood_sugar',
'rest_ecg',
'max_heart_rate_achieved',
'exercise_induced_angina',
'st_depression',
'st_slope',
'num_major_vessels',
'thalassemia', 'target']
# 查看数据信息
data.info()
data.shape # 查看数据的形状
# 所有特征的类型
data.dtypes
# bool形式查看缺失值
data.isnull()
# 各特征缺失值个数
data.isnull().sum()
# 数字特征
data.describe()
# 特征下各类别的数量
data['target'].value_counts()二、补全缺失值
练习:均值\中位数(median)\众数(mode)补全缺失值,实际本数据集无缺失值
- 连续值推荐用众数,排除特别大和特别小的异常值的影响
- 离散值推荐用众数,不能用中位数和平均数
# for循环判断找出数值型类型
for i in data.columns:
if data[i].dtype == 'int64' or data[i].dtype == 'float64':
# 判断是否有缺失值
if data[i].isnull().sum() > 0:
# 中位数填补缺失值
median = data[i].median()
data[i].fillna(median, inplace=True)
# 检查是否有缺失值
data.isnull().sum() 三、离散特征独热编码
# 找出离散特征
discrete_features = []
all_features_names = data.columns.to_list()
for i in all_features_names:
if data[i].dtype == 'object':
discrete_features.append(i)
# 对离散特征进行独热编码
data = pd.get_dummies(data, columns=discrete_features, drop_first=True)
# 对比找出新增的特征
new_features = []
for i in data.columns:
if i not in all_features_names:
new_features.append(i)
# 新特征的bool型转换为int型
for i in new_features:
data[i] = data[i].astype(int)四、数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np1、单个连续特征 箱线图boxplot
plt.figure(figsize=(10, 6))
sns.boxplot(x='st_depression', data=data)
plt.xlabel('st_depression')
plt.title('Box Plot of st_depression')
plt.show()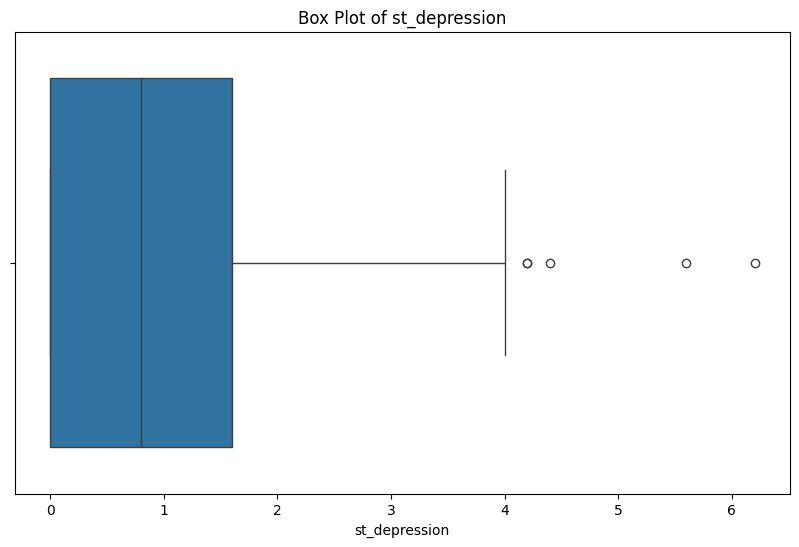
2、单个离散特征 直方图histplot
# 设置全局字体为支持中文的字体,例如SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 同时绘制几个单特征的直方图
# 好多图函数分别使用seaborn和matplotlib实现
# seaborn创建的图更美观,自动实现图的调整,内置hue参数可以实现分类
# 但matplotlib创建的图更灵活,需要手动调整图的大小、间距、字体等,是一些基础的图
# 定义列表 存储需要绘制直方图的特征名称
features_to_plot = ['age', 'chest_pain_type', 'resting_blood_pressure', 'rest_ecg']
# 从数据集data选取指定特征绘制直方图,bins参数设置直方图的柱子数量,figsize参数设置图的大小
data[features_to_plot].hist(bins=30, figsize=(16, 10))
# 设置主标题
plt.suptitle('特征直方图')
plt.show()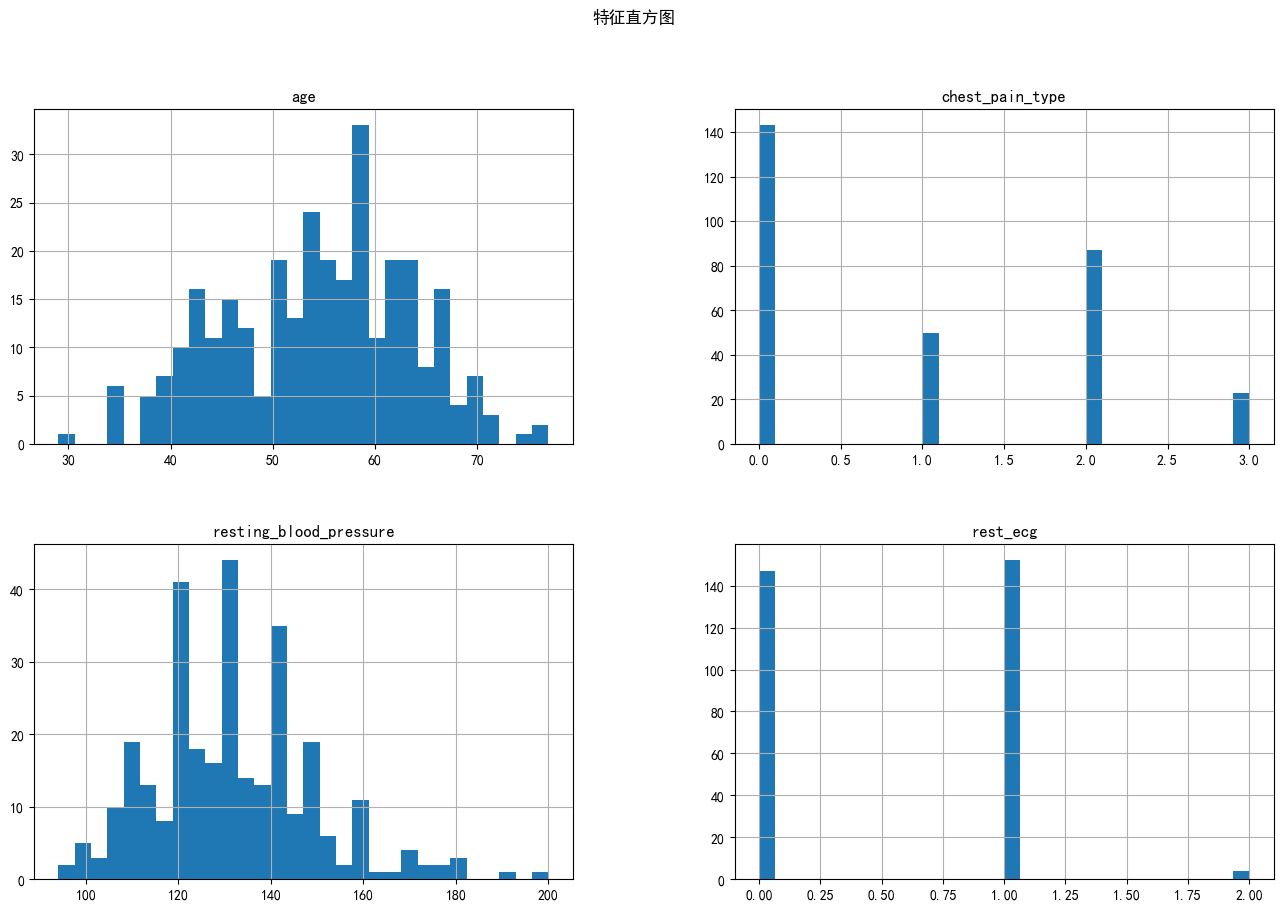
3、特征和标签的关系
1.连续特征和标签
- 横坐标:标签
- 纵坐标:连续特征
plt.figure(figsize=(10, 6))
sns.boxplot(x='target', y='st_depression', data=data)
plt.title('st_depression vs. target')
# x、y轴标签名默认为坐标轴所代表的特征名称,可通过xlabel()和ylabel()进行修改
# plt.xlabel('心脏病诊断')
# plt.ylabel('休息引发的ST下降')
plt.show()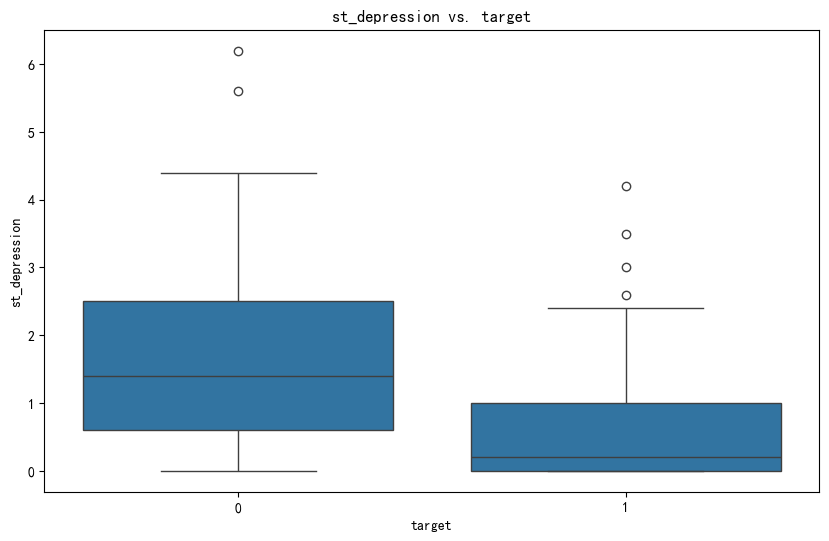
plt.subplot(1, 3, 1) 在画布中规划一个1行3列的子图布局,并指定后续绘图将在第一个位置(最左侧)进行绘制
# 绘制age与target的关系图
plt.subplot(1, 3, 1)
sns.boxplot(x='target', y='st_depression', data=data)
plt.title('st_depression vs target')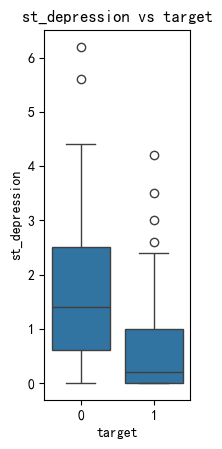
2.绘制age的核密度直方图
# 绘制age的核密度直方图
plt.figure(figsize=(10, 6))
sns.histplot(x='age', hue='target', data=data, kde=True, element='step')
plt.title('Age Distribution')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.show()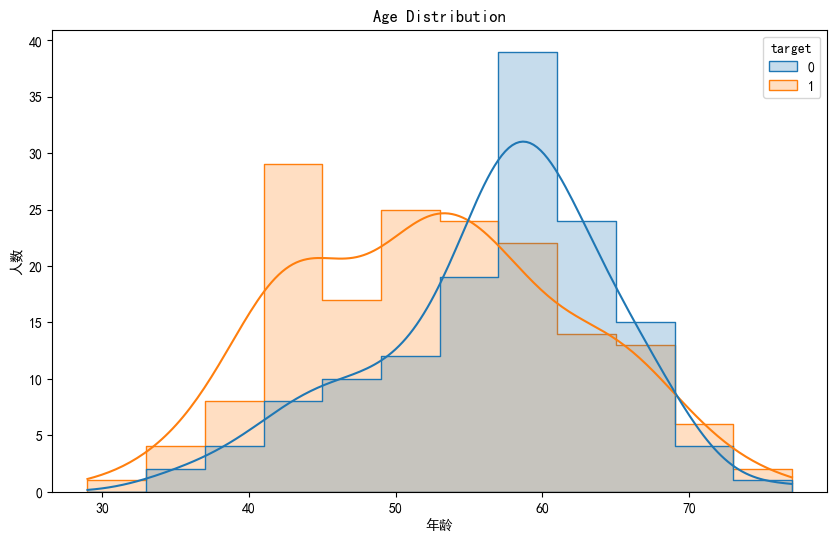


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









