









 实验对比了基于词典的正向、逆向、双向最长匹配分词方法,以及使用Viterbi算法进行词性标注的效果和效率。结果显示,正向与逆向最长匹配在分词和词性标注上表现接近,双向略有下降,而处理txt文件效率高于csv。
实验对比了基于词典的正向、逆向、双向最长匹配分词方法,以及使用Viterbi算法进行词性标注的效果和效率。结果显示,正向与逆向最长匹配在分词和词性标注上表现接近,双向略有下降,而处理txt文件效率高于csv。
一.实验要求
1. 实现基于词典的分词方法和统计分词方法:两类方法中实现一种即可;
2. 对分词结果进行词性标注,也可以在分词的同时进行词性标注;
3. 对分词及词性标注结果进行评价,包括 4 个指标:正确率、召回率、F1 值和效率。
二.实现环境
ASUS VivoBook + Win10 + Pycharm 2021.2.3 + Python 3.9 + Anaconda 3.7
三.实验内容
首先,基于 HanLP 自然核心词典,我们使用正向最长匹配、逆向最长匹配及双向最长匹配三种方法,对网络文章及人民日报语料两份素材进行分词(提供了对 txt 和 csv 两种保存格式的素材的分词接口),并结合作业二中对网络文章的手工分词结果及人民日报语料的已有分词结果进行比较,计算三种分词方法的 Precise、Recall 及 F-measure 值,进而评价分词的效果,使用计时器获得分词时间,进而评价分词的效率。接着,基于人民日报词性标注语料库,我们根据前边得到的人民日报语料的分词结果,使用 Viterbi 算法对其进行词性标注,并结合语料库中手工词性标注的结果进行比较,计算由三种分词方法得到的分词结果对应的词性标注的 Precise、Recall 及 F-measure 值,进而评价预料标注的效果,使用计时器获得词性标注时间,进而评价分词的效率。
四.实验过程
4.1 分词
4.1.1 程序结构
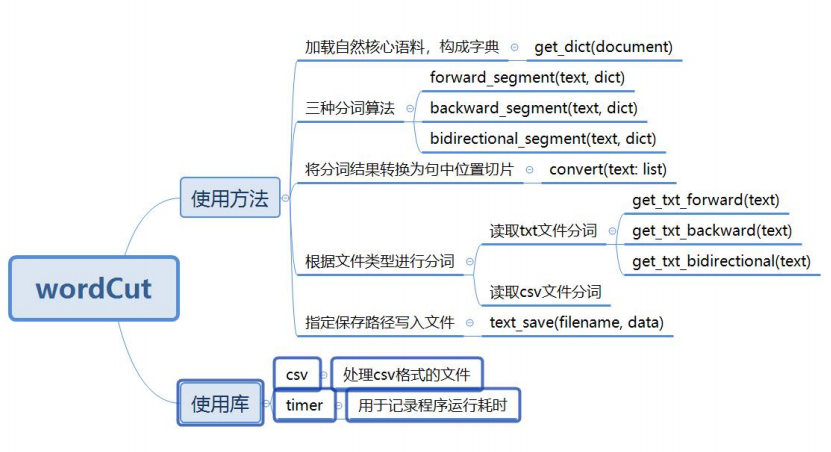
4.1.2 算法设计
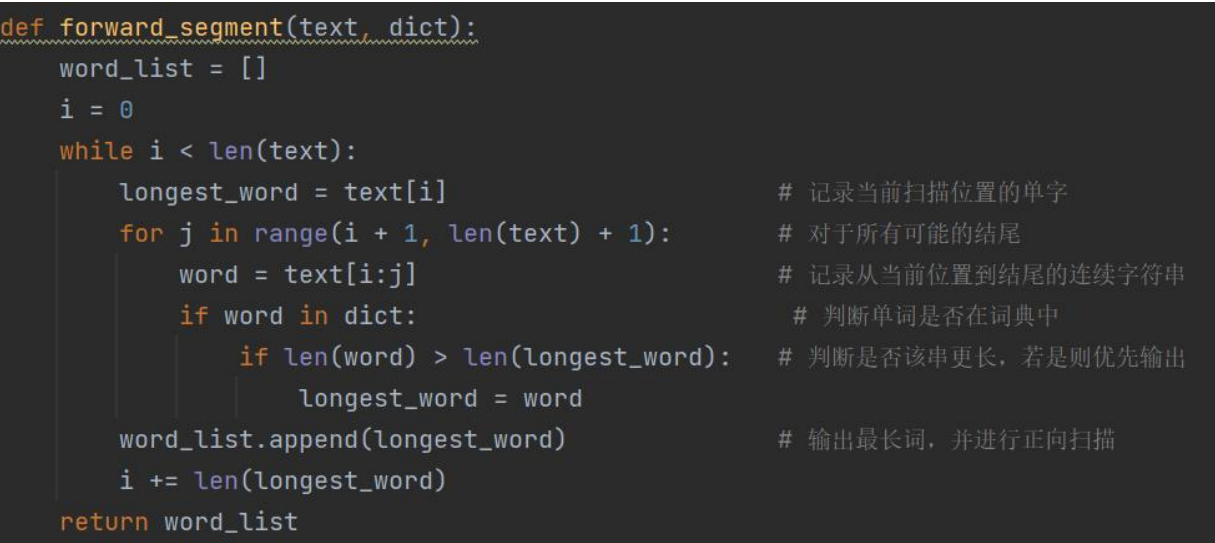
本代码的核心算法是三种分词算法,实现思路见代码注释。
正向最长匹配:
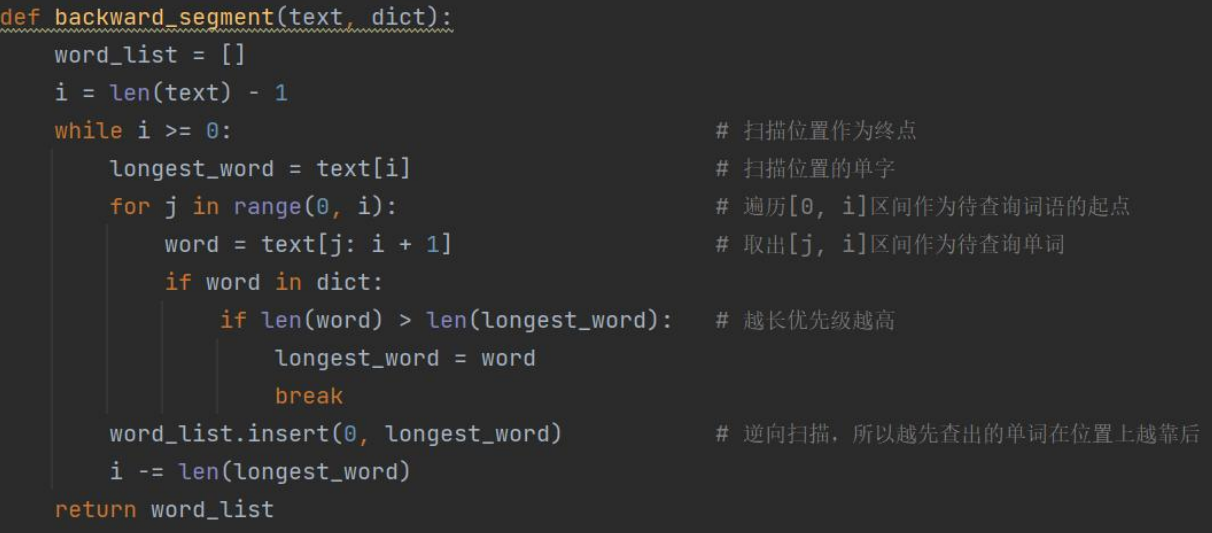
逆向最长匹配:
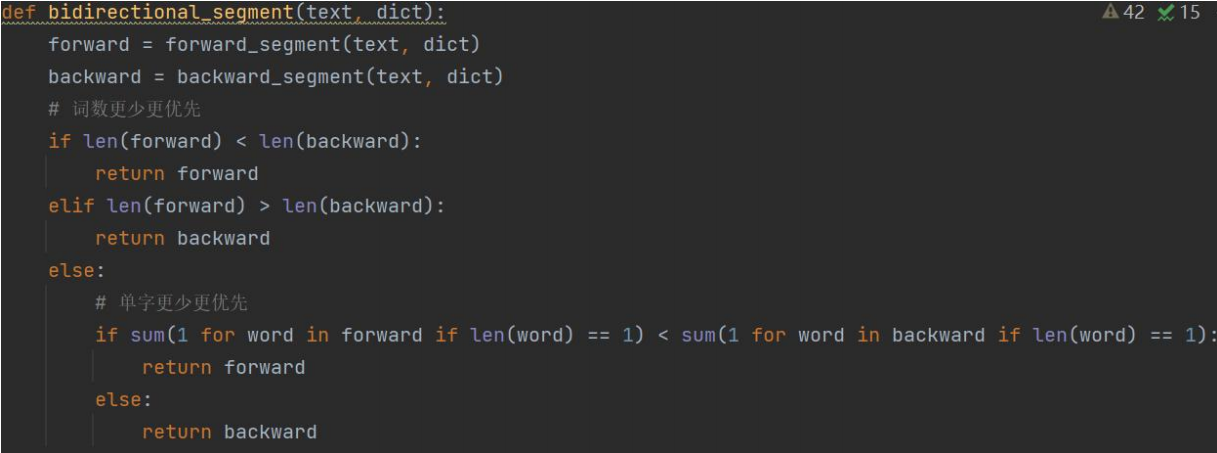
双向最长匹配:
4.1.3 程序运行及结果
在检验分词算法的效果和效率时,我们选用了两份素材,对于网络文章,各算法的运行结果如下:
yuxiuhua.txt:
正向最长匹配:
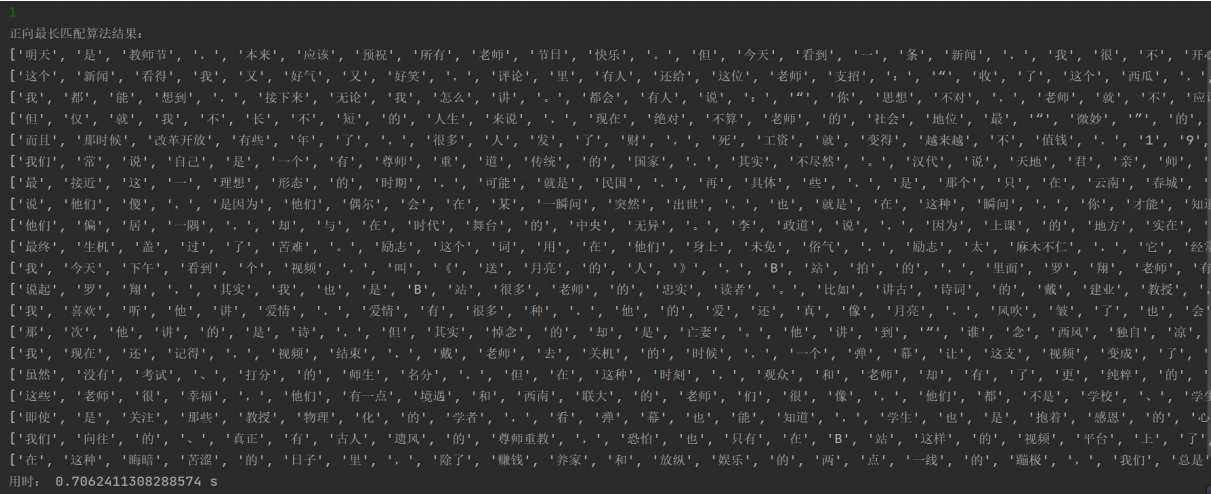
逆向最长匹配:
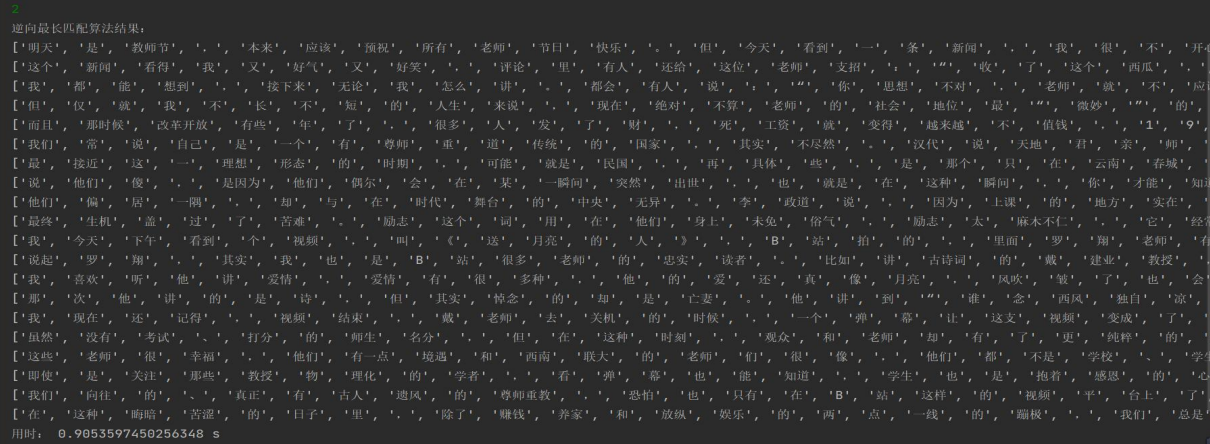
双向最长匹配:
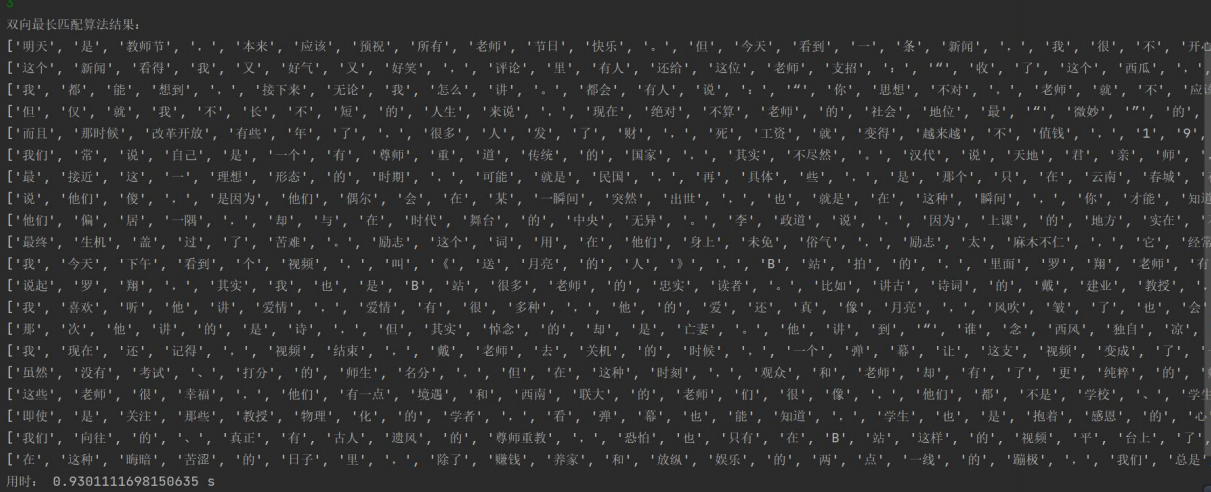
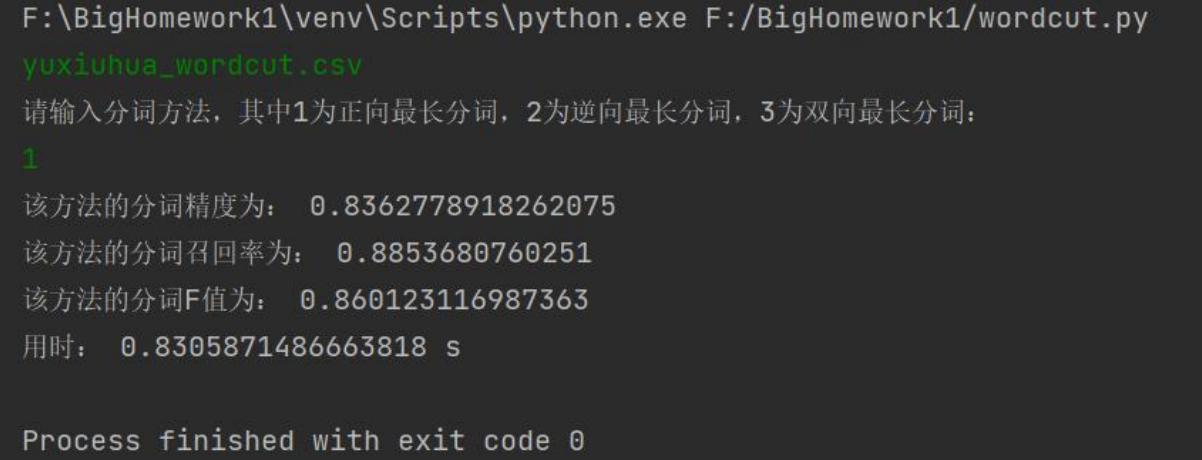
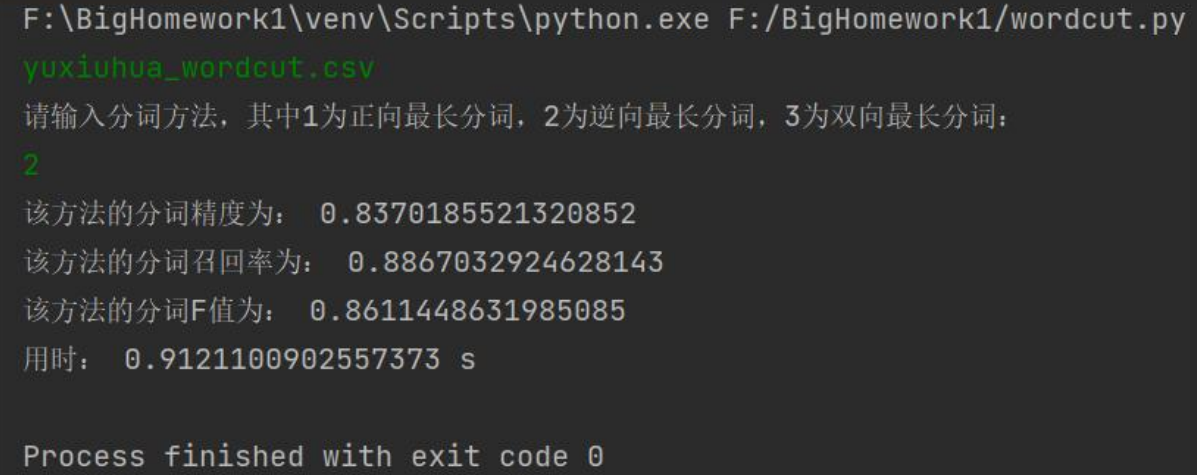
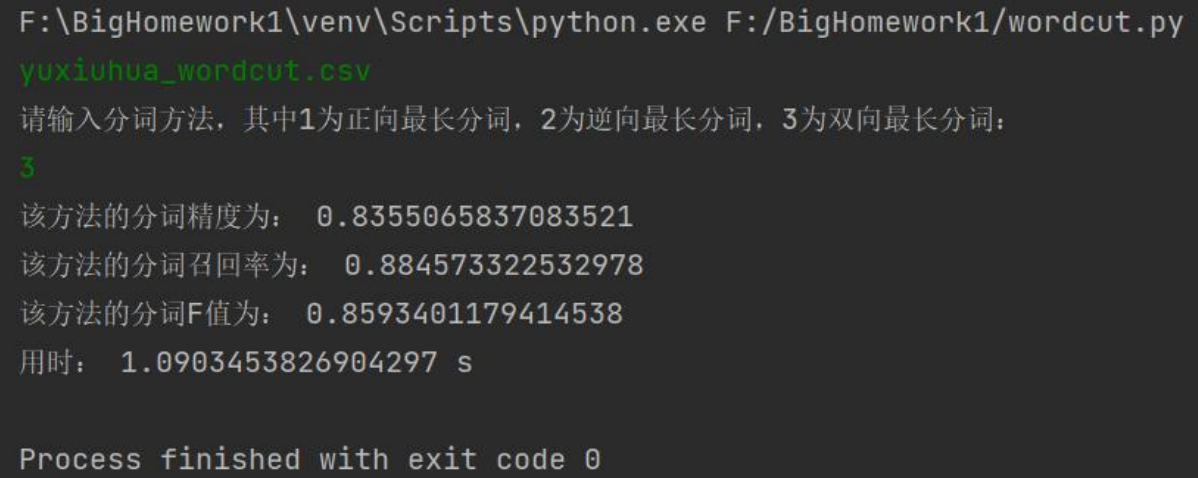
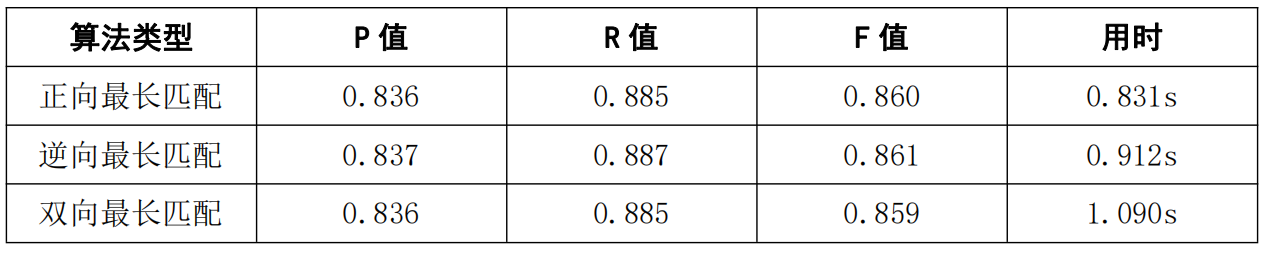
yuxiuhua_wordcut.csv:
正向最长匹配:
逆向最长匹配:
双向最长匹配:
corpus.csv:
正向最长匹配:
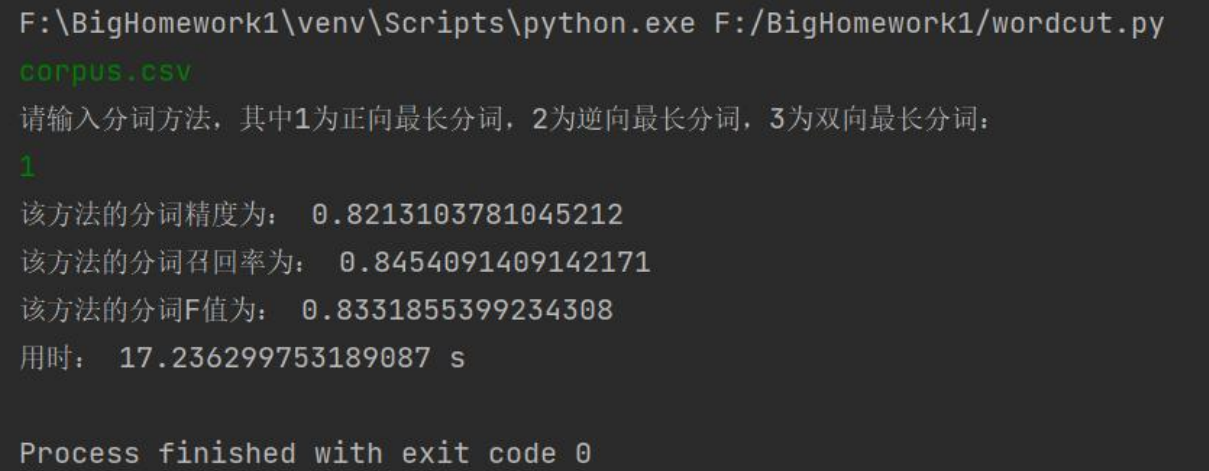
逆向最长匹配:
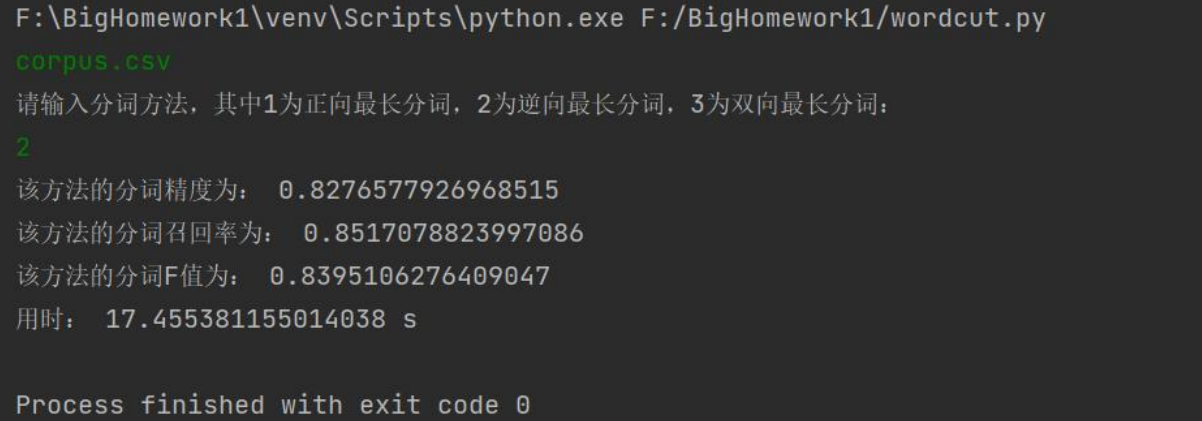
双向最长匹配:
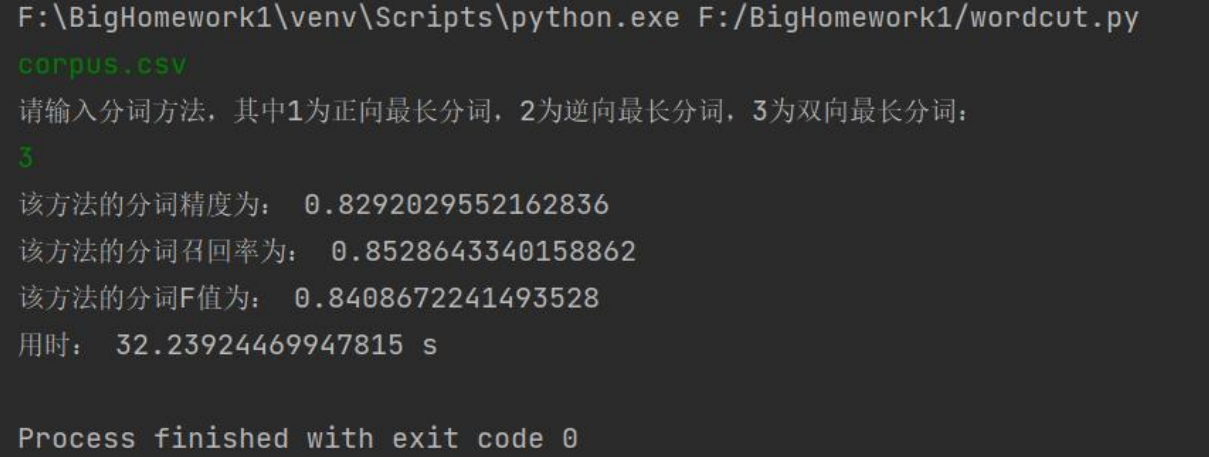
4.2 词性标注
4.2.1 程序结构

4.2.2 算法设计
本代码的核心算法是 Viterbi 算法,实现思路见代码注释。
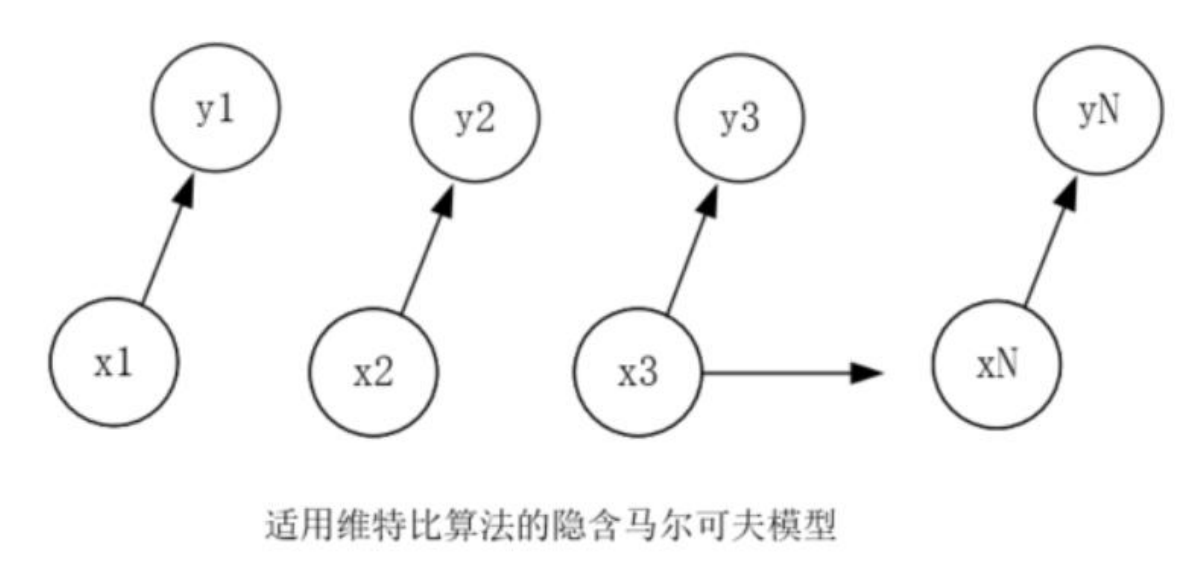
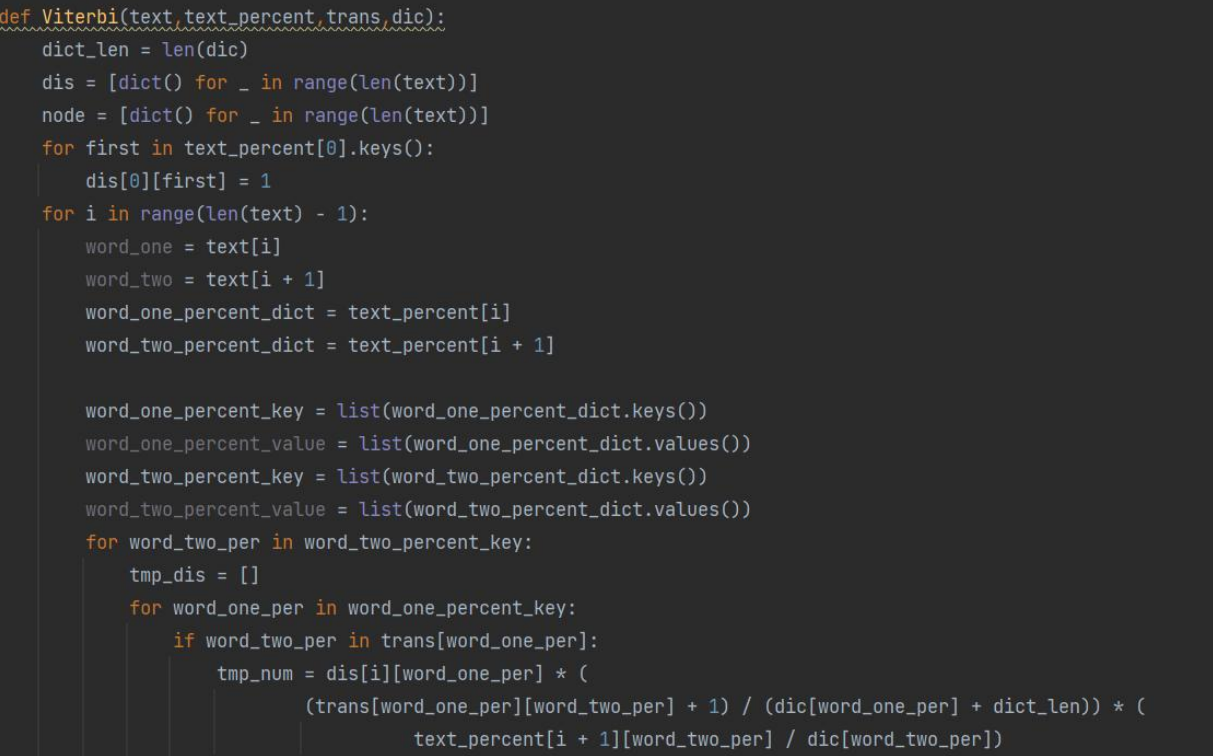
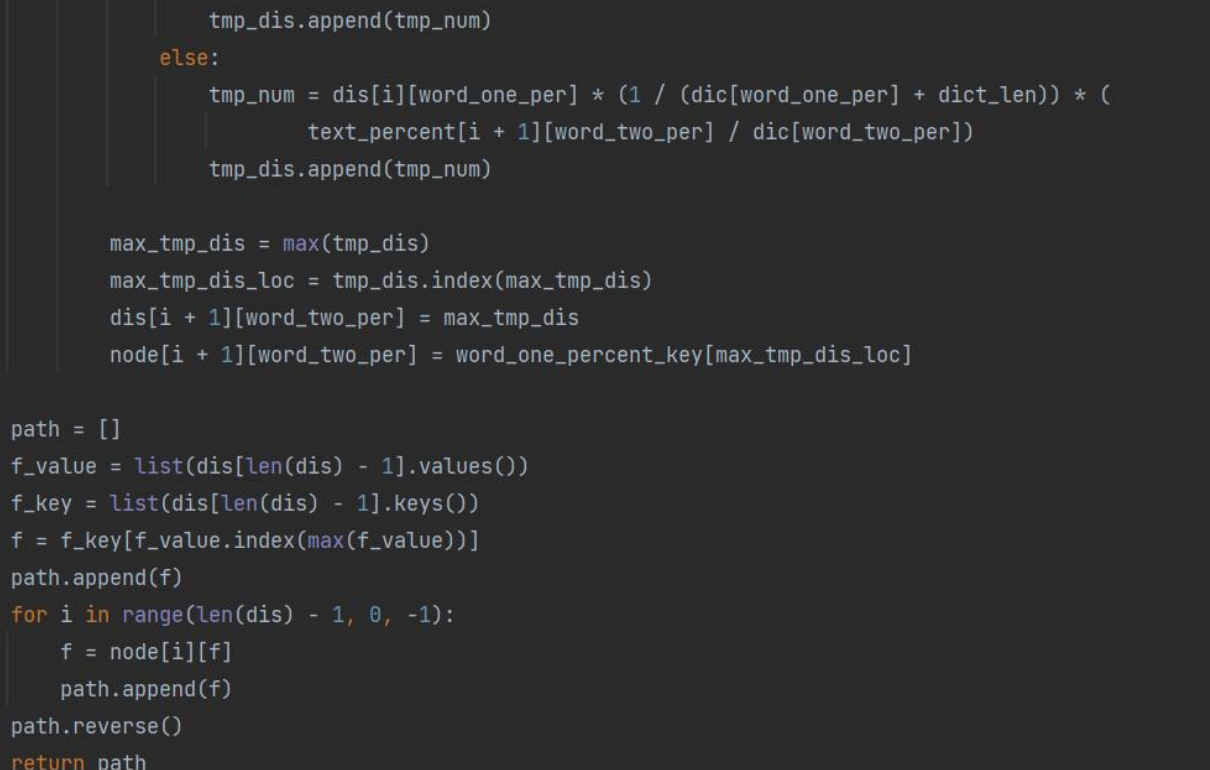
4.2.3 程序运行及结果
fortrain_forward.txt:
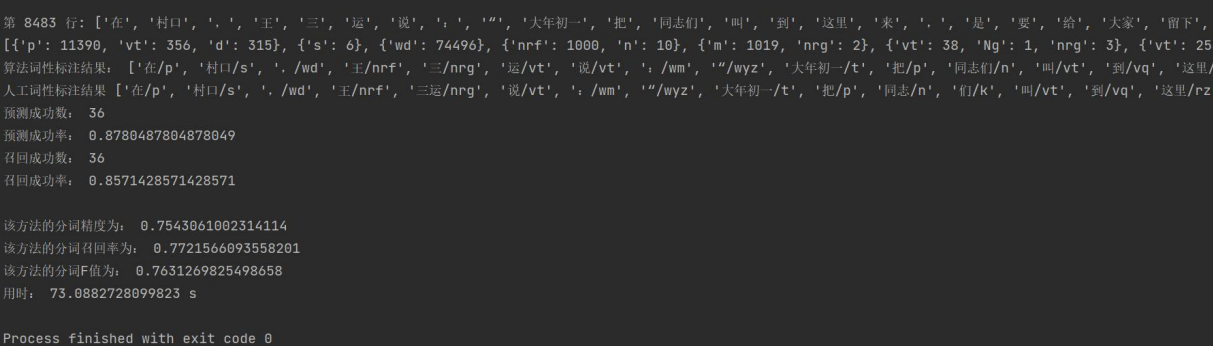
fortrain_backward.txt:
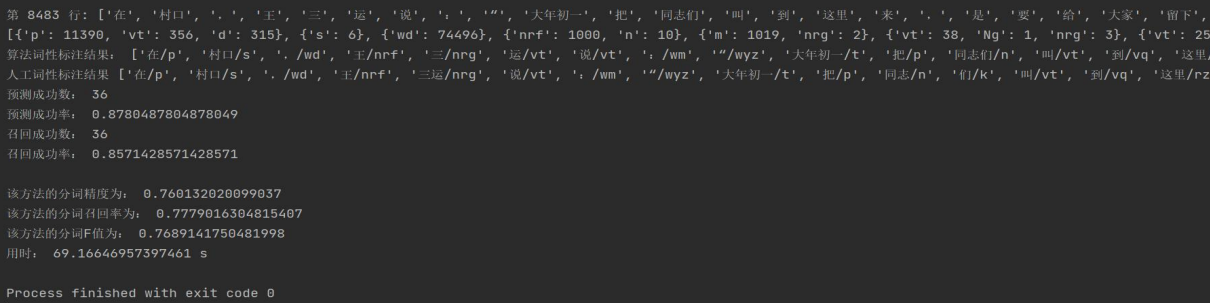
fortrain_bidirectional.txt:
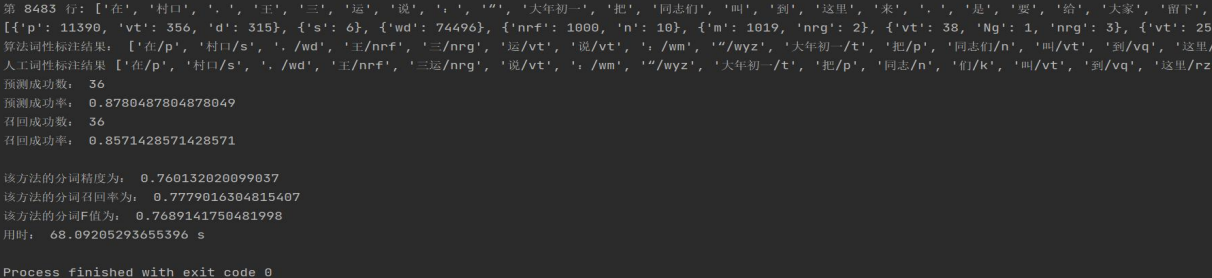
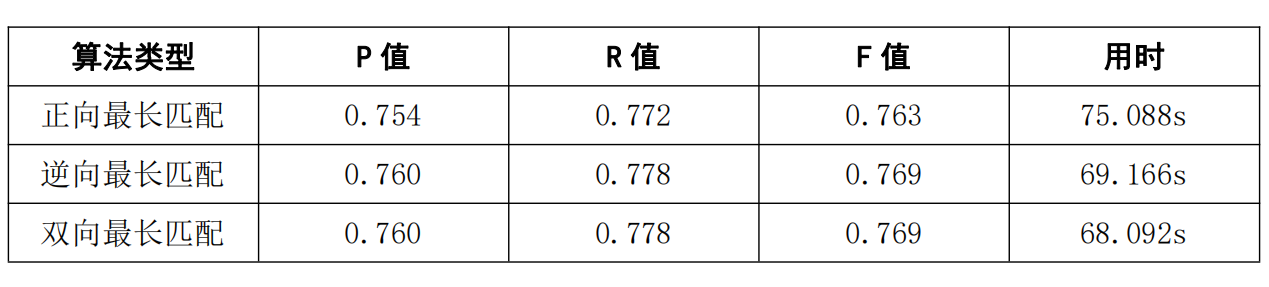
五.实验结论
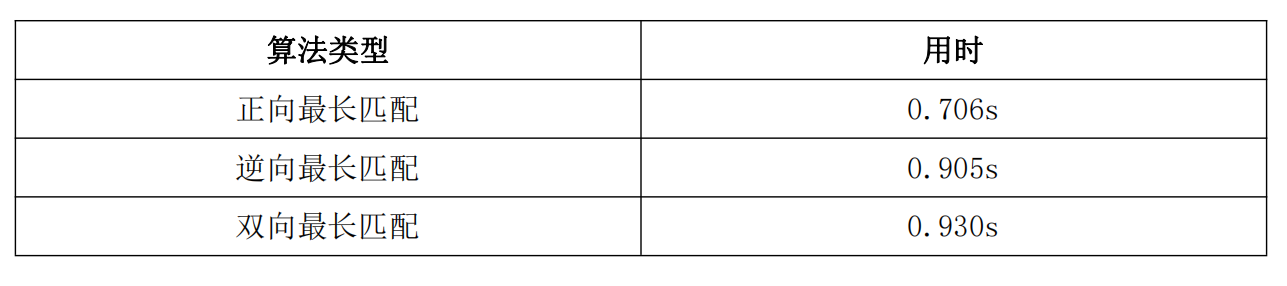
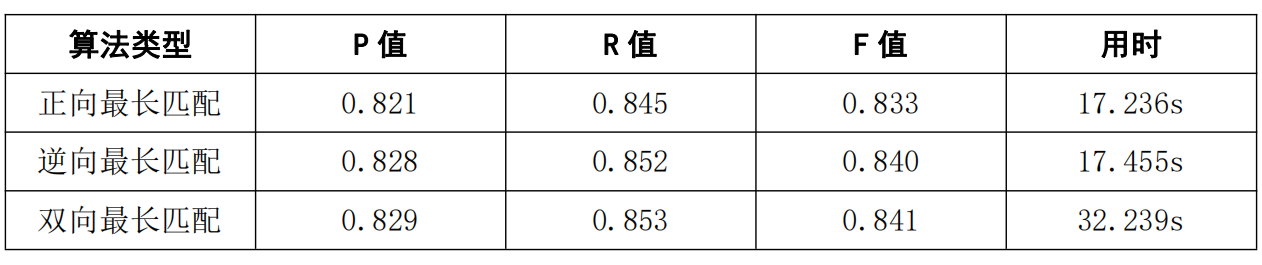
最终,基于本次实验,我们得出结论,就分词效果而言:正向最长匹配 < 逆向最长匹配 ≈ 双向最长匹配,就分词效率而言:正向最长匹配 ≈ 逆向最长匹配 > 双向最长匹配;就词性标注效果而言:正向最长匹配 < 逆向最长匹配 ≈ 双向最长匹配,就词性标注效率而言,正向最长匹配 < 逆向最长匹配 < 双向最长匹配。此外,我们发现,处理 txt 文件比 csv 文件的效率更高。
项目源码及实验报告:https://github.com/YourHealer/NLP-Dictionary-based-segmentation-method.git


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











