









在这里主要展示数据的预处理过程,以及对于生还情况与各特征之间的关系。
1.数据探索
我们首先对样本数据集的结构,规律和质量进行了分析,从数据质量分析和数据特征分析等两个角度进行展开。
1.1 数据质量分析
训练集train.csv中样本共891个,包括以下12个特征:
| 特征名 | 含义 | |
| PassengerID | 乘客ID | |
| Survived | 是否生还 | |
| Pclass | 船舱级别 | |
| Name | 姓名 | |
| Sex | 性别 | |
| Age | 年龄 | |
| SibSp | 兄弟姐妹与配偶的总数 | |
| Parch | 父母和孩子的总数 | |
| Ticket | 船票ID | |
| Fare | 票价 | |
| Cabin | 舱室 | |
| Embarked | 出发港口 | |
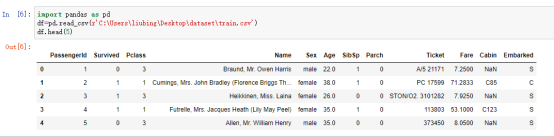
对训练数据集中的数据缺失情况进行了查看,知列Age共缺失177项,列Cabin缺失687项,出发港口缺失2项:
使用info()函数来观察一下特征取值的情况:

使用describe()函数再来看看数值数据的具体统计情况,该函数会返回数值特征的统计情况:
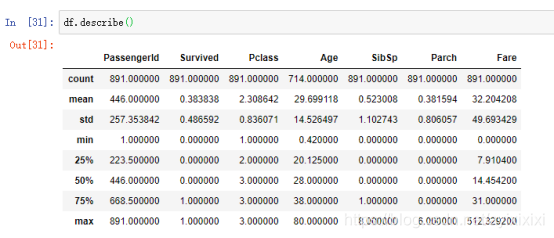
可知年龄的中位数为28。
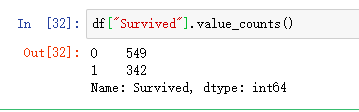
训练集中生还人数情况:生还人数为342人。
1.2 数据特征分析
接下来我们探索是否生还(列Survived)与其他各特征的联系。
(1)性别与生还情况的关系
首先针对性别与是否生还的关系进行研究,使用Tableau进行可视化发现,图1显示总训练数据集中的男性乘客要多于女性乘客,但是由图2中性别的生还概率老看,女性乘客的生还概率显著高于男性乘客:
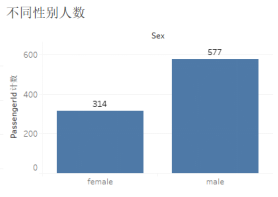
图 1:不同性别对应人数
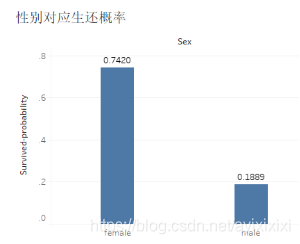
图 2:性别对应生还概率
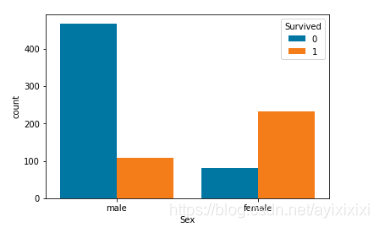
图 3:性别对应生还人数-未生还人数
由图3可知,橙色标志着生还人数,蓝色标志着未生还人数,与未生还人数相比,女性的生还人数显著比较高,并且在男性本身多于女性的条件下看到女性生还的人数还比男性多,那么我们有理由相信,逃生的时候优先让女性先逃生。
(2)年龄与生还情况的关系
下面我们对年龄与生还情况的关系进行探究,我们发现孩子的生还情况显著好于其他组别。据此,我们有理由相信逃生过程中船员让女人和小孩先上救生艇。
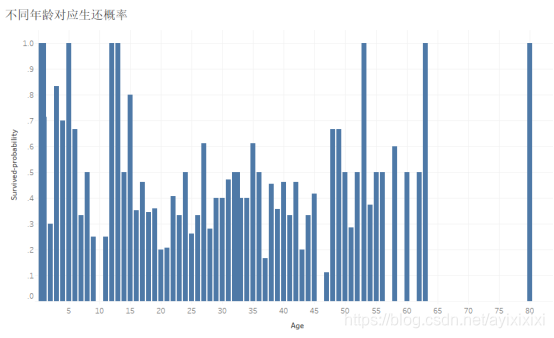
图 4:各年龄乘客对应生还概率
对年龄分为5个区间,查看每个区间的生还概率,可以看到在第一个区间内的生还概率最高,即孩子更容易生还:
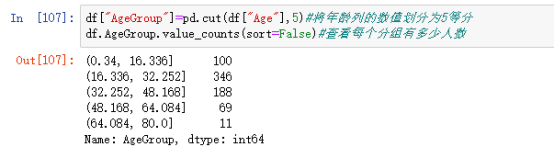
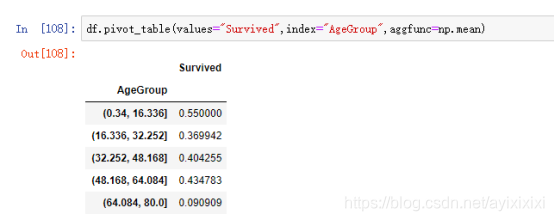
图 5:5个年龄区间各自对应的生还概率
(3)票价、舱级与生还情况的关系
同时我们发现,乘客的生还情况与票价也有相关关系,与舱的级别也有关系。因为一等舱距离救生舱的距离最近,而且一等舱也就是价格最高的舱,并且确实票价高的生还的情况确实比票价低的生还情况要好。从图6中可以清楚地看出Pclass类别为1的生还概率最高,高达63%,其次就是类别为2,其生还概率为47.3%%,生还概率最少的类别为3,其生还概率为24.2%。由图8也能看出,虽然一等舱乘客人数最少,但是生还的人数却最多,也表现出舱级高,生还概率大的现象。
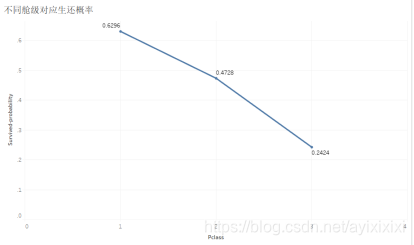
图 6:不同舱级对应生还概率
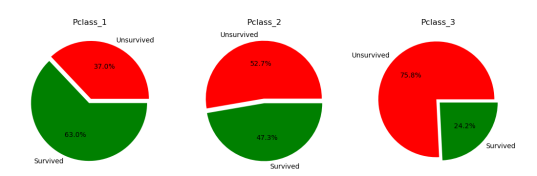
图 7:不同舱级生还概率-未生还概率
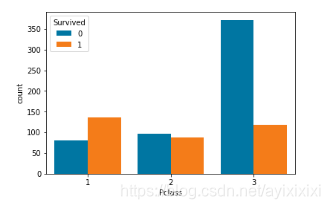
图 8:不同舱级生还人数
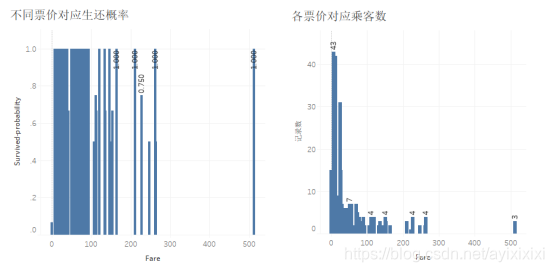
图 9:不同票价对应生还概率
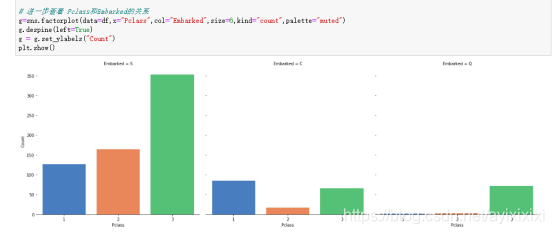
(4)Embarked与生还情况的关系
显示出来在港口C上船的乘客生还概率最大,猜测是不是与票价相关,从C港口上船的人是不是更多的在买舱级高的票,换句话说,票价更高的船票。在这里可以视Embarked的中位数为Q,为了后面填补空缺值。
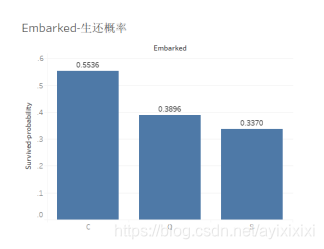
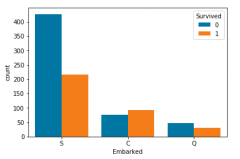
图 10:Embarked对应生还人数-未生还人数情况
查看是否与舱级相关:
可以看到“C”港口登船的乘客中一舱级的乘客数量跟从C港口上船的乘客总数相比所占的比例确实要比其他两个港口高很多。所以我们推测跟生还情况与舱级有关,其实根本上还是与价格相关,因为越贵的位置越靠近逃生点,越容易生还。
(5)部分特征与生还情况没有显著关系
同时我们发现,部分样本特征与生还率没有显著关系。例如兄弟姐妹与配偶的总数(SibSp)、父母和孩子的总数(Parch),这些也是与我们的预期是一致的,因为兄弟姐妹与配偶的总数、父母和孩子的总数与是否生还没有明显任何关系,有明显的关系也是与年龄相关,这一相关在年龄部分已经解释过。

图 11:Parch/SibSp对应生还概率
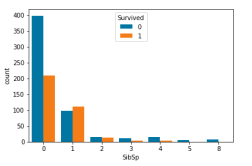
图 12:SibSp对应生还人数-未生还人数情况
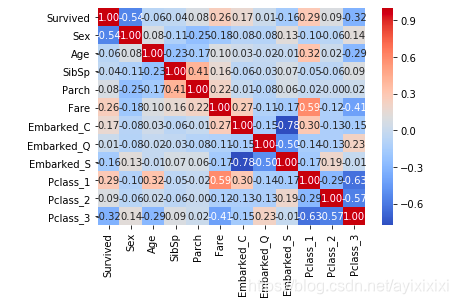
(6)相关系数矩阵
最后,我们对所有样本特征作了相关系数矩阵。从图中可以看到Fare、Pclass、Sex这三个特征与生还率有较大的关联。
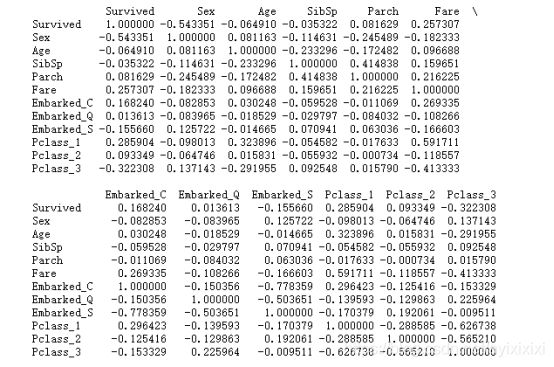
图 13:乘客信息各特征与生存情况的相关系数矩阵
2 数据预处理
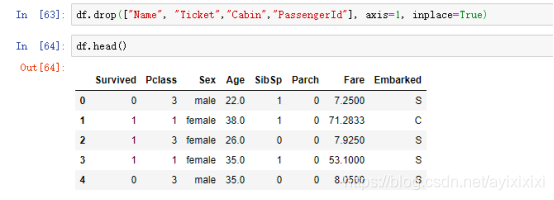
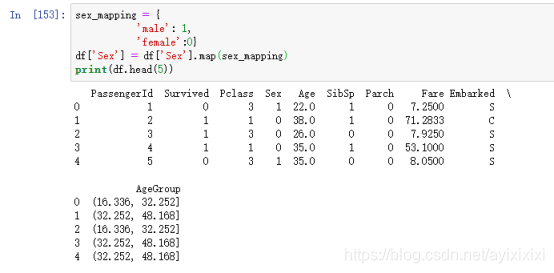
在数据探索的基础上,我们对原始数据进行了预处理,以提高数据挖掘的质量,降低实际挖掘所需要的时间。PassengerID 乘客ID, Name姓名, Ticket船票ID只是作为标签,与乘客的生还没有直接关联,故删除它们。对于Cabin舱室特征,由于缺失值太多(超过所有样本的2/3)难以补全,故也删除它们。并且将性别中的男对应为1,女对应为0.
(1)删除不需要的列
(2)将‘男’表示为1,‘女’表示为0
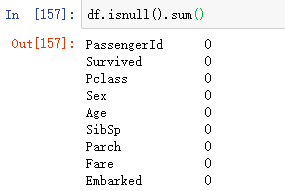
(3)填补缺失值
填补缺失值,使用中位数值进行填补:

填补缺值之后显示当前训练集中各特征缺失数据量显示为0:
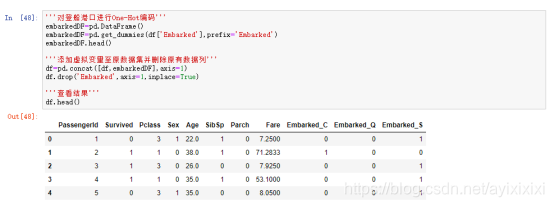
(4)对于Pclass船票级别和Embarked出发港口两个特征,我们进行了one-hot编码。
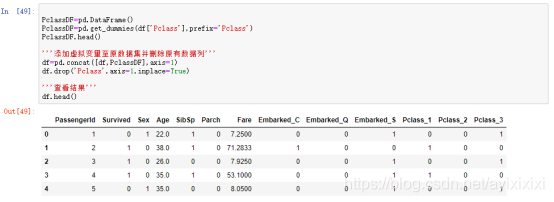
(5)对数据进行0-1标准化。
3. 模型建立
使用多层感知机(MLP)、K-近邻分类器、随机森林、支持向量机(SVM)和Adaboost对训练系进行训练,并对测试集进行测试。由于各种方法都有各自的优势,为了避免偶然性和随机性,在对各模型的预测结果进行评估后,我们将采用voting classifier对各分类方法赋予一定的权重,即分类结果较好的方法赋予较大的权重、结果较差的赋予较小的权重,得到最终的测试集分类结果,并根据test_label.csv中的标签信息判断我们是否已经达到较好的分类效果。
4. 特征选择与模型选择
在数据探索的过程中,我们已经排除了部分对最终分类结果无太大影响或不适合参与预测的特征(如name、cabin、ticket、SipSp、Parch)。我们在运用随机森林模型时,也发现Fare、Age、Sex这三个变量的重要性十分突出。

而从题目的实际背景上来看,这一结果是符合真实情况的。在灾难性事件发生时,的确大多数遵循了“妇女优先、儿童优先”的准则,使这两类人群存活率大幅提升。另一个属性,票价,则是乘客经济能力、社会地位的综合反应。乘客的身份也是在关键时刻是否能搭上救生艇的重要因素。而这些突出的特征也在一定程度上可以解释我们最终得到的预测结果。
展示各个模型对测试集的预测结果:
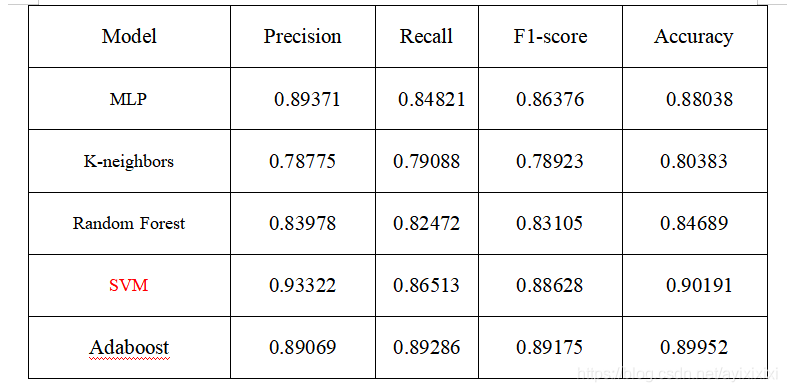
从中,我们可以看出SVM的分类效果高于其他分类模型。
最后,我们综合了多层感知机(MLP)、K-近邻分类器、随机森林、支持向量机(SVM)模型建立了投票模型。投票模型对测试集的预测率达到了100%,是令人满意的。

在检查测试集数据后,发现导致过高的模型预测准确率的原因之一是因为测试集数据本身的因素,仅根据性别、年龄、票价等个别属性就可以达到很好的分类效果。这也就是预测结果反而比对训练集交叉验证还要好的原因。
6. 结论
在数据探索过程中,我们发现女性乘客与小孩生还率更高,而三等舱乘客生还率较低。
在模型建设过程中,我们综合了多层感知机(MLP)、K-近邻分类器、随机森林、支持向量机(SVM)模型对泰坦尼克号乘客的生还情况独立投票建立了预测模型。该投票模型对测试集的预测率达到了100%,是令人满意的。

















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









