







1 概述
先大体分析数据特性,然后分析Survived、Pclass、Sex、Age的数据,最后使用这些svm模型做训练和预测。
2 数据整体分析
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
data = pd.read_csv("泰坦尼克幸存者_all.csv")
# pandas 常用数据结构:DataFrame
print(len(data)) # 样本总数891条数据
print(data.shape) # 表示行数、列数
print(data.info()) # 信息
print(data.values) # 打印数值
print(data.columns) # 列名
print(data.index) # 行名
print(data.head(5)) # 前5行
print(data.tail(5)) # 后5行
# 总体幸存率=幸存人数/总人数
# 1 sum(列)/总数据量,
# 问题1:取出某一列:
# 问题2:数据总量:len(data)
# 取单独的列 方式1:
s = data.Survived
# 取单独的列 方式2:
s2 = data["Survived"]
结果展示:
891
(891, 12)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
[[1 0 3 ... 7.25 nan 'S']
[2 1 1 ... 71.2833 'C85' 'C']
[3 1 3 ... 7.925 nan 'S']
...
[889 0 3 ... 23.45 nan 'S']
[890 1 1 ... 30.0 'C148' 'C']
[891 0 3 ... 7.75 nan 'Q']]
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
RangeIndex(start=0, stop=891, step=1)
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]
PassengerId Survived Pclass ... Fare Cabin Embarked
886 887 0 2 ... 13.00 NaN S
887 888 1 1 ... 30.00 B42 S
888 889 0 3 ... 23.45 NaN S
889 890 1 1 ... 30.00 C148 C
890 891 0 3 ... 7.75 NaN Q
[5 rows x 12 columns]
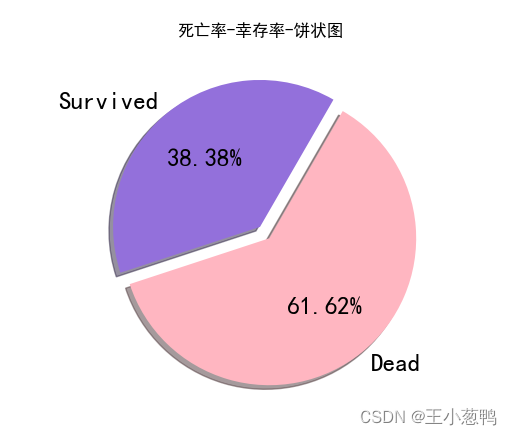
3 死亡率-幸存率分析
# 计算幸存率
sr = sum(s) / len(data)
print(sr) # 保留两位小数点
# 计算死亡率
dr = 1 - sr
print(dr)
0.3838383838383838
0.6161616161616161
使用饼状图展示:
## 绘制饼状图
print("------------饼状图---------")
# 1 导入包 import matplotlib.pyplot as plt
# 2 导入数据
# 3 绘图
# 4 显示图像
# 为了使图像更好看:添加图例、修改颜色、设置字体
sdr = [sr, dr] # [0.38, 0.62]
labels = ["Survived","Dead"]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title("死亡率-幸存率-饼状图")
explode = (0,0.1)
colors = ['mediumpurple','lightpink'] # 颜色
plt.pie(sdr, # 数据
labels=labels, # 标签
autopct='%3.2f%%', # 显示百分比
colors=colors, # 颜色
textprops={'fontsize':18,'color':'k'}, # 文本属性,文字大小颜色
explode=explode, #饼的分离程度
shadow=True, # 阴影
startangle=60)
plt.show() #显示用
4 船舱等级分析
4.1 船舱等级单个变量分析
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
data = pd.read_csv("泰坦尼克幸存者_all.csv")
# 1 取出Pclass这一列
p = data.Pclass
# 2 判断这一列等于1是哪些值
p1 = p == 1
# 3 计算这些值的数量
p1_s = p[p1].count()
p2_s = data.Pclass[data.Pclass == 2].count()
p3_s = data.Pclass[data.Pclass == 3].count()
print(p1_s)
print(p2_s)
print(p3_s)
# 绘制饼状图
sdr = [p1_s, p2_s, p3_s] # [0.38, 0.62]
labels = ["等级1", "等级2", "等级3"]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title("船舱等级-人数-饼状图")
explode = (0, 0.1, 0)
colors = ['mediumpurple', 'lightpink','red'] # 颜色
plt.pie(sdr, # 数据
labels=labels, # 标签
autopct='%3.2f%%', # 显示百分比
colors=colors, # 颜色
textprops={'fontsize': 18, 'color': 'k'}, # 文本属性,文字大小颜色
explode=explode, # 饼的分离程度
shadow=True, # 阴影
startangle=60)
plt.show() # 显示用

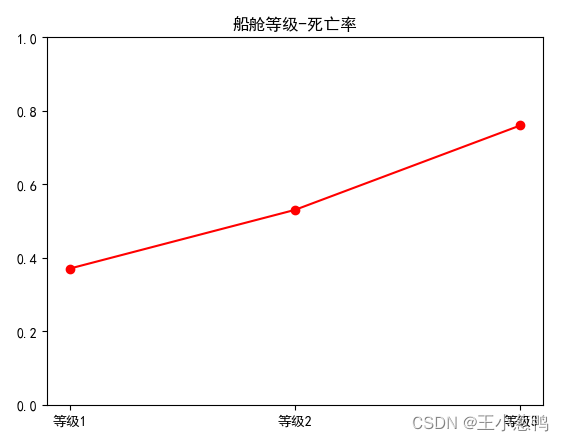
4.2 船舱等级-死亡率的关系
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
data = pd.read_csv("泰坦尼克幸存者_all.csv")
def f(x):
p1_all = sum(data.Pclass == x)
p1_dead = sum(data[data.Pclass == x].Survived == 0)
return p1_dead / p1_all
print("等级1-死亡率:" + str(round(f(1), 2)))
print("等级2-死亡率:" + str(round(f(2), 2)))
print("等级3-死亡率:" + str(round(f(3), 2)))
# 写成函数的形式
p_dead = [round(f(1), 2), round(f(2), 2), round(f(3), 2)]
p_label = ['等级1', '等级2', '等级3']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("船舱等级-死亡率")
plt.ylim((0, 1))
plt.plot(p_label, p_dead, 'ro-')
plt.show()
4.3 线性相关系数的计算
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 100) # x变量
noise = np.random.rand(100)
y = -1 * x + -noise*5 # y变量
corr = np.corrcoef(x, y)[0][1] # 线性相关系数
print(corr)
plt.plot(x, y, 'ro')
plt.show()

5 性别分析
5.1 性别单个变量分析
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('泰坦尼克幸存者_all.csv')
male = df.Sex[df.Sex == "male"].count()
female = df.Sex[df.Sex == "female"].count()
print("male: " + str(male))
print("female: " + str(female))
plt.figure(figsize=(10, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title("性别-饼图")
p = plt.pie([male, female],labels=['male', 'female'],autopct='%1.0f%%')
plt.show()

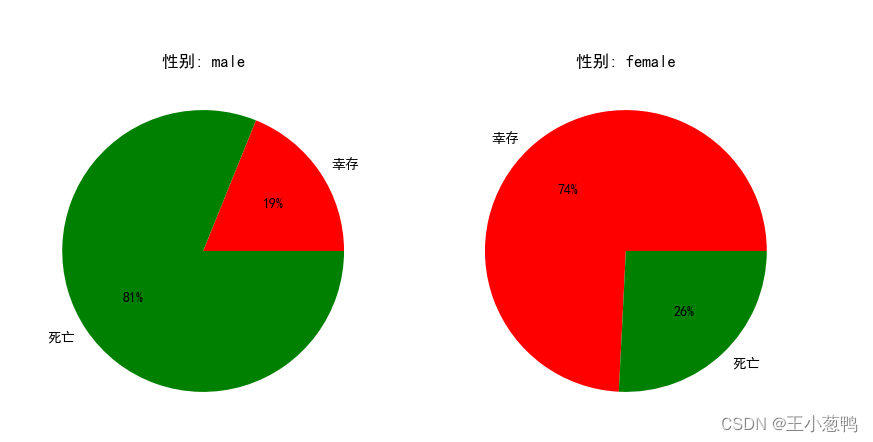
5.2 性别-死亡率的关系
def get_pclass_survived(x):
Survived_Pclass = df[["Survived", "Sex"]]
Pclass = Survived_Pclass[Survived_Pclass["Sex"] == x] # 船舱等级1总共人数
Pclass_Survived = Pclass["Survived"][Pclass["Survived"] == 1].count() # 船舱等级1幸存人数
Pclass_Survived_no = Pclass["Survived"][Pclass["Survived"] == 0].count() # 船舱等级1死亡人数
return Pclass_Survived, Pclass_Survived_no
male_Survived, male_Survived_no = get_pclass_survived("male")
female_Survived, female_Survived_no = get_pclass_survived("female")
plt.figure(figsize=(10, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
def plot_pie(sex, index, Survived, Survived_no):
plt.subplot(index)
plt.title("性别: " + str(sex))
p = plt.pie([Survived, Survived_no],
labels=["幸存", "死亡"],
autopct='%1.0f%%',
colors=['red', 'green'])
plot_pie("male", 121, male_Survived, male_Survived_no)
plot_pie("female", 122, female_Survived, female_Survived_no)
plt.show()
6 年龄分析
6.1 缺失值处理
import pandas as pd
import matplotlib.pyplot as plt
# 分析年龄,缺失值问题
data = pd.read_csv("泰坦尼克幸存者_all.csv")
age = data.Age
# 缺失值所占比例
print(age.isnull().sum() / len(age))
# 删除
# age.dropna(inplace = True)
# 填充1:任一数来填充
# age.fillna(1, inplace = True)
import numpy as np
# mean + noise * std
x = age.mean() + np.random.randn() * age.std()
age.fillna(x, inplace=True)
print(age)
# 填充1: 使用均值
# age.fillna(age.mean(), inplace=True)
# print(age)
# 填充2:使用前面或后面的值 method
# age.fillna(method="ffill", inplace=True)
# print(age)
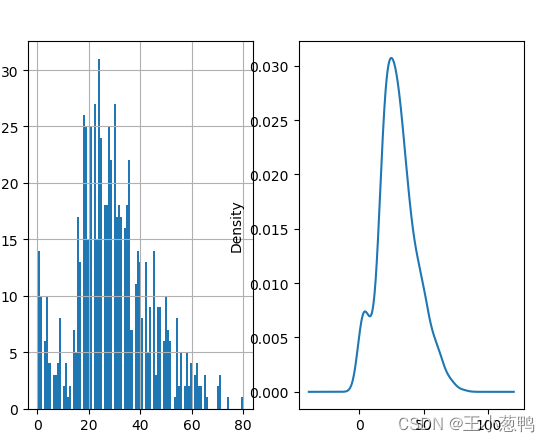
6.2 绘制频率分布直方图
import pandas as pd
import matplotlib.pyplot as plt
# 分析年龄,缺失值问题
data = pd.read_csv("泰坦尼克幸存者_all.csv")
# bins 越大,划分越细
age = data.Age
plt.subplot(121)
age.hist(bins = 100) # 频率分布直方图
plt.subplot(122)
age.plot(kind = 'kde') #密度分布函数
plt.show() # 只是展示
Survived = data.Survived
Survived.hist()
plt.show() # 只是展示
7 使用svm模型进行训练和预测
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 使用svvm模型进行分析
data = pd.read_csv("泰坦尼克幸存者_all.csv")
all_data = data[["Survived", "Pclass", "Sex", "Age"]]
# 处理性别female=0, male=1 loc
for i, x in enumerate(all_data["Sex"]):
if x == "female":
all_data.loc[i, "Sex"] = 0
else:
all_data.loc[i, "Sex"] = 1
# 处理年龄
age = data.Age
x = age.mean() + np.random.randn() * age.std()
all_data["Age"].fillna(x, inplace=True)
# 划分数据集
r = list(range(len(all_data)))
np.random.shuffle(r)
ra = int(len(r) * 0.8)
train_data = all_data.loc[r[0:ra]]
test_data = all_data.loc[r[ra:]]
# 划分特征、标签
features = ["Pclass", "Sex", "Age"]
label = ["Survived"]
train_x = train_data[features].values
train_y = train_data[label].values
test_x = test_data[features].values
test_y = test_data[label].values
# 搭建模型、训练模型、测试模型
svm_model = SVC(kernel='linear')
svm_model.fit(train_x, train_y) # 训练
predict1 = svm_model.predict(train_x) # 预测
accuracy1 = accuracy_score(train_y, predict1)
print(accuracy1)
predict2 = svm_model.predict(test_x)
accuracy2 = accuracy_score(test_y, predict2)
print(accuracy2)
0.7808988764044944
0.8100558659217877
AI学习部,不定期更新数据分析、机器学习、深度学习、python相关知识。


















 5907
5907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











