







这是我参与的第二个项目,进程还是很顺利的。这也不断改进的过程,总共有三个版本:
- 第一个版本是普通的爬取,对于某个农产品关键词,获取它全部的内容,后来由于我的网速太差,python运行报错了,每个农产品都拥有八百多个页面,如果重新开始,就会浪费很多时间,还不能确保它出错,于是我就改进成了第二个版本;
- 第二个版本是对某个农产品定页爬取,爬取某个页数区间的产品,用来弥补第一个版本信息出错后,接着上次的页数爬取数据
- 第三个版本是全自动化爬取;在第二个的基础上,浏览器的窗口总是弹出来干扰我做其他的事,所以就在这个版本中把浏览器隐藏起来,方便我工作。并且还加入随机验证码,实现全部自动化。
网址: http://nc.mofcom.gov.cn/channel/jghq2017/price_list.shtml
文章目录
1、开始前工作:
1.1、分析网页
可以把这个页面简单的理解成为一个查询接口,必须要输入验证码,点击搜索才能拿到数据,我经过简单的分析后,并没有找到数据的接口,所以就直接确定使用selenium来抓取数据了。
1.2、分析验证码
对于存在验证码的很多网页,如果使用验证码的次数不多,我们就可以直接使用手动输入,如果它不断的有验证码,就需要让它自动识别验证码了,但是我们爬取的这个网页验证码并不多,每种产品就只需要输入一次验证码,所以可以使用手动输入,但是重点来了,该网页经过我的测试,发现它的验证码并没有实际的作业,也就是说这个验证码可以随便输入数字,也就为我的第三个版本做铺垫了!
1.3、分析URL
虽然说URL对selenium后期的爬取作用不大,但是这个的URL隐藏了大量的信息:
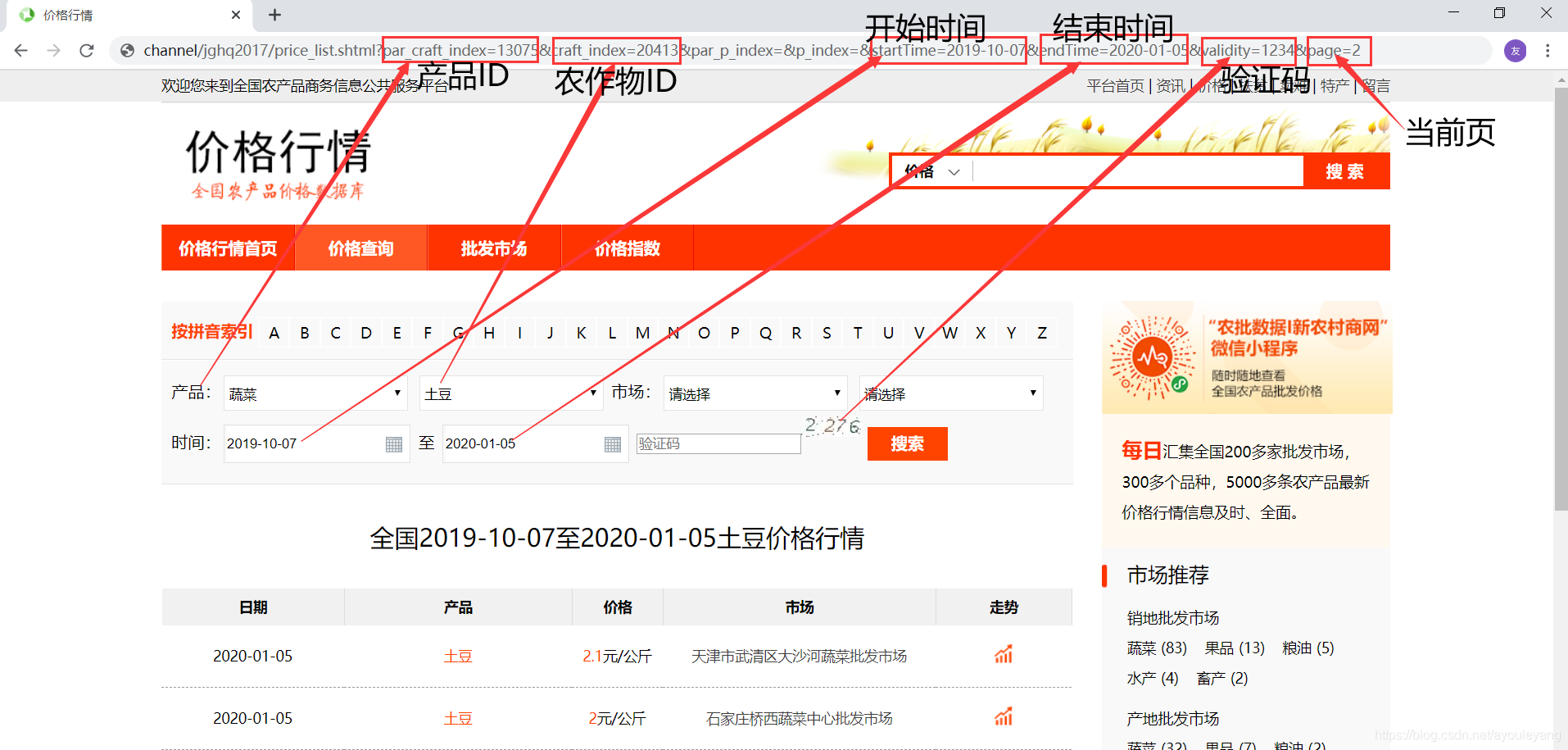
- 默认时间只有三个月,如果需要查看更多商品的话,自己可以去更改时间
- 在接下来的爬取中,它只是页码会有变化,其他的数据都不会改变
- 注意:不能直接在URL上使用起始页不为1的其他页数,因为输入验证码后都是数据都是从第一页开始的
- 建议用selenium时,不要让URL携带验证码和页数
2、第一个版本——普通的爬取
2.1、代码汇总
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from lxml import etree
import time,xlwt
startTime =time.time()#记录开始时间
all_page = []#用来保存所有页面爬取到的数据
url = 'http://nc.mofcom.gov.cn/channel/jghq2017/price_list.shtml?par_craft_index=13075&craft_index=15641&par_p_index=&p_index=&startTime=2019-10-04&endTime=2020-01-02'
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
driver.get(url)#打开网页网页
driver.implicitly_wait(6)#等待加载六秒
time.sleep(10)
def next_page():
for page in range(1,816,1):#从第1页爬取到第815页
print ("~~~~~~~~~~正在爬取第%s页,一共有815页~~~~~~~~~"%page)
if int(page) == 1:#当页码为1时,不需要点击下一页,直接跳转去获取html源码
get_html()
#点击下一页,下一页的a标签是最后一个标签
driver.find_element_by_xpath('/html/body/section/div/div[1]/div[4]/a[last()]').click()
get_html()
def get_html():
driver.implicitly_wait(5)#等待加载,完成后自动执行下一步
source = driver.page_source#获取网页源代码
html = etree.HTML(source)#lxml解析网页
spider(html)
def spider(html):
for tr in html.xpath('/html/body/section/div/div[1]/table/tbody/tr'):
time = tr.xpath('./td[1]/text()')
if len(time) != 0:
goods = tr.xpath('./td[2]/span/text()')#商品
price = tr.xpath('./td[3]/span/text()')#价格
unit = tr.xpath('./td[3]/text()')#单位
market = tr.xpath('./td[4]/a/text()')#市场
link = 'http://nc.mofcom.gov.cn/'+tr.xpath('./td[4]/a/@href')[0] #详情链接
page = [time,goods,price,unit,market,link]#生成数组
all_page.append(page)
saveData()
def saveData():
book = xlwt.Workbook(encoding = 'utf-8')#创建工作簿
sheet = book.add_sheet('生姜',cell_overwrite_ok=< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









