





通常,交通事故预测问题被表述为一个分类问题或一个回归问题。例如,一些工作的目的是预测在每个时间窗口(如一小时,一天),在一个特定的地点或特定的区域(如路段)是否会发生事故[9, 10, 12, 17]。其他工作[7, 8, 15, 23]使用回归模型预测特定时间和地点的事故数量。然而,这些工作通常使用经典的数据挖掘方法,没有考虑交通事故数据的独特特征,如空间异质性和时间自相关性,导致性能不理想。最近有少量的工作尝试使用深度学习方法,如深度神经网络或卷积神经网络来解决这个问题。
(主要用LSTM,把路网分成十个区域卷积)
4 特征提取
4.1静态特征:路网特征、道路状况特征、谷歌地图
4.2动态特征:降雨量、RWIS天气特征、交通流特征、日历特征
4.3空间图特征
为了解决空间异质性问题,我们也考虑到了道路的空间关系。尽管空间异质性在一定程度上可以通过道路的具体特征和天气的相关特征来体现,但仍有许多因素可能使不同地区的事故发生模式不同。例如,从图1(a)中我们可以看到,更多的事故集中在城市地区(如得梅因,锡达拉皮兹),而不是农村地区,这可以归因于不同地区的人口密度。
一个解决方案是包括一套新的特征,考虑不同地点之间的空间关系。这个想法是在所有道路之间构建一个空间图,并对诱导的拉普拉斯矩阵进行特征分析[6]。我们得到拉普拉斯矩阵的顶级特征向量。这些特征向量提供了关于每条道路的拓扑特征的额外信息,以及道路网络中的潜在空间集群。具体来说,让L表示基于空间图计算的图拉普拉斯矩阵,其中L的每一行对应于数据中的一个路段。让V表示L的前K个特征向量,然后我们可以使用V的每一行为相应的路段诱导出一组新的特征。这种方法类似于光谱聚类[30],首先根据拉普拉斯矩阵生成特征,然后根据新的特征进行k-means聚类。我们还根据图1(k=10)中的聚类结果,使用光谱聚类来可视化生成的特征。算法1中总结了特征的构建过程。注意最后一步与谱系聚类不同。
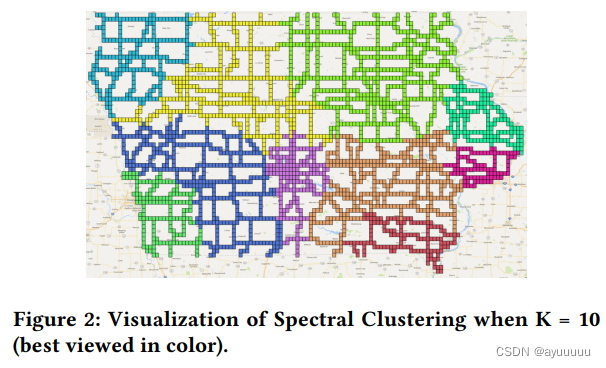
上述过程将为每个路段产生k个spatialGraph特征。最后我们将这些特征映射到每个网格单元si。对于只有一个路段的网格单元,空间图特征被直接分配为相应的路段的特征。对于有多条道路的网格单元,我们选择si中最长的道路段,并对si使用其空间图形特征。这种近似是合理的,因为同一网格单元中的道路段通常是相连的,而且往往具有非常相似的空间图形特征。在我们的实施中,我们选择k=10,导致10个时间不变的空间图特征。
5 THE HETERO-CONVLSTM APPROACH
5.1 convolution LSTM
长短期记忆(LSTM)是一种递归神经网络节点结构,已知在处理具有时间自相关的时间序列数据时具有良好的性能。LSTM神经网络的一个节点由一个记忆单元、一个输入门、一个输出门和一个遗忘门组成。在训练阶段,在LSTM节点的每个门中学习一个加权函数,以控制网络的 "记忆 "和 "遗忘 "能力。
ConvLSTM模型是LSTM的一个变种,用于处理时空预测问题,由Shi等人[32]首次提出,用于降水预报。ConvL STM网络的每个输入特征是一个三维时空张量,其中前两个维度是空间维度。与原来的LSTM模型相比,ConvLSTM单元的输入到状态和状态到状态的转换涉及卷积操作,输出3维张量。这个模型可以进一步模拟为以下公式。∗表示卷积操作,◦表示Hadamard乘积。
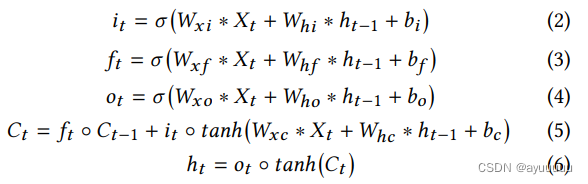
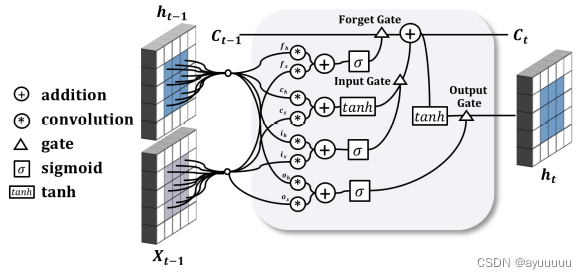
CovnLSTM在交通事故预测方面有很好的特性,因为LSTM部分可以捕捉数据中的时间自相关,而卷积算子可以捕捉局部空间特征(如危险的道路交叉口),这是潜在事故的重要指标。然而,ConvLSTM并没有明确地处理空间异质性。尽管我们在第4.3节中详细介绍了空间图特征,但由于环境条件的变化,模型的准确性可能会受到影响。另外,训练一个单一的、大型的ConvLSTM模型可能需要过多的时间。
为了解决上述限制,我们提出了Hetero-Conv LSTM框架。首先,我们使用一个移动窗口来获得研究区域内一个子区域的数据,并为每个窗口学习一个具有不同参数的ConvLSTM网络模型。窗口的大小是这样选择的,即模型可以在合理的时间内被训练出来,同时该区域仍然足够大,以包括足够的训练样本。在我们的案例中,我们选择一个大小为32×32的区域。在模型训练完成后,我们从每个模型中获得每个网格的预测值,并使用输出的集合作为最终预测值。
5.2 regional prediction model
ConvLSTM结构。对于每个区域窗口,我们构建一个ConvLSTM模型。在时空预测中,如降雨预测[32],只有一个因变量,没有其他特征。输入X是因变量的历史值。在我们的问题中,我们有额外的特征被纳入并反馈给网络。因此,在我们的问题中,输入数据是4维的。上述公式中的参数Xt和ht-1是三维的张量,而不是[32]中的二维图像。
四个ConvLSTM层堆叠在一起,每层有128个ConvLSTM滤波器(隐藏状态),从输入数据和以前的时间步骤的输出中提取空间特征。在任何两个ConvLSTM层之间,我们应用批处理归一化层来进一步加速训练过程。对于像素级的预测,我们将所有的输出连接起来,并将它们输入到1 x 1卷积前向层,为每个时间步骤t生成一个二维地图。
我们还在最终输出上实现了一个额外的过滤器来平滑输出。每个时间步骤t的最终输出图像由网络掩码层(N)通过像素级的和运算进行过滤。道路网络之外的任何非零预测值都被设置为0。
图4显示了输入和输出的整体结构。图3显示了我们模型中单个ConvLSTM单元的详细结构。
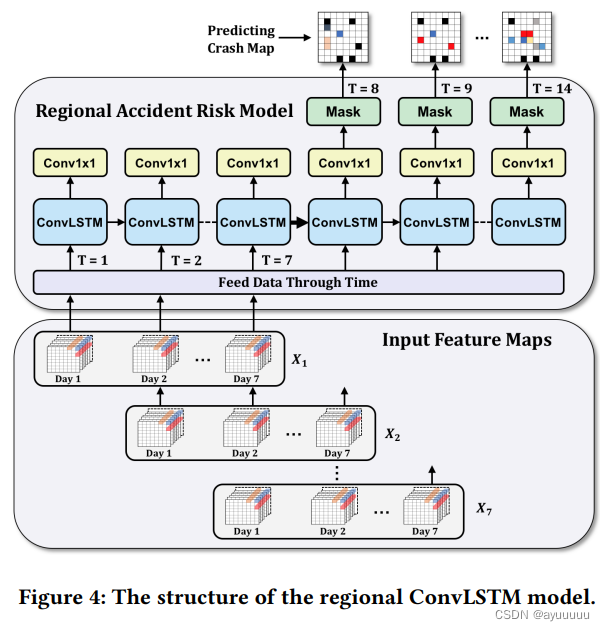
训练和测试。我们以如下方式构建训练样本。每个训练序列由14天组成,其中最后7天是根据前7天的数据预测的(最后7天比前7天移了1天)。这14天的所有特征张量都被送入ConvLSTM模型。我们选择7天是因为交通事故受到人类活动的影响,而人类活动具有强烈的每周模式。
该模型根据截至第t-1天的特征(包括地面实况事故数),每次生成一天t的预测结果。然后将地面实况C作为下一次预测C的输入 注意,我们在第t天不使用任何特征,因为这些特征在第t天过去之前可能无法使用。第4节中描述的所有特征在使用前都被归一化到[0,1]的范围。我们使用交叉熵作为损失函数。
5.3 spatial ensemble of convLSTM models
为了解决空间异质性问题,我们为研究区的每个不同区域建立了一个LSTM模型,并使用模型集合方法来产生最终结果。这种设计背后的直觉是为了减少数据异质性的影响(例如,城市与农村)。我们使用移动窗口的方法,其中移动窗口的大小为32×32。我们通过将窗口从左上角(0,0)-(32,32)移动到右下角(96,32)-(128,64),在水平和垂直方向上以16个网格为单位,对空间框架S进行子集。这导致了21个不同的区域,其中每一对相邻的区域都有50%的网格相互重叠。这些区域如图5所示。
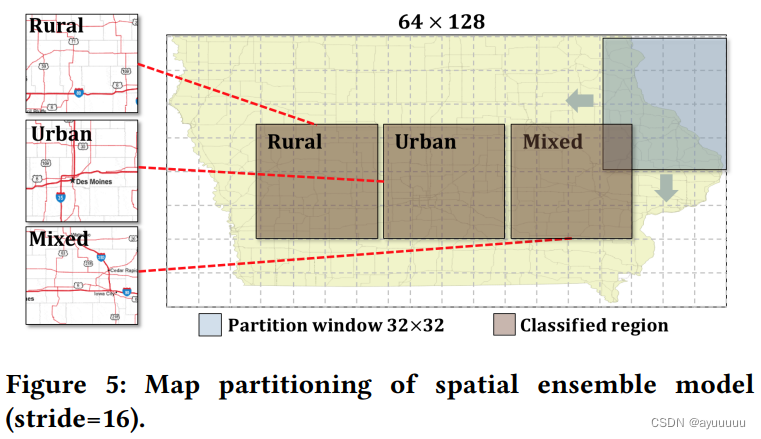
我们把训练集和测试集各分成21个子集。对于每个区域窗口,我们基于自己的训练集学习一个ConvLSTM模型,并对其测试数据集进行预测。一个网格位置si在每一天tj的最终预测值被计算为所有模型在tj的预测值的加权平均值,这些模型的区域覆盖了si。
6 实验结果
6.1实验设置
数据准备。我们的问题是根据过去7天的交通事故和其他相关情况来预测未来7天的交通事故。因此,我们将每个训练和测试样本创建为一个14帧的序列(7帧用于训练,下7帧用于预测)。整个数据集(8年,2922天)被转换为2915个序列。所有的数据被分为2组,前7年(2006-2012)的数据被用作训练集,最后一年(2013)的数据被用作测试集。训练集的10%被选为验证集。如上节所述,我们将爱荷华州划分为5公里乘5公里的网格。对于2013年的每一天,我们使用提议的Hetero-ConvLSTM模型预测交通事故地图。
评价任务。通过实验,我们希望回答以下问题:(1)与经典预测模型和普通ConvLSTM等基线方法相比,所提出的框架工作结果是否更好?(2) 在不同地区,哪些特征对预测的准确性影响最大?(3) 我们提出的模型在不同地区(如城市、农村)的表现有什么不同?(4) 预测结果是否有意义?预测的事故地点与地面实况在空间上是否相关?
参数设置
平台
基准模型:LR、DTR、DNN、FC-LSTM、ConvLSTM、HA
6.2检测准确性结果
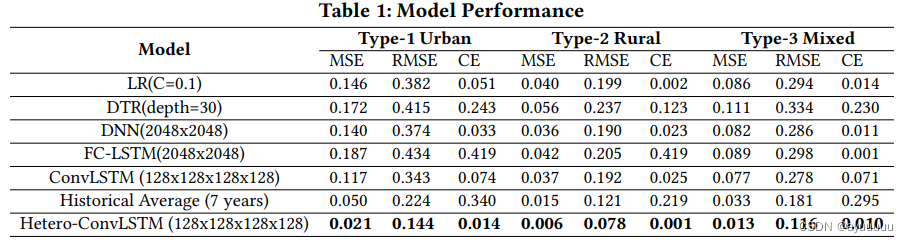
考虑到空间的异质性,我们在实验中提出了三种不同类型的区域的结果。我们将类型1定义为城市地区,如Des Monies;类型2定义为农村地区,如爱荷华州西部;类型3定义为混合地区(在两个城市地区之间),如滑铁卢、爱荷华市和锡达拉皮兹之间的地区。我们报告了对每个区域的结果的评价措施(在像素级)。结果列于表1。Hetero-ConvLSTM模型在所有三个地区都取得了最佳性能,MSE和RMSE最低。历史平均数在所有地区都比其他基线模型表现得好,但比我们提出的模型差。这表明,由于交通事故的周期性和季节性模式,日平均数通常是一个很好的长期预测估算器,平均误差较低。然而,它在预测短期交通事故方面可能并不出色,特别是当事故是由天气状况或罕见事件引起的。总之,Hetero-ConvLSTM比其他所有的模型都要准确一个数量级。
6.3 特征组影响
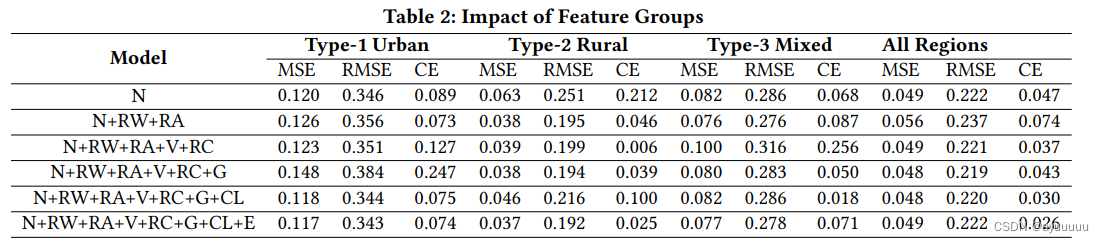
为了研究不同特征组对结果的影响,我们在所有32x32的区域上运行我们的训练模型,并展示三个选定区域的结果以及整个州的总体结果。对于每个区域,我们每次添加1-2个特征组,并测量结果的MSE、RMSE和交叉熵。结果总结在表2中。我们可以观察到,一般来说,更多的特征会导致更低的误差。然而,一些特征组可能会对准确性产生负面影响,而且最重要的特征在不同的地区也有所不同。
在类型1(城市)中,路网(N)、交通量(V)、道路状况(RC)和日历(CL)带来了误差。这可以解释为更高的人口密度和更强的人类活动模式。空间图特征(E)的影响非常小。这可能是由于该地区的异质性较低。
有趣的是,在Type-2和Type-3地区,重要的特征组发生了变化。降雨量(RA),其他天气特征,如温度和风速(RW),以及SpatialGraph特征(E)比其他特征更有效地降低了误差。这很有意义,因为在农村地区与人有关的因素不如环境特征重要。结果还证实了数据中存在强烈的空间异质性(尤其是农村地区),我们提出的SpatialGraph特征有助于处理这一挑战。总体结果显示,在整个州内,日历(CL)和道路状况(RC)特征对结果的准确性贡献最大。然而,由于空间的异质性,这些影响是微不足道的。
6.4 结果质量
最后,我们使用cross-K函数[13]来评估预测结果的位置准确性。Cross-K函数是对两个物体类型之间的空间聚类趋势的测量。在我们的案例中,我们平均计算出预测的事故在真实事故的每一距离d内的密度。改变d,我们得到一个经验曲线。图6显示了这些曲线。底部的曲线代表了完全空间随机性的交叉K函数,即在地面实况和预测之间没有任何关联。在这种情况下,K,其中Ap和Ag是预测和真实事故的空间密度。最上面的曲线代表了Hetero-ConvLSTM预测和地面真相之间的经验交叉K函数。结果显示,预测结果与地面实况在空间上高度相关。
我们将Hetero-ConvLSTM的结果与地面实况进行了直观的比较。图8显示了对其中一个选定区域(类型3)的整个一周的预测结果。圆圈突出了模式被正确预测的区域。正如可以看到的那样,我们的模型能够找到主要的事故热点。预测中的趋势与地面真实数据中的趋势一致。最后,我们从新闻报道中发现,2013年12月8日,一场大雪袭击了爱荷华州。在Cedar Rapids地区,靠近I-380南向车道的地方发生了49起以上的事故[1]。图7显示了这一天的预测结果与地面实况的对比。可以看出,包括上述事故在内的事故群被正确预测。
我们的框架提出了一个使用大的异质数据来预测每日/每周交通事故风险的解决方案。我们的评估结果是在一个实验性的原型系统上进行的。为了全面部署一个可供公众使用的工作系统,我们需要解决以下挑战。1 将我们的框架部署在基于云的服务/存储上,以便实时查询。2 定期更新离线模型以保持预测的准确性。
第一个问题的可行解决方案是将我们训练好的模型部署在云服务中(例如,亚马逊AWS Lambda [2]或微软Azure [4])。对于每日预测,我们的系统将被安排在午夜运行并获取过去一天的天气、交通量、降雨量和车祸数据,将它们转化为特征图,然后以在线方式重新训练模型。学会的模型参数最后被推送并保存到云服务中。对于每周的预测,唯一的区别是使用模拟或预测数据作为时间变化的特征。理想情况下,我们将为用户提供一个网络界面,以查看一天或多天的车祸风险图。在未来,我们也会考虑将这个框架与当前的地图服务平台相结合的可能性,如谷歌地图[3]。















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









