







前言
本篇文章介绍unicode
定义
unicode的中文翻译为统一码,也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准。
简单的来看,unicode就是一个数字,每一个数字对应一个字符的编码,这个字符囊括了整个世界使用的全部语言和符号的字符,所以,从根本上来说,unicode就是一个映射表,一个从数字到文字的映射
unicode发展
1990年开始研发,1994年正式发布1.0版本,2023年12月12日发布15.1.0版本。共收录149,813个字符。
UCS-2和UCS-4
UCS:Universal Character Set的简称,中文叫通用字符集,使用八位编码,是计算机用来表示所有字符的集合。
UCS-2:2个字节编码的通用字符集,其实对应的类型一般就是unsigned short,一般两个字节就可以包含大部分的欧美字符和常用中文。
UCS-4:4个字节编码的通用字符集,其实对应的类型一般就是unsigned int,四个字节可以包含所有目前计算机可以表示的字符
unicode的编码方式
因为UCS-2从原理上来说是UCS-4的子集,所以我们用UCS-4的编码来讲解unicode的编码方式,也就是我们把一个unicode码理解为unsigned int
一个unicode码有四个字节:A B C D,A是最高位字节
- A的首位一定是0,也就是A的表示范围为00000000~01111111,供128个值,我们把这
128个值称为group,一个unicode码一定位于这128个group之中,其实目前所有已使用的都是group0,也就是A其实是0. - B表示范围为00000000~11111111,共256个值,我们把这
256个值称为平面,其实现在unicode编码使用的平面也占很少一部分,后面会介绍 - C表示范围为00000000~11111111,共256个值,我们把这
256个值称为行,所以现在每个平面有256行 - D表示范围为00000000~11111111,共256个值,我们把这
256个值称为码位,所以现在每个平面有256*256=65536个码位 每个码位就代表一个字符的unicode值
虽然原理上unicode可以支持32768 * 65536个码位,但是实际上根本用不到这么多,可能随着以后很多特殊符号的产生,会使用更多的码位,但是现在所有的unicode码位集中在第0个group,第0~第16个平面的所有码位,用unicode的字节范围表示就是0x000000~0x10FFFF,我们列一下基本的平面分类:
-
0平面:编码范围0x0000~0xFFFF,0平面也叫
基本多文种平面,该平面基本包含了所有的文字编码,包括大部分的中日韩表意文字和世界各国语言的字符其中,编码范围0xE000-0xF8FF,共6400个码位,叫做
专用区,这部分是没有字符的其中,编码范围0xD800-0xDB7F,被称为代理对高位字
其中,编码范围0xDB80-0xDBFF,被称为代理对私用区高位字
其中,编码范围0xDC00-0xDFFF,被称为代理对低位字
这三部分被称为代理区,编码范围为0xD800-0xDFFF,共2048个码位,这部分也是没有字符的 -
1平面:编码范围0x10000~0x1FFFF,1平面被叫做
多文种补充平面,我们平常使用的很多表情符号就定义在该平面 -
2平面:编码范围0x20000~0x2FFFF,2平面被叫做
表意文字补充平面,顾名思义,该平面是针对于中日韩表意文字的补充 -
3平面:编码范围0x30000~0x3FFFF,3平面被叫做
表意文字第三平面,顾名思义,该平面是针对于中日韩表意文字的补充 -
4~13平面是未使用的平面
-
14平面:编码范围0xE0000~0xEFFFF,14平面被叫做
特别用途补充平面,这个平面定义了两个块,分别为标签块,编码范围0xE0000~0xE007F,共128个字符,另一个是变体选择符补充,编码范围0xE0100~0xE01EF,共240个字符,该平面一共就定义了368个字符。 -
15~16平面:编码范围0xF0000~0x FFFFF,0x100000~0x10FFFF,这两个平面被称为
保留作为私人使用区,可以简写为PUA,Private Use Area的意思
在计算机中的编码方式
即然所有的字符都有对应的编码,那么我们为什么不在计算机中直接保存unicode值呢,想象一下,unicode目前所有的字符得用四个字节才能完全包含,如果我们默认都使用unicode保存字符信息,相当于一个字符就得占用四个字节的空间,这对于特别是英文等欧美字符来说是极大的浪费,尤其是面对大量的文本或者是网络传输的时候。其实,这种编码方式已经存在了,就是UTF-32编码方式,UTF-32就是对每个字符都使用四个字节来保存,这种编码方式看似很简单,不需要复杂的算法处理和编码逻辑,但是也正是这种简单,造成了空间的极大浪费,因为我们其实大部分使用的字符都是位于第0平面的,也就是高位的两个字节基本没有意义,这使得UTF-32通常会是其它编码的二到四倍。
但是,如果我们不使用每个字符四个字节的空间, 我们有两个需要解决的问题:
- 我们需要找到一种方案,
字符占用的空间可以少于四个字节,但是我们必须能表示所有的字符才行 - 我们针对于
不同的字符使用不同的空间,但是我们必须得知道当前字符使用了几个字节,也就是我们得知道当前字符在哪个字节结束,在哪个字节开始。
由此衍生出了两种编码方式,就是最常见的utf-16和utf-8
UTF-16
我们根据unicode的编码能够看到,其实大部分使用频繁的码位都位于group0的第0平面,也就是编码范围为0x0000~0xFFFF,占用两个字节,那么我们假设如果unicode编码小于0x010000的时候,我们就用两个字节表示,也就是16位空间。除此之外,我们用两个16位,也就是32位表示。这就涉及到第二个问题了,如果我从文件中读取utf-16编码的数据,面对一个16位的数据,我得知道:
- 这个字符就是16位呢,还是其实是32位的一部分
- 如果是32位,我还得知道是32位的高16位呢,还是32位的低16位呢。
UTF-16编码很巧妙的解决了这个问题,还记得前面讲的第0平面的代理区吗?这个代理区的编码范围内可没有使用的unicode码位。代理区的范围为0xD800-0xDFFF,换成二进制表示可能看的更清楚一下,11011000 00000000~11011111 11111111,也就是以110110打头的所有码位和以110111打头的所有码位都没有被使用。既然没有任何码位以这两个值开头,我们就可以使用这两个二进制序列打头来表示这是一个32位数据,两个正好可以一个表示高位,一个表示低位,比如我们读取utf-16编码的数据,判断一个16位二进制序列的前6位:
- 如果等于110110,表示这是32位编码的高16位
- 如果等于110111,表示这是32位编码的低16位
- 否则,当前16位序列就是unicode值
现在就剩下一个问题了,32位序列去掉两个6位打头的序列,只剩下20位,这20位能表示所有的unicode码位吗?我们计算一下:
现在使用的码位范围是0x000000~0x10FFFF,
- 0x0000~0xFFFF的我们不用管,这个用16位就可以表示了
- 对于大于等于0x010000的情况,我们统一减去0x010000,也就是表示范围变成(0x010000 - 0x010000)~(0x10FFFF - 0x010000)= 0x00000~0xFFFFF,20个二进制序列正好足够。
下面,我们用一个例子看看unicode值是怎么用UTF-16编码表示的,比如unicode值0x201F2,中文的汉子𠇲的unicode编码,0x201F2 - 0x10000=0x101F2,二进制表示为0001000000 0111110010,前后两个10位二进制分别添加高低位前缀,最终𠇲的UTF-16表示为:
二进制表示:
11011000010000001101110111110010
十六进制表示:0xd840 0xddf2
十进制表示:55360,56818
随便找一个UTF-16编码解码在线网站试一下是正确的。
UTF-8
UTF-16的编码方式简单,但是从名称就可以看出来,编码方式一定是以16位字节序列为基本单元的,对于很多英文字符的表示还是不够简单,所以本部分介绍UTF-8,最主流的字符编码方式,因为他可以根据字符的unicode值自动编码为1个字节,2个字节,3个字节和4个字节。即然结论一定,剩下的问题就是我们怎么判断一个字节是字符的开始,结束还是中间部分,接着往下看
UTF-8采用了一种特殊的编码方式:(x可以是0或者是1)
- 如果字符只需要一个字节,用
0xxxxxxx的方式表示,这种方式的好处是兼容了ascii的表示方式,并且我们根据第一个位就可以判断当前字符是不是一个字节,但是坏处就是很多拉丁字母没办法用一个字节表示了。一个字节的实际编码位为7位,表示范围为[0,127] - 如果字符需要两个字节,用
110xxxxx 10xxxxxx的方式表示,我们只需要判断字节序列是不是以110开头的即可,如果是,该字符就是以两个字节编码。两个字节的实际编码位为11位,表示范围为[128,2047] - 如果字符需要三个字节,用
1110xxxx 10xxxxxx 10xxxxxx的方式表示,我们只需要判断字节序列是不是以1110开头的即可,如果是,该字符就是以三个字节编码。三个字节的实际编码位为16位,表示范围为[2048,65535] - 如果字符需要四个字节,用
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx的方式表示,我们只需要判断字节序列是不是以11110开头的即可,如果是,该字符就是以四个字节编码。四个字节的实际编码位为21位,表示范围为[65536,2097151]
下面还是用汉字𠇲为例,看看他的UTF-8编码如何,
𠇲的unicode编码为0x201F2,十进制为131570,在区间[65536,2097151],所以,需要四个字节
二进制表示为000 100000 000111 110010
所以UTF-8表示为
11110000 10100000 10000111 10110010
看下面代码:
int main(void)
{
// \xf0 = 11110000
// \xa0 = 10100000
// \x87 = 10000111
// \xb2 = 10110010
char c[]={'\xf0','\xa0','\x87','\xb2','\0'};
printf("%s\n",c);
return 0;
}
结果正好输出
𠇲
关于UTF-8和UTF-16的思考
我们了解了UTF-8和UTF-16的编码方式之后,可以看到:
- 对于英文和数字,UTF-8有很大的优势,只需要1个字节,但是UTF-16需要两个字节
- 但是对于很多中文,UTF-16两个字节就可以表示,而UTF-8需要三个字节,因为UTF-8需要更多的位来标记当前编码的字节数
下面这张图是我用不同的编码方式保存的文本文件
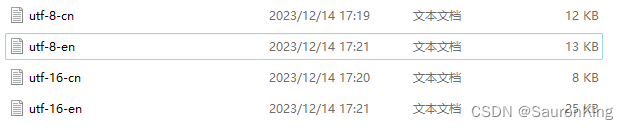
可以发现
- 对于英文数字的情况(文件utf-8-en和文件utf-16-en),utf-8明显小很多,基本一半吧。因为一个是1个字节,一个是两个字节
- 对于中文的情况(文件utf-8-cn和文件utf-16-cn),utf-16差不多小1/3,因为utf-16用两个字节,而utf-8用三个字节(unicode小于2048的时候两个字节就够了)
所以,特别是在网络传输的时候,我们可以根据数据的类型来调整编码方式已达到最小的数据表示和最大的传输速度。
关于LE和BE
LE和BE表示字节在存储器的保存方式
- LE:按照小端法保存,即编码的低位字节放到最前面,这个是针对于整个字符编码的,比如我们前面使用UTF-8表示的文字𠇲的字节序列为
按照LE的保存方式应该是\xf0 \xa0 \x87 \xb2\xb2 \x87 \xa0 \xf0 - BE:按照大端法保存,即编码的高位字节放到最前面
BOM
英文名称:Byte Order Mark。字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
下面列出BOM的各种表示结束本文
- UTF-8:
EF BB BF - UTF-16LE:
FF FE - UTF-16BE:
FE FF - UTF-32LE:
FF FE 00 00 - UTF-32BE:
00 00 FE FF















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









