



 SSNet是一种用于在线动作预测的深度学习模型,采用扩张卷积网络并在时间维度上滑动窗口,通过窗口尺度选择方案和激活共享机制提高预测效率和准确性。
SSNet是一种用于在线动作预测的深度学习模型,采用扩张卷积网络并在时间维度上滑动窗口,通过窗口尺度选择方案和激活共享机制提高预测效率和准确性。
http://openaccess.thecvf.com/content_cvpr_2018/papers/Liu_SSNet_Scale_Selection_CVPR_2018_paper.pdf
摘要首先介绍问题,即action prediction(这里括号写了个early action recognition,看后面的介绍好像是和action recognition有区别的,区别在于并不是用已经获得的整个video进行识别)的目的是用已观测到的进行中的动作预测其class label。接着介绍本文提出的方法,是通过介绍特点和功能而不是介绍流程的方式介绍的模型,本文关注的是online action prediction,采用了一个dilated convolutional network,通过在temporal维度上sliding window的方式抓取动态信息。由于在处理数据的不同阶段观测到的temporal维度上的尺寸有很大变化,本文还提出了一个新的window scale selection scheme来帮助在每一个time step关注进行中的动作,而忽视之前动作带来的噪声(这个估计到后面看了具体的介绍才知道是什么意思),此外,本文还提出了一个activation sharing scheme用来处理邻近帧之间的overlapping computation,使得模型运行更高效。最后介绍了下实验情况。
从introduction中可以看到本问题的详细介绍,也就是说action prediction是处理当只有一部分action被观察到的时候识别动作类别的问题,是在动作完全做完之前就预测,这个问题归属于一个更大的课题,即human activity analysis。此外,已有的工作大多都是处理只包含一个action的video片段,而本文关注的是未经分割的video,也就是一段video可能包含一串不同的动作(如下图中Figure1(a)所示)。
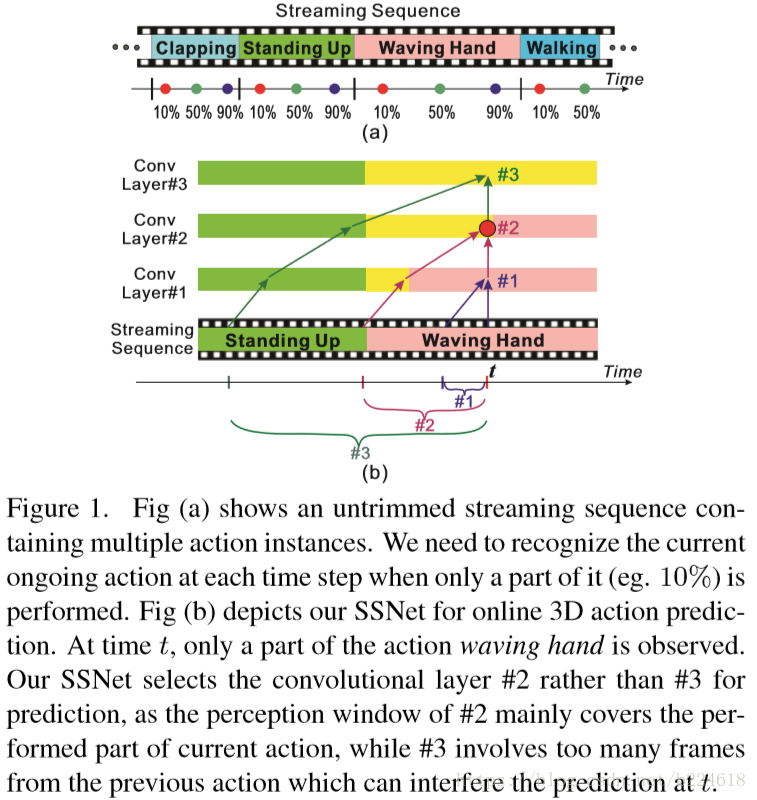
本文提出的模型示意图如下
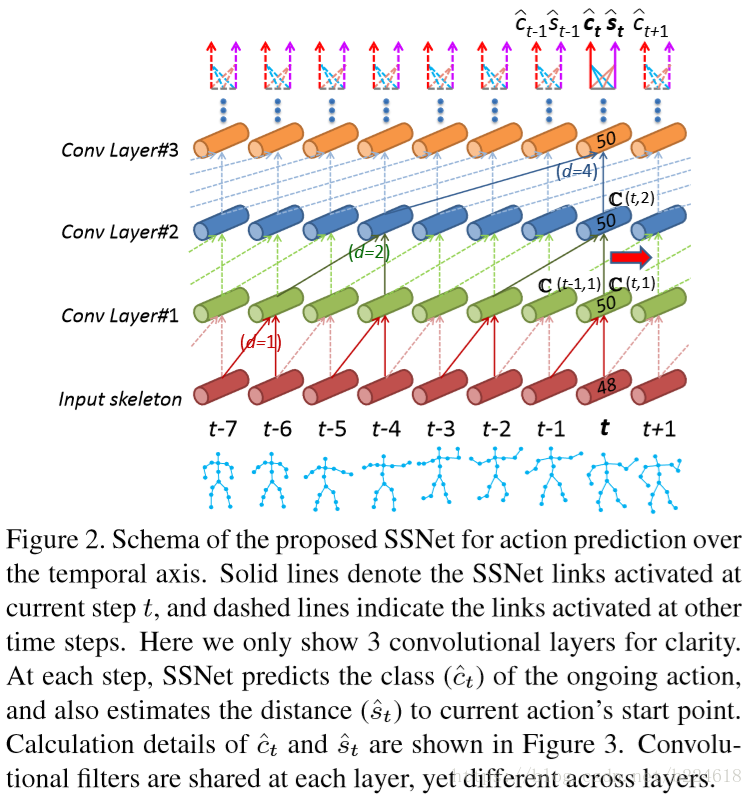
整个模型是在temporal维度上搭建一个hierarchy of one dimensional convolution,每一个time step对应输入到SSNet的是包含在一定尺寸的time window的frames,在不同的时刻,对应的time step所处的action被观察到的比例不同,因此对不同的time step要采用不同的window size,以便能够包含这个time step对应的action被观察到的所有frames,同时又不将前一个action的frame包含进来,造成干扰。
本文采取的是dilated convolution而不是常规的卷积,原因是一个完整的action可能会跨越很多frame,这样的话就需要很大的receptive field,若是采取常规的卷积的,就需要增加网络层数或者是增加filter的尺寸来扩大感受野,但是这样会大大增加待训练的参数数量,因此采取dilated convolution,并且dilated convolution还不需要pooling操作(看来我对pooling的理解还不够深,并不是太懂为什么常规的卷积就要pooling而dilated convolution就不要)。
dilated convolution有一个参数叫做dilation degree,用d标记。如上图所示,随着卷积层数加深,d以指数形式增加。
对于每一个time step,都要确定一个temporl window,![]() ,也即一个scale s,这个temporal window要全面的包含这个time step所处的这个action,又不能包含太多上一个action的frame,以免造成干扰,对于模型的这个需求,本文提出了scale selection scheme,其核心idea就是为每一个time step生成一个proper window,以供下一个time step使用,正如上面的Figure2所示,对于每一个time step,网络的输出既有表示当前所处action的class label,又有当前frame到当前所处action开端的距离的估计
,也即一个scale s,这个temporal window要全面的包含这个time step所处的这个action,又不能包含太多上一个action的frame,以免造成干扰,对于模型的这个需求,本文提出了scale selection scheme,其核心idea就是为每一个time step生成一个proper window,以供下一个time step使用,正如上面的Figure2所示,对于每一个time step,网络的输出既有表示当前所处action的class label,又有当前frame到当前所处action开端的距离的估计![]() ,假设我们得到了t-1时刻的
,假设我们得到了t-1时刻的![]() ,那么在t时刻,也就是第t个frame,
,那么在t时刻,也就是第t个frame,![]() 表示的范围内的frame属于当前的action,那么在选择temporal window的时候就要等于
表示的范围内的frame属于当前的action,那么在选择temporal window的时候就要等于![]() 或者稍稍比它大一点(这里其实有一个细节值得关注,如果t时刻已经是当前action的最后一帧了,那么计算出
或者稍稍比它大一点(这里其实有一个细节值得关注,如果t时刻已经是当前action的最后一帧了,那么计算出![]() 给下一帧用的话,实际上是用当前action的所有帧去为下一个action的第一帧做预测,这个衔接怎么做是很有意思的)。本文是通过选择不同层数的网络来进行temporal window尺寸的调整的,例如在Figure 1中,Layer #2就是一个合适的选择,用
给下一帧用的话,实际上是用当前action的所有帧去为下一个action的第一帧做预测,这个衔接怎么做是很有意思的)。本文是通过选择不同层数的网络来进行temporal window尺寸的调整的,例如在Figure 1中,Layer #2就是一个合适的选择,用![]() 表示为第t帧选出来的合适的层数,然后将
表示为第t帧选出来的合适的层数,然后将![]() 层到第一层的所有激活值
层到第一层的所有激活值![]() (
(![]() )都聚合起来,得到一个全面的representation
)都聚合起来,得到一个全面的representation
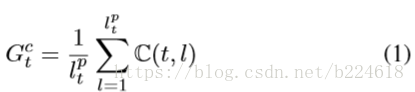
而distance的表达式是
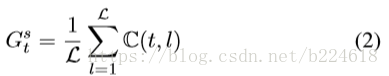
这就相当于加了residual一样,这种skip connection可以使得收敛的速度加快,并且可以搭建更深的模型,同时还能增加representation capacity,因为不同尺度的信息都被整合了起来。之后的操作可由下图展示
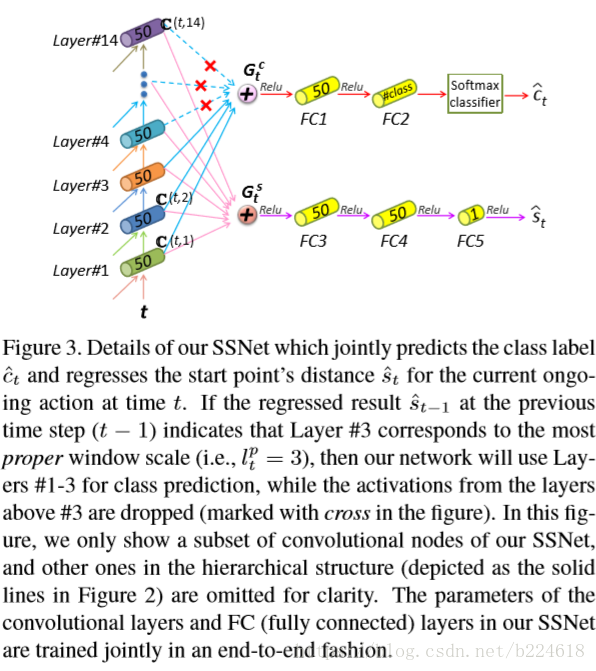
此图首先展示的是选择了合适的layer ![]() 之后,模型并不是只产生
之后,模型并不是只产生![]() 层的激活值,而是将更高层的激活值抛弃掉了;其次,计算
层的激活值,而是将更高层的激活值抛弃掉了;其次,计算![]() 的时候,并不是只用选定的
的时候,并不是只用选定的![]() 层的激活值,而是直接使用从最高层layer往下的所有卷积层的激活值,感受野一般会跨越多个action的。接着作者解释道,到起点的distance的regression其实就是连接两个action的bonding的位置,因此包含前面action的信息其实是有好处的。对于之前提到的衔接的问题,作者给出了解释,对于
层的激活值,而是直接使用从最高层layer往下的所有卷积层的激活值,感受野一般会跨越多个action的。接着作者解释道,到起点的distance的regression其实就是连接两个action的bonding的位置,因此包含前面action的信息其实是有好处的。对于之前提到的衔接的问题,作者给出了解释,对于![]() ,一种策略是采取之前一帧的
,一种策略是采取之前一帧的![]() 用来选择下一帧的temporal scale,另一种就是对于第t帧就从第t帧开始计算
用来选择下一帧的temporal scale,另一种就是对于第t帧就从第t帧开始计算![]() ,实验结果是这两种策略表现都差不多,作者认为这两者的主要差别也是第t帧可能就是下一个action的了,但是由于是下一个action的开端,就一帧,并不会包含太多信息,即使正确的划分了temporal scale,也不好预测其class label,而到了后来
,实验结果是这两种策略表现都差不多,作者认为这两者的主要差别也是第t帧可能就是下一个action的了,但是由于是下一个action的开端,就一帧,并不会包含太多信息,即使正确的划分了temporal scale,也不好预测其class label,而到了后来![]() 和
和![]() 就很接近,得到的预测结果也不会有什么大的区别了。
就很接近,得到的预测结果也不会有什么大的区别了。
SSNet采取14层卷积(具体每一个time step采取几层不一定),具体来讲是将dilation rate分别为1,2,4,8,...,64的subnetwork堆叠两个在一起,详细计算后可知这样的网络在输入上的感受野,从第一层到最顶层是2-255的,按照常规的视频帧频,255帧可以覆盖大约8秒的视频了,范围也算是很大了。
本文还采用了一个activation sharing的机制,不同的time step对应不同大小的window scale,但是都用同一个网络处理,在不同time step进行卷积的时候,低层次网络的激活值是被多次使用的,在本文模型中,这些被重复使用的激活值只计算一次,下一次再用就还用之前计算过的。作者认为这是由于本文使用的是casual convolution,即卷积不包含future information,但是我感觉这种避免重复计算同一个神经元激活值的操作似乎和这个没啥关系。。。只不过是把激活值记下来多用几次,就算包含了future information也可以这样用呀。
模型的objective function如下
![]()
![]() 是class label的ground truth,
是class label的ground truth,![]() 是distance的ground truth,γ是一个权重,
是distance的ground truth,γ是一个权重,![]() 是负的log-likelihood loss,
是负的log-likelihood loss,![]() 。
。
在测试的时候,是每一帧的class label都做预测的。
接下来介绍下实验部分,本文的实验部分分为四块,在四块之前还有一个概述,介绍了本文采取哪些数据集,采用哪些模型。本文采用的数据集是OAD数据集和PKU-MMD数据集,参与实验的模型有七种,前四种是本文模型及变种,后三种是他人提出的模型。本文提出的模型及变种分别是:SSNet,也就是本文的主要模型,能够通过distance regression为每一帧选择合适的layer;FSNet,这个是fixed scale network,和SSNet很像,但是不使用scale selection scheme,而是每一帧都使用top layer,采取最大的window,即最大的感受野,对于这个模型,还分别采取了不同的fixed scale,具体来讲分别是![]() ;FSNet-MultiNet,是多个FSNet的组合,是将前面所提到的不同S的FSNet的结果合在一起;SSNet-GT,这个是一个理想模型,SSNet的layer是通过regression得到的,本模型中使用ground truth的distance(当前帧到当前所在action起始帧的距离)。
;FSNet-MultiNet,是多个FSNet的组合,是将前面所提到的不同S的FSNet的结果合在一起;SSNet-GT,这个是一个理想模型,SSNet的layer是通过regression得到的,本模型中使用ground truth的distance(当前帧到当前所在action起始帧的距离)。
以上是本文提出的几个模型(核心模型及其变种,为了探究模型各个方面的能力),与本文模型对比的还有三个其他人提出来的模型:JCR-RNN,是LSTM的变体,模拟未经处理的sequence的temporal维度上的context dependencies,对sequence的每一个frame都输出一个action class的预测;ST-LSTM,本来是3D action recognition任务的,本文修改后拿来做online的3D action recognition,这样做不知道合不合适,毕竟人家不是在online的task上设计的模型,对于online的任务不一定能有极致的表现;Attention Net,这个模型采取了attention 机制,动态地为不同的frame和不同的skeletal joint分配权重。
实验部分第一块是implementation details,作者介绍了参数的初始化、learning rate是0.001、momentum是0.9、decay rate是0.95,还介绍了在什么硬件上进行试验等等信息。
第二块是OAD数据集上的实验情况,首先介绍数据集情况,OAD数据集是用Kinect v2抓取的室内日常生活视频,包含十种动作,数据集中的long sequences对应着大约700个动作实例,30个long sequences用来训练,20个用来测试,得到实验结果是预测准确率随着观察到的片段占整个action比例的变化,如下图所示,每一个ratio对应的预测准确率是不同action instance处理到这个ratio时预测准确率的平均值,
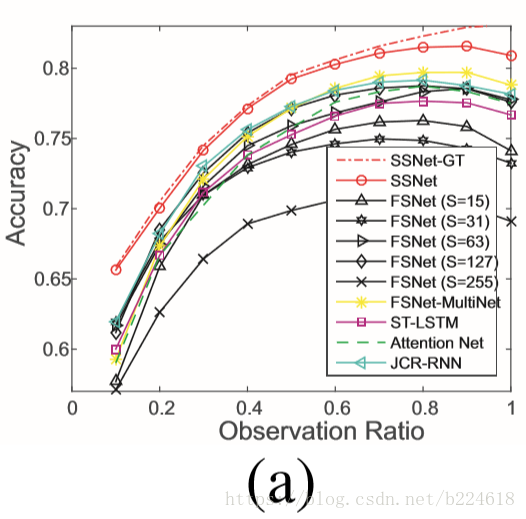
接着就是分析,SSNet-GT由于使用了ground truth,因此是表现最佳的模型,但是SSNet也能达到几乎差不多的水平,体现了scale selection scheme的有效性,除了用了ground truth的模型之外,最好的就是SSNet了,此外由上图还可看出SSNet能够在ratio很小,0.1左右的时候就提供较为可靠的预测准确率,明显由于其他算法。接着作者又分别把其他模型和SSNet对比着说了一下,SSNet表现比fixed scale的要好,不同fixed scale合起来也不如SSNet的表现好,SSNet还比其他得state-of-the-art方法表现出众,并且给出了一些performance差异的定性解读,比如在只观察到每一个action的前10%数据的时候,SSNet可以通过scale selection很好的只关注这10%的数据,但是RNN模型不能选择scale,可能就会将之前的action的frame包含进来,使得对当前frame的预测受到干扰;在action的大部分信息都已经出来了之后,例如90%,RNN模型可能又会失去当前action的前部信息;此外,作者还提到motion pattern在temporal维度上是有hierarchical structure的,RNN/LSTM模型并不能很好地处理这件事,这一点其实没太懂,不知道所谓的hierarchical structure是指什么。对于attention model,作者只是提了一句效果比他好,证明我们模型的优越性,没啥详细分析。
第三块是在PKU-MMD数据集上的实验情况,这个数据集上采取的是cross subject protocol,即57个subject用来训练,9个subject用来测试,可以测试在不同subject之间的迁移能力,这里面subject指的是做动作的人。这个数据集的结果介绍就更简单一些,基本就是重复之前的分析,首先说了由于数据集比较大,只选取了有互动的action的video,并且每4帧取一帧,之后就是用图表展示了实验结果,
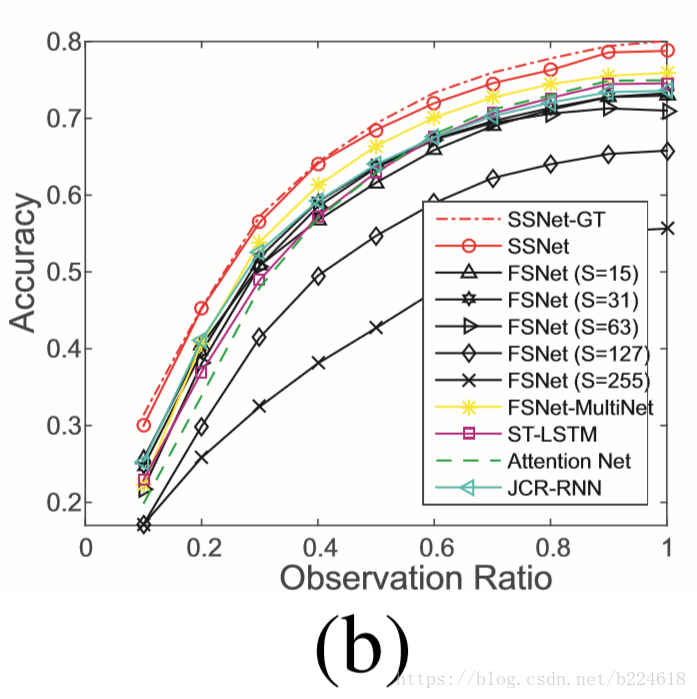
然后简单地说我们的SSNet模型明显优于其他模型,即使是只观察了很小一部分action(例如10%)的时候也是如此,说明模型更加robust。此外作者在这个数据集的结果介绍上加了一条,就是采用fixed scale的FSNet在每一步都是对scale敏感的,不同的scale产生的结果截然不同(即上图曲线出现交叉每个S值对应的曲线都不是一直最高,有时候这个高,有时候另一个S值结果好,但是好像并不是很明显的差距,这其实也好解释,上图展示的是ratio,而不是帧数的绝对值,但是S却是对应具体包含多少帧的,比如S=15,有的action可能一半是15帧,有的可能整个就15帧,那么同样帧数对应不同的ratio,30帧的action当ratio=1的时候用S=15就效果不好,而15帧的action当ratio等于1的时候用S=15效果就好,导致了不同的ratio好几个S值的结果都差不多,因为每一个ratio都对应着适合某个S值的action instance,也可能对应着不适合的,而S太大的,可能一般没有那么长的action,那么就每一个ratio都没有适合这些大S值的,这些模型表现就一直很差),这体现了scale selection scheme的有效性。
第四块是“更多试验”,分三个小版块,包括Evaluation on distance regression、Evaluation of network configurations、Frame-Level Classification。第一个板块,衡量了三个模型的distance regression结果,第一个模型是SSNet,第二个是SSNet*,这个是进行distance的时候不是将所有layer的结果都使用,而是和class label的输出类似,使用选择出来的layers,以变化的window scale进行regression,第三个模型是JCR-RNN,由于这个模型也进行每一个action的start point,因此也可以进行这个的比较。比较的结果如下

这里面的SL-Score指的是![]() ,指数上面是regress的distance与ground truth的差值的绝对值除以当前的action的长度再取负数。由此可见SSNet是效果最好的,SSNet*效果不好的原因很好理解,判断一个action的起点就是寻找当前action和前一个action的分界点,前一个action的信息当然是有用的,如果只考虑当前action的信息,是不会有好结果的。第二个小版块,介绍的是最高层dilation rate不同的SSNet的结果对比,结果如下
,指数上面是regress的distance与ground truth的差值的绝对值除以当前的action的长度再取负数。由此可见SSNet是效果最好的,SSNet*效果不好的原因很好理解,判断一个action的起点就是寻找当前action和前一个action的分界点,前一个action的信息当然是有用的,如果只考虑当前action的信息,是不会有好结果的。第二个小版块,介绍的是最高层dilation rate不同的SSNet的结果对比,结果如下
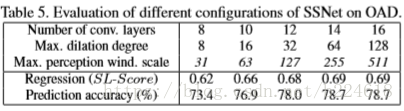
发现最高层dilation rate大一些的话效果会好,但是过大了结果就不变了,可能的原因是window scale255已经基本上大于绝大多数action的长度了,因此最大window 255就能满足一切需求了,再大就没什么意义了。最后一个小板块是对每一帧分类的准确率的对比,计算的是所有帧准确率的平均值,结果如下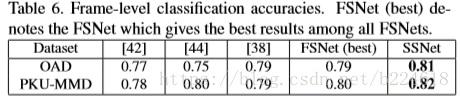

















 1276
1276


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








