







【论文题目】SSNet: A Simple Dilated Semantic Segmentation Network for Hyperspectral Imagery Classification
摘要
基于深度学习的方法在高光谱图像任务中表现出了良好的 性能。然而最近的 方法通常认为HSIC是一个补丁是的图像分类问题, 并通过给像素周围的补丁一个标签来解决它。 再次提出了一个新的分割网络结构, 它可以以端到端的结构直接标记每一个像素。该方法显著提高了训练的效率,较少了一些人工参数。HSIC面临的另一个问题是高光谱图像的空间分辨率比相对比较低,合并操作可能会导致分辨率和覆盖范围的损失。 因此在模型中使用扩张卷积并构造了一个扩张语义分割网络来解决这个问题,DSSNet是专门为HSIC设计的,不需要复杂的结构和预处理模型,可以通过端到端的方式提取联合空间光谱信息,避免了各种预处理和后处理操作。实验证明改进是有效的。
介绍
高光谱图像由几十到几百个波段组成,可以提供丰富的光谱信息,HSIC是指给图像中的每一个像素一个标签,属于语义分割技术。
最近,基于深度学习的语义分割网络被应用于HSIC任务,通过多尺度卷积和残差学习进一步增强了FCN,Deeplab是通过转移学习引入的, 其中输入的 HSI数据被减少到了三个通道。
由于已标记的样本不足,通常通过迁移学习,首先进行降维操作,将已标记的样本数据拟合到预处理好的主干中,然后,与自然科学数据相比,高光谱图像呈现出独特的特征,HSIC网络至少有两个缺点需要克服:
1、首先,卷积网络中的汇集操作会显著降低HSI数据的分辨率。由于HSI的空间分辨率较低,一些细节可能只占用几个像素。这些细节可能会在几次合并后消失,从而损害分类的准确性。
2、其次,为了使用一些预处理后的网络,高光谱数据必须降维到三个通道,这将不可避免地导致光谱信息的丢失。
考虑到上述问题,我们为HSIC开发了一个新的扩展语义分割网络。 首先,应避免合并造成的分辨率损失,以保留原生数据中的细节信息,第二,网络应该在没有迁移学习的情况下进行训练,采用一些技巧来避免过度适应,基于以上动机,我们构建了下面网络结构。
利用扩展卷积来避免分辨率降低的影响,并从HSI数据中聚合多尺度上下文信息。
构建了一个信息语义分割网络,该网络具有简单的结构和端到端的训练方式,能够充分利用HSI数据丰富的光谱信息。
其中扩张卷积是DSSNet的核心。
在CNN中,广泛使用了带汇集的离散卷积,设f() 表示一个非线性的函数,那么第l+1层中的第i个特征映射可以用如下公式表示:
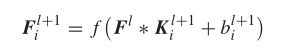
其中 l+1 是第(l+1)层中的 第i个卷积核,Sl表示第i层中的特征映射的数量,卷积之后接着是池化,以平均池化为例。
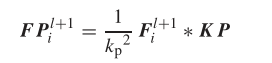
其中Kp X Kp代表窗口大小,Kp是大小为Kp X Kp的矩阵, Stride为Kp。
语义分割是一项密集的预测任务,最后输出大小应该保持与输入图像大小一样 。 因此,需要解卷积或者类似的操作,但是HSI数据的空间分辨率通常是比较有限的,有的素材可能占有几个像素。 经过几层的汇集, 某些特征可能会消失, 所以我们使用扩张卷积来避免这个问题。

下图说明了传统卷积和扩张卷积之间的区别,卷积的感受野可以通过一下方法获得:
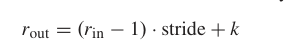
扩张卷积的感受野公式如下:
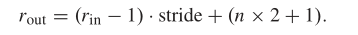
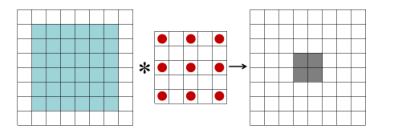
上图感受野是(1-1)*1 +(2 * 2 + 1) = 5,我们可以看到扩张卷积不增加可学习参数的情况下可以扩大感受野,更重要的是,没有池化操作,也就是说没有分辨率的损失。基于扩张卷积,我们可以简单的提取多尺度深层特征,同时保留HSI数据中的细节。
DSSNet由六层组成,其中包括四个卷积和两个全连接操作,虽然DSSNet不是一个深度网络。其中的每个卷积块包括:卷积,批量归一化,校正线性单元(Relu)激活函数。
在上图中,卷积层由conv(核大小)-(滤波器数)-(膨胀因子)描述。例如,conv-3-32-2表示内核包含3 × 3个非零权重,有32个过滤器,膨胀因子为2。请注意,当k = 3 a n d n = 2时,实际滤波器尺寸为5 × 5。然而,因为只有3 × 3的权重需要优化,这里,我们将内核大小记录为3 ×3。如果是内核,偏差也应该优化。
DSSNet模型结构图

再上图中每个卷积快的感受野显示在右侧。由于HSI空间分辨率通常较低, 13X13的感受野已经覆盖了图像中的很大区域,其中包含了丰富的上下文信息,因此,扩大感受野是没有必要的,也是不合适的。
FC块: DSSNet有两个FC块,第一个FC块为所有像素生成512的特征,第二个块对应于 类别号,DSSNet中的FC运算是通过1X1 卷积实现的,为了减轻过拟合风险,我们在FC1和FC2进行了dropout操作。
输出操作: 通过softmax函数将结果映射到【0,1】之间,将设Xp是像素p的输出向量和C是数据集中的类数,我们可以得到下面的等式:
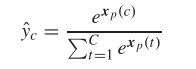
上式中,y^c是Xp数据c类的概率,Xp©表示 Xp中的c元素。
最后选择交叉熵作为损失函数,随机梯度下降和动量作为优化策略,权重衰减L2用于正则化。
关于DSSNet的分析
为了阐明扩张卷积的有效性,作者设计了一个基于池的语义分割网络,PSSNet具有DSSNet一样的结构,包括四个卷积和两个全连接操作,所有的超参数和DSSNet一样,唯一的区别就是PSSNet在么一个卷积操作之后都有池化操作。总的来说,PSSNet使用汇集而不是扩张的回旋增大感受野。

上图中a-c是DSSNet的特征图, b-d是PSSNet的特征图,但是我们看到PSSNet得到的特征图比较模糊, 而DSSNet得到的特征图包括了更多的细节信息, 这正是DSSNet的动机,合并可能导致HSI图像中的细节信息,因此更希望通过使用扩张卷积来细化特征图。
总的来说,DSSNet优点是充分利用了HSI图像具有丰富的光谱信息,孙然迁移学习框架可以利用一些强大的预训练模型,但是他们必须大幅度降低 HSI数据的维度,以适应预训练模型的输入。
实验
本实验使用了HSI四种方法进行对比,分别是3D-CNN, MugNet, HiFi和FEFCN 。其中3D-CNN和MugNet是基于拼接连接的卷积神经网络构建的,HiFi是基于传统的机器学习方法,FEFCN是基于扩张卷积策略。FEFCN模型比迁移学习框架效果更好。 使用SVM作为基线,此外结果也验证了扩张卷积在DSSNet中的优势。
评价指标采用 总体准确度(OA), 平均准确度(AA), 和K(k)。

a : 3D-CNN b:FEFCN c: DSSNet d: ground truth
其中MugNet是一个简化的深度神经网络, 它结合了一些预处理方法。
作为一种传统的基于机器学习的方法,HiFi的改进空间有限。FEFCN也是一个语义分割网络,但是我们可以看到它的准确率不是很高。原因可能是光谱损失和空间分辨率损失。在FEFCN中,输入的HSI数据必须减少到三个通道,这削弱了有用的光谱信息。此外,合并操作损害了空间分辨率,可能导致细节丢失。PSSNet和DSSNet的差距在2%左右。原因可能包括两个部分。
1、IndianP的空间分辨率低;在这种情况下,集中经营将带来更多的土地覆盖损失。
2、PSSNet的架构设计的不好,我们简单的用池化代替了扩张的卷积。
总体而言,DSSNet的表现优于其他约0.4%-2%。
消融研究
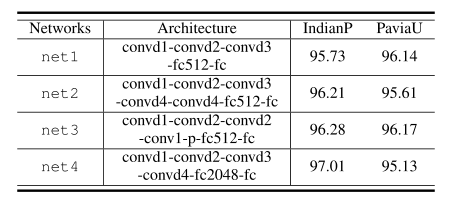
本实验通过修改DSSNet的体系结构来进行消融实验,以评估结构参数的影响。
符号“conv-p-convd2-fc128”是指“卷积-最大池化卷积,n = 2-FC层,128个神经元。”其他超参数保持与DSSNet相同。net1从DSSNet中移除一个卷积层,而net2添加一个。net3结合了扩张的回旋和汇集。net4增加了FC层的神经元数量。
不同网络的分类精度也显示在表四中,其中κ被选择用于评估。我们可以看到,网络结构的微小变化不会显著影响精度。浅层网络(如net1)可能缺乏代表性。另一方面,增加FC层(例如,net4)中的神经元数量将引入更多的参数,这些参数可能会加剧过拟合。
结论
在本论文中,我们为HSIC提出了一个 新的 语义分割 网络DSSNet.DSSNet试图利用HSI图像的特性,因此,将完整的HSI数据作为网络的输入,采用扩张卷积克服空间分辨率的损失,并通过实验证明了扩张卷积的有效性。此外,DSSNet是一个端到端的网络结构 。它不同于一些联合的光谱-空间方法, 在这些方法中,光谱和空间信息通过预处理/后处理操作策略进行组合 ,进而提高精度。















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











