







mysql基础部分在牛客网上
mysql--查询相关_牛客网 (nowcoder.com)
基础部分补充:外键,索引,起别名,事务
外键创建不成功的情况:(具体看)
- 数据类型不匹配:引用列和被引用列的数据类型不一致。
- 列属性不匹配:引用列和被引用列的属性(例如长度、是否允许NULL值等)不一致。
- 引用列没有索引:引用列没有创建索引,或者索引类型与被引用列的索引类型不匹配。
有关index,key的区别等 (具体看)
当我们在执行desc 表名;语句后,查询结果有一个Key值,表示该列是否含有索引
key 有三个值,PRI--(主键), UNI(unique key), MUL(外键或联合索引)
关于起别名
-- 别名要是一个字符串的类型,直接起别名为200是不可以的,mysql会认为这是一个数字
SELECT bookID AS 200 FROM books # 错误
-- 在前面加上字符串类型文字就会转为字符串
SELECT bookID AS 不是200 FROM books # 正确
-- 当然直接加上引号也可以
SELECT bookID AS '200' FROM books # 正确
-- 另外要注意,字符串类型无法把加 '-' 的数字转为字符串
SELECT bookID AS 不是-200 FROM books # 错误
-- 当然加上引号还是可以把其转为字符串类型的
SELECT bookID AS '不是-200' FROM books # 正确
-- 要用变量给字段起别名,我们可以用动态sql的方式实现,直接写是不对的
SET @aliasName =200;
SELECT bookID AS @aliasName FROM books # 错误
-- 动态sql,用concat拼接
-- 注意现在我们@aliasName的值是'200',但是在拼接的时候会把引号去掉,所以会报错
SET @sql = CONCAT('SELECT bookID AS ', @aliasName, ' FROM books'); # 错误
-- 我们可以在拼接的时候自己加上''
SET @sql = CONCAT("SELECT bookID AS '", @aliasName, "' FROM books"); # 正确
SELECT @sql
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;事务:
并发事务问题(脏读,不可重复读,幻读)
事务隔离级别(可读未提交 只读提交 可以重复读 串行)
innodb默认是行锁
开启事务 若查询条件为索引则会为行锁;若查询条件不是索引会升级为表锁,整个表的数据都无法修改,所以尽量使用索引列来修改数据
参考笔记 :【MySQL数据库笔记】基础篇+进阶篇_mysql数据库笔记基础篇 进阶篇 csdn-CSDN博客
一.引擎
存储引擎就是表类型。
1.InnoDB(默认)
特点:支持事务,行级锁,外键
表空间结构:
-
xxx.ibd:xxx代表的是表名,InnoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。 -
参数:
innodb_file_per_table
2.MyISAM
特点:
- 不支持事务,不支持外键
- 支持表锁,不支持行锁
- 访问速度快
表空间结构:
.sdi存储表结构信息.MYD存储数据.MYI存储索引
3.memory
特点:
- 内存存放。(直接放在内存中,而不是磁盘中,读写速度很快)
hash索引(默认)
表空间结构:
xxx.sdi:存储表结构信息
二.索引
索引就是一种数据结构。
【MySQL数据库笔记 - 进阶篇】(二)索引_mysql 查索引-CSDN博客
1.索引结构
无补充知识点,看参考笔记索引部分即可。
- B+tree 大多数引擎均支持,平时建的索引就是这个
- hash memory支持,查询快,无法排序,只能用=,in,between,<,>无法用
2.索引分类
无补充知识点,看参考笔记索引部分即可。
分为主键索引,唯一索引,普通索引。
在 InnoDB 存储引擎中,根据引擎的存储形式,又可以分为以下两种:
聚集索引存放的是一行数据,二级索引存放的是主键id
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一块,索引结点的叶子结点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子结点关联的是对应的主键 | 可以存在多个 |
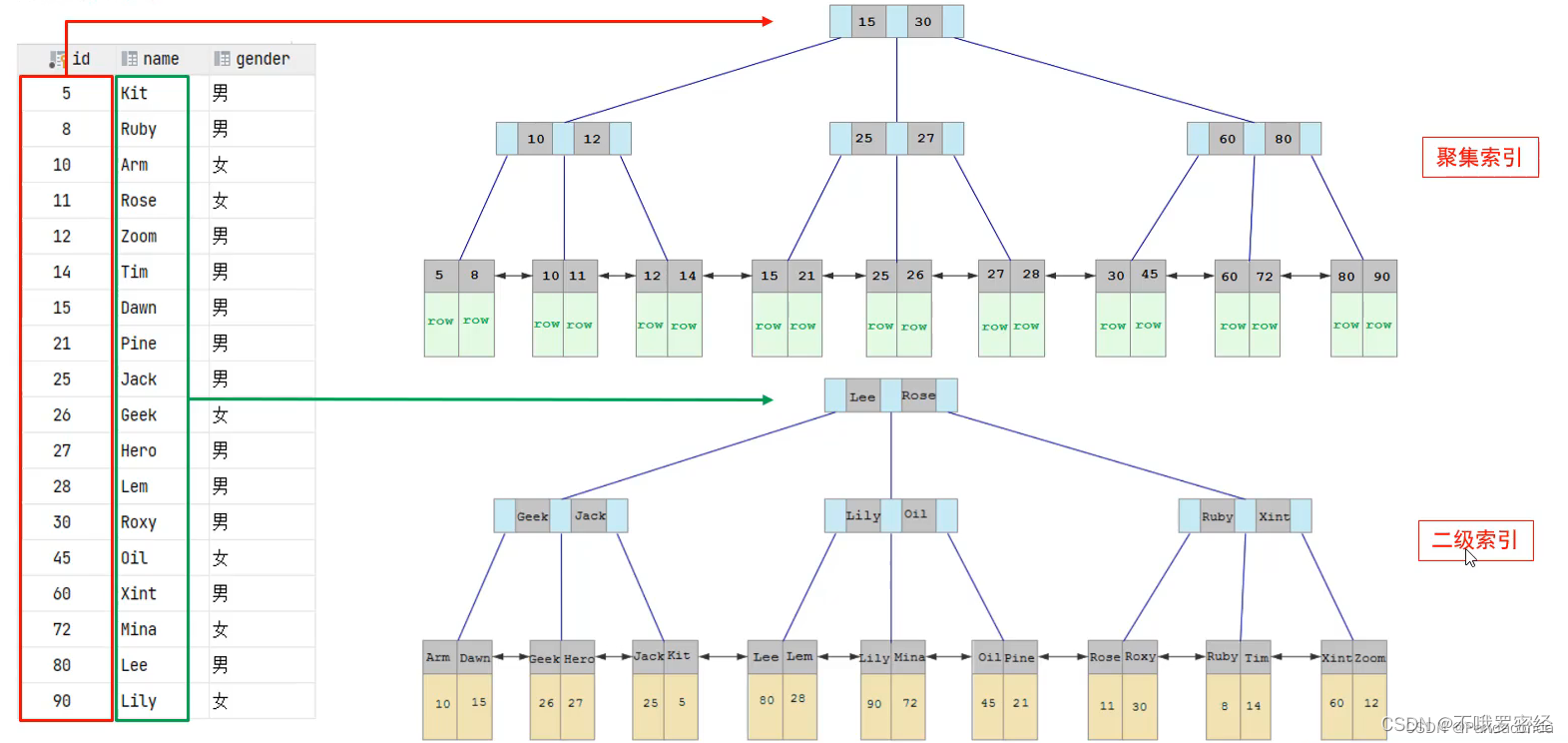
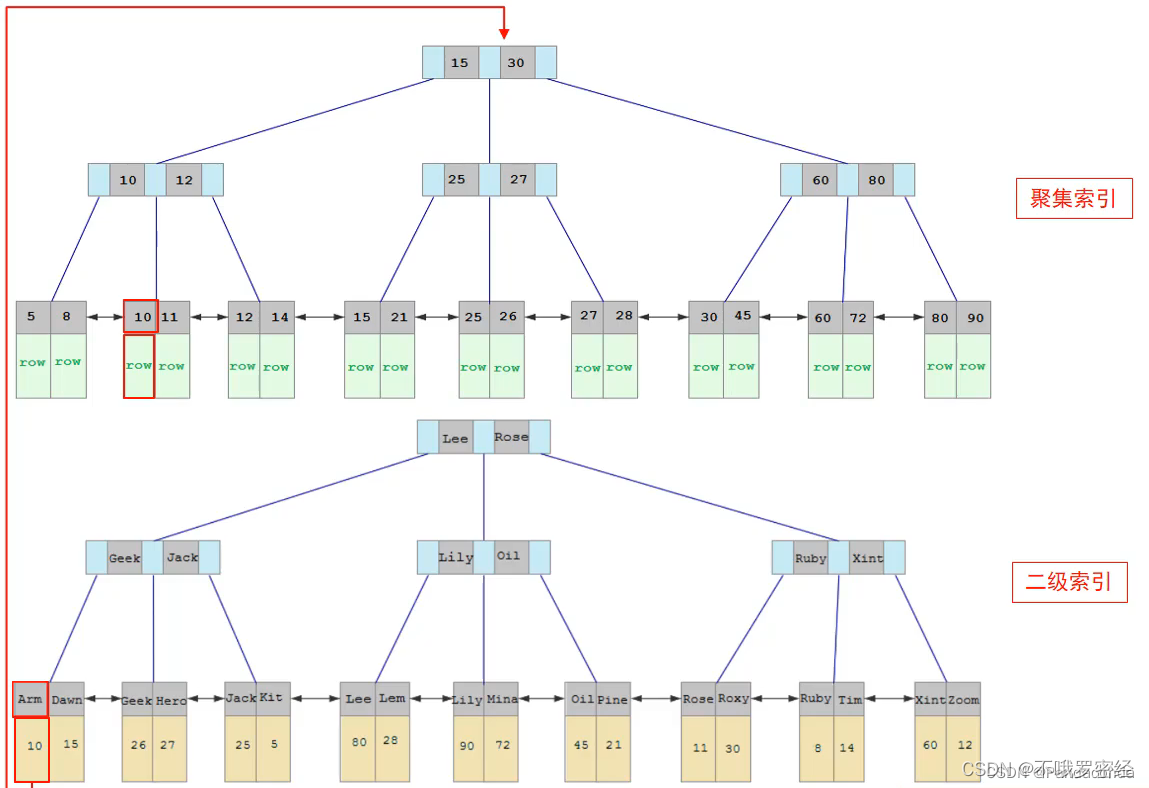
通过二级索引找到对应的值,然后再到聚集索引,这样的操作被称为回表查询。
3.索引语法
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name,...);
查看索引
SHOW INDEX FROM table_name;
删除索引
DROP INDEX index_name ON table_name;
4.SQL性能分析(查询)
1.判断是否要做查询优化
主要优化查询,若查询次数不多,无需做优化。
用下面的语句可以查询当前数据库select,insert....的次数。
(每一次select,不同软件加的不同。)
SHOW GLOBAL STATUS LIKE 'Com_______';
2.具体优化哪个sql呢
1.慢查询
用慢查询日志来看哪个sql语句效率低。
首先我们要开启慢查询日志的功能。
在linux中,mysql8.0的my.cnf被拆分成两个文件
- mysql.cnf
- mysqld.cnf(路径:/etc/mysql/mysql.conf.d/mysqld.cnf)
使用:1.开启慢查询在mysql.cnf下添加
# 开启MySQL慢日志查询开关
slow_query_log = 1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time = 2
2.配置后重启mysql
sudo systemctl restart mysql3.进入 /var/lib/mysql 查看日志文件。
输入命令后,会报错Permission denied.代表当前目录下文件无权限查看,修改等。
我们可以使用sudo chmod 777 [目标目录] /var/lib/mysql 来给用户权限。
(我不太会用这个命令,用了两次才可以访问XXX-slow.log
①sudo chmod 777 /var/lib; cd /var/lib ②sudo chmod 777 /var/lib/mysql; cd mysql; ③查看 cat [主机名]-slow.log)
4.用tail -f [主机名]-slow.log 可以查看日志文件新增的内容
2.explain执行计划
可以获取如何执行select语句,包括select语句中表如何连接和连接顺序。
explain各字段意义:
- id
select 查询的序列号,表示查询中执行 select 字句或者是操作表的顺序(若 id 相同,执行顺序从上到下;若 id 不同,值越大,越先执行)。 - select_type
表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE 之后包含了子查询)等。- type
表示连接类型,性能由好到差的连续类型为 NULL 、system 、const 、eq_ref 、ref 、range 、index 、all 。
代表意义:null (一个表不差) select ''A";
const (按主键索引或唯一索引差)
ref (按普通索引差)
index (用了索引也是全扫) select count(*);
all (全表扫)
- type
- possible_key
显示可能应用在这张表上的索引,一个或多个。 - key
实际使用的索引,如果为 NULL ,则没有使用索引。 - Key_len
表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好。 - rows
MySQL 认为必须要执行查询的行数,在 innodb 引擎的表中,是一个估计值,可能并不是准确的。 - filtered
5.索引使用原则
1.关注where后面的内容
- 多个属性值形成的索引 --> 最左前缀法则
- 必须有第一个,若跳过中间的,只会按第一个查
- 没有第一个,索引失效
- 范围查询 (>,<) 会导致右边的列索引失效,可以用>=,<=规避失败
- 在索引列上进行运算操作,索引失败
- 字符串不加引号,索引失败 --> 存在隐式的类型转换
- 模糊查询,尾部索引不会失效,头部索引会失效
- or 前后列均有索引才会用索引
2. 关注select的内容
- 覆盖索引
尽量查询的字段索引中都有,防止回表查慢 (id不用回表查询,因为二级索引内容为id)
3.数据分布影响
如果 MySQL 评估使用索引比全表更慢,则不使用索引。
4.sql提示
有多个索引,人为指定索引
- use 建议
- ignore 忽略
- force 强制
5.前缀索引
有的列会很长,比如文章标题,内容,如果全用其做索引,索引占用空间会很大,影响效率。
所以可以把字符串的一部分前缀建立索引。
create index idx_xxx on table_name(column(n));
n就是指定的长度。
长度怎么选
尽量截取最少得字符作为前缀索引,让选择性尽量接近或者等于1
其中选择性计算公式为:不重复索引值的数量/总记录数
select count(distinct email)/count(*) from tb_user;
select count(distinct substring(email,1,5))/count(*) from tb_user;
create index idx_email_5 on tb_user(email(5));
在查询过程中,由于截取的是前n位,所以row拿到后,会先匹配是否与全名一致,若一致,会接着看下一个节点是否为前n位,是,返回,再看下一个节点,直到不是。
6.单列索引和联合索引
多个查询条件,建议建立联合索引(要考虑顺序,最左前缀原则)
三.sql优化
四.存储过程
1.变量
mysql中变量不用事前申明,在用的时候直接用“@变量名”使用就可以了。
第一种用法:set @num=1; 或set @num:=1; //这里要使用变量来保存数据,直接使用@num变量
第二种用法:select @num:=1; 或 select @num:=字段名 from 表名 where ……
注意上面两种赋值符号,使用set时可以用“=”或“:=”,但是使用select时必须用“:=赋值”
第三种用法:select 字段名1,字段名2 into @变量1,@变量2 from 表名 where ......
在函数或存储过程或触发器中,在不能使用set的时候推荐第三种,因为第二种会在执行时返回查询结果,这在函数或触发器中会报 “Not allowed to return a result set from a function”错误。而第三种则不会报错。
2.流程控制
- 分支两个
if...then... elseif...then...else...then...end if;
case when...then...when...then...else...then...end case; - 循环三个
while ... do ...end while;
repeat .... until... end repeat;
XXX:loop ....end loop XXX; leave XXX;离开XXX循环,iterate XXX;离开这个循环进入下一个循环
3.游标
用来存储查询结果集的数据类型(相当于迭代器)
- 1.游标声明后绑定到一个查询结果集,就不可以直接被重新赋值为另一个结果集。
- 2.close 游标后,就是把其占用的内存均回收,这个游标就消失了,
- 此时,我们可以起一个一样名字的游标,来获取其他数据集。
- 3.每次从新open游标就会重新执行这个查询。
- 4.关闭后重新开启游标会涉及到资源分配和管理操作,太频繁会性能下降。
4.条件处理程序
MySQL存储过程异常处理_mysql 存储过程exception-CSDN博客
在流程控制结构中遇到的问题进行相应的处理
(1) 异常定义
declare 错误名称 condition for 错误码(或错误条件)
错误码:数值类型
错误条件:char(5)
(2) 异常处理器
declare 处理方式 condition for 错误类型 处理语句处理方式:continue exit
错误类型:sqlstate '字符串错误码' , mysql_error_code ,错误名称 ,sqlwarning, not found, sqlexception
5. 关于声明顺序
- Declare语句通常用来声明本地变量、游标、条件或者handler
- Declare语句只允许出现在
BEGIN...END语句中而且必须出现在第一行 - Declare的顺序也有要求,通常是先声明本地变量,再是游标,然后是条件和handler
6.begin...end
- 可以用在存储过程,存储函数,事件,触发式上。
- 可以多嵌套,完成复杂任务可以用。比如:创建一个临时表,从临时表中获得数据集。
- 可以给begin..end代码块起名字,通过iterate语句跳回循环顶部,leave语句跳出这个循环。
begin //1
create 临时表 ;
begin //2
DECLARE cur cursor for select * from 临时表;
end; //2
end; //1label begin
if ... then leave label;
end if;
end;五.存储函数
是又返回值的存储过程,存储函数的参数只能是in类型的
六.视图
就是对基表的一个窗口去看,去改,去删,所以实际操作的都是基表。
视图进行更新必须要求与基表一一对应,若采用聚合函数等,多条数据对应一个视图中一行,那就不可以更新。
视图没有索引。
- cascaded check option;--->连锁检查,检查依赖的上一级视图是否满足
- local check option;--->本地检查,只检查符不符合自己的条件,不会看依赖的视图
七.触发器
就是定义在进行什么操作后,在触发日志表中添加一条有关数据
八.动态sql
mysql可以使用concat函数搭配流程控制语句
set @sql=concat('select * from','...')
# 预编译,准备拼接的sql语句
prepare stmt from @sql;
# 执行拼接的sql语句
execute stmt;
# 释放语句
deallocate perpare stmt;















 6793
6793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









