







一.绪论
1.算法的性质
输入,输出,有穷性,确定性,可行性
2.什么是好算法
健壮性,正确性,可读性,高效率低存储需求
3.算法分析的目的
估算算法所需的资源,比较和评价算法。
4.时间复杂度
- 与问题规模n相关
- 计算方式 主定理:T(n)=aT(n/b)+c*n^k
当logba>k时,时间复杂度为n^logba
当logba<k时,时间复杂度为n^k
当logba=k时,时间复杂度为n^k*logn - 常用的时间复杂度记忆
二分 最坏平均均为O(logn)
归并 最坏平均均为O(nlogn) 空间复杂度O(n)
快排 最坏O(n^2) 平均O(nlogn) - 常数级,指数级
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)
O(2^n)<O(n!)<O(n^n) - 渐进时间复杂度的含义 --> 当n趋于无穷大时,运行时间的增长趋势。
- 算法的时间复杂度指算法中基本语句的执行次数
二.分治
伪代码部分记住只有二分是l==r是合法的,要再搜一遍
1.思想
- 分 --> 规模较小,相互独立,类型相同
- 治
- 合
将一个难以直接解决的大问题,分割成k个规模较小的子问题,这些子问题相互独立,且与原问题相同,然后各个击破,分而治之。
一般原则:子问题均匀划分、递归处理
2.分治算法的时间复杂性
满足如下形式的递归方程:
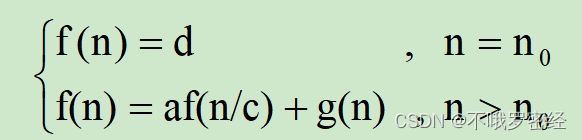
其中,g(n)表示 将问题分割与合并问题解的时间
可以通过减小子问题规模来提高效率
3.二分
1.基本过程
- 首先,将要查找的数组按照升序排序
- 然后,去数组的中间元素
- 如果中间元素等于目标元素,则返回中间元素所在的位置
- 如果如果中间元素大于目标元素,则返回中间元素的左侧子数组中继续查找
- 如果如果中间元素大于目标元素,则返回中间元素的右侧子数组中继续查找
- 重复以上步骤,直到找到目标元素或者确定目标元素不存在
2.伪代码
l=0 , r= n-1
while l<=r do
mid = (l+r)/2
if m[mid]==target then return mid;
else if m[mid]>target then r=mid-1;
else l=mid+1;
end while4.归并
1.基本过程
将待排序列二分为若干个子序列 -- 递归的对子序列进行排序 -- 合并排好序的子序列
2.伪代码
输入:T[1..n]
输出:排好序的T[1..n]
sort(l,r)
1.if (l>=r) return;
2.mid=(l+r)/2;
3.sort(l,mid)
4.sort(mid+1,r)
5.//合并两个子数组
i=l,j=mid+1,k=1
q[1...n]
while(i<=mid&&j<=r) do
if T[i]<=T[j] then q[k++]=T[i++]
else q[k++]=T[j++]
end while
while(i<=mid) do q[k++]=T[i++]
while(j<=r) do q[k++]=T[j++]
T[l...r]=q[1,k]习题练习:
归并排序 :A (65,70,75,80,85,55,50,2)

5.快排
1.基本过程
选取左边第一个元素作为基准元素,从[l+1,r]中不断找i>=基准元素,j<=基准元素,交换,
如果i>j,那就让j与基准元素交换。
快速排序算法的性能取决于 基准元素如何对序列进行划分
随机选取基准元素 可以避免快排总是陷入最坏情况
2.伪代码
输入:T[1...n]
输出:排好序的T[1...n]
sort(l,r)
1.if(l>=r) return;
2.q=find(T) //基准元素所在位置
3.T[l]=T[q]
4.sort(l,q-1)
sort(q+1,r)
find(T) //通过基准元素化划分元素,同时返回基准元素要在的位置j
i=l,j=n+1
while j>i
repeat i++
until T[i]>=m
repeat j--
until T[j]<=m
if j>i then swap(T[i],T[j])
else return j
习题练习:
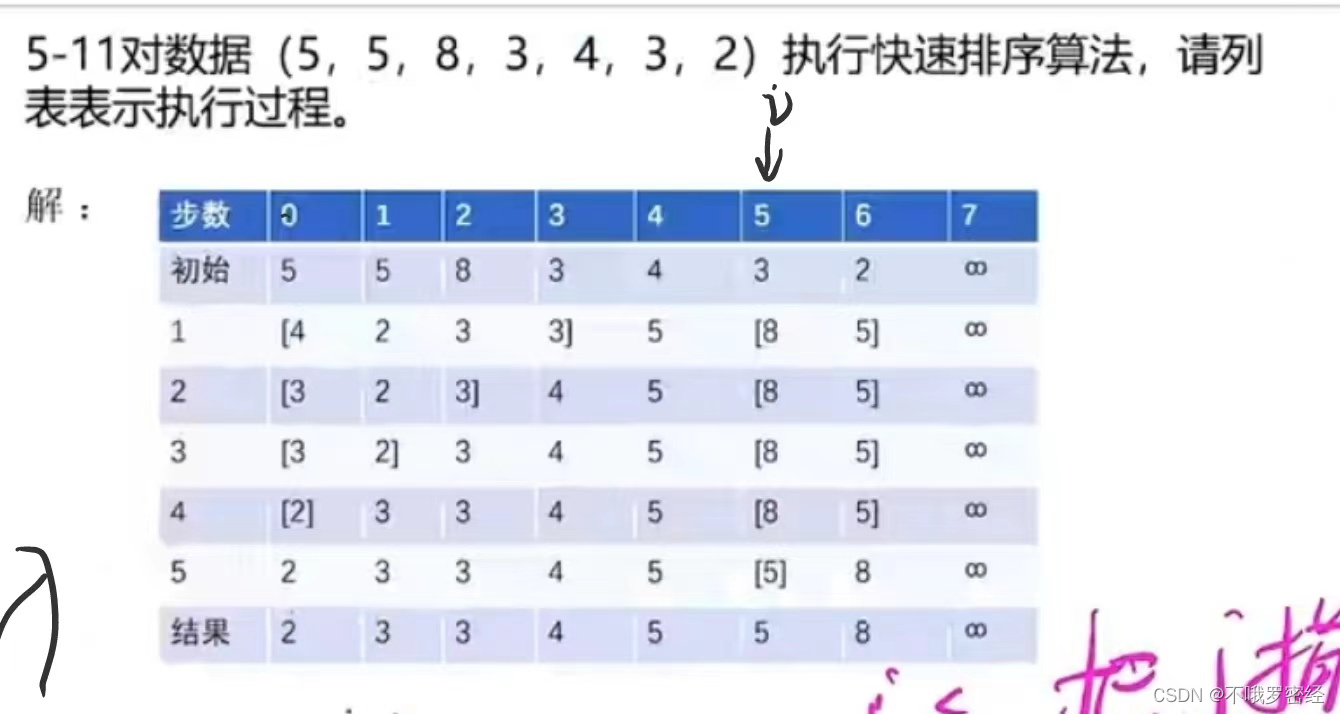
6.最大和数组
伪代码


7.求第k小的数
伪代码
输入:T[1...n]
输出:第k小的数
sort(l,r)
1.if(l==r) return T[l];
2.q=find(T)
3.T[l]=T[q]
4.if(k<=p) eturn sort(l,q)
else return sort(q+1,i)
find(T)
x=T[l]
i=l,j=r+1
while i<j do
repeat i++
util T[i]>=x
repeat j--
util T[j]<=x
if i<j then swap(T[i],T[j])
else return j额外补充
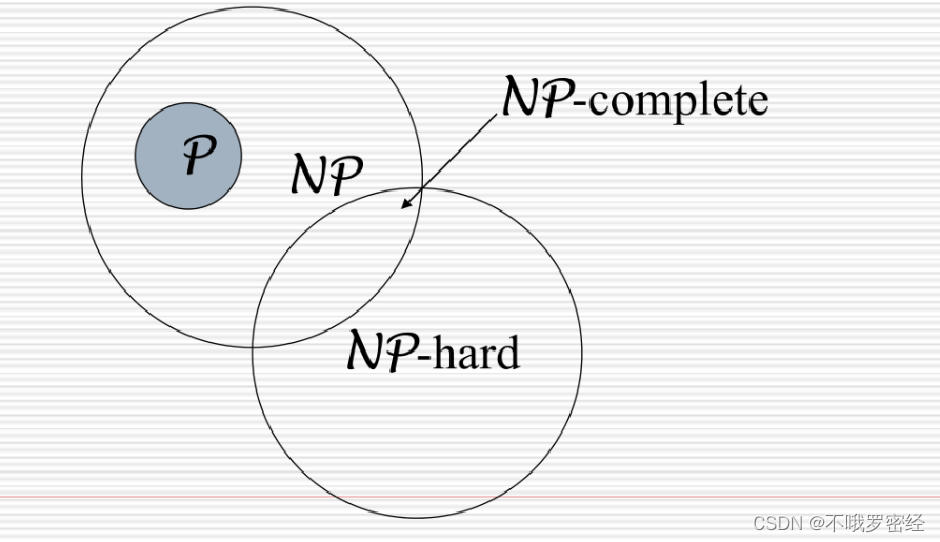
np问题
p问题 --> 确定算法
np问题 --> 不确定算法,可验证问题解
线性规划
1.标准化
- 将>=,<=号右边的数字变成非负
- 将>=,<=号变成等号,引入非负变量,xi
- 将所有取值为任意值的变量,变成两个非负变量相减的结果
2.填表















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









