







需求
有一个会执行luckySheet脚本并且导出excel的node接口,会在每天凌晨执行,但是文件过大时会内存溢出
之前有用worker来实现多线程(主要是避免变量污染),但这样只能保证主线程不卡死,几个子线程合起来占用内存也很大,然后改用流的方式导出来优化占用内存过大的问题。
但是exceljs插件用流的方式导出不支持导出图片,所以有图片就用流的方式导出,没图片还是用一开始的方式导出。为了继续优化这个状况,主管说:“反正是在晚上执行,我们搞个请求排队来限流,一个一个执行,只要白天用户能看到结果就行。”
总结下来这个接口的特点就是:有一点并发量,并且单次请求处理占用资源大(cpu密集型),而且不用考虑时间成本
代码
实现思路:
在业务中间件之前使用一个中间件(就叫他“排队控制中间件”),用于控制什么时候执行业务处理中间件。
我们需要在外部定义一个数组用于存放next(因为执行next就是去执行逻辑处理中间件),还有一个变量用于显示当前有无逻辑处理在进行。
在“排队控制中间件”中,将next入队,并在没有业务中间件在执行的情况下尝试执行队列的第一个next;如果一个业务中间件执行完成,也会尝试去执行队列的第一个next。
代码如下:
globalThis.runQueue = []; //存放next的数组
globalThis.isProcessing = false; //用于显示当前是否有业务在处理
function processQueue() {
if (globalThis.runQueue.length > 0 && !globalThis.isProcessing) {
globalThis.isProcessing = true;
const { req, res, next } = globalThis.runQueue.shift();
next(); // 执行下一个中间件
}
}
app.post('/gongqi/code', function(req, res, next){
const isNeedLieUp= req.body?.params?.isNeedLieUp;
if (isNeedLieUp) {//接口的参数来控制这个接口是否需要进入排队机制
globalThis.runQueue.push({req, res, next}); // 将请求加入队列
processQueue(); // 尝试处理队列
} else {
next(); // 不需要排队,直接执行下一个中间件
}
}, async function (req, res, next) {
// 这里是您的请求处理逻辑
// 处理完成后,需要调用某个函数来触发队列的下一个处理,例如在响应发送后
// 假设这里是异步操作,操作完成后应该调用processQueue()来检查并处理队列中的下一个请求
// 为了示例,我们使用setTimeout来模拟异步操作
setTimeout(() => {
// 假设这里是处理完成后的逻辑
res.send({ message: '处理完成' });
globalThis.isProcessing = false;
processQueue(); // 处理队列中的下一个请求
}, 1000);
});
效果
我用for循环模拟了同时10个请求(导出一个比较小的xlsx,在项目中的比较大,有些需要导出一年的数据),用pm2 monit看一下,有无请求排队的内存占用情况。
1、 使用请求排队后内存情况如下:请求依次执行,每次请求内存占用峰值能达到5-6百多兆。

2、不使用请求排队的情况如下:请求会“交替处理”,占用的内存能达到2G。
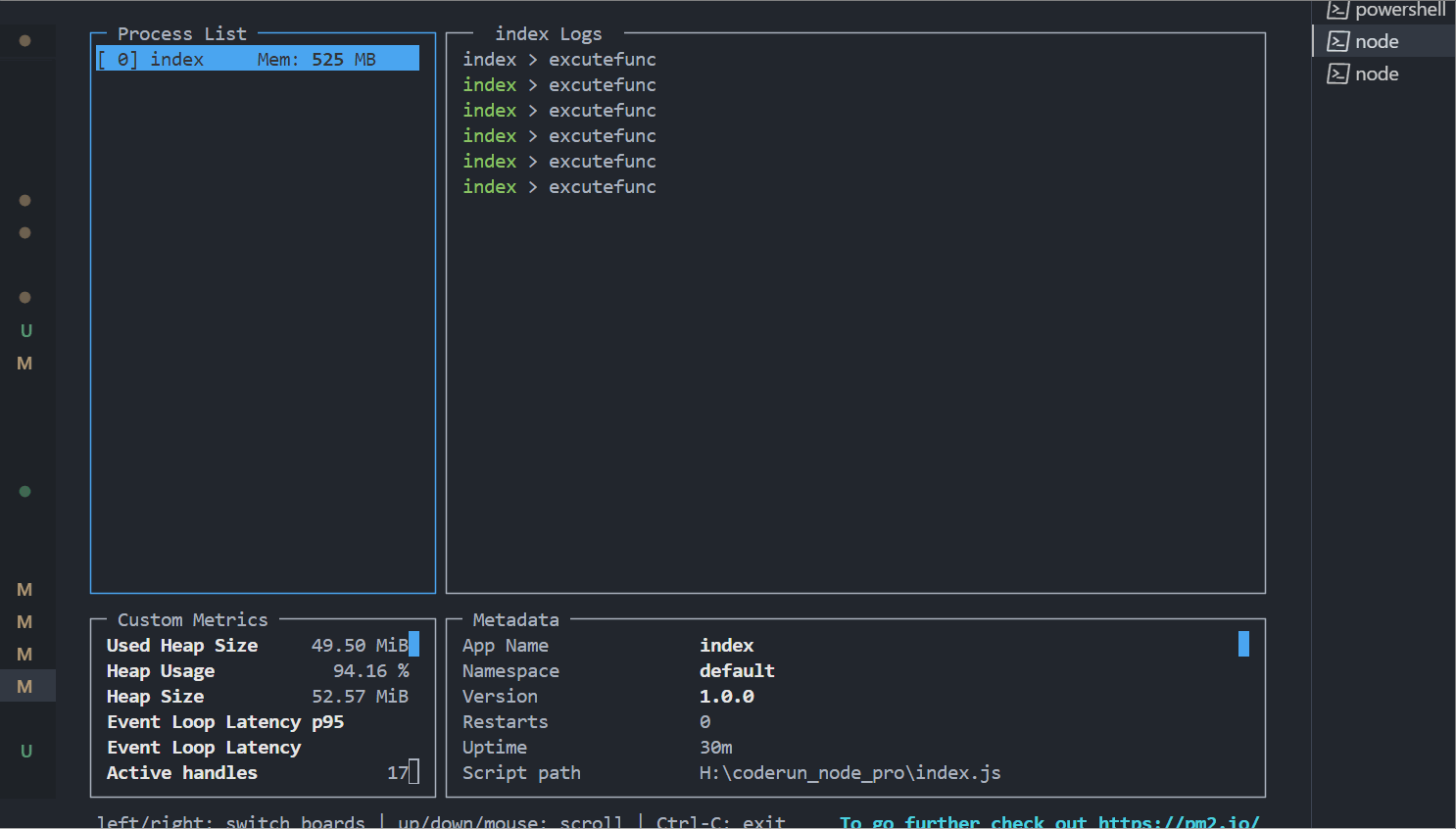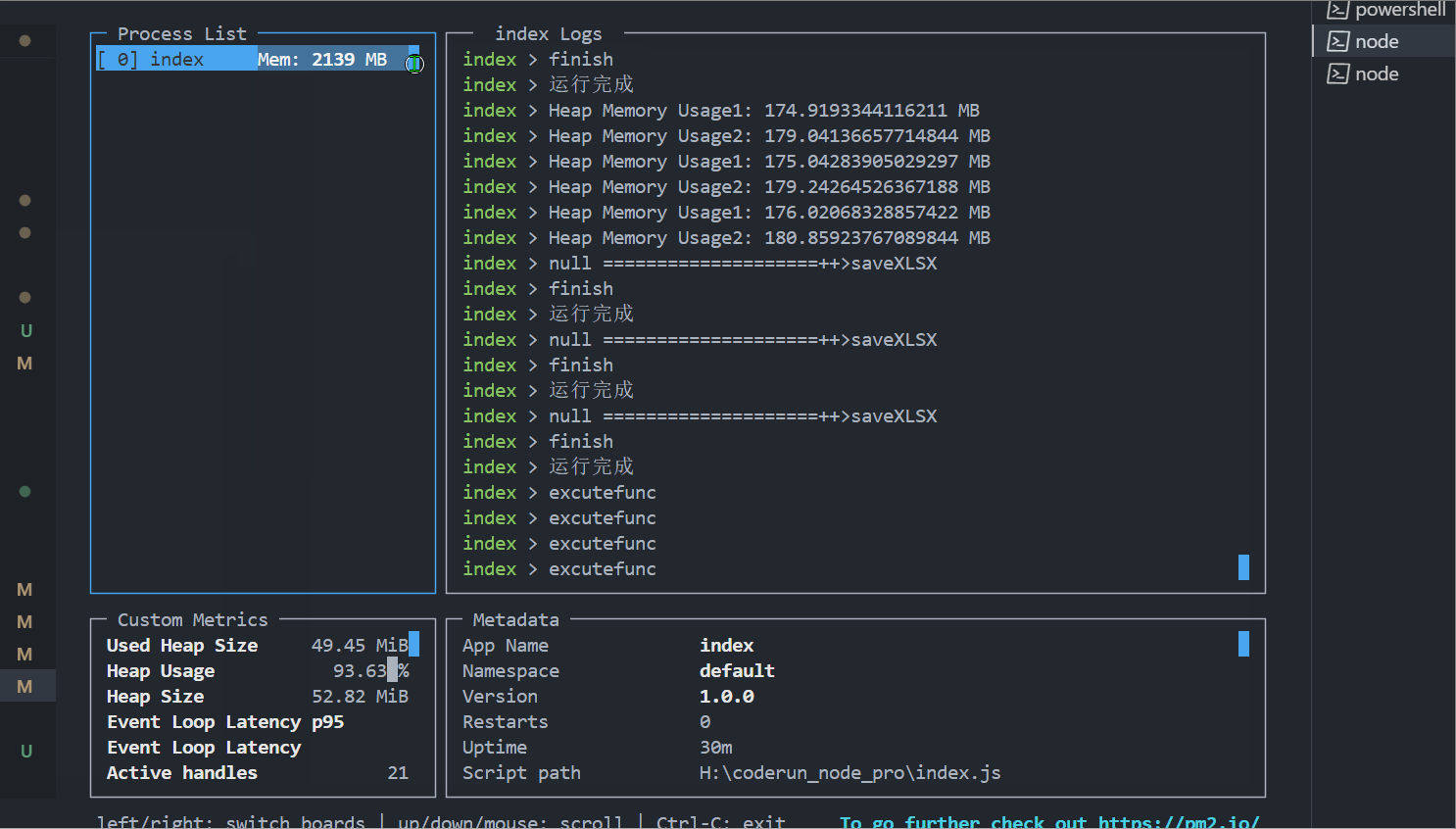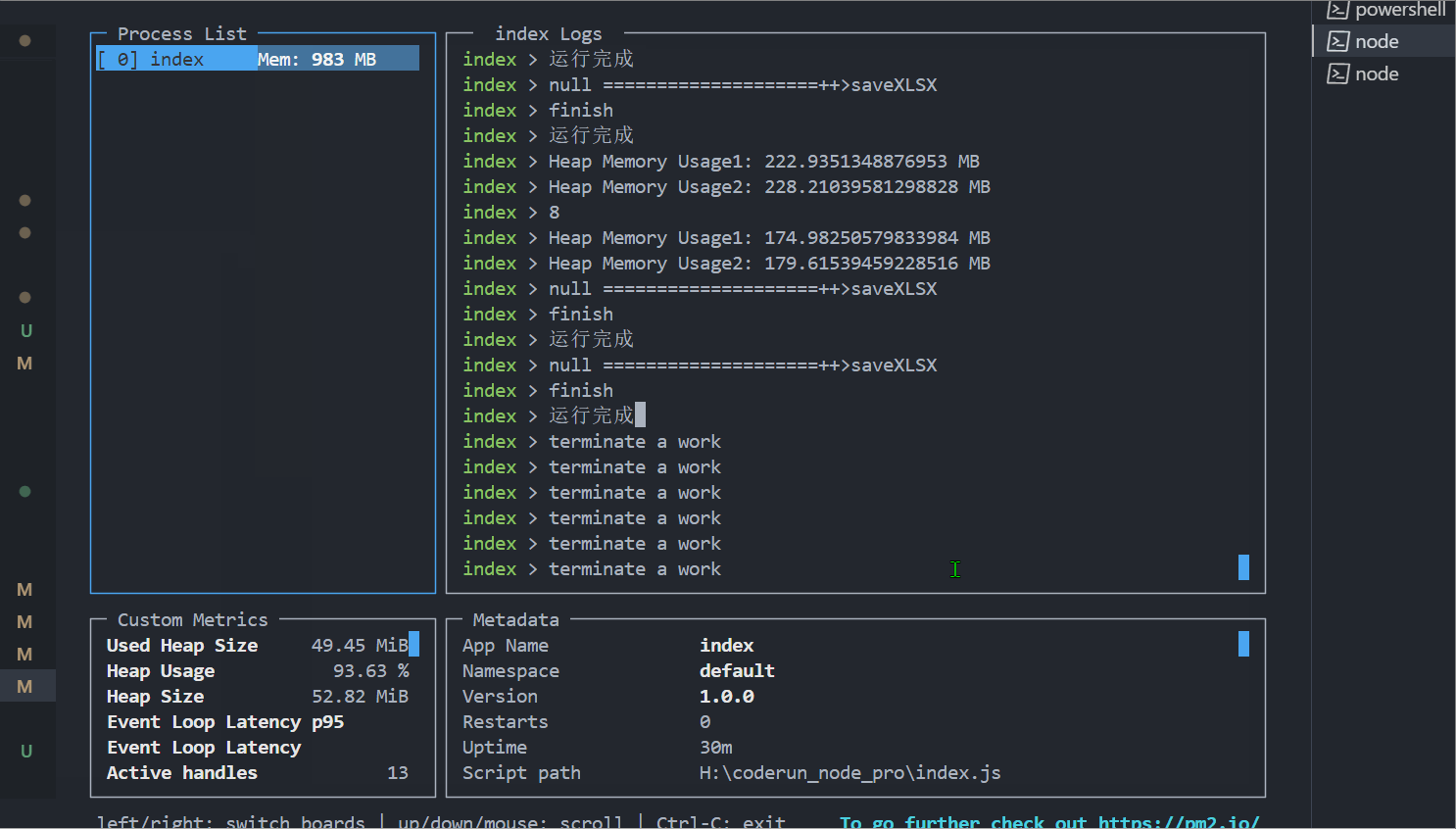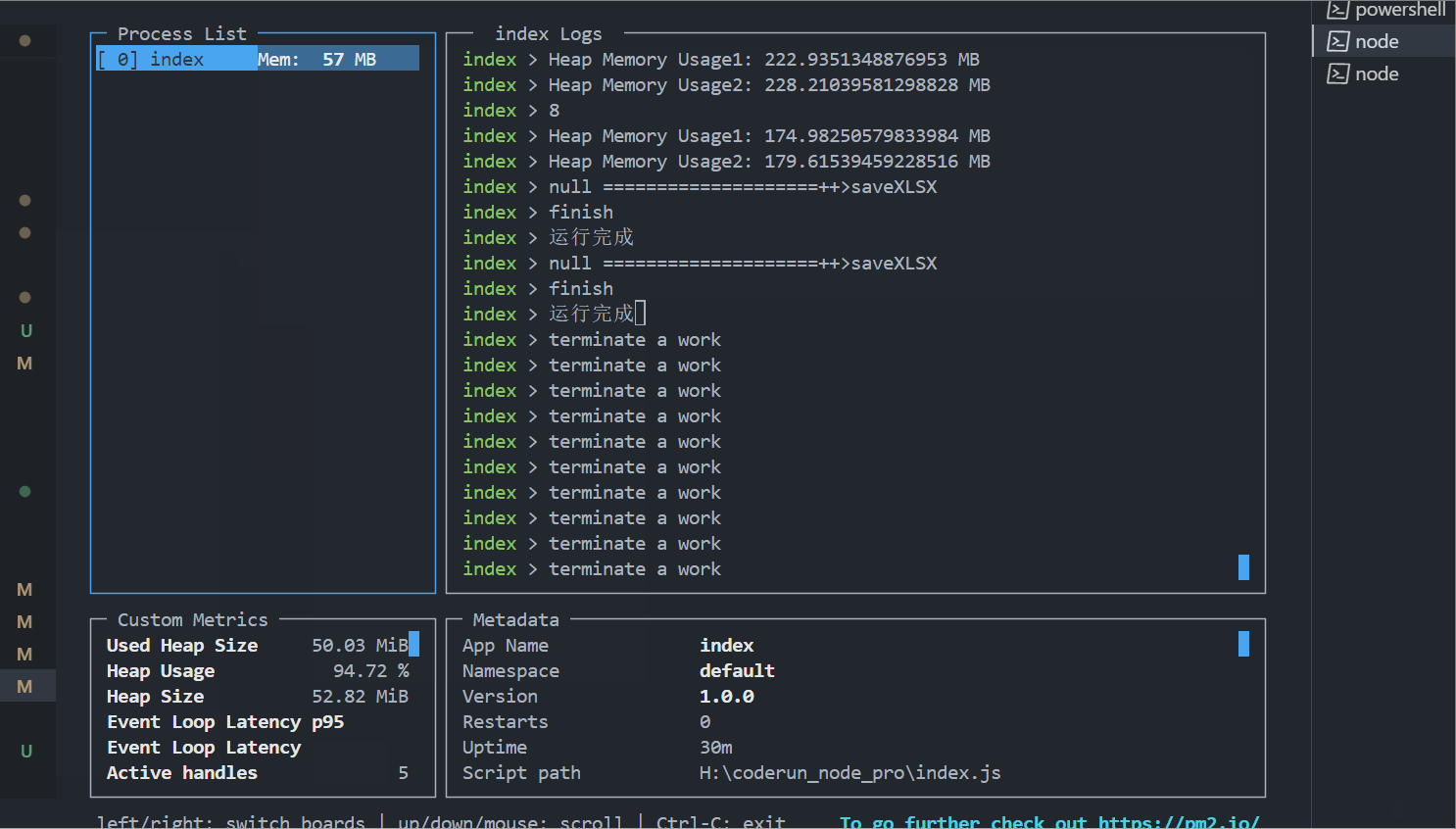
如果并发量更大或者xlsx更复杂,对比更强烈,所以还是有点用的,哈哈哈。
思考
js单线程,node在处理请求时也不会创建新的线程,我竟然认为在node中的请求默认是排队的。
原来node可以异步执行i/o调用,事件循环又能使node在等待io时继续执行其他任务,而不是阻塞线程,所以就有了说node适合高并发和io密集型的任务。
但在本需求中,导出excel属于cpu密集型的操作,还可以改进的是在导出excel时再使用worker创建多线程来处理任务(不止接口的多线程,而是在处理导出excel时再细分线程)。
其他概念
接下来介绍下,写这个需求时遇到的一些知识,了解了解。
限流
上面的请求排队应该也算限流吧,只是可能不入流,能用的前提条件比较多,哈哈。如果有用nginx,可以用设置请求速率和并发连接数来限流。在node中也有一些第三方限流库,比如“`express-rate-limit“。
以下内容来自ai: 后端限流
后端限流是一种重要的系统保护机制,用于控制访问后端服务的速率,以防止过载,确保系统的稳定性和可用性。限流可以在不同的层次上实现,包括应用层、中间件层和网络层。以下是一些常见的后端限流策略和技术:
1. 固定窗口限流
固定窗口限流算法将时间分割成固定大小的窗口,每个窗口内允许的请求量有上限。当请求量达到上限时,新的请求会被拒绝,直到下一个时间窗口开始。这种方法实现简单,但可能会在窗口切换时出现请求量突增的情况。
2. 滑动窗口日志
滑动窗口算法是固定窗口的一种改进,它通过记录每个请求的时间戳,动态计算最近一段时间内的请求总量。这种方法可以更平滑地控制请求速率,但实现相对复杂,需要维护一个时间窗口内的所有请求记录。
3. 令牌桶算法
令牌桶算法使用一个令牌桶来控制请求的速率,系统以恒定速率向桶中添加令牌,处理请求时需要从桶中取出令牌。如果桶中没有足够的令牌,请求则被限流。这种方法可以允许一定程度的突发流量,同时保持长期的速率控制。
4. 漏桶算法
漏桶算法将请求放入一个固定容量的桶中,系统以恒定的速率从桶中取出请求进行处理。如果桶满了,则新的请求会被拒绝或排队。漏桶算法可以平滑地处理突发流量,但不允许突发流量的短期增加。
5. 基于队列的限流
基于队列的限流通过将请求排队,并控制处理队列中请求的速率来实现限流。这种方法可以用于实现更复杂的限流策略,如基于优先级的限流,但需要合理设计队列长度和处理策略,以避免过长的等待时间。
实现工具和库
Nginx:通过配置 Nginx 的 `limit_req` 模块和 `limit_conn` 模块,可以实现简单的请求速率和并发连接数限制。
HAProxy:支持基于各种条件进行复杂的流量控制和限流。
Guava RateLimiter:Google 的 Guava 库中包含了 RateLimiter 组件,提供了基于令牌桶算法的限流实现,适用于 Java 应用。
Node.js Rate Limiter:对于 Node.js 应用,有多个限流库可用,如 `express-rate-limit`,提供了基本的限流功能。限流策略的选择和实现应根据具体的应用场景、性能要求和系统架构来决定。正确的限流策略可以有效地保护系统免受过载影响,确保服务的稳定性和响应性。
worker threads和child processes区别
worker是在一个进程下开启多线程,每个线程有自己的执行栈和局部变量。可以共享一个进程的资源,但是子线程不能直接访问主线程变量,需要通过消息通信等方法获取。创建和销毁的成本较低。
child processes则创建子进程,每个子进程有自己独立的内存空间和v8实例,父子进程也能通信,创建和销毁成本较大。
以下内容来自ai: node的worker和child_process有什么区别
Node.js 中的 Worker Threads(工作线程)和 Child Processes(子进程)都允许在 Node.js 应用程序中执行并行操作,但它们在底层实现、使用场景和通信方式上有所不同。
### Worker Threads(工作线程)
- **实现方式**:Worker Threads 提供了一种在同一个进程内运行多个线程的能力。这意味着所有线程共享同一个进程的资源,但是每个线程有自己的执行栈和局部变量。
- **使用场景**:适用于需要并行执行计算密集型任务而不离开当前进程的场景。由于线程间可以共享一部分内存,这对于需要共享大量数据的任务来说非常高效。
- **通信方式**:线程之间可以通过 `MessageChannel` 和 `MessagePort` 进行通信,也可以通过共享内存(如 SharedArrayBuffer)直接交换数据。
- **优点**:创建和销毁成本相对较低,内存共享可以简化某些并行操作的数据交换。
- **缺点**:多线程编程可能会引入复杂性,如竞态条件和死锁等问题。### Child Processes(子进程)
- **实现方式**:Child Processes 允许 Node.js 应用创建新的进程,每个子进程都有自己的 V8 实例和独立的内存空间。子进程可以执行 Node.js 脚本或任何在系统上可执行的文件。
- **使用场景**:适用于需要执行独立任务的场景,特别是那些可能需要执行外部应用或脚本的任务。子进程可以完全独立于父进程运行,不会共享内存或执行环境。
- **通信方式**:父进程和子进程之间主要通过 IPC(进程间通信)通道进行通信,可以发送消息和共享数据。也可以通过标准输入输出流(stdin、stdout、stderr)进行通信。
- **优点**:进程间完全隔离,可以利用多核 CPU 的优势,适合执行需要隔离或需要大量资源的任务。
- **缺点**:创建和销毁子进程的成本相对较高,进程间通信比线程间通信更复杂和开销更大。### 总结
- **Worker Threads** 更适合执行计算密集型任务,特别是当这些任务需要访问共享数据时。
- **Child Processes** 更适合执行独立的、资源密集型任务,或需要执行系统命令和外部程序的任务。选择使用 Worker Threads 还是 Child Processes 取决于具体的应用场景、性能要求和资源管理策略。














 1772
1772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









