







废话不说,直接切入正题~!
一、卸载Openjdk
先用 java –version查看OpenJDK是否安装;
如安装,输入:rpm -qa | grepjava
显示如下信息:
<span style="font-size:14px;">java_cup-0.10k-5.el6.x86_64
libvirt-java-0.4.7-1.el6.noarch
tzdata-java-2012c-1.el6.noarch
pki-java-tools-9.0.3-24.el6.noarch
java-1.6.0-openjdk-devel-1.6.0.0-1.45.1.11.1.el6.x86_64
java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64
libvirt-java-devel-0.4.7-1.el6.noarch
java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64</span>
卸载:
<span style="font-size:14px;">rpm -e --nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-devel-1.6.0.0-1.45.1.11.1.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64
</span>一、安装JDK
① 下载jdk文件,并上传至虚拟机;
② mkdir /java,并用cp命令将java文件拷贝至次目录下;
③ tar –zxvf jdk-7u60-linux-x64.tar 生成目录jdk1.7.0_60
④ 配置环境变量,运行命令:vi /etc/profile
在最后添加:
<span style="font-size:14px;"># set java environment
export JAVA_HOME=java/jdk1.7.0_60
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
</span>① source /etc/profile
② 输入java –version查看,如显示:
<span style="font-size:14px;">java version "1.7.0_60"
Java(TM) SE Runtime Environment (build 1.7.0_60-b19)
Java HotSpot(TM) 64-Bit Server VM (build 24.60-b09, mixed mode)
</span>表示配置正确。
一、建立ssh无密码登录本机
1. 创建ssh-key,
| ssh-keygen -t rsa -P "" |
如图:(连续回车即可)

创建成功;
2. 进入~/.ssh目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的;<span style="font-size:14px;">cd ~/.ssh
cat id_rsa.pub >> authorized_keys
</span>
3. 登录localhost,验证配置是否成功。
|
|
一、安装hadoop2.2.0
1. 解压缩文件至home目录下;
| tar -zxvf /home/HFile/Hadoop-cdh4.7.tar.gz -C /home |
2. 配置环境变量,在根目录下进入etc/profile,添加如下:
<span style="font-size:14px;">#set Hadoop environment
export HADOOP_HOME=/home/Hadoop-cdh4.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/Hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/Hadoop
</span>
3. 进入Hadoop-cdh4.7中etc/hadoop中,
① 修改hadoop-env.sh
| export JAVA_HOME=/java/jdk1.7.0_60 |
② vi core-site.xml
<span style="font-size:14px;"><configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-cdh4.7/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
<!--
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
-->
</configuration>
</span>③ vi hdfs-site.xml
<span style="font-size:14px;"><property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop-cdh4.7/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop-cdh4.7/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</span>④ 复制mapred-site.xml.template成mapred-site.xml,修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml<span style="font-size:14px;"><property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>localhost:9101</value>
<final>true</final>
</property>
</span>⑤ vi yarn-site.xml
<span style="font-size:14px;"><property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description>hostanem of RM</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run </description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</span><span style="font-size:14px;">
</span><span style="font-size:14px;"><span style="color:#ff0000;">注:在cdh4中为mapreduce.shuffle,cdh5中为mapreduce_shuffle
否则nodemanager启动不了。</span>
</span>⑥ 运行hadoop namenode –format
⑦ 接着执行start-all.sh
⑧ 执行jps,如如下图所示,则表示正常启动:
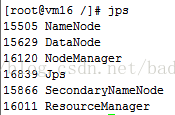
⑨ 最后进入Hadoop-cdh4.7\share\hadoop\mapreduce录入中,测试运行:
hadoop jar hadoop-mapreduce-examples-2.2.0.jar randomwriter out
查看运行是否成功。
查看集群状态:
hadoop dfsadmin –report
如果datanode启动不了检查是不是防火墙没有关闭:
关闭命令:service iptables stop
4. 运行wordcount任务测试:
① 建立file1与file2,及input文件夹:
<span style="font-size:14px;">echo “hello world bye wold” > file1
echo “hello hadoop bye hadoop”>file2
hadoop fs –mkdir /input
</span>② 将file文件传入input
<span style="font-size:14px;">hadoop fs -put /home/hadoop-cdh4.7/file* /input</span>③ 运行wordcound程序:
<span style="font-size:14px;">hadoop jar /home/hadoop-cdh4.7/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.0.0-cdh4.7.0.jar wordcount /input /output1</span>④ 查看结果:
hadoop fs -ls /output1

hadoop fs -cat /output1/part-r-00000

至此hadoop安装彻底完成!
其他注意问题:
cdh是编译之后的包,可直接用于X64的系统,如果是Apache官网下载的Hadoop*.tar.gz的包为32的系统,需要重新编译才可以用于64位系统。















 3568
3568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









