







ElasticSearch
概念
全文检索的数据库
使用Docker安装ElasticSearch和KiBana
- 可以将ElasticSearch理解为 MySql, 将KiBana理解为 navicat
- 安装ElasticSearch
docker pull elasticsearch:7.4.2 //安装elasticsearch
docker pull kibana:7.4.2 // 安装kibana
//创建配置文件,将docker中的elasticsearch的文件和主机中的文件挂载起来
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
//创建elasticsearch.yml文件并写入内容http.host: 0.0.0.0
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
//启动elasticsearch容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ //主机和docker直接的对应端口
-e "discovery.type=single-node" \ //先设置为单节点的(不是集群)
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ //设置最大占用的内存资源
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ //挂载文件
-d elasticsearch:7.4.2
chmod -R 777 /mydata/elasticsearch/ //将elasticsearch中的文件权限全开放,这样才能从外面访问
- 通过主机IP或域名,端口号为9200来访问 (注意关闭防火墙或者开放指定的端口号)
- 安装KiBana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://47.97.18.245:9200 -p 5601:5601 -d kibana:7.4.2
- 通过主机IP或域名,端口号为5601来访问 (注意关闭防火墙或者开放指定的端口号)
注:kibana启动的时候比较慢,直接访问可能会出现错误,需要等待一会后访问。 - 运行出现错误 可以使用 docker logs 容器Id或容器名 来查看日志信息
_cat
Get _cat/nodes 查看所有的节点
Get _cat/health 查看es的健康情况
Get _cat/master 查看主节点
Get _cat/indices 查看所有的索引 (这里的索引相当于Mysql的数据库即 show databases)
GET、PUT 、POST和DELETE
-
get
GET 索引名/类型/id 获取指定的索引下的类型下的id对象的数据 -
put
PUT 索引名/类型/id + json格式的参数
其中 索引名 就相当于 Mysql中的数据库、类型相当于 数据库中的某个表、id就是指定的哪个具体的数据id
如果发送的请求中,es中没有该索引、类型、文档(相当于mysql中的属性)等,会自动创建一个新的,如果存在则会进行更UT新操作。 -
Post
post的方式和Put类似,只不过post可以不加指定的Id,不加的时候会自动生产一个新的Id,之后进行创建操作。
POST 索引名/类型/id/_update + json格式的参数 Post的主动更新,直接进行更新操作,且如果这次更新的数据和存储的对比没有变化的话,就不会进行任何操作(seq_no、version等的值也不会改变)
注: 如果使用_update 的话 ,json格式需要加上doc,
例如:{ "doc":{ "name":"xxx", "age": x } } -
delete
DELETE 索引名/类型/id 删除指定的数据
DELETE 索引名 删除指定的索引
_bulk
批量操作 ,例如:
在某个类型下的
POST customer/external/_bulk
{"index":{"_id":"1"}} //第一个数据
{"name":"Test"}
{"index":{"_id":"2"}} //第二个数据
{"name":"Test2"}
所有的(增删改查)
POST /_bulk
{"delete":{"_index":"","_type":"","_id":""}}
{"create":{"_index":"","_type":"","_id":""}}
{"title":""}
{"index":{"_index":"","_type":""}}
{"title":""}
{"update":{"_index":"","_type":"","_id":""}}
{"doc":{"title":""}}
QueryDSL
两种查询方式
-
通过使用REST request URI 发送参数(uri+检索参数)
//发送查找请求,获取所有的数据,且以account_number的值排序,排序方式是升序 GET bank/_search?q=*&sort=account_number:asc -
通过使用REST request body 来发送 (uri+请求体)
//发送查找请求 GET bank/_search { //查找方式是查找所有 "query": { "match_all": { } }, //排序是先按照account_number来排序,再按照balance来排序 "sort":[ { "account_number": "asc" }, { "balance": "desc" } ] } -
QueryDSL的格式
{ "想要干什么" :{ }, "然后干什么":{ } }
match
match 用于查找,可以精确查找和模糊查找,
如,用在一个数值上
//精确的查找到balance的值为16418的记录
GET bank/_search
{
"query": {
"match": {
"balance": 16418
}
}
}
用在一个 字符串上
//会查找到所有的含有 mill 或者 lane 的记录,
//且返回的结果中有一个得分,与 "mill lane" 越接近得分越高,排名就越靠前
GET bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
match_phrase
上面的match会将一个词分成一个个的字来匹配,如 mill lane 会分为 mill 和lane 而
match_phrase 可以使它按照整个词来查询
//查询adress 含有 mill lane 的,不会再查找 只含有 mill 或者 lane 的
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane"
}
}
}
multi_match
多字段查询
//查询出所有的address 或者 city中含有 Movico Mill 或者 Movico 或 Mill 的所有数据。
GET bank/_search
{
"query": {
"multi_match": {
"query": "Movico Mill",
"fields": ["address","city"]
}
}
}
bool
//如下所示,使用bool 在里面通过 must:查询结果必须要有 must_not :查询结果不能有 should:查询结果应该有
//其中如果must和must_not必须满足,而should可以不满足,如果也满足should的话,相对的查询分数会高一些
//该结果的意思是查询的结果中,gender 必须为M,address必须为 mill ,age一定不能为28,如果state为IL 的话得分相对较高
//而filter 是过滤条件,可以将在这个范围内的符合的数据筛选出来,但是,不会计算文档的分数。
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "28"
}
}
],
"should": [
{
"match": {
"state": "IL"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}
term
精确查找一个数值
GET bank/_search
{
"query": {
"term": {
"balance": 32838
}
}
}
//使用match的时候在文档后加上.keyword后缀,就可以精确查找一个数值
GET bank/_search
{
"query": {
"match": {
"address.keyword": " Madison Street"
}
}
}
aggregations
聚合 ,相当于mysql的分组Group By
用法
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"名字自定义": {
"进行的操作": {
"field": "对哪个字段进行操作",
"size": 10 //查询出的记录数 相当于Mysql 的limit
}
}
}
}
aggs 可以有多个同级也可以嵌套使用。如下的嵌套使用:
//将查询的结果按照年龄分组,再将分过组的数据求其平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"balanceAgg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
映射
映射的创建
PUT /索引名
{
"mappings": {
"properties": {
"文档名(相当于Mysql中的字段名)":{"type": "数据类型"},
"文档名(相当于Mysql中的字段名)":{"type": "数据类型"}
}
}
}
例如:
PUT /my_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"email":{"type": "keyword"},
"name":{"type": "text"}
}
}
}
在原有的映射基础上添加
//添加一个"属性"
PUT /my_index/_mapping
{
"properties":{
"employee-id":{
"type":"keyword",
"index":false
}
}
}
数据迁移
需要创建一个新的映射,然后再将老的迁移到新的,如下所示
//先创建一个新的bank,可以根据自己的需求修改类型
PUT /newbank
{
"mappings": {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text"
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
迁移的固定写法
POST _reindex
{
"source": {
"index": "bank", //老映射
"type": "account"
},
"dest": {
"index": "newbank"//新映射
}
}
ik分词器
安装分词器
在检索的时候,通常会分词检索,但是ElasticSearch不支持中文检索(新版的好像支持了,这是7.4.2d的),所以需要引用插件来分词
-
下载地址:根据对应的版本下载
-
将下载的压缩文件放到/mydata/elasticsearch/plugins 目录下 并解压到 ik文件下(这里已经挂载过,会自动同步到docker下)
-
可进入docker容器里查看docker exec -it 容器Id/ 容器名 /bin/bash
-
重启容器
docker restart elasticsearch -
使用
//两种用法的分词结果不同 POST _analyze { "analyzer": "ik_smart", "text": "我是中国人" } POST _analyze { "analyzer": "ik_max_word", "text": "我是中国人" }
安装Nginx
在/mydata下创建nginx文件夹
安装nginx
docker run -p 80:80 --name nginx -d nginx:1.10
将其下的一些配置复制到创好的nginx文件夹下
docker container cp nginx:/etc/nginx .
将复制的文件放到conf文件中

重新创建nginx容器并挂载(80端口已经占用,所以主机使用81)
docker run -p 81:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf/:/etc/nginx \
-d nginx:1.10
挂载完毕后,会在主机的配置文件中生产一些配置文件,如上图剩余的几个
在html中放一个index.html页面,如果可以通过主机IP:端口号访问到说明配置成功。
自定义分词
进入nginx的html目录下,创建一个分词目录,再创建一个分词文件,在里面填上需要的词

进入安装的ik的配置文件夹
/mydata/elasticsearch/plugins/ik/config
编辑该文件

将注释去掉并改为刚刚创建的fenci文件的地址(能通过浏览器访问到的地址)
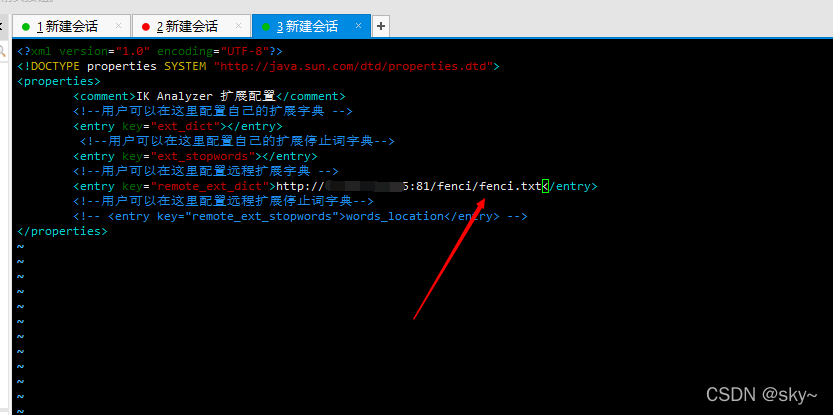
重启容器
docker restart elasticsearch
再进行测试即可
分词自定义前
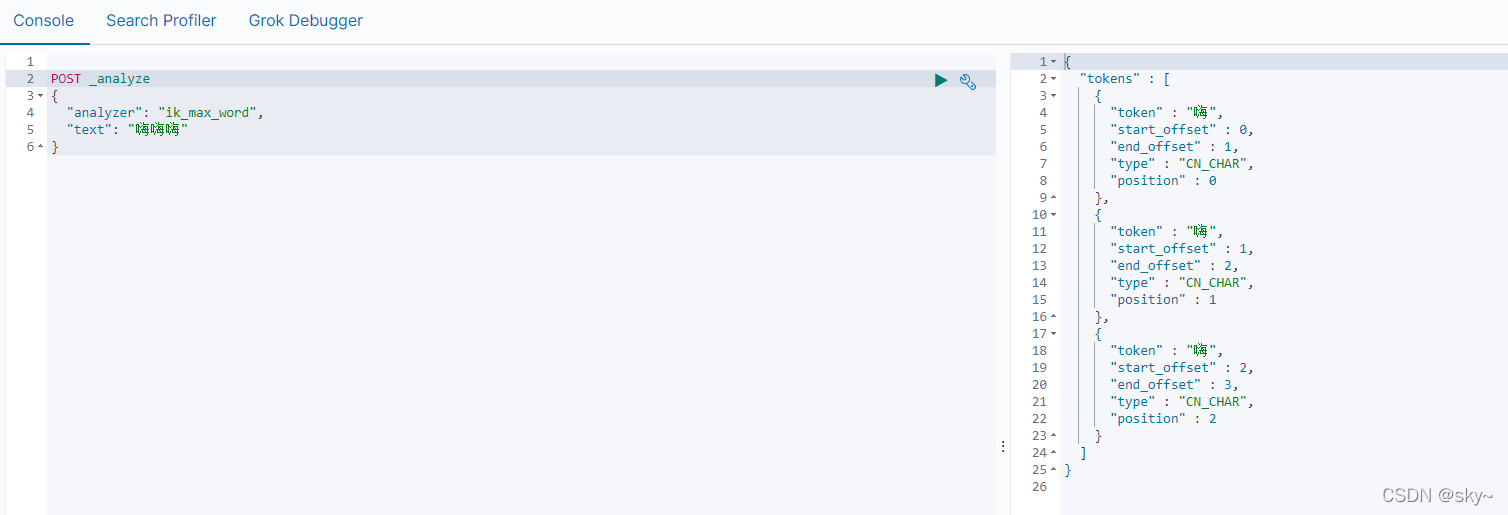
分词自定义后















 3376
3376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









