



前言
今天给大家分享最新开源的一款ASR模型Moonshine, 据官方介绍,比whisper同等级规模的参数版本识别速度更快,准确率更高! 本文将准备多个案例进行实测ASR效果,仅供参考。下面进入今天的主题~
本文目录
-
moonshine模型介绍
-
moonshine性能介绍
-
实战篇:下载moonshine模型权重&&步骤代码进行语音识别
-
使用 onnxruntime 包来运行 Moonshine 模型,不依赖torch
-
使用huggingface框架加载moonshine模型进行asr语音识别
-
效果篇: moonshine-base模型 VS whisper-base模型ASR效果对比
-
案例1: 短文本语音识别-2种模型效果展示
-
案例2: TED演讲视频-2种模型效果展示
moonshine模型介绍
Moonshine 是由 Useful Sensors公司推出开源的语音到文本(speech-to-text, STT)转换模型,旨在为资源受限设备提供快速而准确的自动语音识别(ASR)服务。Moonshine 基于先进的编码器-解码器架构,采用了Transformer模型。其编码器部分负责处理输入的语音信号,而解码器部分则生成文本输出。目前在gitihub社区点赞量达2k! Moonshine模型具有以下特点:
Moonshine模型具有以下特点:
-
开源tiny版本,参数量:27 M, 只支持英文语言; 开源base版本,参数量:61 M, 只支持英文语言;
-
更快的处理速度,Moonshine 的处理速度比 Whisper 快 1.7 倍。对于 10 秒的短音频片段,处理速度可达 Whisper 的五倍。
-
基于20w小时的语音样本训练而来。
moonshine性能介绍
Moonshine 在多个维度上超越了现有的语音识别解决方案,特别是在处理速度和准确度方面。据官方报告,Moonshine 的处理速度「比 OpenAI 的 Whisper 快五倍」,并且在词错误率方面也表现得更好,如下图所示。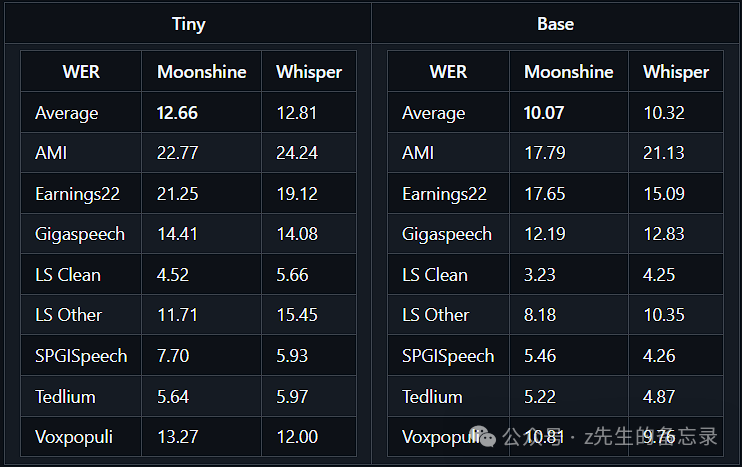 这种显著的优势使得 Moonshine 成为资源受限环境下语音识别的理想选择。
这种显著的优势使得 Moonshine 成为资源受限环境下语音识别的理想选择。
下面我将给大家实操部署moonshine-base模型和whisper-base模型,准备几个案例来实际展示具体的语音识别效果,仅供参考~
实战篇:下载moonshine模型权重&&步骤代码进行语音识别
使用 onnxruntime 包来运行 Moonshine 模型,不依赖torch
from IPython.display import clear_output !pip install moonshine !git clone https://github.com/usefulsensors/moonshine.git !pip install silero_vad onnxruntime sounddevice tokenizers einops !pip install onnxruntime-gpu
下载模型权重
!huggingface-cli download UsefulSensors/moonshine --local-dir . --local-dir-use-symlinks False clear_output()
加载moonshine模型onnx格式权重进行推理
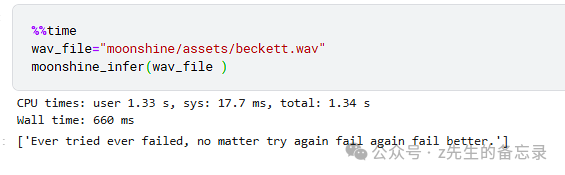
model = MoonshineOnnxModel(models_dir= "./onnx/base") def moonshine_infer(wav_file): with wave.open(wav_file) as f: params = f.getparams() assert ( params.nchannels == 1 and params.framerate == 16_000 and params.sampwidth == 2 ), f"wave file should have 1 channel, 16KHz, and int16" audio = f.readframes(params.nframes) audio = np.frombuffer(audio, np.int16) / 32768.0 audio = audio.astype(np.float32)[None, ...] tokens = model.generate(audio) tokenizer = tokenizers.Tokenizer.from_file("./moonshine/assets/tokenizer.json") text = tokenizer.decode_batch(tokens) return text
进行模型推理
使用huggingface框架加载moonshine模型进行asr语音识别
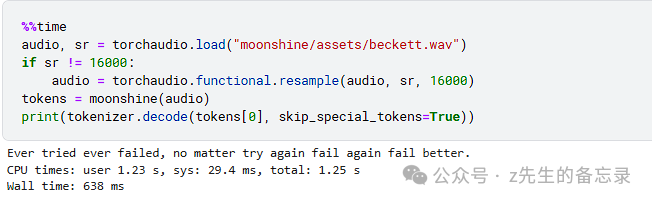
%%time %cd /kaggle/working/moonshine from IPython.display import clear_output from transformers import AutoModelForSpeechSeq2Seq, AutoConfig, PreTrainedTokenizerFast import torchaudio import torch import sys device = "cuda:0" if torch.cuda.is_available() else "cpu" # 'usefulsensors/moonshine-base' for the base model moonshine = AutoModelForSpeechSeq2Seq.from_pretrained('usefulsensors/moonshine-base', trust_remote_code=True) tokenizer = PreTrainedTokenizerFast.from_pretrained('usefulsensors/moonshine-base') audio, sr = torchaudio.load("moonshine/assets/beckett.wav") if sr != 16000: audio = torchaudio.functional.resample(audio, sr, 16000) tokens = moonshine(audio) print(tokenizer.decode(tokens[0], skip_special_tokens=True))
下面我将利用moonshine-base版本和whisper-base版本的模型进行语音识别效果对比,看具体实际案例情况下,模型的具体表现情况,随便找的素材,经供参考~
效果篇: moonshine-base模型 VS whisper-base模型ASR效果对比
案例1: 短文本语音识别-2种模型效果展示
参考音频1效果展示:
moonshine-base的ASR效果展示
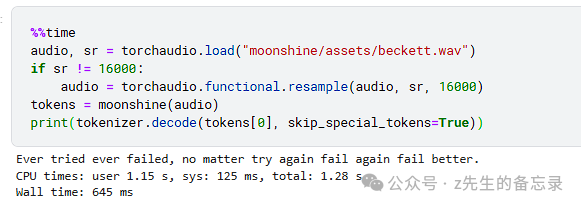 识别结果: Ever tried ever failed, no matter try again fail again fail better.
识别结果: Ever tried ever failed, no matter try again fail again fail better.
whisper-base的ASR效果展示
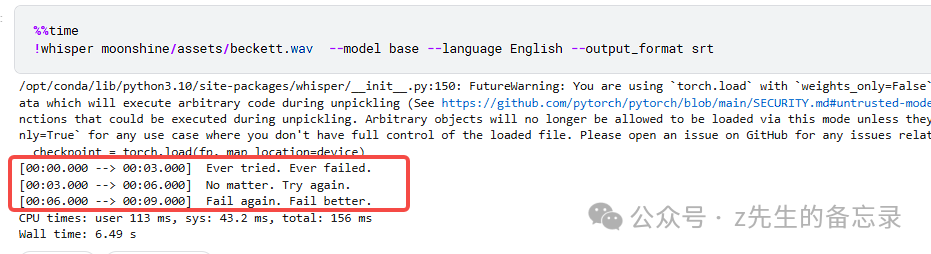
2种模型识别结果都非常正确,而moonshine-base速度很快,只用来不到0.6秒,即便算上模型加载的时间,也才1.2秒。
案例2: TED演讲视频-2种模型效果展示
随便找一份英语的演讲视频进行测试,我这个找到https://www.youtube.com/playlist?list=PLosaC3gb0kGDUYoRq-VioWOZ5Ke0UIoSE,截取前2分钟的视频转化为音频效果如下:
moonshine-base的ASR效果展示
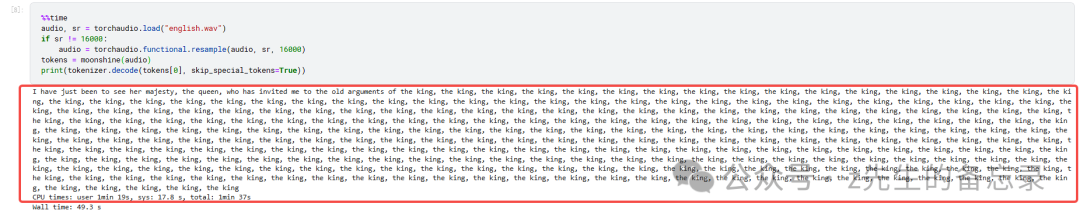 单次不支持长语音识别,采用分段识别,代码如下:
单次不支持长语音识别,采用分段识别,代码如下:
import librosa import os import moonshine import soundfile as sf # !mkdir temp def benchmark(audio_pth): # 读取音频文件 audio, sr = torchaudio.load("english.wav") if sr != 16000: audio = torchaudio.functional.resample(audio, sr, 16000) # 分割音频文件成小段 chunk_duration = 10 # 每个片段的长度(秒) chunk_size = int(chunk_duration * sr) chunks = [audio[0:1,i:i + chunk_size] for i in range(0, audio.shape[1], chunk_size)] # 转录音频 transcription = "" for i, chunk in enumerate(chunks): print(f"正在转录... ({i + 1}/{len(chunks)})") tokens = moonshine_model(chunk) chunk_transcription = tokenizer.decode(tokens[0], skip_special_tokens=True) if isinstance(chunk_transcription, list): chunk_transcription = ' '.join(chunk_transcription) transcription += chunk_transcription return transcription
最后识别的结果如下:
whisper-base的ASR效果展示
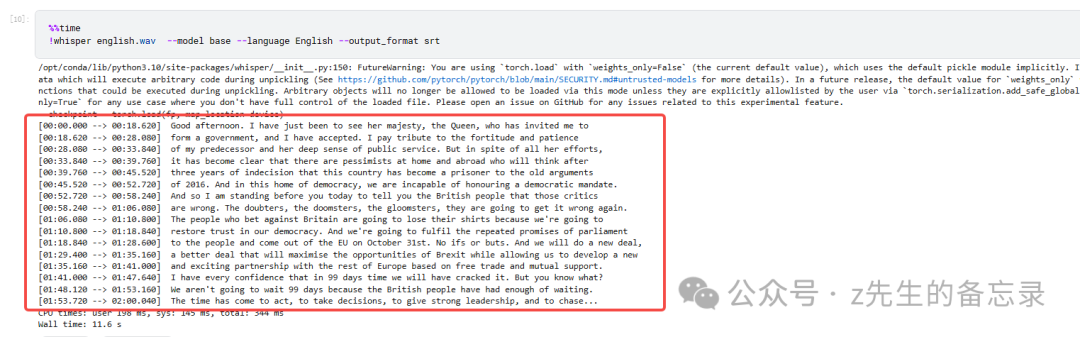
我感觉2个模型识别的效果相差不大,moonshine速度是比较快的,但是目前moonshine只支持英文。大家可以对比录音听听,看看谁识别的更准~
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









