






前言
Hi大家好,我叫延捷,是一名计算机视觉算法工程师,也是叉烧的老朋友了。我们计划发布一系列关于多模态大模型的文章,帮助大家快速、精准地了解多模态大模型的前世今生,并且深入各个多模态大模型领域优秀的工作,希望能给大家一个脉络性的盘点,一起学习,共同进步。
Introduction
上一期我们介绍了Qwen-VL和其最近的延伸Qwen2-VL。本期则会详细介绍一下另外一个在多模态大模型领域相当火热Gemini系列,本文会以Gemini为主干,分享Google在多模态大模型领域的一些经典工作,并且也会介绍笔者非常喜欢的一个Gemini分支作品Mini-Gemini(虽然跟Google的Gemini关系并不算大,但它真的很值得)。同样地我并不会过多列举一些不必要的论文细节和指标,而是会着重讲述:
“心路历程”:一个系列工作逐步发展的路径,作者是如何根据当前工作的缺点一步步优化的,并且会总结出每篇工作的highlight,在精而不在多;
“数据细节”:各个工作中对数据处理的细节,包括但不限于数据的收集,采样时的分布,如何清洗/重建noisy数据,如何进行数据预处理,视频抽样的方案等,这些对算法工程师来说是同样重要的一环;
“前人肩膀”:各个工作中隐藏着一些非常值得盘的消融实验,站在前人的肩膀上,使用这些已有的消融实验结论,不仅能帮助我们更好地理解论文,更能在实际工作中少做些不必要的实验and少走弯路。
同样相信大家会从本文中收获不少,同时祝所有CS的陋室的读者朋友们中秋/国庆双节快乐,阖家幸福。
Gemini 1.0
《Gemini: A Family of Highly Capable Multimodal Models》(2023)
Gemini 1.0算是一个技术报告,并没有提出很多明确的细节,但是作为Gemini系列的开山之作,还是有许多有亮点的地方,下面我们就着重从多模态的角度介绍一下Gemini 1.0这个工作。
Gemini 1.0的核心是提出了“原生多模态”的思想,即把全部模态(文本、图像、视频、音频)全部Tokenizer之后,直接拼接成Multimodel Token Sequence输入到Transformer-Decoder base的模型中进行自回归的训练;并不像BLIP、LLaVA、QwenVL、GPT一样使用不同模态各自的编码器tokenizer+Projector再输入已有LLM后再SFT的做法。
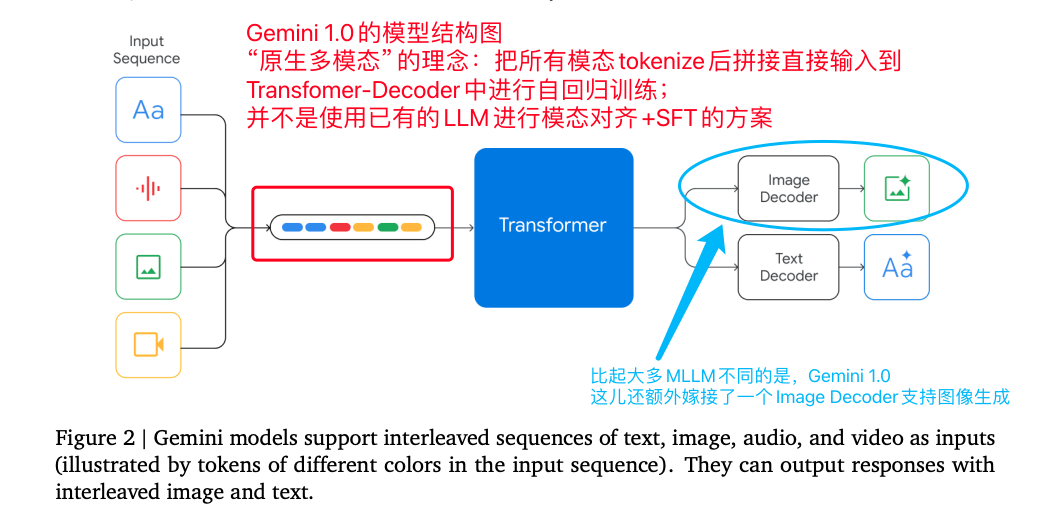
Gemini 1.0的模型架构图,体现了“原生多模态”的理念
下面我们再从【模型架构】和【数据处理】这两个方面,着重详细介绍下Gemini 1.0技术报告中透露出来的细节
模型架构:
Gemini 1.0使用了纯粹的Transformer-Decoder结构,并没有使用T5中用到的Encoder-Decoder架构;Attention方面,把Multi Head Attention替换成了Multi Query Attention(正常的MHA的不同头之间,QKV都是独立的,但是MQA是让不同头之间共享KV,只有Q是独立的,这样能在推理时生成KV时仅需推理一次即可)。
关于编码器,文本部分的Tokenizer跟常规LLM类似;视觉部分的Tokenizer参考了CoCa、Flamingo和PaLI的工作,由于这三个多模态模型的工作也都是Google出品,跟Gemini系列算是一脉相承,笔者这里就借此分别简单介绍一下Google的这三个多模态模型工作。
CoCa
《CoCa: Contrastive Captioners are Image-Text Foundation Models》(2022)
CoCa算是2022年比较早一点的工作,算是延续了ALBEF的思路的工作,核心是使用图像编码器+文本编码器分别抽取视觉和文本特征,再用多模态编码器来融合信息。其中CoCa使用的图像编码器和多模态编码器都是Decoder-Only的结构
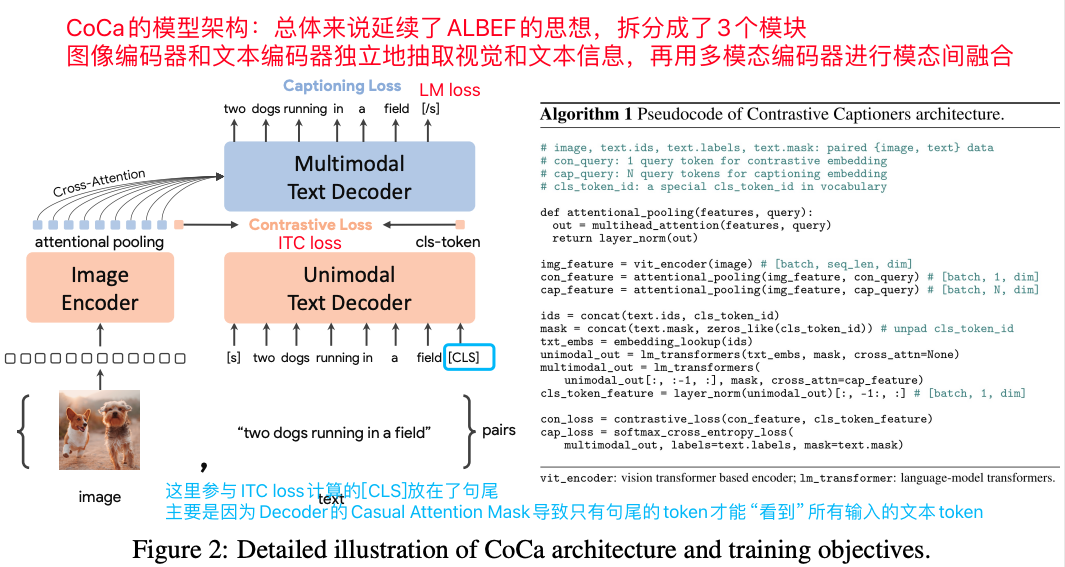
CoCa的模型架构图,图像编码器+图像编码器分别抽取视觉和文本特征,再用多模态编码器来融合信息
Flamingo
《Flamingo: a Visual Language Modelfor Few-Shot Learning》(2022)
经典的视觉编码器+Projector+LLM的架构,但由于是2022年的工作,所设计的Projector也是较为复杂,分为了Perceiver Resampler+GATED XATTN-DENSE,具体为:
A. 首先把图像过一个cross-attention层(文中称之为Perceiver Resampler),这里的cross-attention的Q为64个learnable queries,KV为经过视觉编码器的图像特征和learnable queries的拼接,Flamingo这么设计是希望这64个learnable queries既能从视觉编码中抽象出信息,也能有self-attention的功效,其他都跟常规的cross-attention层没有什么本质区别;(值得注意的是,最近相当火热的miniCPM-V模型也使用Perceiver Resampler作为Resample模块,笔者后续在介绍miniCPM系列模型时会详细拆解一下)
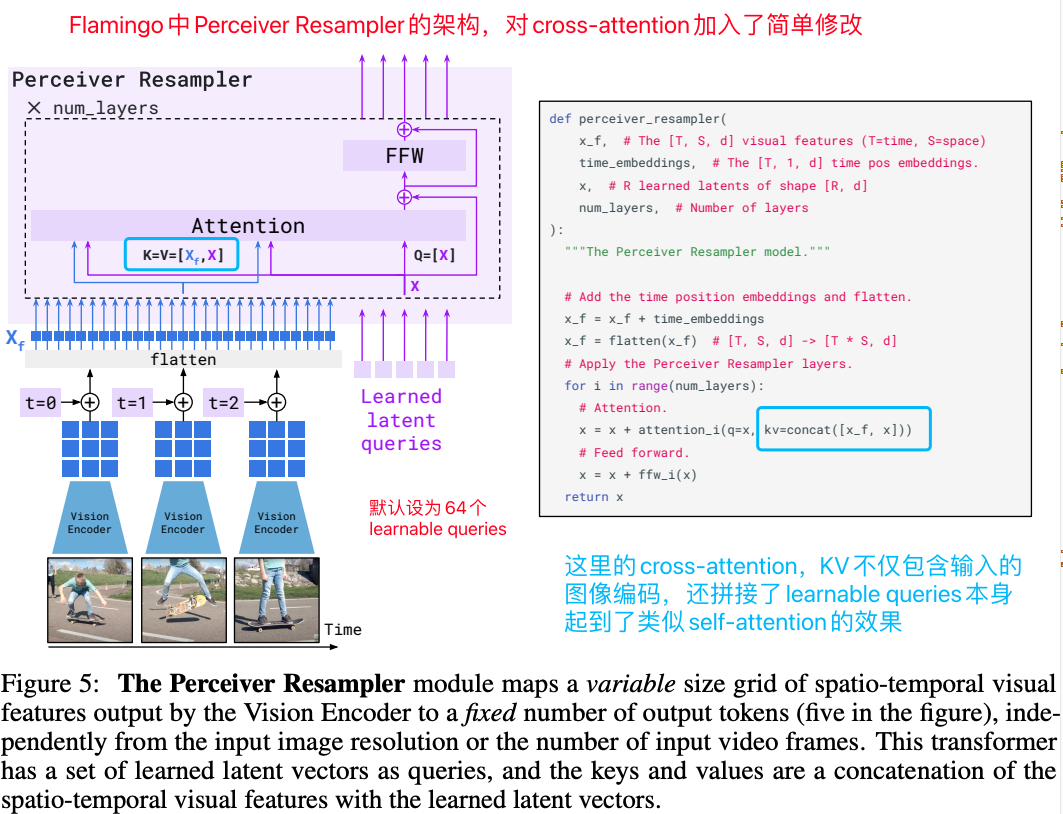
Flamingo中Perceiver Resampler的架构,使用cross-attention抽象出需要的视觉特征
B. 其次是图文交互对齐层,Flamingo中提出了GATED XATTN-DENSE,把Perceiver Resampler中得到的经过固定长度的视觉特征和文本特征进行融合,在基础的cross-attention基础上,引入了两个可学习的参数,并且使用tanh函数来实现门控的功能;
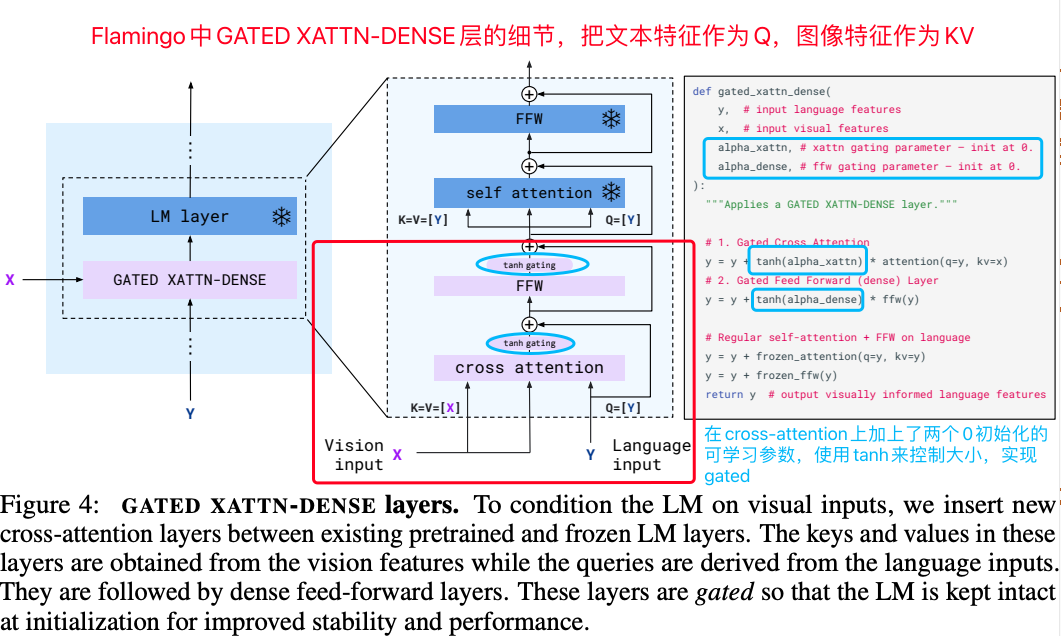
Flamingo中GATED XATTN-DENSE层的架构,使用cross-attention把视觉特征和文本特征进行交互对齐,并且引入了门控的方案
总结来看Flamingo整体模型结构,在当时2022年的角度来看,跟现在的一些经典工作可以说是一个思想,这样的架构有3个非常重要的优点:
i. 能够无缝接入强大的视觉预训练模型和纯语言大模型;
ii. 能够处理任意交错的视觉和文本数据序列,并且使用LM损失给模型带来了强大的文本生成能力;
iii. 无缝地将图像或视频作为输入,并不需要做太多的额外预处理工作;
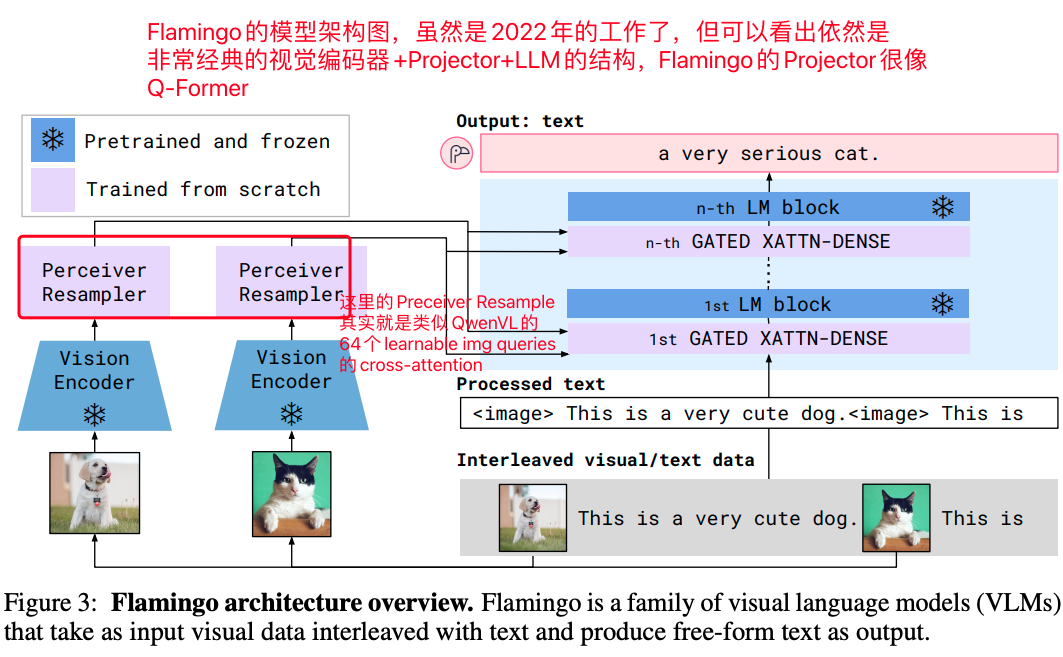
Flamingo的模型架构图,依然是非常经典的多模态模型架构
PaLI
《PaLI: A Jointly-Scaled Multilingual Language-Image Model》(2023)
跟大多数的多模态大模型采用Decoder-Only架构不同,PaLI使用了Encoder-Decoder结构,把img-text projector和llm合并在了一个Encoder-Decoder模型中,具体使用了mT5模型来实现图文对齐+文本解码的能力。
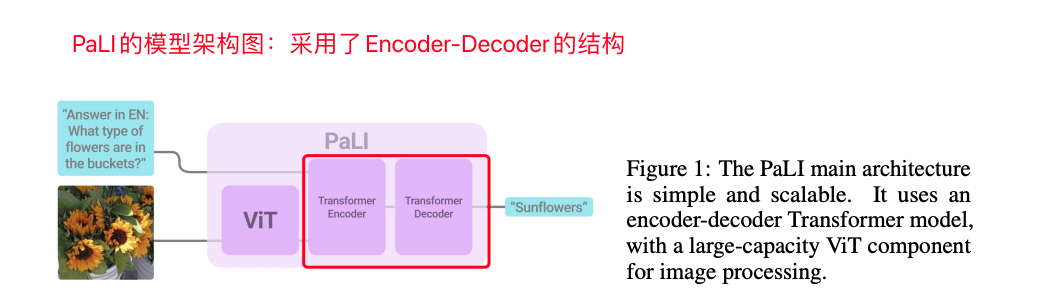
PaLI的模型架构图,使用了Encoder-Decoder结构
继续说回Gemini 1.0,文本方面,使用了在大型语料集上训练得到的Sentence Piece Tokenizer做编码;视频方面,Gemini 1.0提到使用了一个大型的context window把一系列视频帧编码,这里说的比较简单,这里我们猜测有两种可能做法:一是标准地把视频均匀抽帧后用图像编码器tokenize,再拼接成一串tokens,二是用一个类似滑动窗口,每次一个窗口包含多张图像,再把窗口内的窗口的视频帧拼接成一张大图,再用图像编码器做tokenize,再把各个窗口的结果拼接成一串tokens;音频方面,使用的是16kHz的USM(Universal Speech Model)模型进行编码,笔者对音频涉猎有限,这里就不展开介绍了。
Gemini 1.0在模型架构的另一个创新之处在于,在模型最后还接入了一个Image Decoder,给模型提供了图像生成的能力,技术报告中并没有详细介绍这里的图像解码器,我们暂且认为这里就是一个简单的类VAE模型的decoder。
总的来说Gemini 1.0把手头上的文本、图像、音频、视频统计经过上述方案编码后,一并放在一起从头开始训练模型,并没有采用分阶段的操作,体现了技术报告中的“原生多模态”。
数据处理:
由于Gemini 1.0旨在实现原生多模态的目标,所以基本把手头上所有的网页文档、书籍、代码、图像、音频、视频全部一并用上了,在数据处理这块也算比较常规,使用了:
启发式的规则过滤,诸如正则表达式等;
使用了一个数据质量分类器模型,用模型来过滤掉那些质量低的数据;
移除了有害内容,应该是提出了包含了个人信息的数据、有歧视性的数据等;
删除了评估集包含的内容,应该使用了类似CLIP的操作过滤了跟评估集相似度高的数据;
关于数据的抽样权重以及batch数据混合比例,Gemini 1.0提到是在size较小的模型上的笑容满面实验中得到的。根据笔者之前的文章可以看出,数据的抽样权重以及batch数据混合策略,这俩似乎没啥比较显示的方法论,只能通过实验来得到。以笔者的经验来说,提高稍许数量较小数据集的抽样概率,以及尽量不要在batch内只包含单模态的数据,都是可以更优先选择的方案,但是最后的方案肯定以消融实验为主。
Gemini 1.5
《Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context》(2024)
https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
Gemini 1.5的技术报告长达154页,但是关键技术细节一点没透露,仅仅指出Gemini 1.5 Pro 是基于 Transformer 的稀疏混合专家(SMoE)模型,并且指出Gemini 1.5 Pro已经能够支持处理1000万token+的数据输入,并且其中多模态的内容也并不多,有兴趣的朋友可以自行看一下这略有冗长的技术报告。
Mini-Gemini
《Mini-Gemini: Mining the Potential of Multi-modalityVision Language Models》(2024)
Gemini系列的第三篇介绍的是Mini-Gemini这个工作,乍一看名字似乎是迷你化的Gemini的模型,其实这里的Mini并不是“小型、迷你”的意思,而是Mining(挖掘)的缩写。并且本文跟Gemini其实关系也没有那么直接,更多是提出了一个双塔视觉编码器的结构,所需要的LLM也不一定仅限于Gemini。但既然这个工作Mini-Gemini了,笔者就放在这里一并跟大家介绍,虽然关系不大,但笔者依然认为这是一个简练又优秀的工作,里面有相当多的亮点,我们会在下面给大家详细介绍这篇工作的一些细节。
模型架构方面,Mini-Gemini跟LLaVA的结构相当类似,依然是视觉编码器+Projector+LLM的模型结构,但比起LLaVA系列,有几个相当有亮点的改造
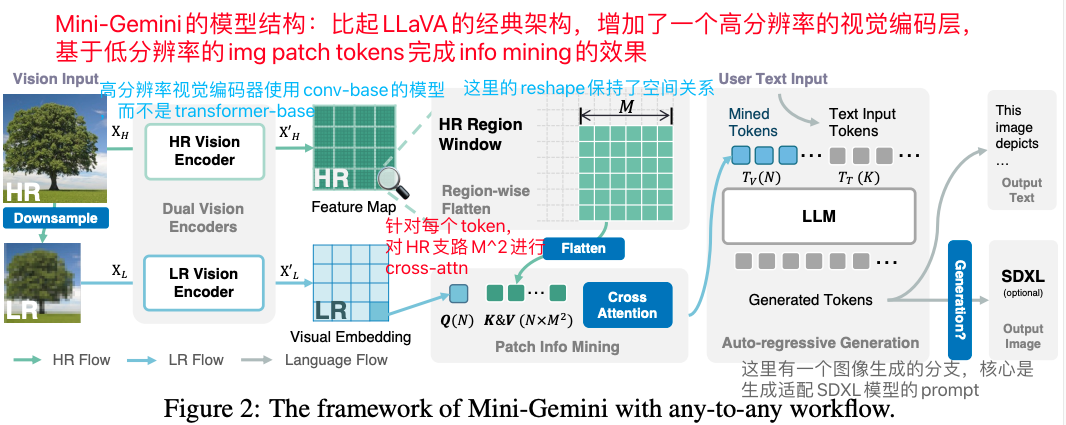
Mini-Gemini的模型架构图,亮点是新增了双塔视觉编码器+Patch Info Mining,并且加入了SDXL prompt分支
新增了双塔视觉编码器+Patch Info Mining的结构,基于低分辨率图像对高分辨率图像编码使用cross-attention进行信息挖掘,在不改变最后tokens数量的前提下,能充分挖掘高分辨率的图像信息;
新增了一个图像生成分支,但并不像Gemini那样原生模型实现图像生成,而是通过生成适配SDXL的文本prompt来实现的(相当简单粗暴);
下面我们会在highlights详细进行拆解。
Highlights:
双塔视觉编码器+Patch Info Mining:在Mini-Gemini的模型结构方面,这个应该是最大的亮点。为了提高模型对小物体的理解和感知能力,高分辨率视觉 token 重要性不言而喻,作者提出了在不增加视觉tokens数目的情况下使用额外的视觉编码器进行高分辨率细化的方案,实现了高分辨率视觉信息的挖掘。
首先是双塔视觉编码器,在低分辨率(LR)分支使用常规的CLIP-pretrained ViT,在高分辨率(HR)分支则使用conv-base的ConvNeXt模型进行特征提取,在这里输入HR分支的图像尺寸要求大于等于LR分支的输入图像,并且ConvNeXt会进行2次的下采样,最终特征图的尺寸为输入尺寸的1/4;由于ViT的patch size一般固定为14,所以HR分支得到特征图的size是大于LR分支的特征图的:
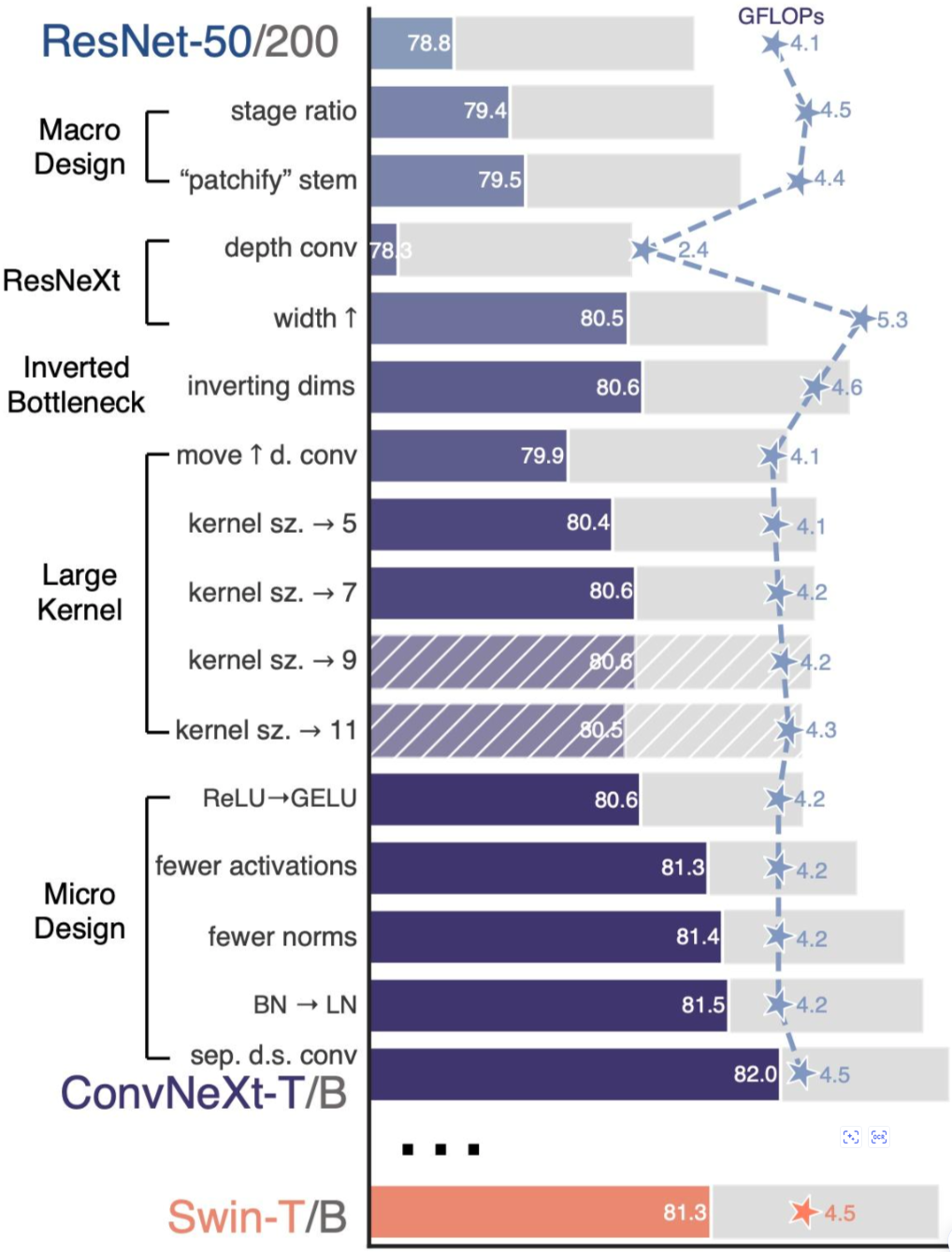
ConvNeXt的一些模型结构细节,集卷积时代的炼丹大全之作
其次是Patch Info Mining:要实现低分辨率img tokens对高分辨率视觉信息的抽取与挖掘,并且要保持img tokens的数量固定,我们很自然地想到使用cross-attention(并且在Qwen-VL和BLIP等工作中也确实是使用cross-attention来实现的),但是Mini-Gemini并不是用无脑的方式直接基于LR的tokens对HR的特征图结果做cross-attention,而是先对HR的特征图做了一次保留位置信息的reshape,再根据位置,让每个img token仅对对应位置的HR特征图做cross-attention,这样不仅能大大减小的计算量,还能让每个token聚焦对应patch细节,实现了Patch粒度的mining,个人觉得作者的设计非常精妙并且很合理。
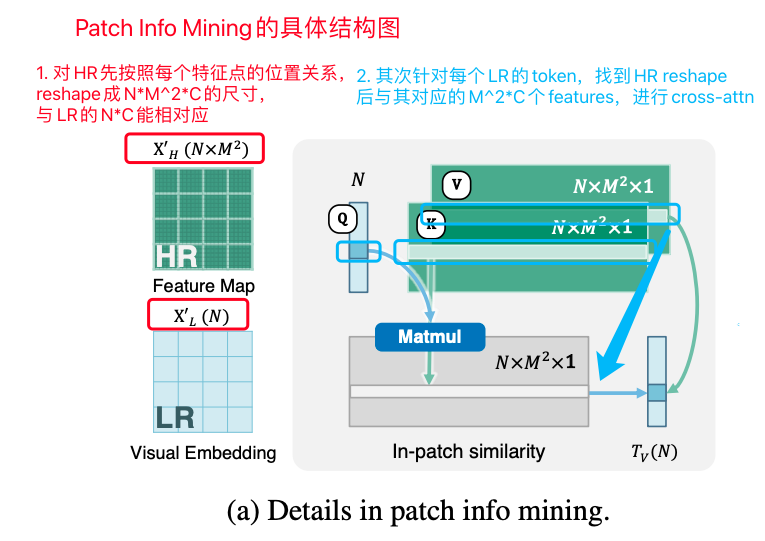
Mini-Gemini中Patch Info Mining的细节示意图
# HR_feat: (N', N', C) # LR_feat: (N, C) N, C = LR_feat.shape HR_feat_reshpae = HR_feat.reshape((N, -1, C)) # HR_feat_reshape: (N, M^2, C) _, M2, _ = HR_feat_reshpae.shpae Q = nn.linear(C, C)(LR_feat) # (N, C) K = nn.linear(C, C)(HR_feat_reshpae) # (N, M2, C) V = nn.linear(C, C)(HR_feat_reshpae) # (N, M2, C) # cross-attention scores = Q.unsqueeze(1) @ K.transpose(-1, -2) # (N, 1, M2) attn_w = torch.softmax(scores, dim=-1) # (N, 1, M2) attn_result = attn_w @ V # (N, 1, C) img_tokens = attn_result.squeeze(1) # (N, C)最后是token extension:这里其实跟LLaVA中AnyRes十分的类似,就是在LR分支,把图片做切分,并且把得到的img tokens拼接到一起,笔者在先前的文章中已经介绍过很多次类似的方案了,现在基本成为了各个MLLM标准配件了,现在效果最好的miniCPM还是InternVL系列都也用到了同样的技术,后续笔者也会给大家详细介绍。
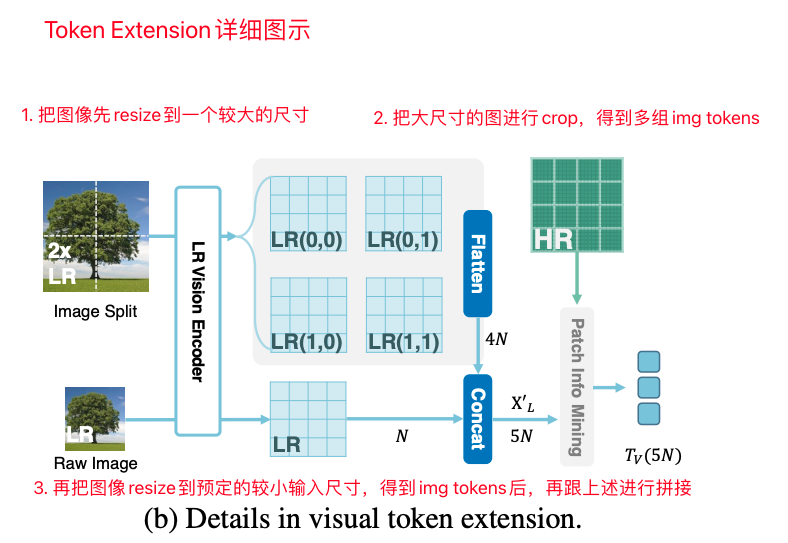
Mini-Gemini中token extension的细节示意图:跟AnyRes技术十分类似,现在已经成为了MLLM中的标配组件
数据处理方面:数据处理永远是最考验算法工程能力,同时又最能提点的方面,笔者也不止一次地强调了在大模型时代,对数据分析、处理、清洗、重生成是对于一个算法同学必不可少的“硬功”。Mini-Gemini在处理方面做了两个方面的改进,一是使用了更丰富+高质量的数据,这个基本上也是每个MLLM工作的标配
a. 预训练阶段数据集构成
| 类型 | CC3M(LLaVA-filtered) | ALLaVA (GPT4V responded captions) |
|---|---|---|
| 预训练阶段数据共1253K(1.2M) | 558K | 695K |
b. 指令微调阶段数据集构成
| 类型 | From Llava(not include 21K TextCaps) | QA pairs from ShareGPT4V | LAION-GPT-4V | ALLaVA(GPT4V responded instruction pairs) | LIMA and OpenAssistant2(text-only multi-turn conversations) | OCR-related dataset(DocVQA、ChartQA、DVQA、AI2D) |
|---|---|---|---|---|---|---|
| 指令微调阶段数据共1487K(1.5M) | 643K | 100K | 10K | 700K | 6K | 28K |
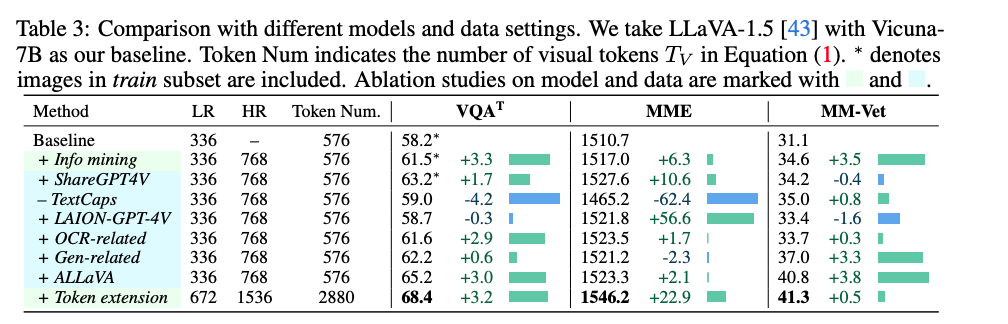
Mini-Gemini做了详细的消融实验,证实了各个数据集的添加对最终效果的影响
c. 前面说到,为了让Mini-Gemini也拥有图像生成的能力,作者这里是通过生成适配SDXL的文本prompt来实现的,具体来说,在instruction prompt中,新增了标识符,表示让LLM开始生成适合SDXL的文本,同时让LLM返回改文本的收尾加入和;为此Mini-Gemini定义了两种类型的Gen-Prompt,一种是简单的问答形式,另一种是较为复杂的对话形式。下图中我们详细介绍了生成SDXL-Prompt的形式和对应生成该Instruction的方法。

Mini-Gemini生成SDXL-prompt的示意图

使用GPT4生成简单的问答形式Gen-Instruction的Prompt

使用GPT4生成复杂的对话问答形式Gen-Instruction的Prompt
总的来说,笔者认为Mini-Gemini是一个相当优秀、扎实的工作,继承了LLaVA的灵魂,加入了合适的改进工作,达到了Gemini的效果,笔者甚至认为Mini-Gemini才是这一期的精华。
Reference
https://arxiv.org/pdf/2312.11805
https://arxiv.org/pdf/2403.18814
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









