






背景:本人Python新手,方法很低级,也不背后原理和机制,整好有个dbf文件需要读取,尝试了很多方法模块(dbfread,dbfpy)等模块,出现了UnicodeDecodeError,一直没有解决方法。最后用dbf模块打开了。
方法:
我看了一些帖子,最后瞎整了一番终于读取了,有几个方法总结一下,我觉得可以分享,若说明不准确或有误,还请各位看到这篇破文的大侠多多指导,不胜感激。
(1)先说dbfread模块
最开始我是这样干的
from dbfread import DBF
table = DBF('21-047.dbf',load=True)
list1=table.fields
list2=table.records
print(type(list1),len(list1))
print(type(list2),len(list2))
提示错误:UnicodeDecodeError: 'ascii' codec can't decode byte 0xd5 in position 346: ordinal not in range(128)
我把encoding改成如:
table = DBF('21-047.dbf',load=True,encoding='gbk')
提示错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xcd in position 265: incomplete multibyte sequence
后来改为utf8也不行......
最后我看了下dbfread.dbf
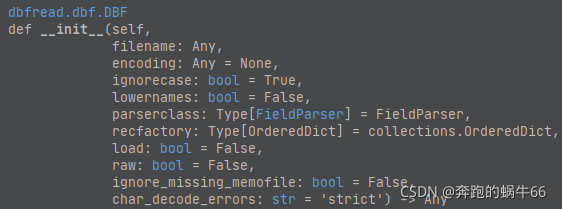
直接忽略掉了,
table = DBF('21-047.dbf',load=True,char_decode_errors='ignore')
print("*" * 40)
可以进去了
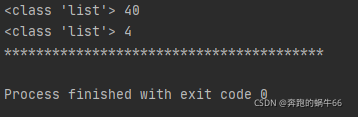
读了一下数据
for i, record in enumerate(table):
for name, value in record.items():
print('records[{}][{!r}] == {!r}'.format(i, name, value))
感觉数据不对....,可能还是decode不对。。。。于是放弃了,没解决.....
(2)dbfpy这个模块,感觉没有摸到门
from dbfpy import dbf
直接报错了,
可能是Python2.x的原因吧,直接放弃了,
(3)dbf模块
这个模块也是网上搜索的,链接:python的dbf操作_jhui123456的博客-CSDN博客
import dbf
table1 = dbf.Table('21-047.dbf')
print(table1)
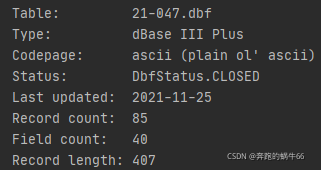
感觉有了曙光
table1 = dbf.Table('21-047.dbf')
print(table1)
table1.open()
for record in table1:
print(record)
table1.close()
后来要读取里面的数据时,发现仍然报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd5 in position 0: ordinal not in range(128)
看来还是没有解决。
后来我网上又学习了一番Python3使用dbf模块读写dbf文件_u010151317的博客-CSDN博客,codepage='cp936'
table1 = dbf.Table('21-047.dbf', codepage='cp936')
终于成功了,后来又查了下什么是codepage,ASCII与Unicode, codepage, utf-8_weixin_33688840的博客-CSDN博客
什么是codepage?codepage就是各国的文字编码和Unicode之间的映射表。
比如简体中文和Unicode的映射表就是CP936,点这里查看官方的映射表。
以下是几个常用的codepage,相应的修改上面的地址的数字即可。
codepage=936 简体中文GBK
codepage=950 繁体中文BIG5
codepage=437 美国/加拿大英语
codepage=932 日文
codepage=949 韩文
codepage=866 俄文
从936中随意取一行,例如:
0x9993 0x6ABD #CJK UNIFIED IDEOGRAPH
前面的编码是GBK的编码,后面的是Unicode。
通过查这张表,就能简单的实现GBK和Unicode之间的转换。
但是我仍然不明白为什么上面的![]() ,不是cp936,不明白为什么。。。。
,不是cp936,不明白为什么。。。。
我自己用的简单代码,用于提取dbf的数据
import dbf
import xlwt
table1 = dbf.Table('21-047.dbf', codepage='cp936')
table1.open() # 读写方式打开tb
updated = list(table1)
table1.close()
print(len(table1),len(table1[0]))
print(table1[0])
titles = dbf.get_fields('21-047.dbf') # 将表头以列表形式打印出来
# titles.insert(0, '序号')
print(titles,len(titles))
#写了个函数,把dbf转为了excel
def write_excel(title, table):
xls = xlwt.Workbook(encoding='utf8')
sheet1 = xls.add_sheet('data')
for r in range(len(table)):
for c in range(len(title)):
if r == 0:
sheet1.write(r, c, title[c].strip())
else:
sheet1.write(r, c, table[r - 1][c].strip().replace(' ','.'))
# pass
xls.save('dbf_excel.xls')
write_excel(titles, table1)

















 6834
6834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









