







目录
三、蓝耘元生代:把 ComfyUI 和服务器虚拟化串起来的 “魔法平台”
一、开头碎碎念
哈喽大家好!我是一名计算机科学与技术专业的学生,最近在研究蓝耘元生代平台的时候,发现了一个很有意思的结合点 —— 平台里的 ComfyUI 工作流创建和服务器虚拟化技术之间居然藏着不少学问。作为一个每天和代码、服务器打交道的学生党,我觉得这俩技术的联动就像打游戏时发现了隐藏关卡,既好奇又想一探究竟。今天就用大白话和大家唠唠这两者之间的联系,顺便分享点自己折腾过的代码和踩过的坑,纯纯个人学习笔记向,大佬轻喷~
二、先搞懂俩主角:ComfyUI 和服务器虚拟化
(一)ComfyUI 工作流:可视化的 “流程积木”
第一次接触 ComfyUI 的时候,我感觉它就像一个编程界的 “乐高积木”。不像平时写代码要一行行敲逻辑,在 ComfyUI 里,你可以通过拖拖拽拽各种节点,像搭积木一样把工作流程拼出来。比如说,我想做一个图片批量处理的任务,只需要找 “图片输入节点”“缩放节点”“滤镜节点”“保存节点”,然后用线连起来,设置好每个节点的参数,这个工作流就能跑起来了,简直是懒人福音!
举个简单的例子,假设我要给一堆图片加上水印,在 ComfyUI 里大概长这样:
- 拖一个 “文件读取节点”,指定图片文件夹路径;
- 连一个 “图片水印节点”,设置水印文字、位置、字体大小;
- 再接一个 “文件保存节点”,指定输出文件夹。
这样一来,整个流程一目了然,就算是刚学编程的小白也能轻松看懂逻辑。对于我们学生来说,做课程设计或者小项目的时候,用 ComfyUI 搭建工作流能省不少写代码的时间,特别是涉及到复杂流程的时候,可视化的优势就更明显了。
(二)服务器虚拟化:给服务器 “开分身”
再来说说服务器虚拟化,这玩意儿听起来挺高大上的,其实说白了就是给服务器 “开分身”。比如说,一台物理服务器性能很强,但只跑一个应用程序的话,资源就浪费了。这时候,我们可以通过虚拟化技术,在这台物理服务器上虚拟出多个 “虚拟机”,每个虚拟机都能独立运行操作系统和应用程序,就像好几台独立的服务器一样。
我第一次接触服务器虚拟化是在做云计算课程作业的时候。当时老师让我们用 VMware Workstation 创建虚拟机,我在自己的笔记本上虚拟出了一个 Linux 系统,用来跑一些服务器端的代码。那时候我就在想,要是学校的服务器也能这样虚拟化,那我们做实验的时候就不用抢服务器资源了,每个人都能有自己的 “小服务器” 分身,多爽!
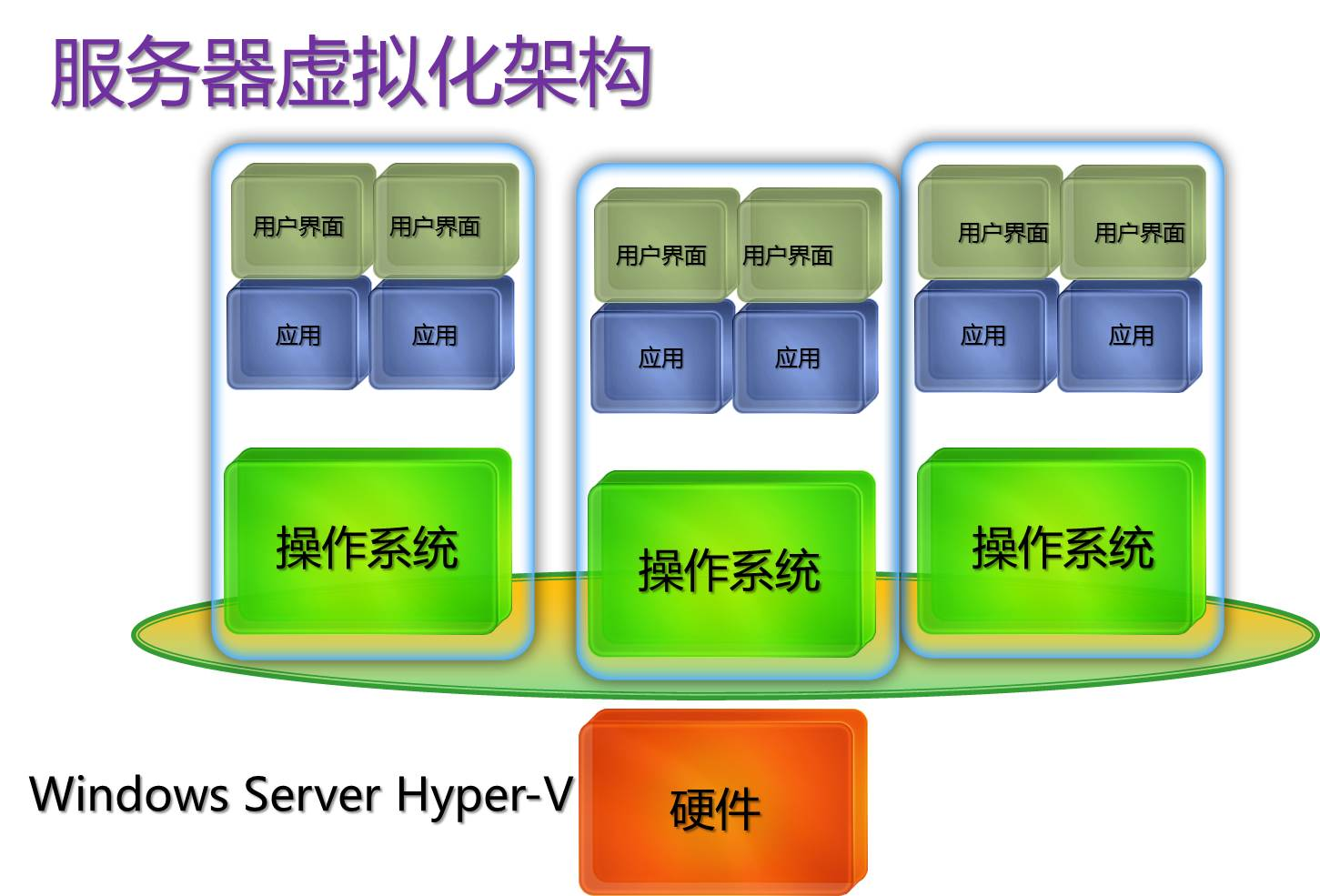
1. 服务器虚拟化的核心技术
服务器虚拟化的核心技术包括 CPU 虚拟化、内存虚拟化、存储虚拟化和网络虚拟化。下面我用更接地气的方式解释一下:
- CPU 虚拟化:就像老师给多个学生分配任务,每个学生轮流使用同一台电脑。CPU 虚拟化技术(如 Intel 的 VT-x)可以让多个虚拟机共享物理 CPU 的资源,通过分时复用的方式,让每个虚拟机都能正常运行。比如物理 CPU 是 4 核的,可以虚拟出 8 个 CPU 核心给各个虚拟机使用,每个虚拟机感觉自己独占了 CPU 资源。
- 内存虚拟化:好比每个学生都有自己的笔记本,虽然放在同一个教室里,但互相看不到对方的笔记。内存虚拟化则是通过地址转换技术,让每个虚拟机都有自己独立的内存空间,互不干扰。例如,物理服务器有 16GB 内存,可以给每个虚拟机分配 2GB 内存,即使某个虚拟机的内存溢出,也不会影响其他虚拟机。
- 存储虚拟化:类似把一个大图书馆的书分成多个小书架,每个学生负责一个小书架的管理。存储虚拟化技术可以将物理服务器的存储资源虚拟成多个独立的存储卷,每个虚拟机可以独立使用这些存储卷,进行文件存储和读写操作。
- 网络虚拟化:就像在一个大房间里用隔板隔出多个小隔间,每个隔间都有自己的网络接口。网络虚拟化可以为每个虚拟机创建独立的虚拟网络接口,实现虚拟机之间的网络隔离和通信。例如,虚拟机 A 和虚拟机 B 可以在同一个虚拟局域网内通信,而虚拟机 C 则处于另一个虚拟局域网,无法直接访问 A 和 B。
2. 常见的服务器虚拟化技术
- VMware vSphere:这是一款专业的服务器虚拟化解决方案,功能强大,但对于学生来说,学习成本较高,需要一定的硬件支持。
- KVM(Kernel-based Virtual Machine):是 Linux 系统自带的虚拟化技术,开源且免费,适合我们学生在实验室的 Linux 服务器上搭建虚拟化环境。
- Xen:也是一款开源的虚拟化技术,曾经很流行,现在在某些特定场景下仍有应用。
三、蓝耘元生代:把 ComfyUI 和服务器虚拟化串起来的 “魔法平台”
现在重点来了,蓝耘元生代平台是怎么把 ComfyUI 工作流和服务器虚拟化结合起来的呢?在我看来,这个平台就像一个 “魔法中介”,一边连接着我们直观的工作流设计需求,另一边连接着服务器资源的高效利用。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
(一)为什么需要把 ComfyUI 和服务器虚拟化结合?
先从需求层面想想。假设我们用 ComfyUI 设计了一个复杂的工作流,比如一个视频渲染工作流,需要大量的计算资源。这时候,如果直接在本地跑这个工作流,可能会因为本地电脑性能不足而卡顿,甚至崩溃。但是如果把这个工作流部署到服务器上,利用服务器的高性能资源来运行,就能大大提高效率。可是,服务器资源是有限的,尤其是在多人共享的情况下,怎么保证每个工作流都能合理使用资源,互不干扰呢?这时候,服务器虚拟化就派上用场了。
通过服务器虚拟化技术,我们可以在服务器上为每个 ComfyUI 工作流创建一个独立的虚拟机环境。每个虚拟机就像一个 “专属小房间”,里面运行着工作流所需的操作系统、依赖环境和代码。这样一来,不同的工作流之间就不会因为环境冲突而互相影响,同时还能根据工作流的资源需求动态分配 CPU、内存等资源,提高服务器的利用率。
案例:学生团队协作开发
比如我们小组有 5 个人,一起做一个机器学习项目。每个人的代码可能依赖不同的 Python 库版本,有的用 TensorFlow 2.0,有的用 PyTorch 1.8。如果直接在同一台服务器上运行,很容易出现库冲突。这时候,我们可以在蓝耘元生代平台上为每个人的工作流创建一个独立的虚拟机,每个虚拟机安装对应的库版本,这样就不会互相影响了。而且,当某个人需要进行大规模模型训练时,可以临时申请更多的 CPU 和内存资源,训练完成后再释放,不会占用过多的服务器资源。
(二)技术层面的联动:从工作流设计到虚拟机部署
接下来聊聊技术层面的实现。我试着从一个学生的视角,还原一下可能的实现过程,可能不够专业,但胜在真实易懂。
1. ComfyUI 工作流的 “编译” 与 “打包”
我们在 ComfyUI 里设计好的工作流,本质上是一个可视化的流程定义,但服务器并不能直接识别这个流程。所以,首先需要把 ComfyUI 的工作流 “翻译” 成计算机能执行的代码或配置文件。这个过程有点像把流程图翻译成编程语言,比如 Python 代码。
举个例子,假设我们在 ComfyUI 里设计了一个数据处理工作流,包含数据读取、清洗、分析和保存四个节点。那么,ComfyUI 平台可能会自动生成对应的 Python 脚本,每个节点对应脚本中的一个函数或类。比如:
# 自动生成的工作流执行脚本
def data_processing_workflow():
# 数据读取节点
data = read_data("input.csv")
# 数据清洗节点
cleaned_data = clean_data(data)
# 数据分析节点
result = analyze_data(cleaned_data)
# 数据保存节点
save_result(result, "output.csv")
if __name__ == "__main__":
data_processing_workflow()当然,实际的生成过程可能更复杂,需要处理节点之间的参数传递、异常处理等。比如,如果数据读取节点读取的是一个不存在的文件,需要添加异常捕获代码,避免工作流崩溃。

2. 工作流与虚拟机的 “绑定”
生成工作流的执行代码后,接下来需要考虑如何在服务器虚拟化环境中运行这个代码。这时候,我们可以把工作流的执行环境打包成一个虚拟机镜像。虚拟机镜像就像一个 “预装了系统和软件的硬盘”,里面包含了工作流运行所需的一切,比如操作系统(如 Ubuntu)、Python 运行环境、依赖的库(如 Pandas、NumPy)、工作流的代码等。
创建虚拟机镜像的过程,我觉得有点像搭积木。首先选一个基础镜像,比如官方的 Ubuntu 镜像,然后在这个基础上安装所需的软件和库,复制工作流的代码,最后把这个镜像保存下来。这个过程可以通过编写脚本自动化完成,比如使用 Shell 脚本:
#!/bin/bash
# 创建工作流运行环境的虚拟机镜像
# 拉取基础镜像(以KVM为例)
wget https://cloud-images.ubuntu.com/jammy/current/jammy-server-cloudimg-amd64.img -O base_image.qcow2
# 启动虚拟机进行配置
qemu-system-x86_64 -enable-kvm -m 2048 -drive file=base_image.qcow2,format=qcow2 -cdrom ubuntu.iso
# 在虚拟机中安装依赖
apt-get update -y
apt-get install -y python3 python3-pip
pip3 install pandas numpy
# 复制工作流代码到虚拟机
scp workflow_code.py user@vm_ip:/home/user/workflow_code.py
# 关闭虚拟机并转换镜像格式
qemu-img convert -f qcow2 -O qcow2 base_image.qcow2 comfyui_workflow_image.qcow2不过,手动配置镜像比较麻烦,后来我发现可以用 Docker 来构建镜像,再通过工具将 Docker 镜像转换为虚拟机镜像,这样更高效。比如,先编写一个 Dockerfile:
FROM ubuntu:latest
RUN apt-get update -y && apt-get install -y python3 python3-pip
RUN pip3 install pandas numpy
COPY workflow_code.py /app/workflow_code.py
CMD ["python3", "/app/workflow_code.py"]然后构建 Docker 镜像:
docker build -t comfyui_workflow_image .最后使用
docker export或第三方工具将 Docker 镜像转换为虚拟机镜像,这样就能在 KVM 等虚拟化平台上使用了。
3. 虚拟机的动态管理:启动、监控与销毁
有了虚拟机镜像后,就可以在服务器虚拟化平台上根据工作流的需求动态创建、启动和销毁虚拟机了。比如说,当有一个新的工作流需要运行时,服务器虚拟化平台会从镜像仓库中拉取对应的虚拟机镜像,创建一个新的虚拟机实例,分配 CPU、内存、存储等资源,然后启动虚拟机运行工作流代码。
在这个过程中,可能需要用到一些服务器虚拟化的管理工具或 API。比如,使用 Python 的
libvirt库来管理 KVM 虚拟机,前面提到的代码示例其实只是冰山一角,实际应用中需要处理更多细节,比如网络配置、存储分配等。
import libvirt
from xml.dom import minidom
# 连接到本地的虚拟化管理程序
conn = libvirt.open("qemu:///system")
# 创建一个虚拟网络
def create_virtual_network(network_name):
network_xml = f"""
<network>
<name>{network_name}</name>
<forward mode='nat'/>
<ip address='192.168.122.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.122.2' end='192.168.122.254'/>
</dhcp>
</ip>
</network>
"""
network = conn.networkDefineXML(network_xml)
network.create()
return network
# 创建虚拟机时指定虚拟网络
def create_vm_with_network(image_path, vm_name, cpu_cores, memory_mb, network_name):
network = conn.networkLookupByName(network_name)
network_xml = network.XMLDesc()
vm_xml = f"""
<domain type='kvm'>
<name>{vm_name}</name>
<memory unit='MiB'>{memory_mb}</memory>
<vcpu>{cpu_cores}</vcpu>
<os>
<type arch='x86_64' machine='pc-i440fx-2.12'>hvm</type>
</os>
<devices>
<disk type='file' device='disk'>
<source file='{image_path}'/>
<target dev='vda' bus='virtio'/>
</disk>
<interface type='network'>
<source network='{network_name}'/>
<model type='virtio'/>
</interface>
</devices>
</domain>
"""
vm = conn.createXML(vm_xml, 0)
return vm这段代码展示了如何创建虚拟网络并将虚拟机连接到该网络,这样虚拟机就可以通过 NAT 方式访问外部网络了。对于我们学生来说,可能不需要深入理解 XML 配置的每个字段,但需要知道如何通过代码为虚拟机配置网络,确保工作流能够正常访问外部资源,比如下载数据、调用 API 等。
四、实战演练:用 ComfyUI 工作流管理虚拟机生命周期
(一)场景假设:学生实验室的服务器资源管理
假设我们计算机系有一台高性能服务器,供同学们做实验用。以前大家都是直接远程登录服务器,经常出现环境冲突、资源抢占的问题。现在,我们可以利用蓝耘元生代平台的 ComfyUI 工作流和服务器虚拟化技术,设计一个 “实验室服务器资源管理工作流”,实现虚拟机的自助申请、创建、使用和释放。
(二)ComfyUI 工作流设计
我们可以在 ComfyUI 里设计一个包含以下节点的工作流:
- 用户申请节点:学生通过这个节点提交虚拟机申请,填写所需的 CPU 核数、内存大小、使用时长等信息;
- 资源审批节点:实验室管理员(或自动审批规则)审核申请,判断服务器资源是否充足;
- 虚拟机创建节点:根据审批通过的申请信息,调用服务器虚拟化 API 创建虚拟机;
- 通知用户节点:通过邮件或平台消息通知学生虚拟机的登录信息;
- 自动销毁节点:在使用时长到期后,自动销毁虚拟机,释放资源。
工作流流程图
用户申请节点 -> 资源审批节点
资源审批节点 -> [通过] 虚拟机创建节点 -> 通知用户节点 -> 自动销毁节点
资源审批节点 -> [不通过] 通知用户节点(审批不通过)(三)关键代码实现
1. 用户申请节点的数据处理
当学生提交申请后,ComfyUI 工作流需要将申请数据保存到数据库,并触发后续的审批流程。这里可以用 Python 的 Flask 框架搭建一个简单的 API 接口,接收申请数据:
from flask import Flask, request, jsonify
import sqlite3
app = Flask(__name__)
# 连接到数据库
conn = sqlite3.connect('vm_application.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS applications
(id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL,
cpu_cores INTEGER NOT NULL,
memory_mb INTEGER NOT NULL,
duration_hours INTEGER NOT NULL,
status TEXT NOT NULL DEFAULT 'pending')''')
conn.commit()
@app.route('/apply_vm', methods=['POST'])
def apply_vm():
data = request.json
username = data['username']
cpu_cores = data['cpu_cores']
memory_mb = data['memory_mb']
duration_hours = data['duration_hours']
# 插入申请数据到数据库
c.execute("INSERT INTO applications (username, cpu_cores, memory_mb, duration_hours) VALUES (?, ?, ?, ?)",
(username, cpu_cores, memory_mb, duration_hours))
conn.commit()
return jsonify({'message': '申请已提交,等待审批'}), 200
if __name__ == '__main__':
app.run(debug=True)2. 虚拟机创建节点的逻辑
在资源审批通过后,ComfyUI 工作流需要调用服务器虚拟化 API 创建虚拟机。这里继续使用前面提到的
libvirt库的代码,结合数据库中的申请信息:
import sqlite3
import libvirt
# 从数据库获取待创建的申请
conn_db = sqlite3.connect('vm_application.db')
c_db = conn_db.cursor()
c_db.execute("SELECT * FROM applications WHERE status='approved'")
applications = c_db.fetchall()
for app in applications:
app_id, username, cpu_cores, memory_mb, duration_hours, status = app
vm_name = f"student_{username}_{app_id}"
image_path = "/path/to/comfyui_workflow_image.qcow2" # 假设镜像路径已知
# 创建虚拟机
conn_virt = libvirt.open("qemu:///system")
create_vm_from_image(image_path, vm_name, cpu_cores, memory_mb)
start_vm(vm_name)
# 更新申请状态为'created'
c_db.execute("UPDATE applications SET status='created' WHERE id=?", (app_id,))
conn_db.commit()3. 自动销毁节点的定时任务
为了在虚拟机使用时长到期后自动销毁,可以设置一个定时任务,每隔一段时间检查数据库中状态为 'created' 的申请,计算剩余使用时间,到期后调用销毁函数:
import schedule
import time
import sqlite3
import libvirt
def check_vm_expiry():
conn_db = sqlite3.connect('vm_application.db')
c_db = conn_db.cursor()
c_db.execute("SELECT * FROM applications WHERE status='created'")
applications = c_db.fetchall()
for app in applications:
app_id, username, cpu_cores, memory_mb, duration_hours, status = app
# 假设创建时间存储在数据库中,这里简化为当前时间减去创建时间
# 实际中需要记录创建时间字段
elapsed_hours = (time.time() - app_creation_time) / 3600
if elapsed_hours >= duration_hours:
vm_name = f"student_{username}_{app_id}"
destroy_vm(vm_name)
c_db.execute("UPDATE applications SET status='destroyed' WHERE id=?", (app_id,))
conn_db.commit()
# 每隔1小时检查一次
schedule.every(1).hours.do(check_vm_expiry)
while True:
schedule.run_pending()
time.sleep(1)五、学生视角的思考:这俩技术联动的优缺点和未来
(一)优点:对学生党太友好了!
- 降低使用门槛:以前用服务器得自己搭环境、配依赖,现在通过 ComfyUI 工作流和预打包的虚拟机镜像,只需要关注工作流逻辑,不用再为环境问题头疼,对新手很友好。比如我第一次用 ComfyUI 搭建数据处理工作流时,只花了半小时就完成了以前需要写几百行代码的任务,而且调试起来更直观。
- 资源分配更公平:服务器虚拟化可以为每个学生分配独立的虚拟机,避免了多人共享同一环境时的冲突。记得有一次小组合作,我用 PyTorch 写模型,同学用 TensorFlow 做数据预处理,两人同时跑任务居然互不影响,要是以前在同一台服务器上,早就因为库版本冲突报错了。
- 弹性扩展超方便:如果某个工作流需要更多资源,只需要在虚拟机配置里调整 CPU 和内存即可,不用换物理服务器。我做图像识别项目时,训练模型需要大量 GPU 资源,通过蓝耘元生代平台申请了一台 8 核 16GB 内存 + RTX 3090 的虚拟机,训练速度比本地电脑快了 10 倍,简直爽歪歪!
(二)缺点:踩过的坑也不少
- 镜像制作有点麻烦:刚开始做虚拟机镜像的时候,经常因为依赖库版本不对、环境配置错误导致镜像无法启动。有一次我在镜像里装了 Python 3.8,结果工作流里的代码用了 Python 3.9 的特性,导致运行报错,花了一晚上才找到问题所在。后来我学会了用
requirements.txt文件管理依赖,还发现可以用 Docker Hub 上的公共镜像作为基础,省了不少事。- 网络配置容易懵:虚拟机之间的网络互通、端口映射等配置对学生来说有点复杂。我第一次配置虚拟机网络时,怎么都连不上外部网络,最后发现是虚拟网络的 NAT 设置没做好,端口转发规则也没配置。后来我把常用的网络配置步骤写成了脚本,每次创建虚拟机时直接调用,才解决了这个问题。
- 资源监控不够直观:虽然知道服务器虚拟化可以动态分配资源,但具体每个虚拟机用了多少 CPU 和内存,怎么实时监控,我还没完全搞明白。目前只能通过
virsh stats命令行查看,不够直观。我想如果能在 ComfyUI 里加一个可视化的资源监控面板,显示每个虚拟机的资源使用曲线,那就太完美了。
(三)未来展望:要是能这样就好了!
- 更智能的资源调度:如果蓝耘元生代平台能自动根据工作流的运行情况调整虚拟机资源,比如当某个工作流需要大量计算时自动分配更多 CPU,空闲时回收资源,那就太智能了。就像云计算里的自动伸缩功能,对于我们做实验来说,能大大提高资源利用率,还不用手动申请调整配置。
- 一键式镜像生成:希望未来 ComfyUI 能支持一键将工作流的依赖环境打包成虚拟机镜像,不用手动写脚本安装库。比如在工作流设计界面里加一个 “生成镜像” 按钮,平台自动扫描工作流中用到的节点和依赖,自动生成对应的虚拟机镜像,对于我们学生来说,能节省大量时间,再也不用为镜像配置发愁了。
- 可视化的虚拟机管理界面:要是能在 ComfyUI 里直接看到所有虚拟机的状态,比如运行中、已停止、资源占用情况等,并且可以通过拖拽操作管理虚拟机,那就更符合 ComfyUI 的可视化风格了。比如用不同颜色的图标表示虚拟机状态,点击图标就能查看详细信息,拖拽图标到不同的资源池进行迁移,这样的操作体验对学生党来说简直不要太友好。


















 3056
3056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











