






1. 多线程原理
1.1 三要素
-
原⼦性:即⼀个不可再被分割的颗粒。在Java中原⼦性指的是⼀个或多个操作要么全部执⾏成功要么全部 执⾏失败。 -
有序性:程序执⾏的顺序按照代码的先后顺序执⾏。(处理器可能会对指令进⾏重排序) -
可⻅性:当多个线程访问同⼀个变量时,如果其中⼀个线程对其作了修改,其他线程能⽴即获取到最新的 值。
1.2Java内存模型(JMM)
JMM(Java Memory Model)规定了JVM必须遵循一组最小保证,这组保证规定了对变量的写入操作在何时将对于其他线程可见。
屏蔽各种硬件和操作系统的内存访问差异,以实现Java程序能在不同平台达到一致的并发效果
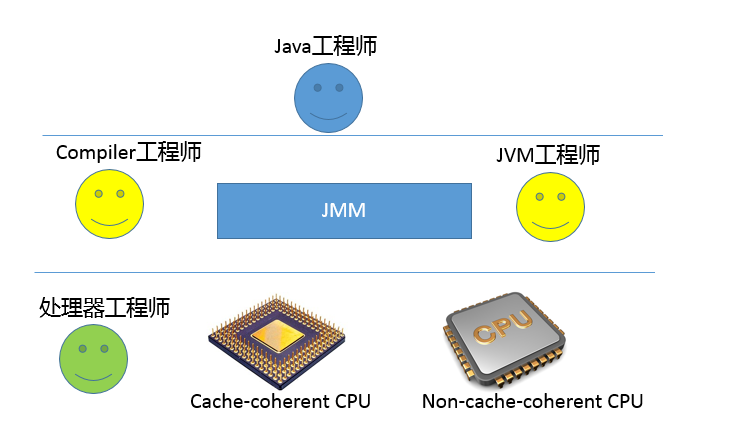
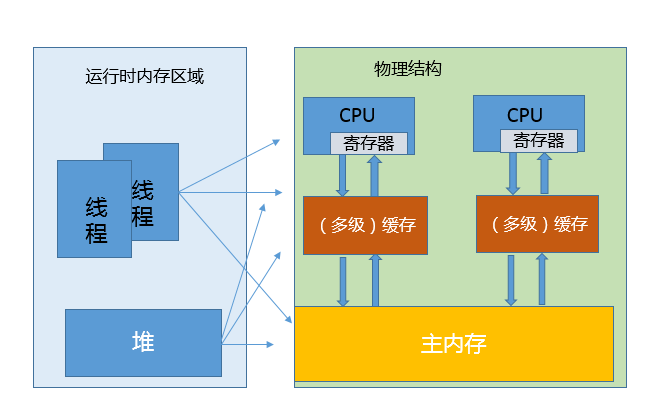
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意如图
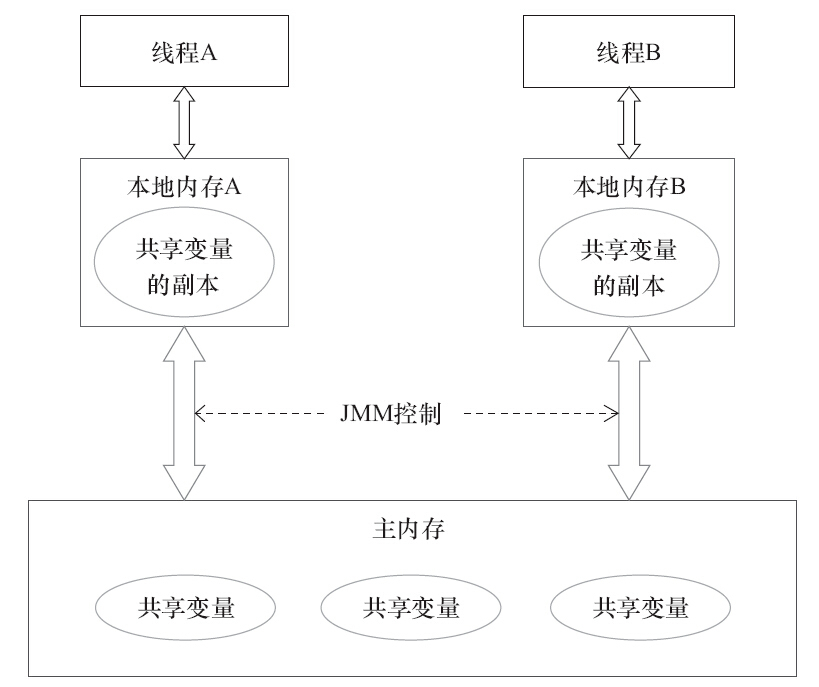
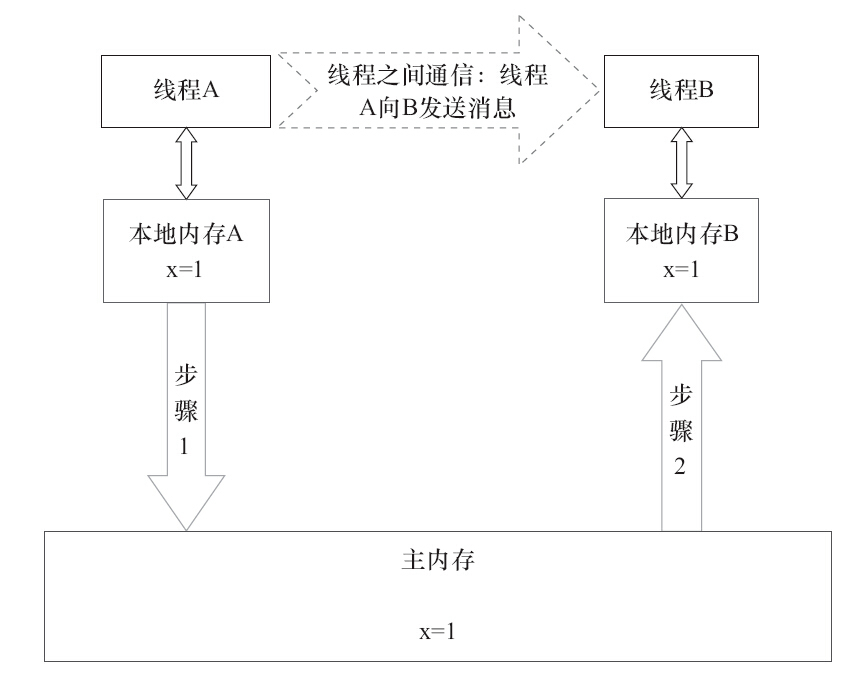
线程间通讯流程图
1)线程A把本地内存A中更新过的共享变量刷新到主内存中去。 2)线程B到主内存中去读取线程A之前已更新过的共享变量
1.2.1 重排序与可见性
重排序是可见性的根因
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。 1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。 2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。 3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

内存重排序案例
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟

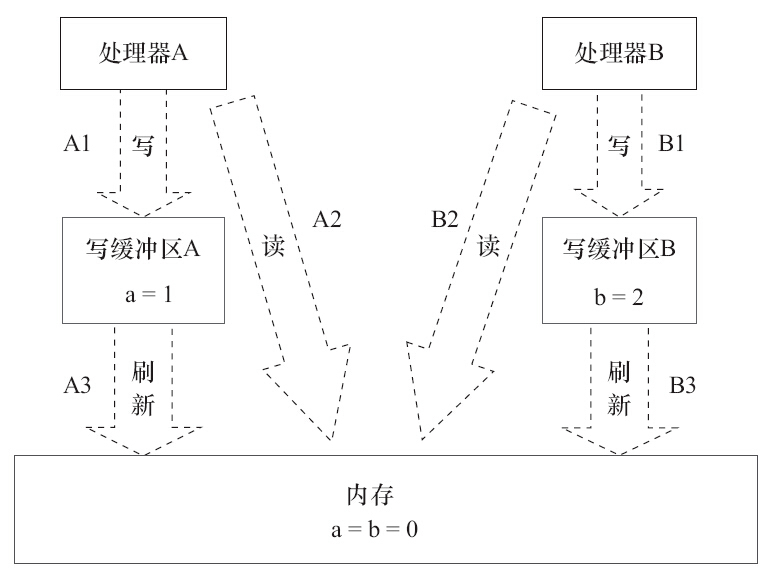
虽然处理器A执行内存操作的顺序为:A1→A2,但内存操作实际发生的顺序却是A2→A1。此时,处理器A的内存操作顺序被重排序了
1.2.2 内存屏障
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM把内存屏障指令分为4类
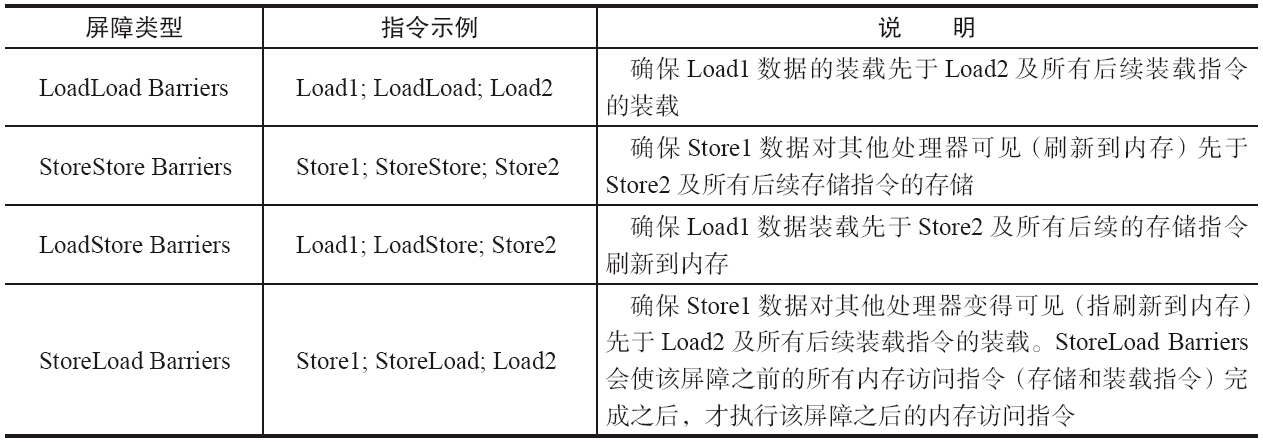
执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(Buffer Fully Flush)
1.2.3 happens-before
用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间
在多线程中,⼀⽅⾯,要让编译器和CPU可以灵活地重排序,提高性能;
另⼀⽅⾯,要对开发者做⼀些承诺,明确告知开发者不需要感知什么样的重排序,需要感知什么样的重排序。然后,根据需要决定这种重排序对程序是否有影响。如果有影响,就需要开发者显示地通过volatile、 synchronized等线程同步机制来禁⽌重排序
-
程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。 -
监视器锁规则(synchronized):对一个锁的解锁,happens-before于随后对这个锁的加锁。 -
volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。 -
final变量规则:对final变量的写, happen-before于final域对象的读, happen-before于后续对final变量的读 -
传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。 -
start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。 -
join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回
1.2.4 as-if-serial
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
多线程间as-if-serial需要上层自告诉编译器cpu何时可以重排序,JMM为我们开发者屏蔽了这一点
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上述代码 A B 可能会重排序 A C不会。
1.2.5 volatile
理解volatile特性的一个好方法是把对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步
volatile变量自身具有下列特性。
-
可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。 -
原子性:对任意 单个volatile变量的读/写具有原子性,但类似于volatile int i ,i++这种复合操作不具有原子性

当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量
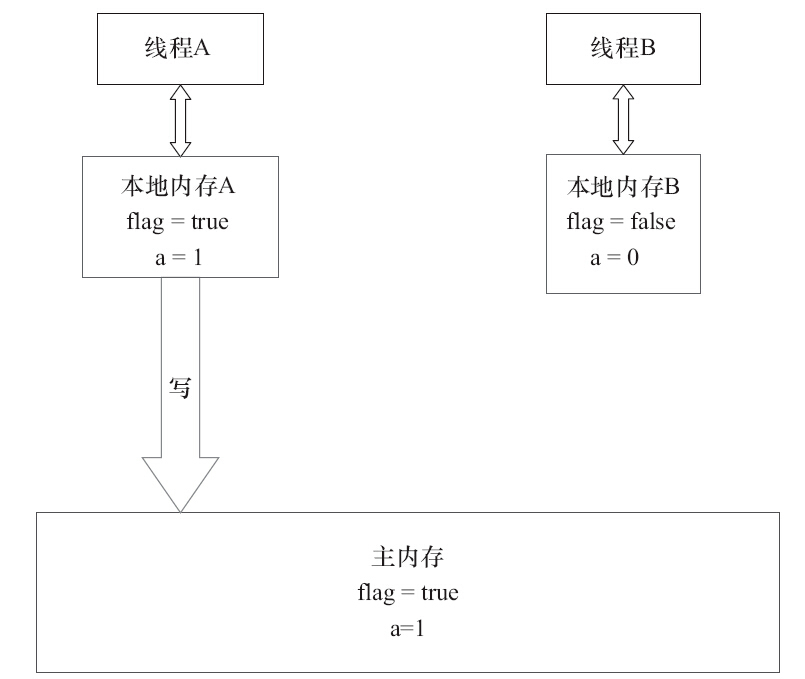
volatile底层实现
JMM会限制编译器重排序和处理器重排序
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略。
-
在每个volatile写操作的前面插入一个StoreStore屏障。 -
在每个volatile写操作的后面插入一个StoreLoad屏障。 -
在每个volatile读操作的后面插入一个LoadLoad屏障。 -
在每个volatile读操作的后面插入一个LoadStore屏障。
1.2.6 final
对于final域,编译器和处理器要遵守两个重排序规则。
-
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。 -
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序
使用final解决构造器溢出问题

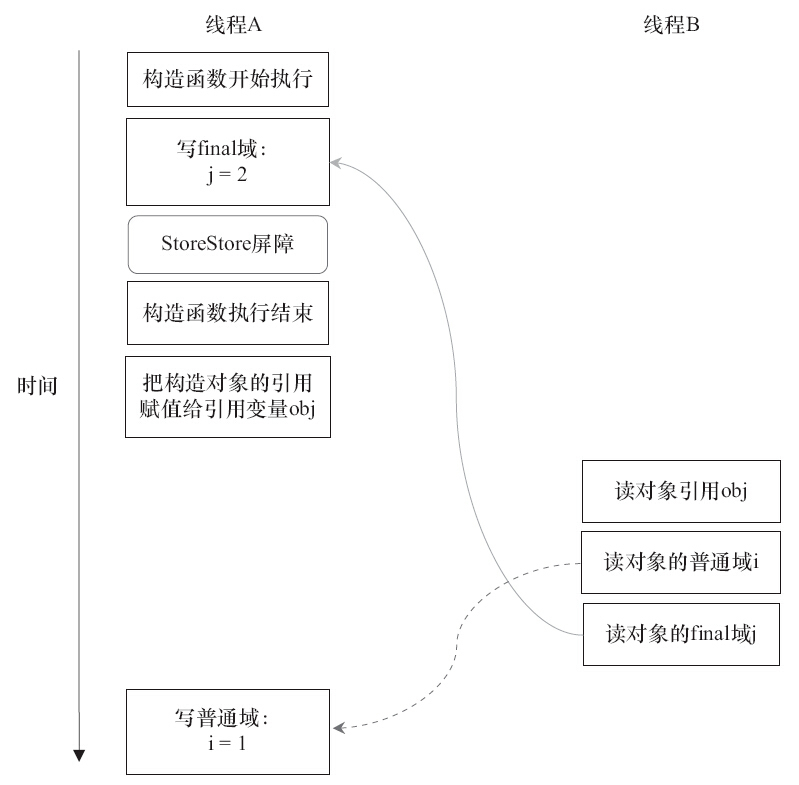
写final重排序规则
编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。以上图为例,在读线程B“看到”对象引用obj时,很可能obj对象还没有构造完成(对普通域i的写操作被重排序到构造函数外,此时初始值1还没有写入普通域i)。
读final重排序规则
编译器会在读final域操作的前面插入一个LoadLoad屏障。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
1.3 线程
1.3.1 什么是线程
现代操作系统在运行一个程序时,会为其创建一个进程。例如,启动一个Java程序,操作系统就会创建一个Java进程。现代操作系统调度的最小单元是线程,也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。处理器在这些线程上高速切换,让使用者感觉到这些线程在同时执行。
Java线程一比一映射到操作系统线程
1.3.2 线程状态转移图
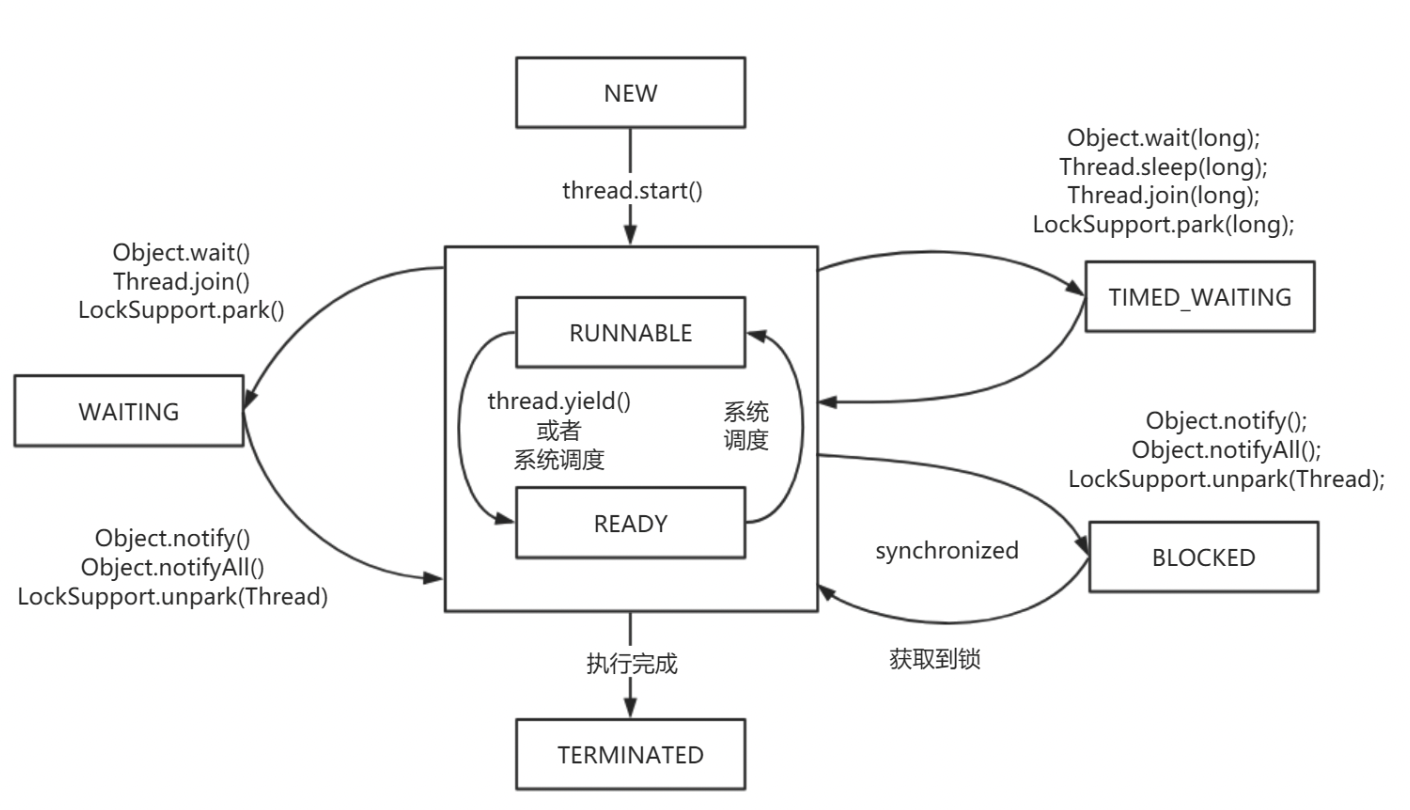
新建(NEW),表示线程被创建出来还没真正启动的状态,可以认为它是个 Java 内部状态。
就绪(RUNNABLE),表示该线程已经在 JVM 中执行,当然由于执行需要计算资源,它可能是正在运行,也可能还在等待系统分配给它 CPU 片段,在就绪队列里面排队。在其他一些分析中,会额外区分一种状态 RUNNING,但是从 Java API 的角度,并不能表示出来。
阻塞(BLOCKED),这个状态和我们前面两讲介绍的同步非常相关,阻塞表示线程在等待 Monitor lock。比如,线程试图通过 synchronized 去获取某个锁,但是其他线程已经独占了,那么当前线程就会处于阻塞状态。
等待(WAITING),表示正在等待其他线程采取某些操作。一个常见的场景是类似生产者消费者模式,发现任务条件尚未满足,就让当前消费者线程等待(wait),另外的生产者线程去准备任务数据,然后通过类似 notify 等动作,通知消费线程可以继续工作了。Thread.join() 也会令线程进入等待状态。
计时等待(TIMED_WAIT),其进入条件和等待状态类似,但是调用的是存在超时条件的方法,比如 wait 或 join 等方法的指定超时版本,如下面示例:
1.3.3时间片
其实在单个处理器的时期,操作系统就能处理多线程并发任务。处理器给每个线程分配 CPU 时间片(Time Slice),线程在分配获得的时间片内执行任务。
CPU 时间片是 CPU 分配给每个线程执行的时间段,一般为几十毫秒。在这么短的时间内线程互相切换,我们根本感觉不到,所以看上去就好像是同时进行的一样。
时间片决定了一个线程可以连续占用处理器运行的时长。当一个线程的时间片用完了,或者因自身原因被迫暂停运行了,这个时候,另外一个线程(可以是同一个线程或者其它进程的线程)就会被操作系统选中,来占用处理器。这种一个线程被暂停剥夺使用权,另外一个线程被选中开始或者继续运行的过程就叫做上下文切换(Context Switch)。
具体来说,一个线程被剥夺处理器的使用权而被暂停运行,就是“切出”;一个线程被选中占用处理器开始或者继续运行,就是“切入”。在这种切出切入的过程中,操作系统需要保存和恢复相应的进度信息,这个进度信息就是“上下文”了。
那上下文都包括哪些内容呢?具体来说,它包括了寄存器的存储内容以及程序计数器存储的指令内容。CPU 寄存器负责存储已经、正在和将要执行的任务,程序计数器负责存储 CPU 正在执行的指令位置以及即将执行的下一条指令的位置。
在当前 CPU 数量远远不止一个的情况下,操作系统将 CPU 轮流分配给线程任务,此时的上下文切换就变得更加频繁了,并且存在跨 CPU 上下文切换,比起单核上下文切换,跨核切换更加昂贵。
1.3.4 线程上下文切换
在并发程序中,并不是启动更多的线程就能让程序最大限度地并发执行。线程数量设置太小,会导致程序不能充分地利用系统资源;线程数量设置太大,又可能带来资源的过度竞争,导致上下文切换带来额外的系统开销。
竞争大的多线程不如单线程
线程由 RUNNABLE 转为非 RUNNABLE 的过程就是线程上下文切换。
-
自发性上下文切换
调用sleep(),wait(),yield(),join(),park(),synchronizedlock
-
非自发性上下文切换
线程被分配的时间片用完,虚拟机垃圾回收导致或者执行优先级的问题导致。
垃圾回收会导致Stop The World 暂停用户线程。
监控上下文切换
-
vmstat查看机器整体上线文切换➜ ~ vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 647096 209224 2664924 0 0 0 8 5 1 0 0 99 0 0
0 0 0 646720 209224 2664932 0 0 0 58 796 1432 1 1 99 0 0
0 0 0 646736 209224 2664932 0 0 0 0 712 1325 0 0 99 0 0
0 0 0 646752 209224 2664932 0 0 0 16 667 1239 0 0 99 0 0
0 0 0 646984 209224 2664932 0 0 0 0 723 1318 1 1 99 0 0
0 0 0 646736 209224 2664932 0 0 0 0 745 1327 0 1 99 0 0 -
pidstat查看进程信息man pidstat查看命令说明手册...
-w
Report task switching activity (kernels 2.6.23 and later only). The following values may be displayed:
UID
The real user identification number of the task being monitored.
USER
The name of the real user owning the task being monitored.
PID
The identification number of the task being monitored.
cswch/s 自愿切换
Total number of voluntary context switches the task made per second. A voluntary context switch
occurs when a task blocks because it requires a resource that is unavailable.
nvcswch/s 非自愿切换
Total number of non voluntary context switches the task made per second. A involuntary context
switch takes place when a task executes for the duration of its time slice and then is forced to
relinquish the processor.
Command
The command name of the task.查看所有分进程的上下文切换情况
➜ ~ pidstat -w -l -p ALL
Linux 3.10.0-1127.19.1.el7.x86_64 (VM-4-16-centos) 05/04/2022 _x86_64_ (2 CPU)
12:44:06 AM UID PID cswch/s nvcswch/s Command
12:44:06 AM 0 1 0.42 0.00 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
12:44:06 AM 0 2 0.01 0.00 kthreadd
12:44:06 AM 0 4 0.00 0.00 kworker/0:0H
12:44:06 AM 0 6 0.21 0.00 ksoftirqd/0
12:44:06 AM 0 7 0.49 0.00 migration/0
12:44:06 AM 0 8 0.00 0.00 rcu_bh
12:44:06 AM 0 9 16.82 0.00 rcu_sched
上下文切换损耗
-
操作系统保存和恢复上下文; -
调度器进行线程调度; -
处理器高速缓存重新加载; -
上下文切换也可能导致整个高速缓存区被冲刷,从而带来时间开销。
1.4 ThreadLocal
-
由Java提供的一种保存线程私有信息的机制; -
在线程的整个生命周期内有效; -
可使用的场景:在一个线程关联的不同业务模块之间传递关键类信息。(比如用户ID,request上下文信息 )
源码分析

每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例.
这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal.
当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例的话,threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用.
只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
内存泄漏
GC日志:https://gceasy.io/my-gc-report.jsp?p=c2hhcmVkLzIwMjIvMDUvNC8tLWdjLTIwMjItMDUtMDRfMTAtMTYtMzkubG9nLS0yLTE2LTI0&channel=WEB
public class ThreadLocalDemo {
/**
* -XX:+PrintHeapAtGC
* -XX:+PrintGCDetails
* -XX:+PrintGCTimeStamps
* -XX:+PrintGCDateStamps
* -XX:+PrintGCApplicationStoppedTime
* -XX:+PrintGCApplicationConcurrentTime
* -Xloggc:/Users/david/Downloads/gc-demo/gc-%t.log
*/
@SneakyThrows
public static void main(String[] args) {
new Thread(() -> {
ThreadLocal<byte[]> threadLocal = new ThreadLocal<>();
threadLocal.set(new byte[1024 * 1024 * 4]);
threadLocal = null;
gc();//threadLocal被回收
Thread currentThread = Thread.currentThread();
//此时key为null value没有回收发生内存泄漏
Object threadLocals = ReflectUtil.getFieldValue(currentThread, "threadLocals");
System.out.println(threadLocals);
//线程退出后会GC threadLocals
}).start();
Thread.sleep(3_000);
gc();
}
@SneakyThrows
private static void gc() {
System.gc();
Thread.sleep(1_000L);
}
}
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。
ThreadLocal本身尽力避免内存泄漏
Java为了最小化减少内存泄露的可能性和影响,在ThreadLocal的get,set的时候都会清除线程Map里所有key为null的value。 所以最怕的情况就是,threadLocal对象设null了,开始发生“内存泄露”,然后使用线程池,这个线程结束,线程放回线程池中不销毁,这个线程一直不被使用,或者分配使用了又不再调用get,set方法,那么这个期间就会发生真正的内存泄露。
调用set()方法时,采样清理、全量清理,扩容时还会继续检查。 调用get()方法,没有直接命中,向后环形查找时。 调用remove()时,除了清理当前Entry,还会向后继续清理。
set方法源码
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 计算下标,算法:hashCode & (len - 1),和HashMap一样,这里不详叙。
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
/*
如果下标元素不是null,有两种情况:
1.同一个Key,覆盖value。
2.哈希冲突了。
*/
e != null;
/*
哈希冲突的解决方式:开放定址法的线性探测。
当前下标被占用了,就找next,找到尾巴还没找到就从头开始找。
直到找到没有被占用的下标。
*/
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
// 相同的Key,则覆盖value。
e.value = value;
return;
}
if (k == null) {
/*
下标被占用,但是Key.get()为null。说明ThreadLocal被回收了。
需要进行替换。
*/
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
/*
1.判断是否可以清理一些槽位。
2.如果清理成功,就无需扩容了,因为已经腾出一些位置留给下次使用。
3.如果清理失败,则要判断是否需要扩容。
*/
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
弱引用的作用?
ThreadLocalMap的Entry的指向ThreadLocal的弱引用反倒是解决了ThreadLocal对象的内存泄漏问题
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
ThreadLocal<byte[]> threadLocal = new ThreadLocal<>();
threadLocal.set(new byte[1024 * 1024 * 4]);
threadLocal = null;
如上面代码的用例局部局部变量的ThreadLocal如果在ThreadLocalMap.Entry是强引用,那么会造成ThreadLocal对象跟GCRoot相连无法被GC
避免内存泄漏
-
完全是由于程序员的错误使用造成。使用 set后一定手动调用remove,从而避免内存泄漏。 -
ThreadLocal设置成全局变量,避免ThreadLocal回收后造成ThreadLocalMap内存泄漏。
1.5 协程
实现线程主要有三种方式:轻量级进程和内核线程一对一相互映射实现的 1:1 线程模型、用户线程和内核线程实现的 N:1 线程模型以及用户线程和轻量级进程混合实现的 N:M 线程模型。
协程也叫用户态线程
线程实现模型
-
1:1 线程模型
内核线程(Kernel-Level Thread, KLT)是由操作系统内核支持的线程,内核通过调度器对线程进行调度,并负责完成线程的切换。
Linux 操作系统编程中,往往都是通过 fork() 函数创建一个子进程来代表一个内核中的线程。 一个进程调用 fork() 函数后,系统会先给新的进程分配资源,例如,存储数据和代码的空间。然后把原来进程的所有值都复制到新的进程中,只有少数值与原来进程的值(比如 PID)不同,这相当于复制了一个主进程。
相对于 fork() 系统调用创建的线程来说,轻量级进程(Light Weight Process,即 LWP) 使用 clone() 系统调用创建线程,该函数是将部分父进程的资源的数据结构进行复制,复制内容可选,且没有被复制的资源可以通过指针共享给子进程。因此,轻量级进程的运行单元更小,运行速度更快。LWP 是跟内核线程一对一映射的,每个 LWP 都是由一个内核线程支持。
-
N:1 线程模型
1:1 线程模型由于跟内核是一对一映射。
所以在线程创建、切换上都存在用户态和内核态的切换,性能开销比较大。
它还存在局限性,主要就是指系统的资源有限,不能支持创建大量的 LWP。
不需要内核的帮助了,线程创建、同步、销毁的过程中不会产生用户态和内核态的空间切换,因此线程的操作非常快速且低消耗。
-
N:M 线程模型
N:1 线程模型的缺点在于操作系统不能感知用户态的线程,因此容易造成某一个线程进行系统调用内核线程时被阻塞,从而导致整个进程被阻塞。
N:M 线程模型是基于上述两种线程模型实现的一种混合线程管理模型,即支持用户态线程通过 LWP 与内核线程连接,用户态的线程数量和内核态的 LWP 数量是 N:M 的映射关系。
Go协程与Java线程区别
JDK 1.8 Thread.java 中 Thread#start 方法的实现,实际上是通过 Native 调用 start0 方法实现的;在 Linux 下, JVM Thread 的实现是基于 pthread_create 实现的,而 pthread_create 实际上是调用了 clone() 完成系统调用创建线程的。
Java采用的是1:1模型,所以线程通过内核调度,会产生上下文切换。
Go采用的是N:M模型,在N个内核线程上调度M个协程。上下文切换在用户态完成,损耗较小。
协程实现原理
我们可以将协程看作是一个类函数或者一块函数中的代码,在用户态进行调度
假设程序中默认创建两个线程为协程使用,在主线程中创建协程 ABCD…,分别存储在就绪队列中,调度器首先会分配一个工作线程 A 执行协程 A,另外一个工作线程 B 执行协程 B,其它创建的协程将会放在队列中进行排队等待。
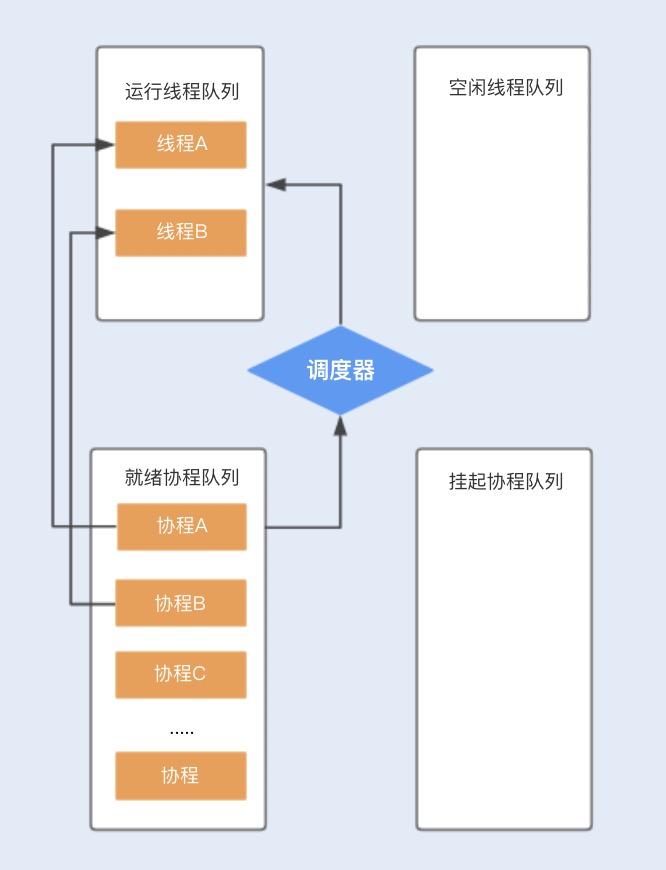
相比线程,协程少了由于同步资源竞争带来的 CPU 上下文切换,I/O 密集型的应用比较适合使用,特别是在网络请求中,有较多的时间在等待后端响应,协程可以保证线程不会阻塞在等待网络响应中,充分利用了多核多线程的能力。而对于 CPU 密集型的应用,由于在多数情况下 CPU 都比较繁忙,协程的优势就不是特别明显了。
JAVA中的协程
Kilim:https://github.com/kilim/kilim
本文由 mdnice 多平台发布















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









