







引入
model-free 模型可以针对未知的MDP问题
- 已知的MDP
Policy和Reward都是expose to agent,因此,可以方便地进行policy iteration和value iteration
(1) policy evalutaion采用Bellman expectation 进行迭代,此时policy保持不变,将状态空间中的所有state的value进行评估
v
i
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
i
−
1
(
s
′
)
)
v_i(s) = \sum_{a\in A}\pi(a|s)\left( R(s,a) + \gamma\sum_{s' \in S}P(s'|s,a)v_{i-1}(s') \right)
vi(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vi−1(s′))
然后,采用greedy算法根据action-value 的q function来选择最佳的policy,如此往复迭代value function 和 policy 直至收敛
q
π
i
(
s
,
a
)
=
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
π
i
(
s
′
)
π
i
+
1
(
s
)
=
arg
max
a
q
π
i
(
s
,
a
)
\begin{aligned} q_{\pi_{i}}(s, a) &=R(s, a)+\gamma \sum_{s^{\prime} \in S} P\left(s^{\prime} \mid s, a\right) v_{\pi_{i}}\left(s^{\prime}\right) \\ \pi_{i+1}(s) &=\underset{a}{\arg \max } q_{\pi_{i}}(s, a) \end{aligned}
qπi(s,a)πi+1(s)=R(s,a)+γs′∈S∑P(s′∣s,a)vπi(s′)=aargmaxqπi(s,a)
由此得到,policy iteration = policy evaluation + policy improvement
(2) value iteration则是每次迭代都选择最优的policy得到最优的value function,迭代公式为:
v
i
+
1
(
s
)
←
max
a
∈
A
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
i
(
s
′
)
v_{i+1}(s) \leftarrow \max _{a \in \mathcal{A}} R(s, a)+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \mid s, a\right) v_{i}\left(s^{\prime}\right)
vi+1(s)←a∈AmaxR(s,a)+γs′∈S∑P(s′∣s,a)vi(s′)
等value function收敛之后,再一次计算得到最优的policy
π
∗
(
s
)
←
arg
max
a
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
v
end
(
s
′
)
\pi^{*}(s) \leftarrow \underset{a}{\arg \max } R(s, a)+\gamma \sum_{s^{\prime} \in S} P\left(s^{\prime} \mid s, a\right) v_{\text {end }}\left(s^{\prime}\right)
π∗(s)←aargmaxR(s,a)+γs′∈S∑P(s′∣s,a)vend (s′)
- 未知的MDP
policy iteration 和 value iteration的假设都是环境的dynamics和rewards都是可观测的,但现实问题要嘛是未知的,或者太过于庞大
因此,迭代方法其实是利用完全已知的信息和现有的公式去迭代计算,但是没有用到agent和interaction的交互和反馈
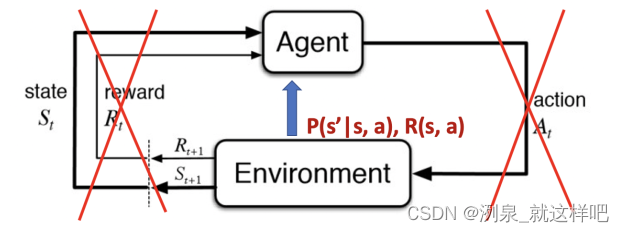
model-free RL:从interaction中学习
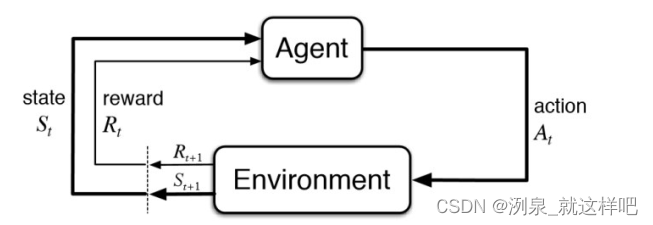
交互过程可以用trajectory或episode来表示,包括
{
S
1
,
A
1
,
R
1
,
S
2
,
A
2
,
R
2
,
…
,
S
T
,
A
T
,
R
T
}
\left\{S_{1}, A_{1}, R_{1}, S_{2}, A_{2}, R_{2}, \ldots, S_{T}, A_{T}, R_{T}\right\}
{S1,A1,R1,S2,A2,R2,…,ST,AT,RT}
Model-free prediction
采用的方法是policy evalution without access,也就是不用得到环境观测,也能进行policy的迭代,因此需要对特定policy的反馈进行估计,方法包括:
- Monte Carlo policy evaluation,即 蒙特卡洛策略评估, MC
- Temporal Difference learning,即 时间差分学习, TD
Monte-Carlo Policy Evaluation
蒙特卡洛方法的核心是采样
- return: 给定policy π \pi π, G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … G_{t}=R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\ldots Gt=Rt+1+γRt+2+γ2Rt+3+…
- value function 估计: v π ( s ) = E τ ∼ π [ G t ∣ s t = s ] v^{\pi}(s)=\mathbb{E}_{\tau \sim \pi}\left[G_{t} \mid s_{t}=s\right] vπ(s)=Eτ∼π[Gt∣st=s]
- MC 仿真:采样得到许多轨迹,然后计算实际的return,并计算平均return
- MC policy evalatiton: 根据之前得到的平均return来评估
- MC 不要求MDP的动态过程或reward,也不需要bootstrapping的概率分布估计,同时不要求状态满足Markov
- MC只能用于离散MDPs
算法具体过程:
- 每个step评估state v ( s ) v(s) v(s)是通过采样,根据真实return来更新
- 通过大量的采样,逼近真实的
v
π
(
s
)
v^\pi(s)
vπ(s)
μ t = 1 t ∑ j = 1 t x j = 1 t ( x t + ∑ j = 1 t − 1 x j ) = 1 t ( x t + ( t − 1 ) μ t − 1 ) = μ t − 1 + 1 t ( x t − μ t − 1 ) \begin{aligned} \mu_{t} &=\frac{1}{t} \sum_{j=1}^{t} x_{j} \\ &=\frac{1}{t}\left(x_{t}+\sum_{j=1}^{t-1} x_{j}\right) \\ &=\frac{1}{t}\left(x_{t}+(t-1) \mu_{t-1}\right) \\ &=\mu_{t-1}+\frac{1}{t}\left(x_{t}-\mu_{t-1}\right) \end{aligned} μt=t1j=1∑txj=t1(xt+j=1∑t−1xj)=t1(xt+(t−1)μt−1)=μt−1+t1(xt−μt−1)
增量MC更新:
N ( S t ) ← N ( S t ) + 1 v ( S t ) ← v ( S t ) + 1 N ( S t ) ( G t − v ( S t ) ) v ( S t ) ← v ( S t ) + α ( G t − v ( S t ) ) \begin{array}{l} N\left(S_{t}\right) \leftarrow N\left(S_{t}\right)+1 \\ v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\frac{1}{N\left(S_{t}\right)}\left(G_{t}-v\left(S_{t}\right)\right)\\ v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{t}-v\left(S_{t}\right)\right) \end{array} N(St)←N(St)+1v(St)←v(St)+N(St)1(Gt−v(St))v(St)←v(St)+α(Gt−v(St))
DP和MC在policy evalution上的区别
-
DP 是通过boostrapping方法和前一步的value来估计下一步的value
v i ( s ) ← ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v i − 1 ( s ′ ) ) v_{i}(s) \leftarrow \sum_{a \in \mathcal{A}} \pi(a \mid s)\left(R(s, a)+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \mid s, a\right) v_{i-1}\left(s^{\prime}\right)\right) vi(s)←a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vi−1(s′))
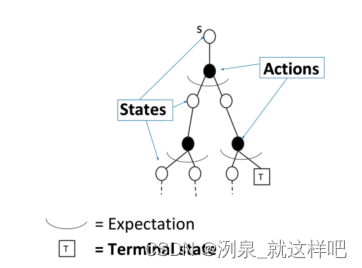
-
MC 则是基于经验平均return进行采样
v ( S t ) ← v ( S t ) + α ( G i , t − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{i, t}-v\left(S_{t}\right)\right) v(St)←v(St)+α(Gi,t−v(St))
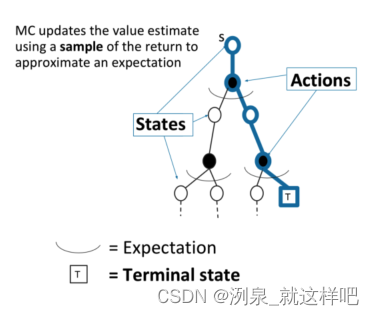
-
MC优势:MC可以应用于environment未知的场景,可以避免复杂的转换概率的推断,采样过程可以独立进行,适合大规模分布计算,之后再进行汇总计算平均return
Temporal-Difference (TD) Learning
-
TD方法可以直接从历史经验中学习
-
TD方法是model-free的,没有关于MDP转移方程和reward的先验知识
-
TD是不完全的episodes学习,基于bootstrapping
-
objective:给定policy,在线从经验中学习,更新 v π v_\pi vπ
-
最简单的TD算法:TD(0),对return进行估计, R t + 1 + γ v ( S t + 1 ) R_{t+1}+\gamma v\left(S_{t+1}\right) Rt+1+γv(St+1)
v ( S t ) ← v ( S t ) + α ( R t + 1 + γ v ( S t + 1 ) − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(R_{t+1}+\gamma v\left(S_{t+1}\right)-v\left(S_{t}\right)\right) v(St)←v(St)+α(Rt+1+γv(St+1)−v(St)) -
R t + 1 + γ v ( S t + 1 ) R_{t+1}+\gamma v\left(S_{t+1}\right) Rt+1+γv(St+1)称为TD target
-
δ t = R t + 1 + γ v ( S t + 1 ) − v ( S t ) \delta_{t}=R_{t+1}+\gamma v\left(S_{t+1}\right)-v\left(S_{t}\right) δt=Rt+1+γv(St+1)−v(St)称为TD error
-
与MC方法不同,MC方法的return是真实的,而TD方法是估计得到的
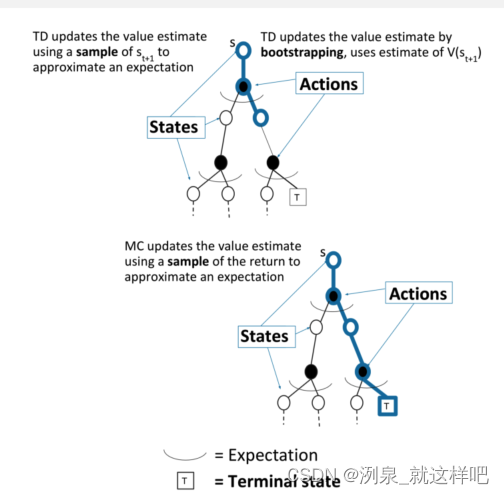
TD和MC对比
- TD可以在每个step之后在线学习,sequence可以是不完整的,TD可以利用Markov特性
- MC需要完成整个episode而得到return,sequence必须是完整的,MC不基于Markov特性
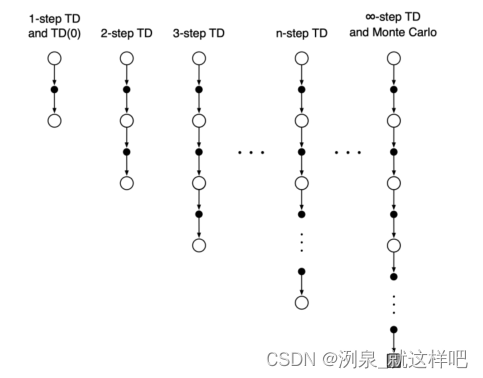
- 二者转化如下,MC相当于
T
D
(
∞
)
TD(\infty)
TD(∞)
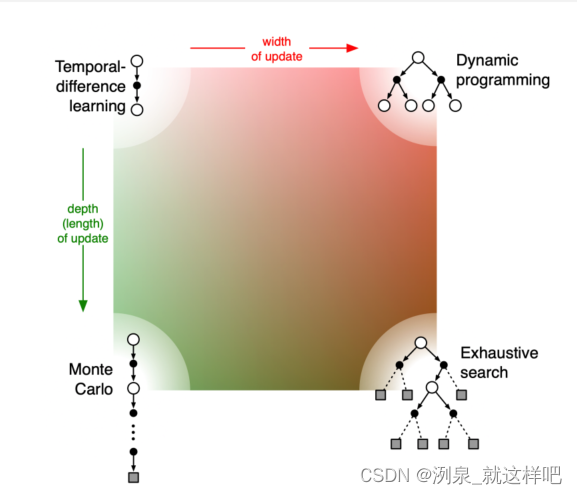
DP、MC、TD
- DP:bootstrap and no sampling,相当于广度优先,每个step都考虑当前最优(greedy learning)
- MC:sampling and no bootstrap,相当于深度优先,每次完成episode进行迭代
- TD:boostrap and samping ,相当于综合考虑广度和深度
- 完全搜索:完全采样,确定最优
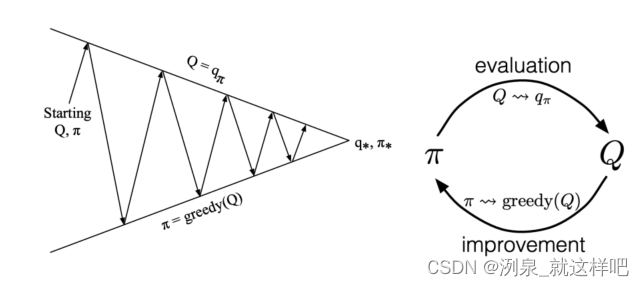
Model-free Control for MDP
基于policy iteration with action-value function进行推广
- policy evaluation:采用MC policy evaluation
- policy improvement:greedy policy improvement
ϵ \epsilon ϵ-Greedy Exploration
- trade-off exploration 和 exploitation
-
ϵ
\epsilon
ϵ就是有概率随机选择,而不会轻易陷入局部最优,跳出greedy
π ( a ∣ s ) = { ϵ / ∣ A ∣ + 1 − ϵ if a ∗ = arg max a ∈ A Q ( s , a ) ϵ / ∣ A ∣ otherwise \pi(a \mid s)=\left\{\begin{array}{ll} \epsilon /|\mathcal{A}|+1-\epsilon & \text { if } a^{*}=\arg \max _{a \in \mathcal{A}} Q(s, a) \\ \epsilon /|\mathcal{A}| & \text { otherwise } \end{array}\right. π(a∣s)={ϵ/∣A∣+1−ϵϵ/∣A∣ if a∗=argmaxa∈AQ(s,a) otherwise - 算法过程:

TD学习相对于MC学习的优点
- lower variance
- online
- incomplete sequences
Sarsa: on-policy TD control

包含两次action

Q-learning: Off-policy control
- 根据上一个状态和action确定最优的policy
π ( S t + 1 ) = arg max a ′ Q ( S t + 1 , a ′ ) \pi\left(S_{t+1}\right)=\underset{a^{\prime}}{\arg \max } Q\left(S_{t+1}, a^{\prime}\right) π(St+1)=a′argmaxQ(St+1,a′)
-
确定Q-learning的target
R t + 1 + γ Q ( S t + 1 , A ′ ) = R t + 1 + γ Q ( S t + 1 , arg max Q ( S t + 1 , a ′ ) ) = R t + 1 + γ max a ′ Q ( S t + 1 , a ′ ) \begin{aligned} R_{t+1}+\gamma Q\left(S_{t+1}, A^{\prime}\right) &=R_{t+1}+\gamma Q\left(S_{t+1}, \arg \max Q\left(S_{t+1}, a^{\prime}\right)\right) \\ &=R_{t+1}+\gamma \max _{a^{\prime}} Q\left(S_{t+1}, a^{\prime}\right) \end{aligned} Rt+1+γQ(St+1,A′)=Rt+1+γQ(St+1,argmaxQ(St+1,a′))=Rt+1+γa′maxQ(St+1,a′) -
Q-learning的迭代方程
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a\right)-Q\left(S_{t}, A_{t}\right)\right] Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]

Sarsa 和 Q-learning对比
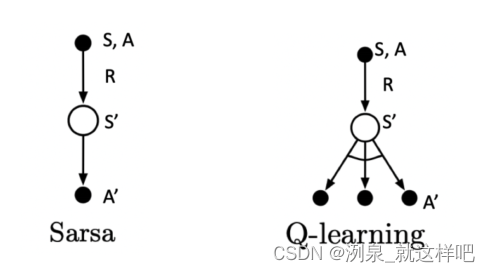
Sarsa是通过相同的采样进行action,两次的action是一样的,Q-learning是一次采样得到action,一次确定最优action,所以两次action不一样
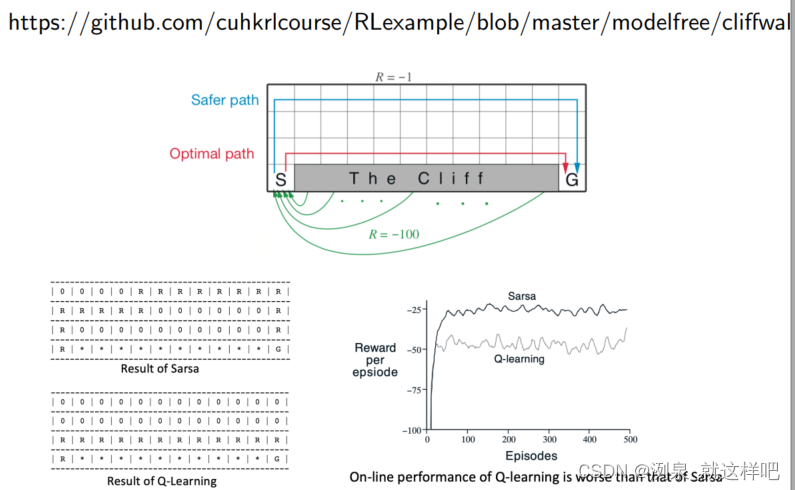
从例子中看出,Sarsa总是选择最安全的路径(保守而可行),而Q-learning是选择最佳的路径(冒险而最佳)
summary of DP和TD
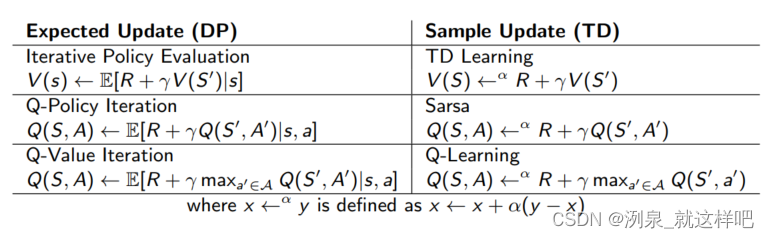















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









