






1 点云概述
随着3D采集技术的飞速发展,3D传感器成本逐步降低,得到更多的推广应用,包括各种类型的3D扫描仪、LiDAR和RGB-D相机(例如Kinect,RealSense和Apple深度相机)。这些传感器获取的立体数据可以提供丰富的几何信息(形状、大小、三维空间位置等)、特征信息(颜色、不透明率、反射率、反照率等)。与二维图像互补,立体数据可以更好地识别机器周围环境,捕捉目标细节信息,在不同领域具有众多应用,包括自动驾驶、机器人技术、遥感测绘、医学治疗和设计行业等。
点云是在三维空间中点集的定义,点云已经成为三维表示中最重要的数据格式之一,图1(a)和(b)是典型的点云数据集。3D点云是由一系列同时具有几何和特征信息的点组成,几何信息反应的是点在笛卡尔坐标系的位置(X,Y,Z),而特征信息可以描述每个点的视觉呈现,最常用的是用色彩值(RGB或YUV)来表示,并具有法向量信息(见图1(d)),还会考虑反射信息等。通常情况下,几何坐标是用浮点数表示的,但在大规模高密度点云压缩中,往往采用整数表示,目的是为了节省CPU计算时间和优化内存使用。因此,几何坐标需要进行基于整数规则网格的量化。整数表示法是压缩过程额外的限制,需要采用整数到整数的变换。传输比特率都在500 MB/s左右,说明应用高效压缩方法来处理复杂、高带宽数据的必要性。
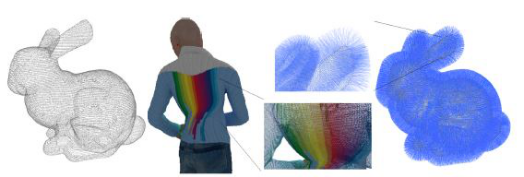
(a)斯坦福兔子 (b)queen数据集 (c)细节放大 (d)法向量
图1 点云数据示例
目前,点云处理的难点包括:一是点云的稀疏特点使得远处物体的点数量比近处物体少得多;二是点云的不规则性使得很难有效搜索临近点;三是纹理信息的缺失使得不同目标的识别区分较为困难,例如出现“三人成车”的错误现象;四是点云数据的无序性使得采用深度学习等工具进行分析十分困难,不同顺序的输入矩阵能得到完全不同的结果;五是点云数据的旋转不变性,由于点云数据表示的是三维物体,所有整体数据的旋转不会改变数据特征,但造成识别的困难性。
2 点云压缩方法标准
点云压缩(Point Cloud Compression,PCC),包括无损压缩和有损压缩。无损压缩通过消除统计冗余可以使得数据更紧凑,并完整保留原始信息。然而,有损压缩可以通过量化过程移除不必要的视觉冗余信息。不管采用哪种方式,都需要对数据进行去相关。最高级别描述的是冗余减少的维度,三种不同的模式包括:一维遍历、二维映射、三维去相关。第二级别呈现了几何和特征信息压缩,包括三种方法,即细节划分级别、聚类方法和基于变换的技术。前两级交错,第三级涉及处理几何信息的数据结构,这里可以考虑各种类型的基于树的表示,包括八叉树、二叉树和kd树。
目前ISO/IEC下属的工作组MPEG正在开展点云压缩标准化工作。关于PCC的讨论开始于2013年,一开始是关于处理沉浸式呈现,后来更多的数据和证据表明PCC的必要性,2015年开始进行探索性实验。使用的测试工具是Point Cloud Library (http://pointclouds.org),支持静态和动态点云对象,可以压缩几何和特征信息。前期通过确立了点云压缩技术在消费电子工业的需求,成立了MPEG-3DG工作组,并将点云压缩标准按处理方法划分为基于视频的点云压缩(Video-based Point Cloud Compression ,V-PCC)和基于几何的点云压缩(Geometry-based Point Cloud Compression,G-PCC)。
V-PCC旨在为需要实时解码的应用提供低复杂度的解码能力,如虚拟/增强现实、沉浸式通信等。V-PCC正在利用现有和未来的视频压缩技术,以及一般的视频生态系统(硬件加速、传输服务和基础设施),同时实现新型的应用模式。在第124届MPEG会议的参考模型编码器上,实现显示了125:1的压缩率,同时实现了良好的感知质量。2018年10月,V-PCC标准已进入委员会起草阶段。
G-PCC被认为可以为自主驾驶、3D地图和其他利用激光雷达生成的点云(或类似内容)的应用程序的部署提供高效的无损和有损压缩。G-PCC包中包括几种几何驱动方法。G-PCC标准已于2019年3月提升至委员会起草阶段。
3 基于视频的点云压缩(V-PCC)
V-PCC的整体框架如图2所示,类似于传统的三维视频,整体编码过程可分为四个步骤:补丁生成、几何/纹理图像生成、附加数据压缩和视频压缩。在视频压缩过程可以采用已发布的视频编码标准H.265/HEVC、H.266/VVC进行压缩。
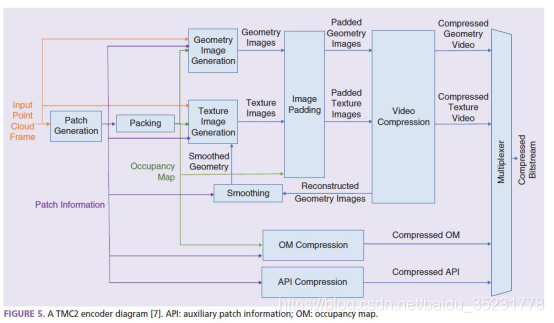
图2 V-PCC整体框架
V-PCC将输入点云分解为一组子图像(也称补丁)。首先,在局部平面近似的作用下,将法向量与每个点相关联。然后,在给定的搜索半径内,通过对具有相似方向(相对于给定阈值)的相邻点进行分组来确定点的初始聚类。在一定范围内对具有相似法向量的相邻点进行迭代更新,以获得平滑的聚类边界和最小化相关的映射失真。由于聚集在结果簇中的点具有相似的法向量,因此可以将参考方向与每个面片相关联,其对应于单个法向量的平均值。
完成了点云的分片之后,则将点云集正交投影到与参考法向量相对应的二维平面上。将投影平面按给定分辨率的规则采样,实现网格型的离散化,得到像素化的投影图像表示。深度和属性(颜色)信息都保留在生成的投影图像中。最后,通过在全局图像中嵌入正交投影的二维子图像生成几何和属性图像。这些补丁按大小降序填充到图像中。一旦填充了补丁,像素将被标记为“已占用”。利用二维子图像的边缘信息避免了子图像之间的交叉,同时最小化全局图像中子图像之间的空白。通过填充处理,可以获得更适合视频编码的具有更高时空一致性的平滑图像。

图3 V-PCC编码结果
V-PCC背后的主要原理是利用现有的视频编解码器压缩动态点云的几何和纹理信息,基本上是通过将点云转换成一组不同的视频序列来实现的。具体地说,两个视频序列,一个捕获几何信息,另一个捕获点云数据的纹理信息,使用现有的视频编解码器(如MPEG-4?AVC、HEVC、AV1等)生成和压缩。同时,编码两个视频序列所需的附加元数据,还包括生成和压缩占用地图和辅助补丁信息。然后将视频生成的比特流和元数据复用在一起,以生成最终点云V-PCC比特流。需要注意的是,元数据信息只占据总体比特流的相对较小的量(5-20%),大部分信息由视频编解码器处理。
4 基于几何的点云压缩(G-PCC)
如图4所示,首先是体素化过程,对输入的三维位置进行积分来得到位置表示,通过创建一个边界框来计算对象在所有xyz方向上的最大尺寸,然后将最大尺寸用作给定比特范围的最大值(即10位表示中的1023)。其次,是创建八叉树。八叉树非常适合于稀疏采样的点云,八叉树构建过程如图5所示。当完成了体素化,每个3D点(或位置)可以表示为八叉树中的叶节点。在这种情况下可以实现无损表示。对于有损压缩,叶节点可以是包含一个或多个点的大体素。图6是“斯坦福兔子”的体素化结果。八叉树形成后,每个含有一个或多个点的体素通过预测、变换和量化等常规压缩过程进行编码。最后,编码后的数据经过熵编码过程。

图4 G-PCC的几何信息编码过程
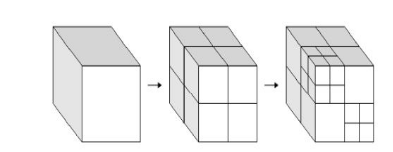
图5 G-PCC的八叉树生成过程
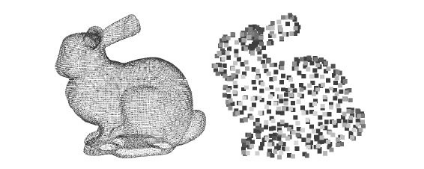
图6 原图与体素化结果对比
当几何体完成编码,就确定了编码所需的点数,需要根据编码的几何体选择适当数量的属性,因此,将几何体编码作为颜色编码过程的输入,如图7所示。如果几何体编码是无损的或接近无损的,则点的数目将保持与输入点云相同。因此,颜色重采样过程主要与颜色转换有关,例如,红色、绿色、蓝色(RGB)到YUV和YUV到RGB。如果几何体编码是有损的,则颜色重采样过程必须将一个或多个颜色值映射到一个颜色值。颜色重采样后,选定颜色值的处理顺序与几何体编码的顺序相同,几何体编码顺序由细节层次(LoD)生成重新计算。使用LoD,在每个层次上对点进行分组和排序,并且这个LoD生成过程将以相同的方式在解码器处重复进行,以确保颜色值与几何信息相匹配。如果要对颜色值进行编码,最好使用预测或变换来利用相邻颜色值之间的高相关性。
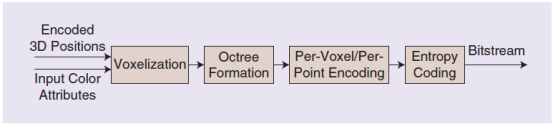
图7 G-PCC的颜色信息编码过程
5 发展趋势及应用前景
当前点云应用广泛,包括3D扫描和建模、环境监测、农林业、生医影像、CAD、自动驾驶等,随着压缩技术进步,未来可进一步应用于实时便携设备,实现自主导航、VR/AR等方面的应用。基于GPU的计算设备使得高密度的3D点云数据的实时获取和可视化得以实现。与3D网格相比,3D点云的优势是可以提供更简单、高密度、更接近实际的表示,但点云数据在拓扑和连续信息的缺失是主要的困难。同时,点云数据量巨大,需要有效的压缩方法来确保数据的存储和传输,包括几何和特征信息的提取。ISO/MPEG正在推进3D-PCC标准化进程。
目前,点云压缩的两个方向都具有前景,其中V-PCC可以利用现有的视频编码标准技术,实现点云压缩技术的快速实现,在不久的将来可以在消费电子行业、沉浸式多媒体上得到推广应用。G-PCC是对于点云数据进行更精细化操作和压缩,其计算量更大,但压缩性能和3D还原程度更好,适合于自动驾驶、机器人操作、医疗辅助等领域的应用,同样具有广阔前景。
6 参考文献
- [1] Gu S , Hou J , Zeng H , et al. 3D Point Cloud Attribute Compression Using Geometry-Guided Sparse Representation[J]. IEEE Transactions on Image Processing, 2019, 29(99):796-808.
- [2] Cao C , Preda M , Zaharia T . 3D Point Cloud Compression: A Survey[C]. The 24th International Conference on 3D Web Technology. 2019.
- [3] Schwarz S , Preda M , Baroncini V , et al. Emerging MPEG Standards for Point Cloud Compression[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2018:1-1.
- [4] Cui L , Xu H Y , Jang E S . Hybrid color attribute compression for point cloud data[C]. IEEE International Conference on Multimedia & Expo. IEEE, 2017.
- [5] Cui L , Mekuria R , Preda M , et al. Point-Cloud Compression: Moving Picture Experts Group’s New Standard in 2020[J]. Consumer Electronics Magazine, IEEE, 2019.
- [6] Xu Y , Wang S , Zhang X , et al. Rate-distortion optimized scan for point cloud color compression[C]. Visual Communications & Image Processing. IEEE, 2018.
- [7] Jang E S, Preda M, Mammou K, et al. Video-Based Point-Cloud-Compression Standard in MPEG: From Evidence Collection to Committee Draft [Standards in a Nutshell][J]. IEEE Signal Processing Magazine, 2019, 36(3):118-123.


















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









