







对抗样本
1.Biggio′s attack
Biggio[22]等人首先针对传统机器学习分类器(如SVM和三层全连接神经网络)的MNIST手写数字识别数据集生成对抗样本。
它通过优化判别函数来误导分类器。
2. Szegedy′s limited-memory BFGS (L-BFGS) attack
Szegedy[8]等人首次证明了可以通过对图像添加小量的人类察觉不到的扰动误导深度神经网络图像分类器做出错误的分类。他们首先尝试求解让神经网络做出误分类的最小扰动的方程。作者认为,深度神经网络所具有的强大的非线性表达能力和模型的过拟合是可能产生对抗性样本原因之一。
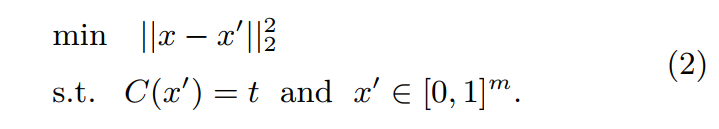
其中,x表示原始图像,x’表示添加微小扰动后的图片,x-x’则表示扰动大小,
∥
x
−
x
′
∥
2
2
\left\|x-x^{\prime}\right\|_{2}^{2}
∥x−x′∥22表示扰动的L2范数,C()是深度神经网络的分类器。
Szegedy等人引入损失函数,即寻找最小的损失函数添加项,使得神经网络做出误分类,这就将此问题转化成了凸优化过程。
min
c
∥
x
−
x
′
∥
2
2
+
L
(
θ
,
x
′
,
t
)
,
\min c\left\|x-x^{\prime}\right\|_{2}^{2}+\mathcal{L}\left(\theta, x^{\prime}, t\right), \quad
minc∥x−x′∥22+L(θ,x′,t), s.t.
x
′
∈
[
0
,
1
]
m
\quad x^{\prime} \in[0,1]^{m}
x′∈[0,1]m
L( , , )计算分类器的loss
3.Fast gradient sign method (FGSM)
Goodfellow等人[9]认为高维空间下深度神经网络的线性线性行为是导致该问题(存在对抗样本)的根本原因。提出了一种一步生成法来快速生成对抗样本,可以有效计算对抗扰动。
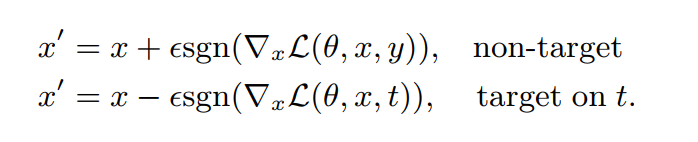
η
=
ε
sgn
(
∇
x
L
(
θ
,
x
,
t
)
)
\eta=\varepsilon \operatorname{sgn}\left(\nabla_{x} \mathcal{L}(\theta, x, t)\right)
η=εsgn(∇xL(θ,x,t))
x
x
x:原始图像
η
\eta
η:扰动
ε
\varepsilon
ε:表示控制扰动大小的自定义参数
L
\mathcal{L}
L:损失函数
sgn
\operatorname{sgn}
sgn:符号函数
FGSM的核心思想是:通过让扰动方向与梯度方向一致,使损失函数值变化最大,进而使分类器分类结果变化最大。sign函数保证了扰动方向与梯度方向一致;对损失函数求偏导。
FGSM 算法优点是只需一步迭代就能生成对抗样本,并且可以通过控制参数
ε
\varepsilon
ε生成任意
L
∞
L_{\infty}
L∞范数距离的对抗样本;缺点是扰动自身抗干扰能力不强,容易受到其他噪声的影响; 另外,模型损失函数与模型输入并不是完全线性的,这说明该算法生成的对抗样本扰动不是最优扰动。
4.DeepFool
Moosavi-Dezfooli 等人 [32] 通过迭代计算的方法生成能够使分类器模型产生误识别的最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。作者证明他们生成的扰动比 FGSM 更小,同时有相似的欺骗率。
Deepfool 算法生成对抗样本过程与使用 L-BFGS 生成对抗样本过程类似,主要区别是: Deepfool 算法每次迭代都计算当前样本和各决策边界的距离,然后选择向最近的决策边界迭代生成扰动。
5.Jacobian-based saliency map attack(JSMA)
基于雅可比矩阵的显着性图攻击(JSMA)[33]介绍了一种基于计分函数F的雅可比矩阵的方法。 通过迭代操纵对模型输出影响最大的像素,可以将其视为贪婪攻击算法。
对抗攻击文献中通常使用的方法是限制扰动的 L∞或 L2 范数的值以使对抗样本中的扰动无法被人察觉。但 JSMA[33] 提出了限制 L0 范数的方法,即仅改变几个像素的值,而不是扰动整张图像。
6.Basic iterative method (BIM)/Projected gradient descent (PGD) attack
针对 FGSM 算法存在的问题, Kurakin 等人[15,31]在 FGSM 算法基础上提出了一种以多步迭代的方式生成对抗样本的方法 BIM。
one-step 方法通过一大步运算增大分类器的损失函数而进行图像扰动,因而可以直接将其扩展为通过多个小步增大损失函数的变体,从而我们得到 Basic Iterative Methods(BIM)
7.Carlini & Wagner′s attack(CW)
Carlini 和 Wagner[36] 提出了三种对抗攻击方法,通过限制 L∞、L2 和 L0 范数使得扰动无法被察觉。实验证明 defensive distillation (防御性蒸馏)完全无法防御这三种攻击。该算法生成的对抗扰动可以从 unsecured 的网络迁移到 secured 的网络上,从而实现黑盒攻击。
C&W是一种基于目标函数优化的对抗样本攻击算法,其核心思想是:假设对抗样本是一个变量,那么要使其成功攻击分类器模型,必须满足两个条件, 一是其与原始样本的距离要尽可能的小,二是其能够误导分类器模型对其进行错误分类。
8.Ground truth attack
Carlini等人[35]试图找到可证明的最强攻击,即找到理论上最小失真的对抗样本的方法。
该攻击基于Reluplex [36],Reluplex是一种用于验证神经网络属性的算法。 它将模型参数F和数据(x,y)编码为线性编程系统的主体,然后求解该系统以检查在x’的邻居中是否存在可以欺骗模型的合格样本x’。 如果我们一直减小搜索区域的半径,直到系统确定不存在一个x’会欺骗模型,那么最后发现的对抗样本被称为标注的真实数据的对抗样本,因为事实证明它与x的相似性最小。
Ground truth攻击是计算分类器精确鲁棒性(最小扰动)的第一项工作。但是,该方法涉及使用可满足性模理论(SMT)求解器,(一种复杂算法, 用于检验一系列理论的可满足性),这将使其效率变慢并且无法扩展到大型网络。近期的研究工作[37,38]提高了 Ground truth攻击的效率。
附录(上述提到算法的论文)
- [22]B. Biggio, I. Corona, D. Maiorca, B. Nelson, N. Šrndić, P. Laskov, G. Giacinto, F. Roli. Evasion attacks against machine learning at test time. In Proceedings of European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, Prague, Czech Republic, pp.387–402, 2013. DOI: 10.1007/978-3-642-40994-3_25
- [8]C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus. Intriguing properties of neural networks. ArXiv: 1312.6199, 2013.
- [9]I. J. Goodfellow, J. Shlens, C. Szegedy. Explaining and harnessing adversarial examples. ArXiv: 1412.6572, 2014.
- [32]S. M. Moosavi-Dezfooli, A. Fawzi, P. Frossard. DeepFool:A simple and accurate method to fool deep neural networks. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Las Vegas, USA, pp.2574–2582, 2016. DOI: 10.1109/CVPR.2016.282.
- [33]N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B.Celik, A. Swami. The limitations of deep learning in adversarial settings. In Proceedings of IEEE European Symposium on Security and Privacy, IEEE, Saarbrucken, Germany, pp.372−387, 2016. DOI: 10.1109/EuroSP. 2016.36.

















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









