








Automatic segmentation of accumulated fluid inside the retinal layers from optical coherence tomography images
翻译:从光学相干断层扫描图像自动分割视网膜层内的积液
抽象的
视力障碍主要与视网膜疾病有关,例如青光眼,与年龄有关的黄斑变性,视网膜层内积液和其他疾病。为了评估与视网膜下积液有关的视力丧失,OCT图像得到了广泛使用。长期以来,从图像中视觉估计了受影响的视网膜节段。在本文中,我们提出了一种新颖的视网膜液自动检测(RFAD)算法,该算法可自动提取由于液体积聚而引起的受影响的视网膜节段,从而比通过适当的边缘检测更早地增加受影响区域的视觉影响。该方法针对25张OCT图像进行了定性和定量验证,包括正常和不同类型的异常情况。如结果部分所示,获得了良好的敏感性和特异性。


在OCT图像中(图2),可以看到视网膜内部的液体填充区域(如果有的话),因为与周围的视网膜组织相比,液体的光学散射较小。 但是,不能从光学快速外观中正确地测量出有效百分比。 为了防止由于视网膜内部的液体积聚而导致视力丧失[9,10],需要自动方法来识别视网膜色素上皮(RPE)和视网膜神经感觉层之间的液体区域。 这可以提供辅助诊断技术以及数字图像存储和分析的自动化。 已经提出了一些半自动化和自动化的方法,该方法使用眼部OCT图像来识别视网膜内部的液体填充区域,以增强眼科的临床设施。
以往大多数关于眼OCT图像的研究都是针对黄斑疾病[7]和CME评估[11,12]。先前在[13]中已经提出了一种涉及双边滤波和边界追踪的自动方法。使用特定于患者的SNR平衡技术来确保检测囊状液的一致性。该方法的处理时间相对较高,并且分割算法的准确性主要受SNR差的限制。 DCFernández等人[14]提出了一种半自动技术,通过使用非线性各向异性扩散滤波器消除强斑点噪声并分离患者视网膜结构中的液体填充区域,从而识别液体填充区域,但是对患者的视网膜结构进行了定量分析。没有提出该方法,并且该方法无法对OCT图像中不存在中心凹凹陷的视网膜层进行分割。在[15]中,报道了一种使用多尺度3D图形搜索技术根据视网膜内层的厚度和特征对视网膜内层进行分割的方法。这里介绍了光谱域OCT中正常黄斑区的表征。此外,从每个层中提取23个特征作为黄斑中与纹理和厚度相关的参数。但是这种方法既费时又繁琐,而且不是一种完全自动化的方法。此外,也没有有关SEAD(有症状的渗出液相关排列紊乱)量的信息。还提出了一种图形切割方法来识别视网膜的顶层和底层,并使用基于Split Bregman的分割方法提取出充满液体的区域[16]。为了区分真实的流体区域和错误检测的流体区域,使用了随机森林分类器。为了准确检测流体区域,根据用户在调用和精度之间的权衡取舍,可以选择任意值b。
在目前的工作中,提出了一种基于k最近邻(KNN)的提取和定量评估视网膜节段充液区域的新方法。基于KNN的聚类在预处理的图像上进行操作,以分离图像中的相似像素。然后,一种新的视网膜液自动检测(RFAD)算法被应用来从图像中分离出液体部分。下一节将详细说明整个方法,然后下一节将进行结果和定量分析。程序框及其各自的功能如图3所示。

2.方法论
提出的方法依次包括以下步骤:滤波,K-均值聚类,彩色图像到灰度图像的转换,查找OCT原始图像的视网膜内液(IRF)量,仅提取液部分,比较液具有真实流体部分和定量数据分析的部分。以上所有步骤均由图7中的流程图表示。这些OCT原始图像是使用Carl Zeiss stratus OCT收集的。
原始RGB图像通常包含在图像中产生颗粒状外观的脉冲椒盐噪声,这使得边缘检测变得困难。中值滤波[17]是一种非线性技术,它在去除盐和胡椒粉噪声的同时提供了非常有效的滤波,同时保留了边缘。在中值滤波中,窗口沿图像逐像素移动,并且根据强度对滑动窗口中的相邻像素进行排序,并且取决于窗口长度的像素的中值强度值成为的输出强度。正在处理的像素。因此,当二维滤镜窗口x(i,j)以图像坐标(i,j)为中心时,滤镜输出为:
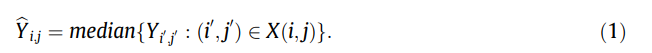
像传统的平滑滤波一样,中值滤波可使图像最平滑,这对于减少噪声很有用。与常规平滑滤波不同,任何类型的不连续性或边界信息都通过中值滤波保留在阶跃函数中,并且还替换了一些像素值与其周围环境明显不同的像素,而不会影响其他像素。
通过K均值聚类[18–20],我们将图像聚类为不同的组。图4显示了聚类或分段输出。在保留图像边缘时也很有用。 K均值聚类是一种将一组数据对象分组的技术。相似的数据对象属于同一群集,并且与其他群集中的对象不同。 K均值聚类是一种标准过程,用于通过迭代计算每个类别的平均强度并通过使用最接近的平均值对类别中的每个像素进行分类来对图像进行分割,从而进行聚类。在这里,我们选择K值为6作为参数。 K-means算法的工作原理如下。
。。。。
在OCT图像中,视网膜内液和视网膜外液(ORF)区域具有几乎相似的像素值。 在这里,K均值算法用于将IRF和ORF区域隔离到一个群集中。 这样,可以将感兴趣的区域(此处为IRF区域)分开。 分离方法已在下一节中介绍。
图4示出了聚类图像,该聚类图像标识了保持图像边缘的流体区域的边界。 该图还清楚地显示了A,B,C区域(在图4中标记)包含在单个群集中,其中A是IRF区域B。
2.1。 视网膜液自动检测(RFAD)算法
如下所述,使用独特的RFAD算法可以有效地发现IRF。 从图5可以清楚地看出,ORF和IRF的颜色是相同的。 但是,我们的利益全都集中在IRF地区。 因此,为了仅突出显示IRF区域,从点B或点C逐列扫描ORF区域的上部,直到达到不同的像素值(例如,第k列的点A),并且将像素值上移到点A (图5)。
一旦在列k中达到不连续点,它将停止扫描同一列的其余点,并跳到第(k +1)列。 重复此技术,直到扫描整个图像以获得较高的ORF。 该操作的顺序处理流程在图7的流程图中标记为“ 1”部分。对于较低的ORF,从点D或点E开始采用类似的方法。
最后,取决于OCT图像质量和聚类,可以将与IRF区域相邻的一些非IRF部分分类为流体累积部分。 可以通过使用适当的阈值来拒绝这些部分。 在这里使用一个固定的阈值,该阈值是通过反复试验方法选择的。 所提出的算法从宽度的最左端开始扫描,如果在任何特定位置的数组值(IRF像素值的出现次数)小于上述阈值,该算法会自动丢弃那些IRF区域以获得有效结果 如图8所示。[这些步骤在图7中显示为“ 5”部分]。














 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









