









mmdet2.7 doc
一、安装
略。
二、3种数据格式
1、CustomDataset
./mmdet/datasets/custom.py
ann_file可为pickle格式,即直接支持mmdet0.6中pickle格式的数据;
img_prefix为图片目录路径;
pipeline为数据增强管道;
初始化CustomDataset对象时,传入classes更新类属性CLASSES;
数据格式如下:
data/
train/# 训练图片
test/# 测试图片
train.pkl
test.pkl
class CustomDataset(Dataset):
Args:
ann_file (str): Annotation file path.
pipeline (list[dict]): Processing pipeline.
classes (str | Sequence[str], optional): Specify classes to load.
If is None, ``cls.CLASSES`` will be used. Default: None.
data_root (str, optional): Data root for ``ann_file``,
``img_prefix``, ``seg_prefix``, ``proposal_file`` if specified.
test_mode (bool, optional): If set True, annotation will not be loaded.
filter_empty_gt (bool, optional): If set true, images without bounding
boxes of the dataset's classes will be filtered out. This option
only works when `test_mode=False`, i.e., we never filter images
during tests.
"""
CLASSES = None
def __init__(self,
ann_file,
pipeline,
classes=None,
data_root=None,
img_prefix='',
seg_prefix=None,
proposal_file=None,
test_mode=False,
filter_empty_gt=True):
self.ann_file = ann_file
self.data_root = data_root
self.img_prefix = img_prefix
self.seg_prefix = seg_prefix
self.proposal_file = proposal_file
self.test_mode = test_mode
self.filter_empty_gt = filter_empty_gt
self.CLASSES = self.get_classes(classes)
2、XMLDataset
./mmdet/datasets/xml_style.py
继承CustomDataset类;
ann_file为txt格式的文件,txt中每一行为图片名(不含图片后缀);
load_annotations重写了父类加载数据的方法,只支持后缀为.jpg格式的图片;
数据集格式如下:
data/
JPEGImages/# jpg图片,包括训练和测试集
Annotations/# xml文件,包括训练和测试集
train.txt
test.txt
class XMLDataset(CustomDataset):
"""XML dataset for detection.
Args:
min_size (int | float, optional): The minimum size of bounding
boxes in the images. If the size of a bounding box is less than
``min_size``, it would be add to ignored field.
"""
def __init__(self, min_size=None, **kwargs):
super(XMLDataset, self).__init__(**kwargs)
self.cat2label = {cat: i for i, cat in enumerate(self.CLASSES)}
self.min_size = min_size
会自动过滤太小的目标,小目标检测需要注意修改这里;
会自动过滤不在CLASSES内的目标;
def _filter_imgs(self, min_size=32):
"""Filter images too small or without annotation."""
valid_inds = []
for i, img_info in enumerate(self.data_infos):
if min(img_info['width'], img_info['height']) < min_size:
continue
if self.filter_empty_gt:
img_id = img_info['id']
xml_path = osp.join(self.img_prefix, 'Annotations',
f'{img_id}.xml')
tree = ET.parse(xml_path)
root = tree.getroot()
for obj in root.findall('object'):
name = obj.find('name').text
if name in self.CLASSES:
valid_inds.append(i)
break
else:
valid_inds.append(i)
return valid_inds
可小改代码,采用如下格式更方便训练测试
data/
Images/# 所有图片和xml
train.txt# txt中每一行为图片名字,包括后缀,不限制为.jpg
test.txt具体修改如下
#filename = f'JPEGImages/{img_id}.jpg'
filename = img_id
#xml_path = osp.join(self.img_prefix, 'Annotations',
# f'{img_id}.xml')
xml_path = osp.join(self.img_prefix, f'{osp.splitext(filename)[0]}.xml')
VOCDataset继承XMLDataset,针对VOC数据集使用,可不考虑;
./mmdet/dataset/voc.py
3、COCODataset
./mmdet/dataset/coco.py
继承自
CustomDataset,重写了数据加载方式,过滤机制与XMLDataset相似;
数据格式为典型COCO格式,与mmdet0.6相同,如下:
data/
annotations/
train.json
test.json
train/JPEGImages
test/JPEGImages
4、小结
1.已有数据集格式为
pkl格式,可使用CustomDataset,无需修改;
2.已有数据集格式为coco格式,使用COCODataset,无需修改;
3.数据集格式为xml格式,(1)可使用
XMLDataset,小改代码后更方便训练(如果改,最好统一改);
(2)可使用bbox2mask脚本先转换为labelme格式,然后语义分割转实例分割,最后labelme2coco.py转为coco格式。
三、训练与测试
mmdet2.7中将配置文件按功能模块拆分开,使用的时候通过组合来自不同功能模块的配置,去生成一个完整的训练配置。
配置文件目录
configs/
_base_/# 数据、模型和学习率调度规则的基本配置
datasets/# 数据集配置文件
models/# 基础模型配置文件
schedules/# 学习率调度配置文件
default_runtime.py
cascade_rcnn/# 模型配置
vfnet/首次起训时,以
configs/cascade_rcnn/cascade_mask_rcnn_x101_32x4d_fpn_1x_coco.py为例,
其配置如下:_base_ = './cascade_mask_rcnn_r50_fpn_1x_coco.py' model = dict( pretrained='open-mmlab://resnext101_32x4d', backbone=dict( type='ResNeXt', depth=101, groups=32, base_width=4, num_stages=4, out_indices=(0, 1, 2, 3), frozen_stages=1, norm_cfg=dict(type='BN', requires_grad=True), style='pytorch'))
_base_为继承使用configs/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco.py的配置。
configs/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco.py配置如下,_base_ = [ '../_base_/models/cascade_mask_rcnn_r50_fpn.py', '../_base_/datasets/coco_instance.py', '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py']因此,模型、数据和学习率等配置信息去
_base_目录下相应位置修改。
启动训练之后,会在模型checkpoint目录(work_dir)下,保存完整的配置文件。
之后可以直接基于该配置去训练。
1、关键配置说明
(1)
DCN模块配置
==在mmdet2.7中==
# DCNv1
dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True))
# DCNv2
dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True))
==在mmdet0.6中,DCNv2等同于如下配置==
dcn=dict(
modulated=True,
groups=32,
deformable_groups=1,
fallback_on_stride=False),
stage_with_dcn=(False, True, True, True))
(2)
backbone
目前部分实验结果发现,res2net作为backbone效果比同深度resnext更好,其配置如下,
backbone=dict(type='Res2Net', depth=101, scales=4, base_width=26,
dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)),
(3)学习率与梯度裁剪
(a)mmdet2.7中模型训练对数据和配置更敏感,默认是不使用梯度裁剪的,但增加梯度裁剪会提高训练成功率…
(b)mmdet2.7中,初始学习率由使用GPU数和batch大小决定;
1GPU且batch_size为1,则学习率设置为0.02/16;
8GPU且batch_size为2则学习率设为0.02;
如果使用了梯度裁剪,则直接使用0.02也可能不会出现梯度消失或爆炸问题。
./configs/_base_/schedules/schedule_1x.py
# optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
==默认配置==
#optimizer_config = dict(grad_clip=None)
==更改如下,与mmdet0.6配置相似==
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
total_epochs = 12
2、开始训练
(1)训练脚本配置如下
mmdetection/train.sh
#!/usr/bin/env bash
# base config
#config=configs_retails/cascade_rcnn/cascade_rcnn_x101_32x4d_fpn_base.py
#config=configs_retails/cascade_rcnn/cascade_mask_rcnn_x101_32x4d_fpn_1x_coco.py
config=retails_configs/cascade_rcnn_x101_32x4d_fpn_voc_6.0.py
#config=configs_retails/cascade_mask_rcnn_x101_32x4d_fpn_1x_coco.py
# log
#log_dir=${work_dir}/bottle_mm2.7_20201225.log
#log_dir=${work_dir}/jingtian_mm2.7_20201226.log
log_dir=work_dir/.logtrain2
## 单卡训练
gpu_ids=2
#python tools/train.py $config --gpu_ids ${gpu_ids} --no-validate
#nohup python tools/train.py $config > $log_dir 2>&1 &
## 多卡训练
num_gpus=2
port=29505
launcher=pytorch
CUDA_VISIBLE_DEVICES=0,1
#python -m torch.distributed.launch --nproc_per_node=$num_gpus --master_port=$port tools/train.py $config --launcher $launcher
nohup python -m torch.distributed.launch --nproc_per_node=$num_gpus \
--master_port=$port tools/train.py $config --launcher $launcher \
> $log_dir 2>&1 &
tail -f $log_dir
(2)两种训练方式:
要么单卡训练,要么多进程多卡训练。不支持mmdet0.6多线程训练方式,起训之后如果要关掉训练,只能一个一个kill掉...
单卡训练与mmdet0.6相同,但mmdet2.7默认每个epoch都会测试评估验证集,如果嫌麻烦,加指令 --no-validate不测试。python tools/train.py $config --gpu_ids ${gpu_ids} --no-validate
多卡多进程训练,基于tools/dist_train.sh脚本进行训练,launcher方式为pytorch,每次训练要指定一个端口号master_port。python -m torch.distributed.launch --nproc_per_node=$num_gpus \ --master_port=$port tools/train.py $config --launcher $launcher
3、测试评估
(1)测试脚本内容如下
CONFIG=configs/cascade_mask_rio.py
CHECKPOINT=/data/hjzhen/data/rio/20210201_train/check_dir/latest.pth
GPUS=1
# mAP模式, 会打印出每个类的recall和ap,但没有precision。
# "bbox", "segm", "proposal" for COCO,
# and "mAP", "recall" for PASCAL VOC'
METRIC=bbox
export CUDA_VISIBLE_DEVICES=3
## 单卡测试
python tools/test.py $CONFIG $CHECKPOINT --eval $METRIC
## 多卡测试
PORT=${PORT:-29400}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/tools/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4} --eval $METRIC
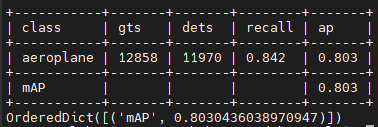
(2)对于xml或者pkl格式的数据集,使用mAP模式进行评估时,会打印出每一类的recall和ap;修改以下脚本后,可将precision指标也打印出来:
./mmdet/core/evaluation/mean_ap.py
def print_map_summary(...):
...
# mmdet2.7原代码
#header = ['class', 'gts', 'dets', 'recall', 'ap']
#for i in range(num_scales):
# if scale_ranges is not None:
# print_log(f'Scale range {scale_ranges[i]}', logger=logger)
# table_data = [header]
# for j in range(num_classes):
# row_data = [
# label_names[j], num_gts[i, j], results[j]['num_dets'],
# f'{recalls[i, j]:.3f}', f'{aps[i, j]:.3f}'
# ]
# table_data.append(row_data)
# table_data.append(['mAP', '', '', '', f'{mean_ap[i]:.3f}'])
# table = AsciiTable(table_data)
# table.inner_footing_row_border = True
# print_log('\n' + table.table, logger=logger)
# 修改后
header = ['class', 'gts', 'dets', 'recall', 'precision', 'ap']
for i in range(num_scales):
table_data = [header]
for j in range(num_classes):
row_data = [
label_names[j], num_gts[i, j], results[j]['num_dets'],
'{:.3f}'.format(recalls[i, j]), '{:.3f}'.format(
precisions[i, j]), '{:.3f}'.format(aps[i, j])
]
table_data.append(row_data)
table_data.append(['mAP', '', '', '', '', '{:.3f}'.format(mean_ap[i])])
table = AsciiTable(table_data)
table.inner_footing_row_border = True
print_log('\n' + table.table, logger=logger)
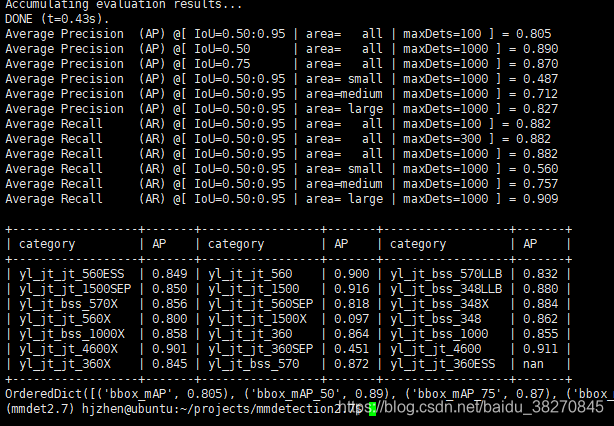
(3)对于coco格式的数据集,
./mmdet/dataset/coco.py
classwise为True时可将每一类的AP打印出来,
def evaluate(self,
results,
metric='bbox',
logger=None,
jsonfile_prefix=None,
classwise=False,
proposal_nums=(100, 300, 1000),
iou_thrs=None,
metric_items=None):
可在
./test.py中增加如下参数进行设置,
options='classwise=True'
python ./tools/test.py $config $checkpoint --options $options
输出如下
可在./mmdet/dataset/coco.py的evaluation函数中增加计算AP的功能。
if classwise: # Compute per-category AP
# Compute per-category AP
# from https://github.com/facebookresearch/detectron2/
precisions = cocoEval.eval['precision']
# precision: (iou, recall, cls, area range, max dets)
assert len(self.cat_ids) == precisions.shape[2]
results_per_category = []
for idx, catId in enumerate(self.cat_ids):
# area range index 0: all area ranges
# max dets index -1: typically 100 per image
nm = self.coco.loadCats(catId)[0]
precision = precisions[:, :, idx, 0, -1]
precision = precision[precision > -1]
# recall ...
if precision.size:
ap = np.mean(precision)
else:
ap = float('nan')
results_per_category.append(
(f'{nm["name"]}', f'{float(ap):0.3f}'))
num_columns = min(6, len(results_per_category) * 2)
results_flatten = list(
itertools.chain(*results_per_category))
mmdet2.7一个好处是更方便去测试评估了。
四、其他
1.将xml的bbox转为coco格式时,
segmentation属性可以为空,不影响训练;
也就是说所有bbox的数据都可以用coco格式来训练,方便统一训练测试流程…
# coco数据的一个实例目标
{
"id": 1521,
"image_id": 46,
"category_id": 15,
"segmentation": [], # 可为空,只训练bbox,不训练mask分支
"area": 1163.0,
"bbox": [
470.0,
349.0,
26.0,
48.0
],
"iscrowd": 0
}
2.
bbox_head+mask_head多任务组合对于模型训练比较友好,但训练好一个mask模型以后,可以不使用mask_head分支,而仅加载bbox_head分支进行推理,这样可快模型推理速度,减少部分显存(实际上服务中好像都没用到mask的输出…),且实验过模型精度不会受到影响。
只需要将config文件中的mask_roi_extractor和mask_head删除掉即可,即删除掉以下内容
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=80,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0)))














 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









