






2017马上就走啦。你好2018。
1.冒泡排序
冒泡排序的基本思想是:每次比较两个相邻的元素,如果它们的顺序错误就把它们交换过来。每次都是比较相邻的两个数,如果后面的数比前面的数大,则交换这两个数的位置。一直比较下去直到最后两个数比较完毕后,最小的数就在最后一个了。就如同是一个气泡,一步一步往后“翻滚”,直到最后一位。所以这个排序的方法有一个很好听的名字“冒泡排序”。
代码实现:for (int i=1; i<=n-1; i++)
for (int j=1; j<=n-i; j++)
if (a[j]<a[j+1])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
改进:设置一个布尔变量bo 来记录是否有进行交换。值为false表示本趟中进行了交换,true 则没有。代码如下:
int i=1;
do
{
bo=true;
for (int j=1; j<=n-i; j++)
if (a[j]<a[j+1])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
bo=false;
}
i++;
}
while (!bo);
冒泡排序的核心部分是双重嵌套循环。不难看出冒泡排序的时间复杂度是 O(N^2)。这是一个非常高的时间复杂度。冒泡排序早在 1956 年就有人开始研究,之后有很多人都尝试过对冒泡排序进行改进,但结果却令人失望。如 Donald E. Knuth(高德纳,1974 年图灵奖获得者)所说:“冒泡排序除了它迷人的名字和导致了某些有趣的理论问题这一事实之外,似乎没有什么值得推荐的。”
2.桶排序
桶排序的思想是若待排序的记录的关键字在一个明显有限范围内(整型)时,可设计有限个有序桶,每个桶装入一个值(当然也可以装入若干个值),顺序输出各桶的值,将得到有序的序列。
例:输入n个0到100之间的不相同整数,由小到大排序输出。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
int main()
{
int b[101],k,i,n;
memset(b,0,sizeof(b)); //初始化
scanf("%d",&n);
for( i=1; i<=n; i++)
{
cin>>k;
b[k]++; //将关键字等于k的值全部装入第k桶
}
for( i=0; i<=100; i++)
while (b[i]>0)
{
printf("%d ",i); //输出排序结果
b[i]--;
}
printf("\n");
}
3.选择排序
基本思想:每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在待排序的数列的最前,直到全部待排序的数据元素排完。
过程模拟:
初始关键字[49 38 65 97 76 13 27 49]
第一趟排序后 13 [38 65 97 76 49 27 49]
第二趟排序后 13 27 [65 97 76 49 38 49]
第三趟排序后 13 27 38 [97 76 49 65 49]
第四趟排序后 13 27 38 49 [76 97 65 49]
第五趟排序后 13 27 38 49 49 [97 65 76]
第六趟排序后 13 27 38 49 49 65 [97 76]
第七趟排序后 13 27 38 49 49 65 76 [97]
最后排序结果 13 27 38 49 49 65 76 97
代码实现:
void SelectSort(int R[]) //对R[1..n]进行直接选择排序
{
for(int i=1; i<=n-1; i++) //n - 1趟选择排序
{
K=i;
for(int j=i+1; j<=n; j++) //在当前无序区R[i..n]中选最小的元素R[K]
{
if(R[j]<R[K]) K=j;
}
if(K!=i) //交换R[i]和R[K]
{
Temp=R[i];
R[i]=R[K];
R[K]=Temp;
}
}
} //SelectSort
4.插入排序
插入排序是一种简单的排序方法,其算法的基本思想是:
假设待排序的数据存放在数组R[1..n]中,增加一个哨兵结点x。
(1) R[1]自成1个有序区,无序区为R[2..n];
(2) 从i=2起直至i=n为止,将R[i]放在恰当的位置,使R[1..i]数据序列有序;
① x:=R[i];
② 将x与前i-1个数比较, j:=i-1; whilex<a[j] do j:=j-1;
③ 将R数组的元素从j位置开始向后移动: for k:=i downto j do a[k]:=a[k-1];
④ R[j]=x;
(3) 生成包含n个数据的有序区。
例如:设n=8,数组R中8个元素是: 36,25,48,12,65,43,20,58,执行插入排序程序后,其数据变动情况:
第0步:[36] 25 48 12 65 43 20 58
第1步:[25 36] 48 12 65 43 20 58
第2步:[25 36 48] 12 65 43 20 58
第3步:[12 25 36 48] 65 43 20 58
第4步:[12 25 36 48 65] 43 20 58
第5步:[12 25 36 43 48 65] 20 58
第6步:[12 20 25 36 43 48 65] 58
第7步:[12 20 25 36 43 48 58 65]
代码实现:
void insertsort(int r[]) //对r[1..n]按递增序进行插入排序,x是监视哨
{
for(i=2; i<=n; i++) //依次插入r[2],...,r[n]
{
x=r[i];
j=i-1;
while(x< r[j]) //查找r[i]的插入位置//
{
r[j+1] =r[j]; //将大于r[i]的元素后移//
j--;
}
r[j+1]=x; //插入r[I] //
}
}
5.快速排序
快速排序是对冒泡排序的一种改进。它的基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。
代码看这里:http://blog.csdn.net/baidu_41248654/article/details/78698148
C++的STL(使用algorithm库中的sort函数):
#include<cstdio>
#include<algorithm>
int num[100010],n;
int main()
{
scanf("%d",&n);
for(int i=1; i<=n; i++)
scanf("%d",&num[i]);
sort(num+1,num+n+1);
for(int i=1; i<=n; i++)
printf("%d ",num[i]);
return 0;
}
6.归并排序
(来自http://blog.csdn.net/yuehailin/article/details/68961304)
基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序?可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
//将有二个有序数列a[first...mid]和a[mid...last]合并。
void mergearray(int a[], int first, int mid, int last, int temp[])
{
int i=first,j=mid+1;
int m=mid,n=last;
int k=0;
while(i<=m&&j<=n)
{
if(a[i]<=a[j])
temp[k++]=a[i++];
else
temp[k++]=a[j++];
}
while(i<=m)
temp[k++]=a[i++];
while(j<=n)
temp[k++]=a[j++];
for(i=0; i<k; i++)
a[first+i]=temp[i];
}
void mergesort(int a[], int first, int last, int temp[])
{
if (first<last)
{
int mid=(first+last) / 2;
mergesort(a,first, mid, temp); //左边有序
mergesort(a,mid+1, last, temp); //右边有序
mergearray(a,first, mid, last, temp); //再将二个有序数列合并
}
}
bool MergeSort(int a[], int n)
{
int *p=new int[n];
if (p==NULL)
return false;
mergesort(a,0,n-1,p);
delete[] p;
return true;
}
7.小结
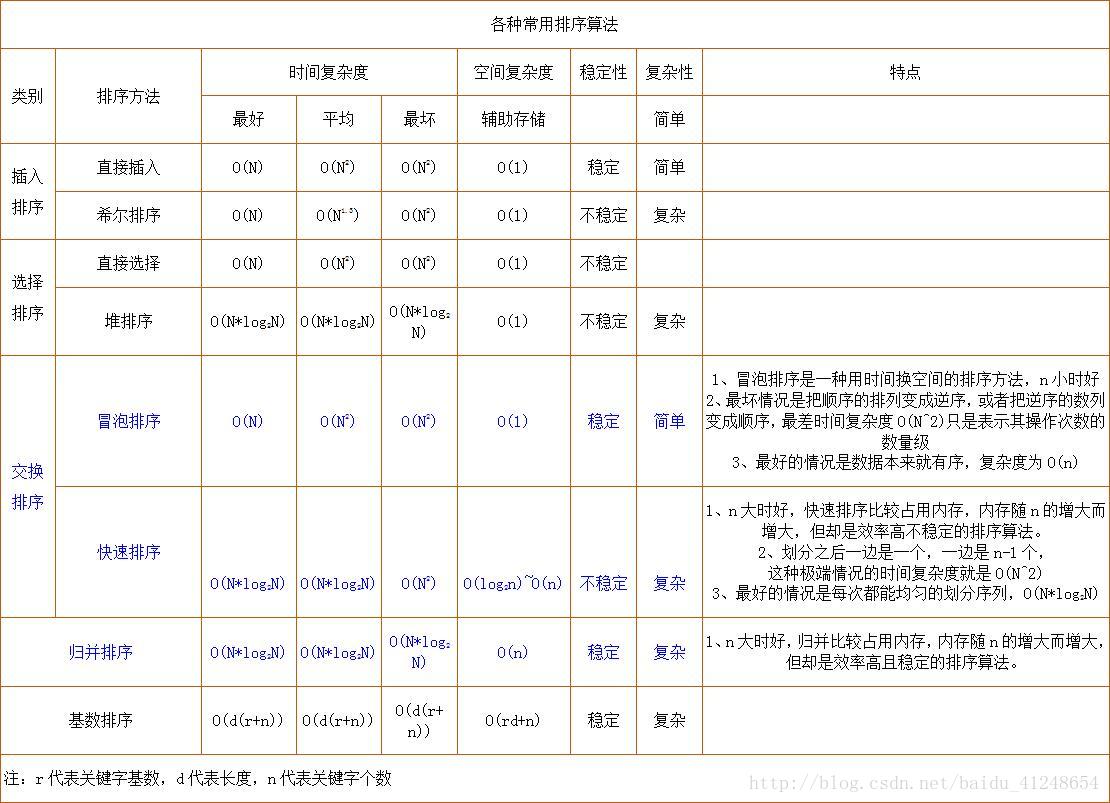
相关概念:注:1、归并排序每次递归都要用到一个辅助表,长度与待排序的表长度相同,虽然递归次数是O(log2n),但每次递归都会释放掉所占的辅助空间,2、快速排序空间复杂度只是在通常情况下才为O(log2n),如果是最坏情况的话,很显然就要O(n)的空间了。当然,可以通过随机化选择pivot来将空间复杂度降低到O(log2n)。
1、时间复杂度
时间复杂度可以认为是对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
常见的时间复杂度有:常数阶O(1),对数阶O(log2n),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n2)
时间复杂度O(1):算法中语句执行次数为一个常数,则时间复杂度为O(1),
2、空间复杂度
空间复杂度是指算法在计算机内执行时所需存储空间的度量,它也是问题规模n的函数
空间复杂度O(1):当一个算法的空间复杂度为一个常量,即不随被处理数据量n的大小而改变时,可表示为O(1)
空间复杂度O(log2N):当一个算法的空间复杂度与以2为底的n的对数成正比时,可表示为O(log2n)
ax=N,则x=logaN,
空间复杂度O(n):当一个算法的空间复杂度与n成线性比例关系时,可表示为0(n).














 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









