






前言
生成式人工智能(Generative AI)的热潮引发了广泛的兴趣,也将向量数据库(Vector Database)市场推向了风口浪尖,众多向量数据库产品开始崭露头角,走入了公众的视野。
根据 IDC 的预测,到 2025 年,超过 80% 的业务数据将呈现非结构化形式,以文本、图像、音频、视频或其他格式存储。然而,处理大规模的非结构化数据存储和查询面临着极大的挑战。
在生成式 AI 和深度学习领域,通常的做法是将非结构化数据转换为向量形式进行存储,并利用向量相似性搜索技术来进行语义相关性检索。而快速存储、索引和搜索嵌入向量(Embedding)正是向量数据库的核心功能。
那么,什么是嵌入向量(Embedding)呢?简单来说,嵌入向量是由浮点数构成的向量表征。两个向量之间的距离表示它们的相关性,距离越接近表示相关性越高,距离越远表示相关性越低。如果两个嵌入向量相似,那就意味着它们代表的原始数据也是相似的。这一点与传统的关键词搜索有很大不同。
但是向量数据库作为有状态的数据库产品,管理起来是复杂的,如果要在生产环境使用,也面临着跟传统的 OLTP 和 OLAP 数据库一样的问题,比如数据安全、高可用、垂直/水平扩展性、监控告警、备份恢复等等。**用户更关注大模型和向量数据库给业务带来的价值,而不是花费大量精力在管理大模型和向量数据库上,**并且向量数据库作为比较新的一类产品,很多用户缺乏相关的领域知识,也给大模型+向量数据库技术栈的落地带来了非常大的挑战。
实际上,这些挑战是普遍的,任何一款带状态的数据库产品都存在这些问题,为了解决这些问题,KubeBlocks 对数据库进行了统一抽象,基于 K8s 的声明式 API,实现了用一个 operator、一套 API 管理用户的各种数据库,极大地简化了管理负担。KubeBlocks 构建于 K8s 之上,天生支持多云,避免了被云厂商 lock-in 的风险。
EKS 是 AWS 提供的托管式 K8s 服务,它能够让我们轻松地在 AWS 上运行、扩展和管理 Kubernetes 集群,无需担心节点的部署、升级和维护。EKS 本身也是多可用区高可用部署,确保了集群在节点故障或可用区终端的情况下仍然可用。另外借助于 AWS 强大的资源池,我们可以在业务高峰和低谷时按需加减节点,充分保证了弹性和扩展性。
本文主要探讨如何基于 Amazon EKS 等服务通过 KubeBlocks 轻松部署和管理向量数据库。
架构说明
Kubernetes 已成为容器编排事实上的标准。它利用 ReplicaSet 提供的可扩展性和可用性以及 Deployment 提供的转出和回滚功能来管理数量不断增加的无状态工作负载。然而,管理有状态工作负载给 Kubernetes 带来了巨大的挑战。尽管 StatefulSet 提供了稳定的持久存储和唯一的网络标识符,但这些能力对于复杂的有状态工作负载来说还远远不够。为了应对这些挑战,解决复杂性问题,KubeBlocks 引入了 ReplicationSet 和 ConsensusSet,具有以下功能:
- 基于角色的更新顺序,减少了因升级版本、扩展和重启而导致的停机时间。
- 维护数据复制的状态并自动修复复制错误或延迟。
凭借 K8s 强大的容器编排能力,以及对数据库引擎的统一抽象,KubeBlocks具有如下优势:
- 多云兼容性,支持 AWS、GCP、Azure、阿里云等。
- 提供生产级性能、弹性、可扩展性和可观察性。
- 简化 day-2 运维操作,例如升级、扩容、监控、备份和恢复。
- 包含一个强大且直观的命令行工具。在几分钟内建立一个全栈、生产就绪的数据基础设施。
这使得我们可以非常方便快速地在 KubeBlocks 上构建大模型和向量数据库等 AIGC 基础设施。对新出现的数据库,也能非常快的接入,只需要定义 ClusterDefinition、ClusterVersion 等几个 CR,配置一下运维脚本、参数和监控面板,就可以在 KubeBlocks 拉起一个数据库集群,并且自动支持参数配置、垂直/水平扩缩容、升降级、备份恢复等能力。
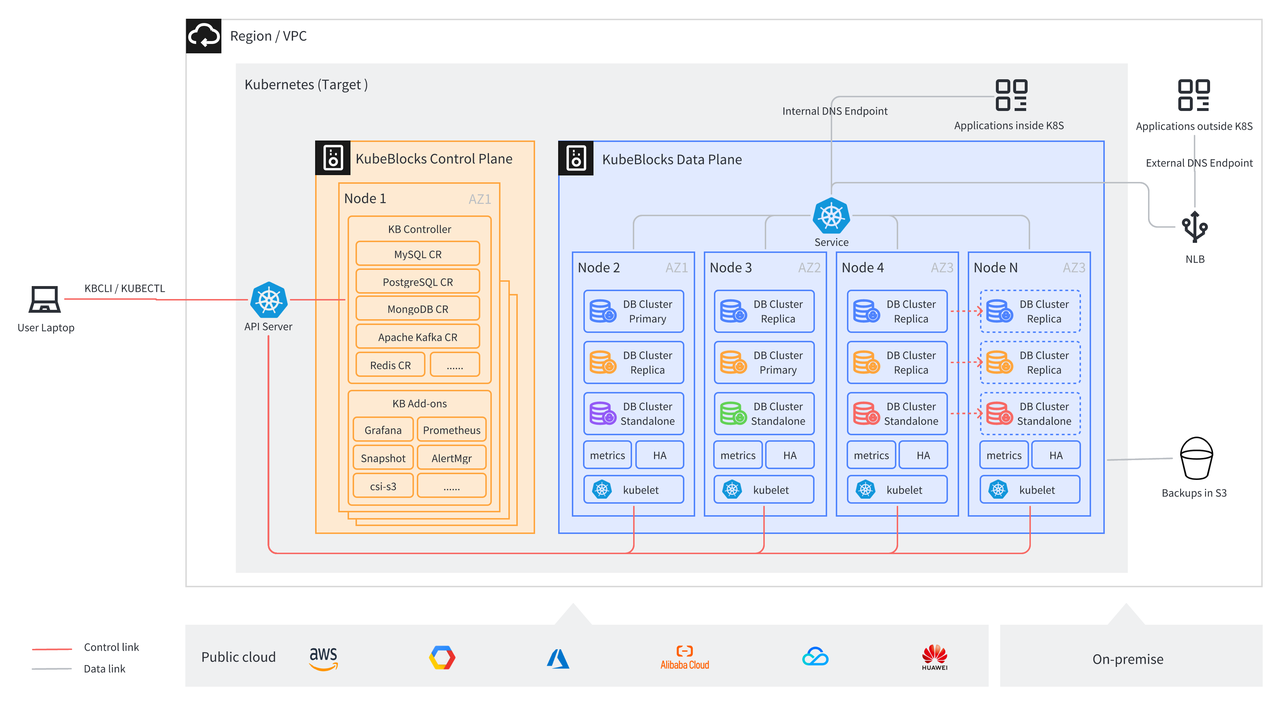
以下我们以 Qdrant 为例,介绍怎么在 AWS EKS 上,借助 KubeBlocks,拉起向量数据库。
Qdrant 是一个开源的向量数据库,它专注于高效地存储和查询高维向量数据,整体架构如下:

PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
},
"shard_number": 6,
"replication_factor": 2,
"write_consistency_factor": 2,
}
Qdrant 有如下几个特点:
-
存储引擎(Storage Engine):Qdrant 使用 RocksDB 作为其存储引擎。RocksDB 是一个高性能的键值存储引擎,它基于 LSM(Log-Structured Merge)树结构,提供了快速的写入和查询性能。
-
索引结构(Index Structure):Qdrant 使用了一种基于 MVP(Most Valuable Point)的索引结构,称为 HNSW(Hierarchical Navigable Small World)。HNSW 索引结构通过构建多层的图结构来组织向量数据,以便快速进行近似最近邻搜索。
-
向量编码(Vector Encoding):Qdrant 支持多种向量编码方法,包括 L2、IP、Cosine 等。这些编码方法用于将高维向量映射到低维空间,以便在索引结构中进行高效的相似度计算和搜索。
-
查询处理(Query Processing):Qdrant 使用多线程和并行计算来处理查询请求。它通过将查询向量与索引结构进行比较,并使用近似最近邻算法来找到最相似的向量。
-
分布式部署(Distributed Deployment):Qdrant 支持水平扩展和分布式部署。它可以在多个节点上进行数据分片和负载均衡,以提高存储容量和查询吞吐量。
总体而言,Qdrant 的架构设计旨在提供高效的向量存储和查询能力。它利用存储引擎、索引结构、向量编码和查询处理等技术来实现快速的近似最近邻搜索,适用于各种需要处理高维向量数据的应用场景。
ClusterDefinition
Qdrant 的 ClusterDefinition 定义如下,可以看到该 CR 定义了 Qdrant 的服务访问方式、监控指标采集路径、可用性探测方式等跟引擎密切相关的内容。
---
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ClusterDefinition
metadata:
name: qdrant
labels:
{{- include "qdrant.labels" . | nindent 4 }}
spec:
type: qdrant
# 定义对外服务的连接方式,包括链接地址,用户名,密码等信息,字段名和值可以根据引擎需要自行定义
connectionCredential:
username: root
password: "$(RANDOM_PASSWD)"
endpoint: "$(SVC_FQDN):$(SVC_PORT_tcp-qdrant)"
host: "$(SVC_FQDN)"
port: "$(SVC_PORT_tcp-qdrant)"
componentDefs:
- name: qdrant
workloadType: Stateful
characterType: qdrant
probes:
# 配置监控数据采集端口和地址,兼容prometheus协议
monitor:
builtIn: false
exporterConfig:
scrapePath: /metrics
scrapePort: 6333
logConfigs:
scriptSpecs:
- name: qdrant-scripts
templateRef: qdrant-scripts
namespace: {{ .Release.Namespace }}
volumeName: scripts
defaultMode: 0555
# 定义引擎配置模板,在运行时以volume的形式挂载到Pod容器内使用
configSpecs:
- name: qdrant-config-template
templateRef: qdrant-config-template
volumeName: qdrant-config
namespace: {{ .Release.Namespace }}
# 定义对外服务端口
service:
ports:
- name: tcp-qdrant
port: 6333
targetPort: tcp-qdrant
- name: grpc-qdrant
port: 6334
targetPort: grpc-qdrant
volumeTypes:
- name: data
type: data
# podSpec,和k8s原生pod.spec结构一致,定义容器启动命令,环境变量等信息
podSpec:
securityContext:
fsGroup: 1001
initContainers:
- name: qdrant-tools
command:
- /bin/sh
- -c
- |
cp /bin/jq /qdrant/tools/jq
cp /bin/curl /qdrant/tools/curl
imagePullPolicy: {{default .Values.images.pullPolicy "IfNotPresent"}}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /qdrant/tools
name: tools
containers:
- name: qdrant
imagePullPolicy: {{default .Values.images.pullPolicy "IfNotPresent"}}
securityContext:
runAsUser: 0
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: tcp-qdrant
scheme: HTTP
periodSeconds: 15
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
exec:
command:
- /bin/sh
- -c
- |
consensus_status=`/qdrant/tools/curl -s http://localhost:6333/cluster | /qdrant/tools/jq -r .result.consensus_thread_status.consensus_thread_status`
if [ "$consensus_status" != "working" ]; then
echo "consensus stopped"
exit 1
fi
failureThreshold: 2
initialDelaySeconds: 5
periodSeconds: 15
successThreshold: 1
timeoutSeconds: 3
startupProbe:
failureThreshold: 18
httpGet:
path: /
port: tcp-qdrant
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
lifecycle:
preStop:
exec:
command: ["/qdrant/scripts/pre-stop.sh"]
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /qdrant/config/
name: qdrant-config
- mountPath: /qdrant/storage
name: data
- mountPath: /qdrant/scripts
name: scripts
- mountPath: /etc/annotations
name: annotations
- mountPath: /qdrant/tools
name: tools
dnsPolicy: ClusterFirst
enableServiceLinks: true
ports:
- name: tcp-qdrant
containerPort: 6333
- name: grpc-qdrant
containerPort: 6334
- name: tcp-metrics
containerPort: 9091
- name: p2p
containerPort: 6335
command: ["/bin/sh", "-c"]
args: ["/qdrant/scripts/setup.sh"]
env:
- name: QDRANT__TELEMETRY_DISABLED
value: "true"
volumes:
- name: annotations
downwardAPI:
items:
- path: "component-replicas"
fieldRef:
fieldPath: metadata.annotations['apps.kubeblocks.io/component-replicas']
- emptyDir: {}
name: tools
ClusterVersion
Qdrant ClusterVersion 定义如下,这个 CR 定义了 Qdrant 的具体一个版本,如果有多个版本,每个版本对应一个 ClusterVersion 即可。
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ClusterVersion
metadata:
name: qdrant-{{ default .Chart.AppVersion .Values.clusterVersionOverride }}
labels:
{{- include "qdrant.labels" . | nindent 4 }}
spec:
clusterDefinitionRef: qdrant
componentVersions:
- componentDefRef: qdrant
versionsContext:
initContainers:
- name: qdrant-tools
image: {{ .Values.images.registry | default "docker.io" }}/{{ .Values.images.tools.repository }}:{{ default .Chart.AppVersion .Values.images.tools.tag }}
containers:
- name: qdrant
image: {{ .Values.images.registry | default "docker.io" }}/{{ .Values.images.repository}}:{{ default .Chart.AppVersion .Values.images.tag }}
操作说明
先决条件
- EKS 集群
- kubectl、Helm 客户端
安装
安装 kbcli
执行以下命令,安装最新版本的 kbcli。
curl -fsSL https://kubeblocks.io/installer/install_cli.sh | bash
安装 KubeBlocks
kbcli 安装完毕后,执行以下命令,安装对应版本的 KubeBlocks。
kbcli kubeblocks install
KubeBlocks 安装完毕后,需要启用 Qdrant add-on。
kbcli addon enable qdrant
创建
执行以下命令,创建单节点 Qdrant 集群。
kbcli cluster create qdrant --cluster-definition=qdrant
如果数据量比较大,也可以设置 replicas 参数,创建多节点 Qdrant 集群。
kbcli cluster create qdrant --cluster-definition=qdrant --set replicas=3
等待集群创建完成。
# 查看集群列表
~ kbcli cluster list
NAME NAMESPACE CLUSTER-DEFINITION VERSION TERMINATION-POLICY STATUS CREATED-TIME
qdrant default qdrant qdrant-1.1.0 Delete Running Aug 15,2023 23:03 UTC+0800
# 查看集群信息
~ kblci cluster describe qdrant
Name: qdrant Created Time: Aug 15,2023 23:03 UTC+0800
NAMESPACE CLUSTER-DEFINITION VERSION STATUS TERMINATION-POLICY
default qdrant qdrant-1.1.0 Running Delete
Endpoints:
COMPONENT MODE INTERNAL EXTERNAL
qdrant ReadWrite qdrant-qdrant.default.svc.cluster.local:6333 <none>
qdrant-qdrant.default.svc.cluster.local:6334
Topology:
COMPONENT INSTANCE ROLE STATUS AZ NODE CREATED-TIME
qdrant qdrant-qdrant-0 <none> Running <none> x-worker3/172.20.0.3 Aug 15,2023 23:03 UTC+0800
qdrant qdrant-qdrant-1 <none> Running <none> x-worker2/172.20.0.5 Aug 15,2023 23:03 UTC+0800
qdrant qdrant-qdrant-2 <none> Running <none> x-worker/172.20.0.2 Aug 15,2023 23:04 UTC+0800
Resources Allocation:
COMPONENT DEDICATED CPU(REQUEST/LIMIT) MEMORY(REQUEST/LIMIT) STORAGE-SIZE STORAGE-CLASS
qdrant false 1 / 1 1Gi / 1Gi data:20Gi standard
Images:
COMPONENT TYPE IMAGE
qdrant qdrant docker.io/qdrant/qdrant:latest
Data Protection:
AUTO-BACKUP BACKUP-SCHEDULE TYPE BACKUP-TTL LAST-SCHEDULE RECOVERABLE-TIME
Disabled <none> <none> 7d <none> <none>
Show cluster events: kbcli cluster list-events -n default qdrant
连接
Qdrant 提供 http 和 grpc 两种协议供客户端访问,端口分别为 6333 和 6334。接下来,我们看下怎么连接 Qdrant 集群。根据客户端在哪里,我们有几种不同的连接方案。
请注意,如果在 AWS 上,还需要先安装 AWS LoadBalancer Controller。
- 如果客户端在 K8s 集群内,那么可以直接用
kbcli cluster describe qdrant获取集群的 ClusterIP 连接地址或者对应 K8s 集群内域名。 - 如果客户端在 K8s 集群外,但是和 Server 在同一个 VPC 中,那么可以执行命令
kbcli cluster expose qdant --enable=true --type=vpc,为数据库集群获取一个 VPC LB 地址。 - 如果客户端在 VPC 之外,那么可以执行命令
kbcli cluster expose qdant --enable=true --type=internet,为数据库集群开放一个公网可达的地址。
测试
向 Qdrant 集群中插入数据,首先需要创建一个 Collection,命名为 test_collection,向量维度为 4,采用 Cosine 余弦距离计算相似度。
curl -X PUT 'http://localhost:6333/collections/test_collection' \
-H 'Content-Type: application/json' \
--data-raw '{
"vectors": {
"size": 4,
"distance": "Cosine"
}
}'
返回结果。
{"result":true,"status":"ok","time":0.173516958}
执行以下命令,查看刚创建的 collection 的信息。
curl 'http://localhost:6333/collections/test_collection'
返回结果。
{
"result": {
"status": "green",
"optimizer_status": "ok",
"vectors_count": 0,
"indexed_vectors_count": 0,
"points_count": 0,
"segments_count": 2,
"config": {
"params": {
"vectors": {
"size": 4,
"distance": "Cosine"
},
"shard_number": 1,
"replication_factor": 1,
"write_consistency_factor": 1,
"on_disk_payload": true
},
"hnsw_config": {
"m": 16,
"ef_construct": 100,
"full_scan_threshold": 10000,
"max_indexing_threads": 0,
"on_disk": false
},
"optimizer_config": {
"deleted_threshold": 0.2,
"vacuum_min_vector_number": 1000,
"default_segment_number": 0,
"max_segment_size": null,
"memmap_threshold": null,
"indexing_threshold": 20000,
"flush_interval_sec": 5,
"max_optimization_threads": 1
},
"wal_config": {
"wal_capacity_mb": 32,
"wal_segments_ahead": 0
},
"quantization_config": null
},
"payload_schema": {}
},
"status": "ok",
"time": 1.9708e-05
}
然后我们往 collection 里插入一些数据。
curl -L -X PUT 'http://localhost:6333/collections/test_collection/points?wait=true' \
-H 'Content-Type: application/json' \
--data-raw '{
"points": [
{"id": 1, "vector": [0.05, 0.61, 0.76, 0.74], "payload": {"city": "Berlin" }},
{"id": 2, "vector": [0.19, 0.81, 0.75, 0.11], "payload": {"city": ["Berlin", "London"] }},
{"id": 3, "vector": [0.36, 0.55, 0.47, 0.94], "payload": {"city": ["Berlin", "Moscow"] }},
{"id": 4, "vector": [0.18, 0.01, 0.85, 0.80], "payload": {"city": ["London", "Moscow"] }},
{"id": 5, "vector": [0.24, 0.18, 0.22, 0.44], "payload": {"count": [0] }},
{"id": 6, "vector": [0.35, 0.08, 0.11, 0.44]}
]
}'
返回结果。
{
"result": {
"operation_id": 0,
"status": "completed"
},
"status": "ok",
"time": 0.040477833
}
接下来测试一下搜索刚刚插入的数据,比如搜索跟向量[0.2,0.1,0.9,0.7]相似的数据。
curl -L -X POST 'http://localhost:6333/collections/test_collection/points/search' \
-H 'Content-Type: application/json' \
--data-raw '{
"vector": [0.2,0.1,0.9,0.7],
"limit": 3
}'
返回结果。
{
"result": [
{
"id": 4,
"version": 0,
"score": 0.99248314,
"payload": null,
"vector": null
},
{
"id": 1,
"version": 0,
"score": 0.89463294,
"payload": null,
"vector": null
},
{
"id": 5,
"version": 0,
"score": 0.8543979,
"payload": null,
"vector": null
}
],
"status": "ok",
"time": 0.003061
}
搜索时,还可以添加额外的元数据过滤条件,比如在 city 等于 London 的点中,查找跟向量[0.2,0.1,0.9,0.7]相似的数据。
curl -L -X POST 'http://localhost:6333/collections/test_collection/points/search' \
-H 'Content-Type: application/json' \
--data-raw '{
"filter": {
"should": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}'
返回结果。
{
"result": [
{
"id": 4,
"version": 0,
"score": 0.99248314,
"payload": null,
"vector": null
},
{
"id": 2,
"version": 0,
"score": 0.66603535,
"payload": null,
"vector": null
}
],
"status": "ok",
"time": 0.012462584
}
扩容
如果创建集群选择的是单节点,后来发现容量不够,需要扩容,KB 也是支持的,可以垂直扩容,也可以水平扩容。
我们先看垂直扩容,即增加 cpu 和 memory 资源,执行以下命令。
kbcli cluster vscale qdrant --components qdrant --cpu 8 --memory 32Gi
如果垂直扩容已经到了机器上限,我们还可以水平扩容增加节点,比如从单节点,扩容到 3 节点,执行以下命令。
kbcli cluster hscale qdrant --replicas 3
磁盘扩容
如果磁盘空间不足了,可以通过kbcli对磁盘进行扩容。
kbcli cluster volume-expand qdrant --components postgresql --storage=50Gi --volume-claim-templates=data
启停
对于开发测试环境的集群,有时候不用了,希望能暂时释放计算资源,但是保留存储,可以通过如下命令,停止集群的所有 pod。
kbcli cluster stop qdrant
当有需要时,可以执行如下命令,重新启动集群。
kbcli cluster start qdrant














 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









