






本文作者:于雨
目前任职于 360 智汇云云平台基础架构部,dubbogo 社区负责人, OpenAtomFoundation/pika 项目负责人,前蚂蚁集团 seata 项目负责人。从业⼗四年来⼀直在服务端基础架构工作,热爱开源,陆续参与和改进过 Redis/Pika/Muduo/dubbo/dubbo-go/Sentinel-golang/Seata-go 等知名项⽬。先后荣获诸多荣誉,阿⾥ 2021 年开源先锋⼈物,2022 开放原子全球开源峰会 “代码贡献之星” ,2022 年度 "OSCAR 尖峰开源人物”,代表作 dubbo-go 荣获 2021年科创中国 “年度优秀开源产品” 大奖。
过去有很多小伙伴一直很好奇 KubeBlocks 如何帮助数据库轻松上云,今天小猿姐邀请了来自 PikiwiDB 的小伙伴于雨来给大家手把手教学,一起来看 PikiwiDB 如何借助 KubeBlocks 的经验和抽象能力,在云环境中实现高效、便捷的部署和管理。
过去有很多小伙伴一直很好奇 KubeBlocks 如何帮助数据库轻松上云,今天小猿姐邀请了来自 PikiwiDB 的小伙伴于雨来给大家手把手教学,一起来看 PikiwiDB 如何借助 KubeBlocks 的经验和抽象能力,在云环境中实现高效、便捷的部署和管理。
1 PikiwiDB(原 Pika) 介绍
PikiwiDB(原 Pika) 是一个以 RocksDB 为存储引擎的的大容量、高性能、兼容 Redis 协议、数据可持久化的弹性 KV 数据存储系统,支持 Redis 常见数据结构,如 string/hash/list/zset/set/geo/hyperloglog/pubsub/bitmap/stream 等。
当 Redis 内存使用超过阈值(例如 16GiB)时,会面临内存容量有限、单线程阻塞、启动恢复时间长、内存硬件成本贵、缓冲区容易写满、一主多从故障时切换代价大等问题。PikiwiDB(原 Pika) 力求在完全兼容 Redis 协议、继承 Redis 便捷运维设计的前提下,通过持久化存储的方式解决了 Redis 一旦存储数据量巨大就会出现内存容量不足的瓶颈问题,并且可以像 Redis 一样,支持使用 slaveof 命令实现主从模式,还支持数据的全量同步和增量同步。还可以用 twemproxy or Codis 实现静态数据分片。
PikiwiDB(原 Pika) 作为现代数据库,积极迎合云计算趋势,追求分钟级交付、极大容量、极高性能、极致弹性以及云平台提供的数据稳定性和安全性。在实现这些能力的探索中,借助 KubeBlocks,我们更轻松地解决了云化过程中遇到的问题。
为了更好地理解这些问题,让我们从简要介绍 PikiwiDB(原 Pika) 集群架构开始。
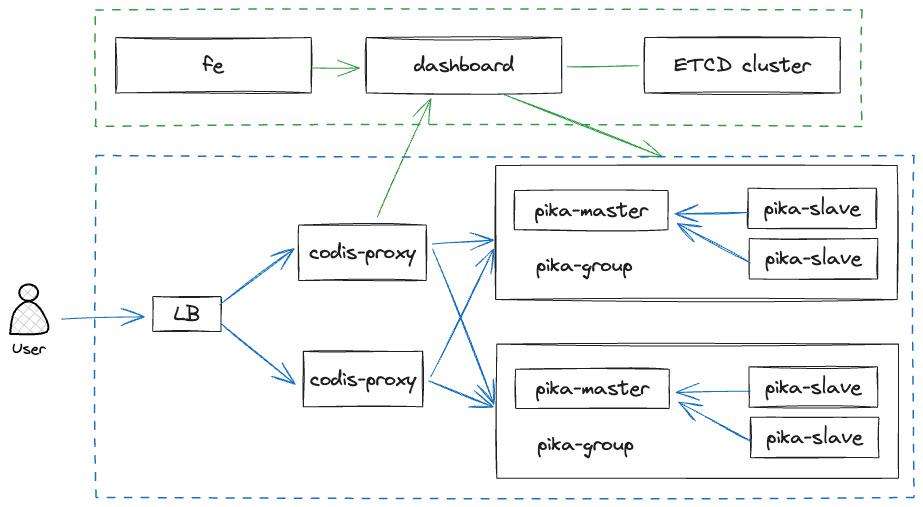
PikiwiDB(原 Pika) 集群采用 Codis 的方案,包括控制面和数据面。控制面有前端 fe、控制中心 dashboard 以及存储配置信息的 ETCD 集群。数据面有用于分发数据的代理 proxy 和 PikiwiDB(原 Pika) 主从实例。每组主从实例形成一个 group,相当于一个分片,由 dashboard 管理。PikiwiDB(原 Pika) 社区对 Codis 进行改造,如为了减少组件,将高可用组件 Redis-Sentinel 融合至 dashboard 中。
2 关键改进
在云化过程中,我们面临诸多挑战,首要问题是集群模型的抽象。
2.1 集群抽象
整个集群组件繁多,无论是部署维护还是简单试用,这种复杂度会让人望而却步。将集群部署到 Kubernetes 中,直接使用 StatefulSet 等对象难以满足 PikiwiDB(原 Pika) 集群对状态管理的需求。其中大量地址和变量需要管理,即便使用 Helm 也需花费较长时间调试上线。
社区曾尝试为 PikiwiDB(原 Pika) 开发 operator 以实现快速部署,但在将有状态集群抽象成简单配置的过程中遇到了困难,进展缓慢。容器有许多固定和可变参数,如 Volume、mount 地址、PVC 的 storage class 等。在将一完整 YAML 抽象成可重复部署、可多环境部署的 Helm 时,会遇到很多这种问题,如何将不同的参数,抽象至不同的层,需要平衡灵活性和易用性。
在探索调研中,于 2023 年 6 月正式开源的 KubeBlocks 吸引了我们的注意:
KubeBlocks 是一个基于 Kubernetes 的云原生数据管理平台,旨在为用户提供一种便捷的方式来管理和运维关系型数据库、NoSQL 数据库、向量数据库以及流计算系统。KubeBlocks 的名字来源于 Kubernetes 和 LEGO 积木,这表明在 Kubernetes 上构建数据库和分析型工作负载既高效又愉快,就像玩乐高玩具一样。
KubeBlocks 将顶级云服务提供商的大规模生产经验与增强的可用性和稳定性改进相结合,帮助用户轻松构建容器化、声明式的关系型、NoSQL、流计算和向量型数据库服务。
KubeBlocks 还具有以下优势:不必学习数据库调优,充分利用存储和计算资源,实现最佳数据库性能;在节点或可用区级别提供容错能力,确保数据丢失或服务中断的风险降到最低。
起初我们只是想学习一下,然后完善自己的 operator。但调研完毕后,发现 KubeBlocks 团队将云厂商经验融入软件中,提供了在 Kubernetes 上抽象有状态集群的解决方案,更了解到 KubeBlocks 背后的团队是原 PolarDB 创始团队后,我们决定直接放弃自己的 operator,完全采用 KubeBlocks 实现 PikiwiDB(原 Pika) 集群的云原生化。通过借助其经验和抽象能力,我们轻松实现了各个组件的云化部署。

KubeBlocks 将集群分为三层:细粒度的组件 Component、集群定义 ClusterDefinition、集群实例配置 Cluster。它将分布式模型、配置、脚本、存储、监控、备份等功能抽象至不同层,使集群能够良好映射至 Kubernetes。KubeBlocks Addon 支持多种扩展方式,目前主流的扩展方式是 Helm。创建集群的 Helm Chart,PikiwiDB(原 Pika) 基本上只用按照 KubeBlocks 的定义给出各个组件的 YAML 文件即可,用一个集群 YAML 模板文件用来定义集群拓扑、组件配置和组件启动脚本,即可迅速拉起一个集群。
目前所有 Pika YAML 文件都在 https://github.com/OpenAtomFoundation/pika/tree/unstable/tools/kubeblocks_helm 放着,按照 Readme 文档即可迅速实现集群的部署以及集群的扩容。
KubeBlocks 内建的许多功能也为后续的完善提供了很好的思路,随着其发版更新,我们社区会及时跟进。
2.2 状态管理
YAML 文件只是在 Kubernetes 上部署了一个 PikiwiDB(原 Pika) 集群,但 PikiwiDB(原 Pika) 作为一个数据库,是一个有状态的集群,所以 Operator 还需要维护集群的状态。为了说明问题,让我们简要介绍一下 PikiwiDB(原 Pika) 集群的 slot 管理。

Codis 将整个集群以 Slot 为单位分成 1024 个 Slots,PikiwiDB(原 Pika) 对 Slot 数量进行了扩容,原理相似。每组 Pika-group 存储不同的 Slots,Slots 的 index 存储在 dashboard 中。proxy 从 dashboard 获取 Slots 的 Index,当用户请求到达 proxy 时,它会根据 Slots 的 index 路由请求。
对 PikiwiDB(原 Pika) 集群进行扩容时,需要按一定顺序执行:
- 增加新的 group;
- 等组创建完成后,通知 dashboard 进行 slot 搬迁。
在缩容时也需要进行反向操作,先搬迁,待搬迁完成后再进行缩容,以避免数据损失。
只使用 Kubernetes 本身的机制,很难实现这样的操作。例如,在整个 PikiwiDB(原 Pika) 主从实例组全部正常运行后,再使用某种机制调用 dashboard 进行扩容。而使用 KubeBlocks,只需在 Component 中添加一个 postStartSpec。创建完成 group 后,KubeBlocks 触发一个 Job 执行后续任务,整个过程非常优雅。
2.3 功能验证
本节给出一个实操流程,以 step by step 的方式,详述如何在 macOS 上部署一个可在 Kubernetes 上运行的 PikiwiDB(原 Pika) 集群。
- 启动 Docker
open -a Docker
- 部署 k8s 集群 (以 KIND 替代)
brew install kind
kind create cluster
- 安装 KubeBlocks
curl -fsSL https://kubeblocks.io/installer/install_cli.sh | bash # 下载 kbcli
kbcli kubeblocks install --version 0.5.3 -v1 # 下载 kubeBlocks
kbcli kubeblocks status # 检查 KubeBlocks 状态
- 部署集群
cd ./tools/kubeblocks-helm/ # https://github.com/OpenAtomFoundation/pika/tree/unstable/tools/kubeblocks_helm
helm install pika ./pika # 下载 Pika
helm install pika-cluster ./pika-cluster # 部署 cluster
kubectl get pods --all-namespaces -o wide # 查看 cluster 状态,或者使用命令 kubectl get cluster --watch
- 访问集群
kubectl port-forward svc/pika-cluster-codis-fe 8080 # 访问 codis-fe,转发暴露 codis-fe 到 8080 端口
kubectl port-forward svc/pika-cluster-codis-proxy 19000 # 连接到 proxy 访问 pika-cluster
redis-cli -p 19000 # 连接到 codis
kbcli cluster hscale pika-cluster --replicas 4 --components pika # 水平扩容增加 2 个 Pika 实例
3 下一站
基于 KubeBlocks 的 Operator 帮助 PikiwiDB(原 Pika) 集群实现了上云以及节点的扩容,但上 K8s 仅仅是云化的初步 – 上云,要实现一个云原生的 PikiwiDB(原 Pika) 集群,还需要对 PikiwiDB(原 Pika) 进行架构改造,才能为用户提供更加灵活、按需的数据库服务,提高资源利用率,使用户无需关心底层基础设施的维护和管理。
PikiwiDB(原 Pika) 云化关键技术点如下:
1. 存储结构
目前 PikiwiDB(原 Pika)的数据存储结构包括以下几个方面:
- 使用 RedisCache 在内存中缓存热数据,以提高读取效率。
- 使用 RocksDB Block Cache 缓存温数据,以实现更高效的读取操作。
- 关闭 RocksDB 的 Write-Ahead Log (WAL),保留 binlog 机制,并将 RocksDB WAL kPointInTimeRecovery 级别崩溃恢复机制加到 binlog 上,以确保数据安全性。
- 使用位于 SSD 磁盘上的 binlog 作为主从同步缓存,确保数据同步的可靠性。
- 使用 SSD 磁盘进行持久化存储,以保证全量数据的长期保存。
进一步改进方向:
- 保留 RedisCache 和 RocksDB Block Cache 作为读缓存。
- 将 binlog 以多副本方式存储存入一个日志型数据库作为写缓存。
- 引入一个独立的 Page Server,负责从日志型数据库消费 binlog 然后进行物化,将物化后的数据存储到 S3,同时充当作为 PikiwiDB(原 Pika) 的读缓存。
这一方案可以保证数据的最终一致性,适用于 group 内 slave 节点的极速启动,对 slot 数据进行快速 rebalance,因为只需重新重放部分 binlog record 即可。
2. 状态管理
目前的 Operator 仅实现了 Shard 的 Scale Out 功能,尚未完全支持 Scale In。在执行 Scale In 操作时,首先禁用槽位(Slot)的重新平衡(slot rebalance),接着进行槽位的移出(slot move out),然后逐步减少 Shard 的数量,最终再启用槽位的重新平衡。这一流程确保了在减少 Shard 的过程中不会导致数据不一致,有效管理集群规模的动态变化。
还需要实现一个独立的可在多云环境运行的 etcd manager,以探针方式监控每个 etcd cluster manager,管理一个健康的 etcd 集群。
3. 可观测性
将 PikiwiDB(原 Pika)集群的监控组件 pika-exporter 在 Operator 中进行集成,以实现该组件的高可用性。
4. 数据备份
首先,我们计划使各个组件能够独立配置存储,以提高系统的灵活性和可定制性。其次,我们着手实现集群数据备份,以确保数据的安全性和可恢复性。随后,我们将推动 Operator 实现集群从备份拉起的功能,从而降低系统维护的复杂性。最后,我们将专注于实现集群恢复备份的流程,以更加高效地应对潜在的系统故障。
4 结语
KubeBlocks 团队和 PikiwiDB(原 Pika)社区一起通过基于 KubeBlocks 的 PikiwiDB(原 Pika)云化探索,我们不仅实现了 PikiwiDB(原 Pika)在云环境中更高效、便捷的部署和管理,同时为 PikiwiDB(原 Pika)的未来发展提供了新的可能性。
这一深度的探讨不仅解决了云化过程中的难题,也为 PikiwiDB(原 Pika)社区的用户提供了更好的使用体验。欢迎试用我们的云化方案,也诚邀 PikiwiDB(原 Pika)社区的用户积极参与共建,共同推动 PikiwiDB(原 Pika)在云计算时代的发展。















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









