







背景
Pod 删除时卡在 Terminating 是一个偶发但几乎每个 K8s 玩家都遇到过的问题。
最近和社区用户在测试 KB 0.8 升级 0.9 时,遇到一个 Cluster 无法删除的 case,一起断断续续交互式分析和排查问题一天后,基本确定了几个诡异问题的原因,最后剩下一个 Pod 卡在 Terminating 的问题,刚好也在给 KB 训练营的小伙伴分享 Pod 的生命周期,于是想理论结合实际,深挖一下问题到底出在哪里。
问题复现
经过回忆和尝试(估计花了一些时间),问题复现步骤如下:
- KubeBlocks v0.8 中执行
kbcli playground init - 执行
kbcli cluster create xxxx - 升级 kbcli 至 v0.9
- KubeBlocks v0.9 中执行
kbcli kubeblocks upgrade,helm upgrade job超时失败 - 执行
helm uninstall kubeblocks - 执行
Delete cluster xxxx - 执行
helm install kubeblocks Cluster xxxx一直处于Deleting状态
问题排查
定位卡点
按照过去的经验,Cluster 无法删除通常是某些二级资源无法删除导致,社区用户也观测到 Pod 跟 PVC 都卡在 Terminating 状态,而 PVC 在其所挂载的 Pod 删除前是不会被删除的(有 finalizer 保护),所以问题自然聚焦到 Pod 为什么删不掉上。
首先来看看 Pod 对象的 YAML 文件,根据官方文档对 Pod Termination 过程的描述,我们过滤出跟 Pod 终止相关的字段:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-07-08T07:36:57Z"
deletionGracePeriodSeconds: 30
deletionTimestamp: "2024-07-09T06:58:59Z"
name: cherry18-postgresql-0
namespace: default
spec:
terminationGracePeriodSeconds: 30
status:
containerStatuses:
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/kubeblocks-tools:0.8.3
name: config-manager
state:
terminated:
exitCode: 0
reason: Completed
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/kubeblocks-tools:0.8.3
name: lorry
state:
terminated:
exitCode: 0
reason: Completed
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/agamotto:0.1.2-beta.1
name: metrics
state:
terminated:
exitCode: 0
reason: Completed
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/pgbouncer:1.19.0
name: pgbouncer
state:
terminated:
exitCode: 137
reason: Error
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/spilo:14.8.0-pgvector-v0.5.0
name: postgresql
state:
terminated:
exitCode: 143
reason: Error
initContainerStatuses:
- image: infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/spilo:14.8.0-pgvector-v0.5.0
name: pg-init-container
state:
terminated:
exitCode: 0
phase: Running
qosClass: Burstable
startTime: "2024-07-08T07:36:57Z"
依然有点多,但也只能逐个字段分析了,好在分析起来很快:
deletionTimestamp已经有了;finalizer为空;- 超过了
terminationGracePeriodSeconds(=30s); - 所有的容器也都
terminated了; - 有两个容器退出
code非0(137&143)。
按照 K8s 的文档,此时 kubelet 应该把 pod phase 更新为 Failed,但实际还是 Running。
看来 kubelet 现在的行为跟文档描述并不相符,那就翻翻 kubelet 日志,看看发生了啥。
Kubelet 日志
又是一份很长的文本,不过好在文件最后就有报错信息:
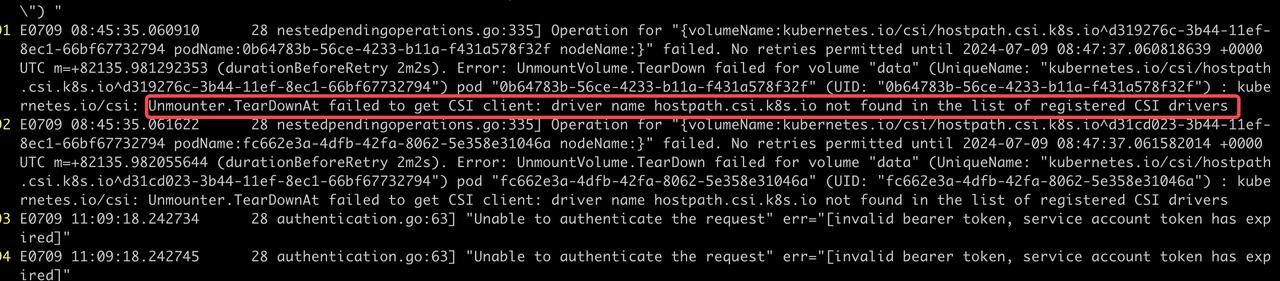
看来 kubelet 在 Unmount data 这个 Volume 时,因为没找到对应的 Hostpath CSI Driver,所以报错了。经确认,Hostpath CSI Driver 确实被一开始的某个步骤删除了。于是赶紧装回来:
kbcli addon enable csi-hostpath-driver
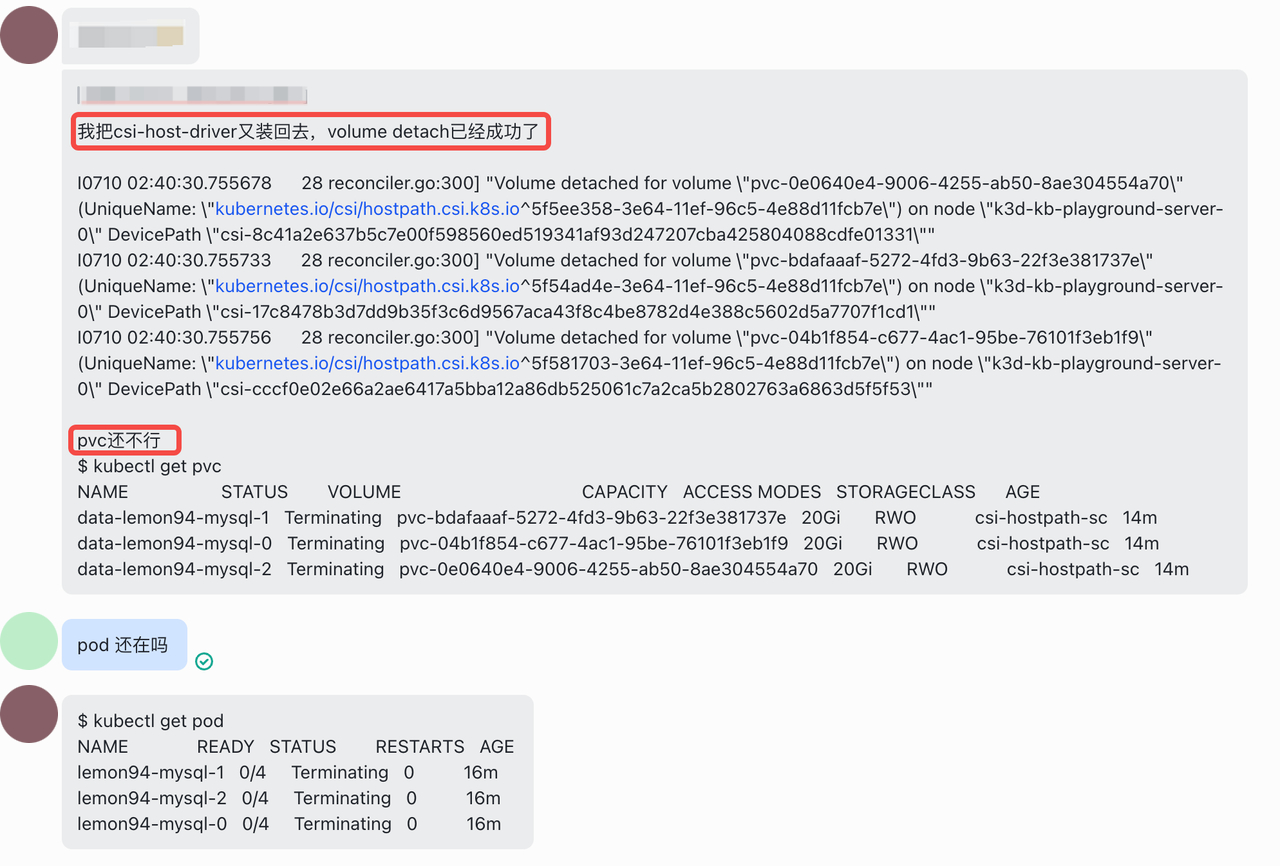
然而不幸的是,Unmount 虽然不再报错,但 Pod 跟 PVC 依然处于 Terminating 状态:
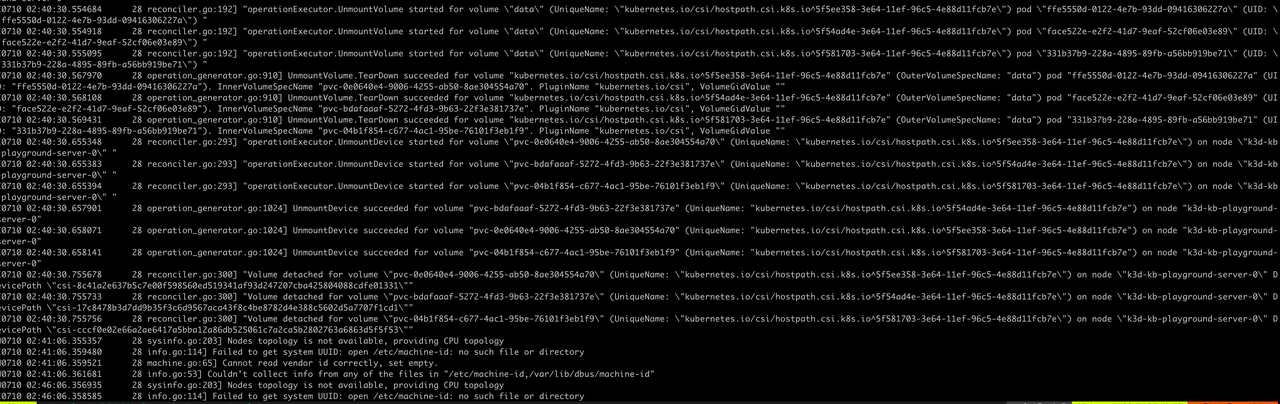
Kubelet log 也没有更多信息了:
Kubelet Verbose 日志
作为一个规范的开源项目,良好的日志管理机制是必不可少的。
通过翻看文档,确认 Kubelet 启动命令和配置文件中均可设置日志级别,该值默认情况下是 0,最高可到 7。
于是开始尝试通过调高日志级别到 6 来获得更多 log。
不幸的是,经过切换多种姿势,在 K3d 中均无法调整日志级别,GPT-4o 也表示无能为力。
于是又花了些时间,在 minikube 上重现了问题,并成功将日志级别设置为了 6:
minikube start --extra-config=kubelet.v=6
获取 log 方式:
minikube logs -f
简化复现流程
一开始的问题复现过程非常耗时,根据前面分析得到的线索,问题跟 KubeBlocks 其实没有关系,可以简化为:
- 创建 Pod & PVC;
- 停用 Hostpath CSI Driver;
- 删除 Pod & PVC,问题触发。
于是构造了如下 Pod & PVC 对象:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data-xxxxxx
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:
name: hello-xxxxxx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: volume-xxxxxx
mountPath: /data
volumes:
- name: volume-xxxxxx
persistentVolumeClaim:
claimName: data-xxxxxx
而 CSI Driver 改为直接使用 minikube 自带的 hostpath:
minikube addon enable csi-hostpath-driver
简化后,就可以愉快&高效的重现问题并分析冗余版本 kubelet 日志了。
更多信息来了
日志非常的多,只能耐心的看了。
看过一段时间后,发现有两个疑点。
疑点一:每隔 100ms 报一次 “Pod is terminated, but some volumes have not been cleaned up”
Jul 15 03:49:33 minikube kubelet[1432]: I0715 03:49:33.850919 1432 kubelet.go:2168] "Pod is terminated, but some volumes have not been cleaned up" pod="default/hello-xxxxxx" podUID="9a42f711-028a-4ca2-802a-0e4db734592d"
疑点二:指数规律报 “failed to remove dir …: device or resource busy”
Jul 15 03:49:34 minikube kubelet[1432]: E0715 03:49:34.053463 1432 nestedpendingoperations.go:348] Operation for "{volumeName:kubernetes.io/csi/hostpath.csi.k8s.io^e9216f9a-425b-11ef-9abf-4e607aa5fc75 podName:9a42f711-028a-4ca2-802a-0e4db734592d nodeName:}" failed. No retries permitted until 2024-07-15 03:51:36.0534518 +0000 UTC m=+881.487053596 (durationBeforeRetry 2m2s). Error: UnmountVolume.TearDown failed for volume "volume-xxxxxx" (UniqueName: "kubernetes.io/csi/hostpath.csi.k8s.io^e9216f9a-425b-11ef-9abf-4e607aa5fc75") pod "9a42f711-028a-4ca2-802a-0e4db734592d" (UID: "9a42f711-028a-4ca2-802a-0e4db734592d") : kubernetes.io/csi: Unmounter.TearDownAt failed to clean mount dir [/var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount]: kubernetes.io/csi: failed to remove dir [/var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount]: remove /var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount: device or resource busy
疑点一看着像 kubelet 在周期性的检测 Pod 相关资源是否已释放,但发现有 Volume 未释放;而疑点二看起来是 kubelet 在尝试删除 pvc 对应的目录时,目录仍然在使用。
两者都指向了 volume 资源仍为释放。
那登录到 minikube 里,看看目录为何没有释放:
root@minikube:/var/lib/kubelet/pods# lsof +D /var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount
root@minikube:/var/lib/kubelet/pods# mount | grep /var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount
/dev/vda1 on /var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount type ext4 (rw,relatime)
lsof 返回空,说明没有进程正在使用该目录。mount 返回不为空,说明该目录仍处于挂载状态。
所以问题进一步归结为:PVC 所对应目录并未 unmount 或 unmount 失败。
可以下结论了
至此,我们可以说,因为在 Pod & PVC 删除过程中,出现了 CSI Driver 的重启,导致 PVC 对应目录没有(或不能)正确 unmount,从而导致 Pod 终止流程卡住。
解法是:手动 unmount 对应的目录。
还有什么
但是,等等,CSI Driver 本质上不就是存储资源的管控平面吗?管控平面的重启不应该导致存储资源不可释放啊,K8s 不能这么弱吧。
感觉还有大瓜:为什么 CSI Driver 重启,会导致 PVC 目录 unmount 失败。
吃瓜的兴致来了
首先这无疑是 kubelet 或 CSI Driver 的 Bug 了,接下来就是找到 Bug 所在。日志已经不能提供更多信息,那就翻代码吧。
| 组件名称 | 版本 |
|---|---|
| K8s | 1.29.3 |
| Hostpath CSI Driver | 1.11.0 |
根据前面的疑点一和疑点二,通过报错中的信息搜到对应的代码位置。
代码位置一:
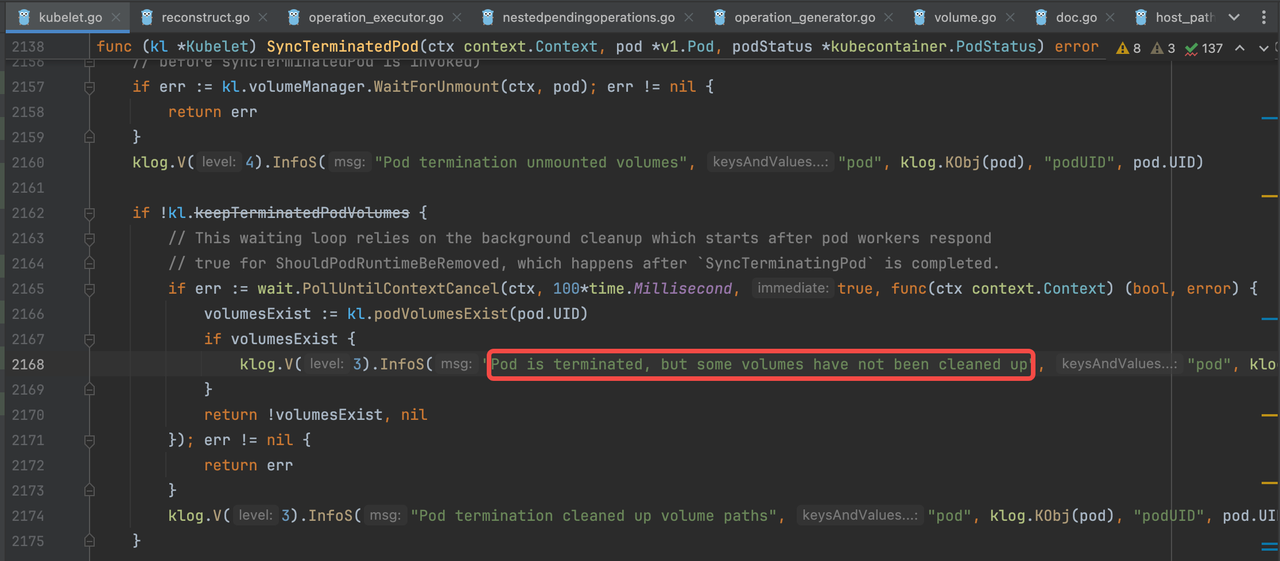
这里可以看出,在终止 Pod 流程中,kubelet 会以 100ms 的间隔周期性查询 volume 是否已清理完,在方法返回 true 之前,该循环会一直重复下去,也就意味着 kubelet 会一直卡在这里,后续的删除 Pod 流程无法进行,也就意味着 Pod 会一直处于 Terminating 状态。
这跟我们看到的现象和疑点一中的日志均一致。
代码位置二:
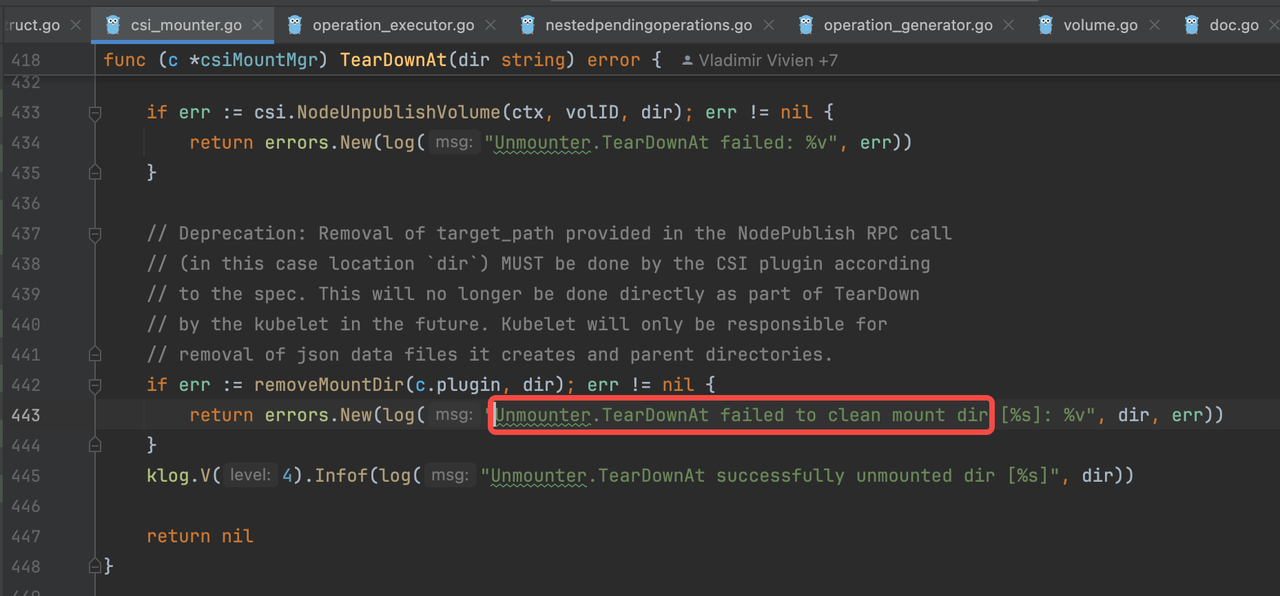
这里可以看出,kubelet 确实会有删除 pvc 对应目录的操作,进一步往上层查看代码的话,可以看到,如果删除报错,会有一个指数型重试机制。
不过这里却有一个新的发现:removeMountDir 能够执行的前提是 csi.NodeUnpublishVolume 成功返回,而 csi.NodeUnpublishVolume 成功意味着 unmount 已成功。
所以疑犯只剩下 Hostpath CSI Driver 了。
真凶出现
进一步查看 Hostpath 的 log:
I0715 03:49:34.052729 1 server.go:101] GRPC call: /csi.v1.Node/NodeUnpublishVolume
I0715 03:49:34.052749 1 server.go:105] GRPC request: {"target_path":"/var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount","volume_id":"e9216f9a-425b-11ef-9abf-4e607aa5fc75"}
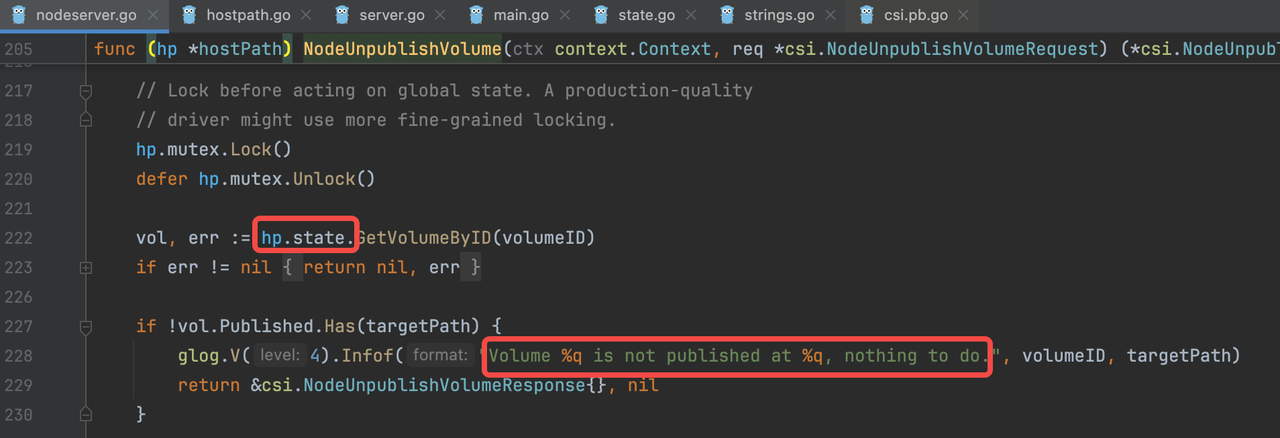
I0715 03:49:34.053026 1 nodeserver.go:228] Volume "e9216f9a-425b-11ef-9abf-4e607aa5fc75" is not published at "/var/lib/kubelet/pods/9a42f711-028a-4ca2-802a-0e4db734592d/volumes/kubernetes.io~csi/pvc-ea3178bf-fc12-432c-a01b-8389b04c508e/mount", nothing to do.
“Volume … is not published at …”
居然说目录没有 published,重启后元数据丢了?元数据居然放内存?不能这么不靠谱吧?
等等,CSI Driver 是 Hostpath,这玩意官方说仅用于测试,难道真这么不靠谱?
继续翻代码确认:
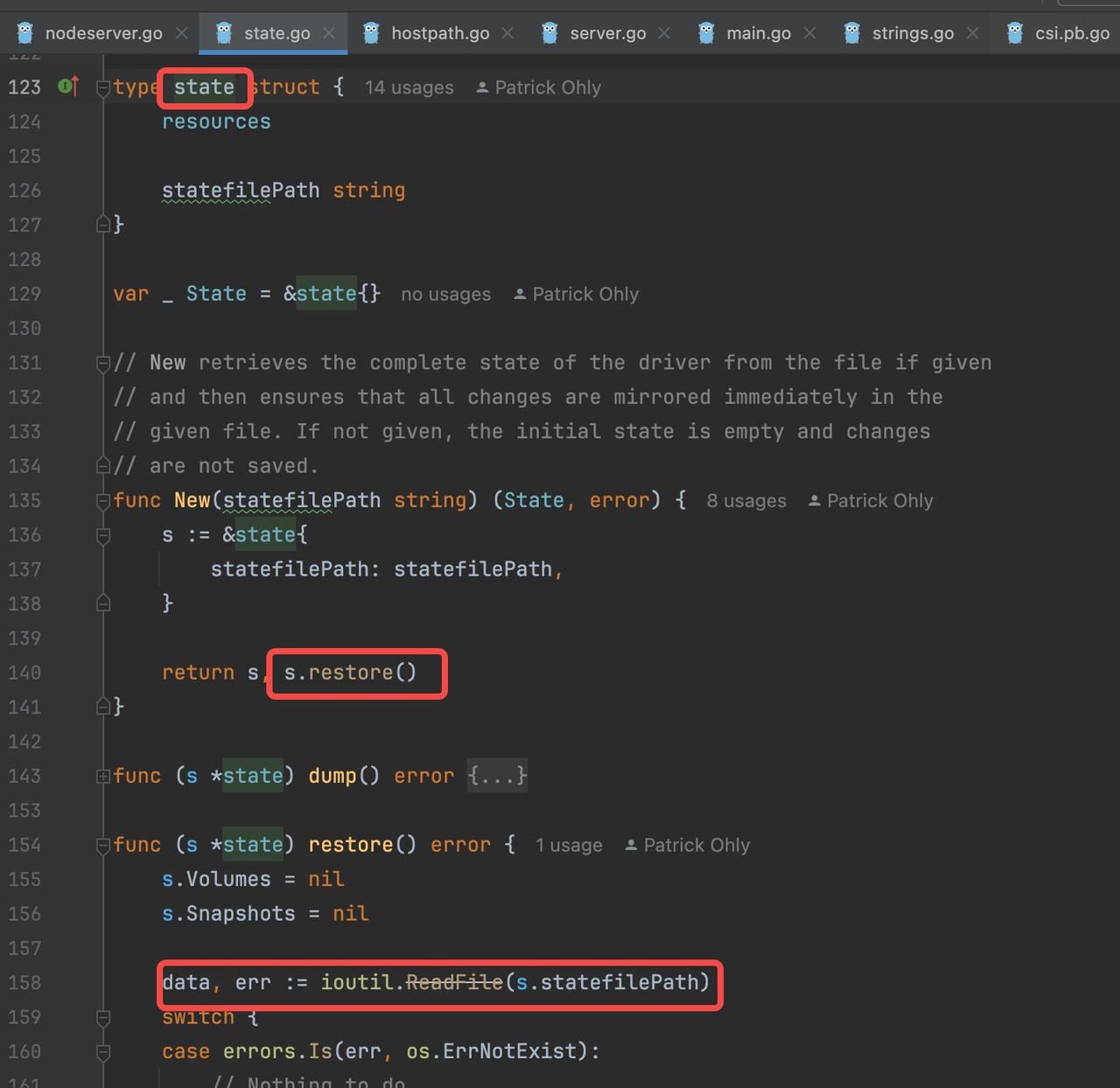
看来状态元数据都存在了一个文件中,打开文件看看:
minikube ssh
cat /var/lib/csi-hostpath-data/state.json
{"Volumes":[{"VolName":"pvc-be2792ca-6937-4296-a234-381bd7c94f1d","VolID":"f595ce89-4283-11ef-ba81-6a2e54b029dc","VolSize":2147483648,"VolPath":"/csi-data-dir/f595ce89-4283-11ef-ba81-6a2e54b029dc","VolAccessType":0,"ParentVolID":"","ParentSnapID":"","Ephemeral":false,"NodeID":"","Kind":"","ReadOnlyAttach":false,"Attached":false,"Staged":null,"Published":null}],"Snapshots":null}
还真是:"Published":null。
修复
瓜吃完了:Hostpath CSI Driver 在持久化元数据时有 Bug。
那准备给官方提 issue 和 PR 吧。在提 issue 前照例翻翻已有 issue 列表,看是不是已经存在了:
https://github.com/kubernetes-csi/csi-driver-host-path/issues/457。
挺好,已经有人提过并 fix 了,咱只要升级就行了:
https://github.com/apecloud/helm-charts/pull/21。
后记
实际的问题排查过程要比描写的繁杂的多,工作量也巨大。为了便于理解,叙述过程中省略了一些分析,也跳过了一些分支。
比如构造高效的问题重现方式就需要不少的时间,把 kubelet log 折腾出来也花了很多时间,花了比较多的时间来完整阅读 kubelet 跟 volume 管理相关的代码等等。
一些关键收获:
- Pod Termination 过程中会死等所有 volume 资源释放;
- Kubelet 处理 Pod 的模型是:为每个 Pod 分配一个 goroutine,负责 Pod 从 Creating 到 Running 到 Terminating 到 Terminated 整个生命周期;
- Kubelet 中处理 volume 相关工作的模块叫 volume manager,会为每个 volume 分配一个 goroutine,负责 volume 的 attaching、mounting、unmounting和detaching;
- Hostpath CSI Driver 真的不适合用于生产环境。















 4319
4319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









