







- 什么是Spark
Apache Spark 的架构基础是弹性分布式数据集 (RDD),这是一种只读的多组数据项,分布在机器集群上,以容错方式维护。[2] Dataframe API 作为 RDD 之上的抽象发布,随后是 Dataset API。在 Spark 1.x 中,RDD 是主要的应用程序编程接口(API),但从 Spark 2.x 开始,鼓励使用数据集 API [3],即使 RDD API 没有被弃用。[4] [5] RDD 技术仍然是 Dataset API 的基础。[6] [7]
Spark 及其 RDD 于 2012 年开发,以应对MapReduce集群计算范式的局限性,该范式在分布式程序上强制采用特定的线性数据流结构:MapReduce 程序从磁盘读取输入数据,跨数据映射函数,减少映射,并将缩减结果存储在磁盘上。Spark 的 RDD 充当分布式程序的工作集,提供(故意)受限形式的分布式共享内存。[8]
在 Apache Spark 内部,工作流作为有向无环图(DAG) 进行管理。节点代表 RDD,而边代表 RDD 上的操作。
Spark 有助于实现迭代算法(在循环中多次访问其数据集)和交互式/探索性数据分析,即重复的数据库式数据查询。与Apache Hadoop MapReduce 实施相比,此类应用程序的延迟可能会减少几个数量级。[2] [9] 在迭代算法的类别中,有机器学习系统的训练算法,它形成了开发 Apache Spark 的最初动力。[10]
Apache Spark 需要一个集群管理器和一个分布式存储系统。对于集群管理,Spark支持standalone(原生Spark集群,可以手动启动集群,也可以使用安装包提供的启动脚本,也可以在单机上运行这些daemon进行测试)、Hadoop YARN、Apache Mesos或Kubernetes。[11]对于分布式存储,Spark 可以与多种接口,包括Alluxio、Hadoop 分布式文件系统(HDFS)、[12] MapR 文件系统(MapR-FS)、[13] Cassandra、[14] 可以实施OpenStack Swift、Amazon S3、Kudu、Lustre 文件系统[ 15]或自定义解决方案。Spark还支持一种伪分布式本地模式,通常只用于开发或测试目的,不需要分布式存储,可以使用本地文件系统代替;在这种情况下,Spark 运行在一台机器上,每个CPU 核心有一个执行程序。
- Spark内置模块
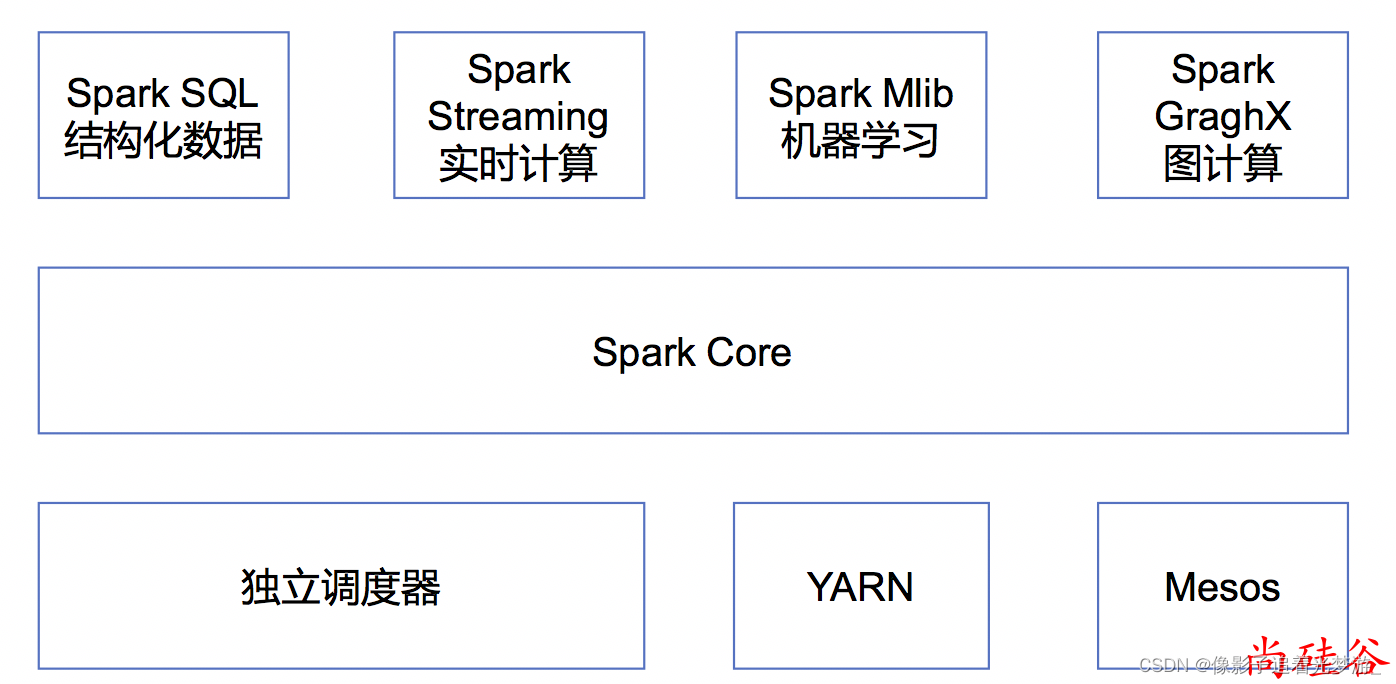
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模 块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定 义;
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON 等;
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并 且与Spark Core中的 RDD API高度对应;
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供 了模型评估、数据 导入等额外的支持功能;
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样 的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个调度器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、 Pivotal、百度、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数 据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾 讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
- Spark的特点
1)快:与Hadoop的MapReduce相比,Spark基于内存的运算要快很多,基于硬盘的运算也要快10倍以 上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在 于内存中的。
2)易用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同 的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群 来验证解决问题的方法。
3)通用:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流 处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都 可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
兼容性(扩展):Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop 的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括 HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使 用Spark的强大处理能力。
- 官网地址















 2487
2487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









