






SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
摘要
我们提出了语义区域自适应归一化(SEAN),这是一种简单但有效的构建块,用于在生成对抗网络(GANs)中根据描述所需输出图像中语义区域的分割掩模进行条件化。使用SEAN归一化,我们可以构建一个网络架构,可以单独控制每个语义区域的风格,例如,我们可以为每个区域指定一个风格参考图像。SEAN在编码、传输和合成风格方面比目前最好的方法更适合,并且在重建质量、多样性和视觉质量方面都有更好的表现。我们在多个数据集上评估SEAN,并报告比当前最先进的方法更好的定量指标(例如FID、PSNR)。SEAN还推动了交互式图像编辑的前沿。我们可以通过更改分割掩模或任何给定区域的风格来交互式地编辑图像。我们还可以在每个区域进行两种参考图像之间的风格插值。代码:https://github.com/ZPdesu/SEAN。

- 重构图(b)表示是用源图的风格编码生成的图像;被编辑的图(如c),可以看到将参考/风格图像的头发的语义风格给到源图的风格,可以看到生成的图中,女孩的头发是风格图像中的头发
1. 引言
在本文中,我们处理使用条件生成对抗网络(cGANs)进行合成图像生成的问题。具体来说,我们希望能够使用具有每个语义区域标签的分割掩模来控制生成图像的布局,并根据它们的标签将现实风格添加到每个区域。例如,面部生成应用程序将使用眼睛、头发、鼻子、嘴巴等区域标签,而风景画应用程序将使用水、森林、天空、云等标签。尽管存在许多非常好的框架来解决这个问题\cite{ref22,ref8,ref39,ref44},但目前最好的架构是SPADE\cite{ref38}(也称为GauGAN)。因此,我们决定使用SPADE作为我们研究的起点。通过分析SPADE的结果,我们发现了两个我们希望在这项工作中改进的不足之处。
首先,SPADE仅使用一个风格代码来控制整个图像的风格,这对于高质量合成或详细控制来说是不够的。例如,可以很容易地出现所需输出图像的分割掩模包含在输入风格图像的分割掩模中不存在的标记区域。在这种情况下,缺少区域的风格是未定义的,这会产生低质量的结果。此外,SPADE不允许在分割掩模的每个区域中使用不同的风格输入图像。我们的第一个主要思想因此是单独控制每个区域的风格,即,我们提出的架构接受每个区域(或每个区域实例)的一个风格图像作为输入。
其次,我们认为仅在网络的开始处插入风格信息并不是一个好的架构选择。最近的架构\cite{ref25,ref31,ref2}已经证明,如果风格信息作为多个网络层中的归一化参数注入,可以获得更高质量的结果,例如使用AdaIN\cite{ref19}。然而,这些先前的网络都没有使用风格信息生成空间变化的归一化参数。为了解决这个不足,我们的第二个主要思想是设计一个归一化构建块,称为SEAN,它可以使用风格输入图像为每个语义区域创建空间变化的归一化参数。这项工作的一个重要方面是,空间变化的归一化参数依赖于分割掩模以及风格输入图像。
我们的方法在多个具有挑战性的数据集上进行了广泛的评估:CelebAMaskHQ\cite{ref28,ref24,ref32}、CityScapes\cite{ref10}、ADE20K\cite{ref50}和我们自己的Fac¸ades数据集。定量上,我们使用包括FID、PSNR、RMSE和分割性能在内的广泛指标来评估我们的工作;定性上,我们展示了可以通过视觉检查评估的合成图像示例。我们的实验结果证明了比目前最先进的方法有了很大的改进。
我们引入了一个新的架构构建块SEAN,它具有以下优点:
-
SEAN提高了条件GANs合成图像的质量。我们与最先进的方法SPADE和Pix2PixHD进行了比较,并在定量指标(例如FID得分)和视觉检查方面取得了明显的改进。
-
SEAN改进了每个区域的风格编码,使得重建的图像可以与输入风格图像更相似,这是通过PSNR和视觉检查来衡量的。
-
SEAN允许用户为每个语义区域选择不同的风格输入图像。这使得图像编辑功能能够产生更高质量并提供比目前最先进的方法更好的控制。示例图像编辑功能包括交互式区域风格转换和每个区域的风格插值(见图1、2和5)。

2. 相关工作
生成对抗网络(GANs)。自从2014年被引入以来,生成对抗网络(GANs)\cite{ref14}已经成功地应用于各种图像合成任务中,例如图像修复\cite{ref48,ref11}、图像操作\cite{ref52,ref5,ref1}和纹理合成\cite{ref29,ref43,ref12}。随着GAN架构\cite{ref40,ref25,ref38}、损失函数\cite{ref33,ref4}和正则化\cite{ref16,ref36,ref34}的不断改进,GANs合成的图像变得越来越逼真。例如,StyleGAN\cite{ref25}生成的人脸图像质量非常高,几乎可以与未经训练的观察者的照片相媲美。传统的GAN使用噪声向量作为输入,因此用户提供的控制很少。这促进了条件GANs(cGANs)\cite{ref35}的发展,用户可以通过提供条件信息来控制合成过程。例子包括类别标签\cite{ref37,ref34,ref6}、文本\cite{ref41,ref18,ref46}和图像\cite{ref22,ref53,ref30,ref44,ref44,ref38}。我们的工作建立在具有图像输入的条件GANs上,旨在解决图像到图像的翻译问题。
图像到图像的翻译。图像到图像的翻译是一个涵盖计算机视觉和计算机图形学中许多问题的总称。作为一个里程碑,Isola等人\cite{ref22}首次展示了图像条件GANs可以作为各种图像到图像翻译问题的通用解决方案。从那时起,他们的方法被扩展到包括无监督学习\cite{ref53,ref30}、少样本学习\cite{ref31}、高分辨率图像合成\cite{ref44}、多模态图像合成\cite{ref54,ref21}和多域图像合成\cite{ref9}等场景。在各种图像到图像翻译问题中,语义图像合成是一个特别有用的类别,因为它通过修改输入的语义布局图像,使用户可以轻松控制\cite{ref28,ref5,ref15,ref38}。迄今为止,SPADE模型(也称为GauGAN)生成了最高质量的结果。在本文中,我们将通过引入每个区域的风格编码来改进SPADE。
风格编码。风格控制在各种图像合成和操作应用中是一个重要组成部分\cite{ref13,ref29,ref20,ref25,ref1}。风格通常不是由用户手动设计的,而是从参考图像中提取的。在大多数现有方法中,风格在三个地方编码:i) 图像特征的统计数据\cite{ref13,ref42};ii) 神经网络权重(例如快速风格迁移\cite{ref23,ref51,ref47});iii) 网络归一化层的参数\cite{ref20,ref27})。当应用于风格控制时,第一种编码方法通常是耗时的,因为它需要一个缓慢的优化过程来匹配由图像分类网络提取的图像特征的统计数据\cite{ref13}。第二种方法可以实时运行,但每个神经网络只编码选定参考图像的风格\cite{ref23}。因此,需要为每个风格图像训练一个单独的神经网络,这限制了其在实践中的应用。到目前为止,第三种方法是最佳的,因为它实现了任意风格迁移并且是实时的\cite{ref20},它被StyleGAN\cite{ref25}、FUNIT\cite{ref31}和SPADE\cite{ref38}等高质量网络所使用。我们的每个区域风格编码也建立在这种方法上。我们将展示我们的方法生成了更高质量的结果,并实现了更详细的用户控制。
3. 每个区域的风格编码和控制
给定一个输入的风格图像及其对应的分割掩模,本节展示了如何根据掩模从图像中提取每个区域的风格,以及如何使用提取的每个区域的风格代码来合成逼真的图像。
3.1 如何编码风格?
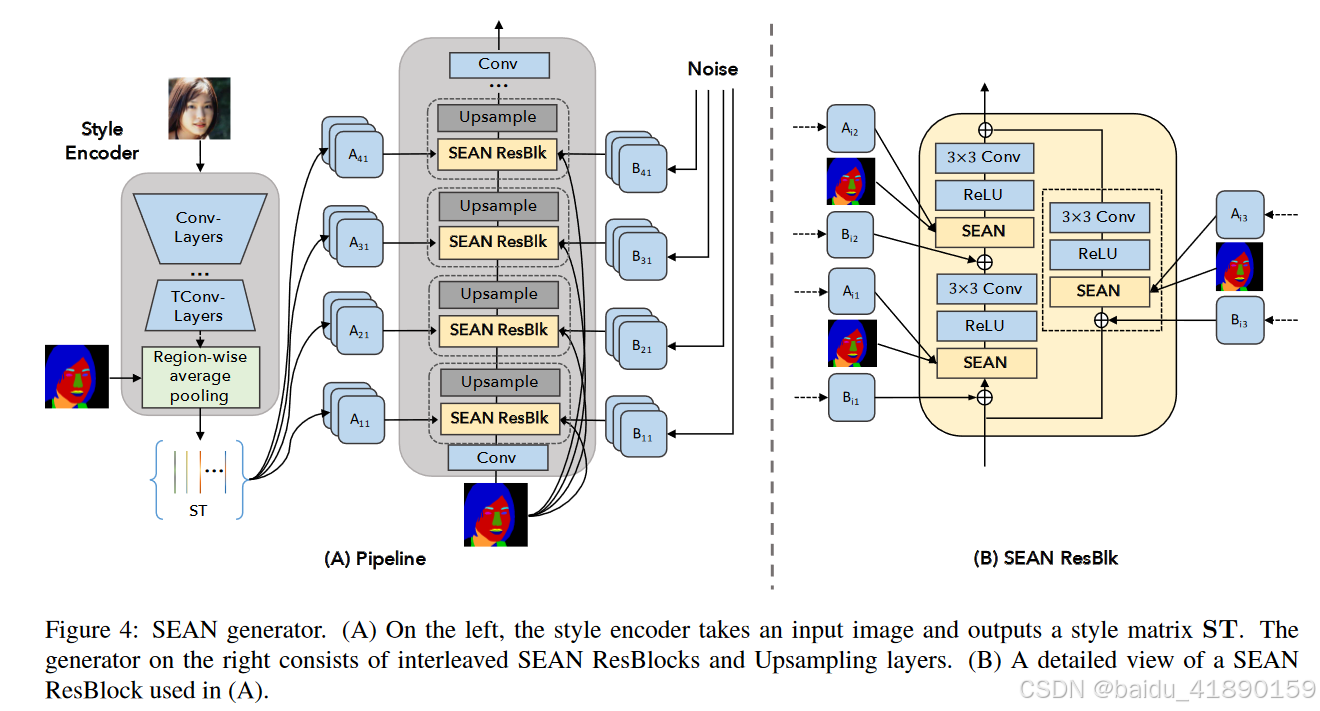
每个区域的风格编码器。为了提取每个区域的风格,我们提出了一个新的风格编码器网络,以同时从输入图像的每个语义区域中提取相应的风格代码(见图4(A)中的风格编码器子网络)。风格编码器的输出是一个512×s维的风格矩阵ST,其中s是输入图像中语义区域的数量。矩阵的每一列对应一个语义区域的风格代码。与建立在简单下采样卷积神经网络上的标准编码器不同,我们的每个区域风格编码器采用了一个“瓶颈”结构,以从输入图像中去除与风格无关的信息。结合风格应与语义区域的形状无关的先验知识,我们通过网络块TConv-Layers生成的中间特征图(512通道)通过一个区域平均池化层,并将它们简化为一组512维向量。作为实现细节,我们想指出我们使用s作为数据集中语义标签的数量,并将输入图像中不存在的区域对应的列设置为0。作为此架构的变体,我们还可以为具有实例标签的数据集提取每个区域实例的风格,例如CityScapes。
3.2 如何控制风格?
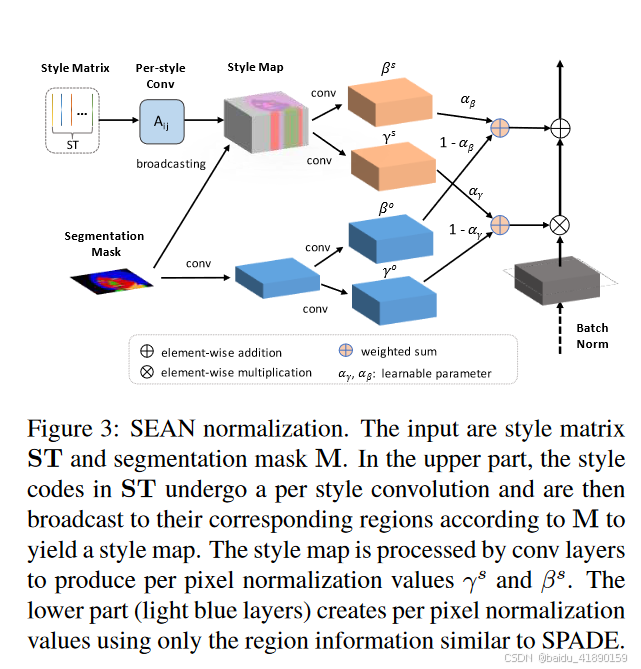
有了每个区域的风格代码和分割掩模作为输入,我们提出了一种新的条件归一化技术,称为语义区域自适应归一化(SEAN),以实现对逼真图像合成中风格的详细控制。类似于现有的归一化技术\cite{ref20,ref38},SEAN通过调节生成器激活的尺度和偏差来工作。与所有现有方法不同,SEAN学习到的调节参数依赖于风格代码和分割掩模。在SEAN块(图3)中,首先根据输入分割掩模将风格代码广播到它们对应的语义区域。然后,这个风格图和输入分割掩模一起通过两个单独的卷积神经网络来学习两组调节参数。它们的加权和用作最终的SEAN参数,以调节生成器激活的尺度和偏差。权重参数在训练过程中也是可以学习的。SEAN的正式定义如下。
语义区域自适应归一化(SEAN)。SEAN块有两个输入:一个编码每个区域风格代码的风格矩阵ST和一个分割掩模M。设h表示当前SEAN块在深度卷积网络中的输入激活,对于一批N个样本。设H、W和C分别为激活图的高度、宽度和通道数。位置(n∈N,c∈C,y∈H,x∈W)的调节激活值由下式给出:
γ
c
,
y
,
x
(
S
T
,
M
)
h
n
,
c
,
y
,
x
−
μ
c
⊘
σ
c
+
β
c
,
y
,
x
(
S
T
,
M
)
\gamma_{c,y,x}(ST, M)h_{n,c,y,x} - \mu_c \oslash \sigma_c + \beta_{c,y,x}(ST, M)
γc,y,x(ST,M)hn,c,y,x−μc⊘σc+βc,y,x(ST,M)
其中
h
n
,
c
,
y
,
x
h_{n,c,y,x}
hn,c,y,x是归一化前的位置激活,调节参数
γ
c
,
y
,
x
\gamma_{c,y,x}
γc,y,x和
β
c
,
y
,
x
\beta_{c,y,x}
βc,y,x分别是
γ
s
\gamma_{s}
γs、
γ
o
\gamma_{o}
γo和
β
s
\beta_{s}
βs、
β
o
\beta_{o}
βo的加权和(见图3中
γ
\gamma
γ和
β
\beta
β变量的定义):
γ
c
,
y
,
x
(
S
T
,
M
)
=
α
γ
γ
s
,
c
,
y
,
x
(
S
T
)
+
(
1
−
α
γ
)
γ
o
,
c
,
y
,
x
(
M
)
\gamma_{c,y,x}(ST, M) = \alpha_{\gamma}\gamma_{s,c,y,x}(ST) + (1 - \alpha_{\gamma})\gamma_{o,c,y,x}(M)
γc,y,x(ST,M)=αγγs,c,y,x(ST)+(1−αγ)γo,c,y,x(M)
β
c
,
y
,
x
(
S
T
,
M
)
=
α
β
β
s
,
c
,
y
,
x
(
S
T
)
+
(
1
−
α
β
)
β
o
,
c
,
y
,
x
(
M
)
\beta_{c,y,x}(ST, M) = \alpha_{\beta}\beta_{s,c,y,x}(ST) + (1 - \alpha_{\beta})\beta_{o,c,y,x}(M)
βc,y,x(ST,M)=αββs,c,y,x(ST)+(1−αβ)βo,c,y,x(M)
其中,
μ
c
\mu_c
μc和
σ
c
\sigma_c
σc分别是通道c中激活的平均值和标准差:
μ
c
=
1
N
H
W
∑
n
,
y
,
x
h
n
,
c
,
y
,
x
\mu_c = \frac{1}{NHW} \sum_{n,y,x} h_{n,c,y,x}
μc=NHW1n,y,x∑hn,c,y,x
σ
c
=
1
N
H
W
∑
n
,
y
,
x
h
n
,
c
,
y
,
x
2
−
μ
c
2
\sigma_c = \sqrt{\frac{1}{NHW} \sum_{n,y,x} h_{n,c,y,x}^2 - \mu_c^2}
σc=NHW1n,y,x∑hn,c,y,x2−μc2
4. 实验设置
4.1 网络架构
图4(A)展示了我们的生成器网络的概览,它建立在SPADE\cite{ref38}的生成器基础之上。与\cite{ref38}类似,我们采用了一个由多个SEAN ResNet块(SEAN ResBlk)和上采样层组成的生成器。
SEAN ResBlk。图4(B)展示了我们的SEAN ResBlk的结构,它由三个卷积层组成,它们的尺度和偏差分别由三个SEAN块调节。每个SEAN块接受两个输入:一组每个区域的风格代码ST和一个语义掩模M。注意,两个输入在开始时都进行了调整:输入的分割掩模下采样到与一层中的特征图相同的高度和宽度;来自ST的输入风格代码通过1×1卷积层Aij进行每个区域的转换。我们观察到,初始转换是架构中不可缺少的组成部分,因为它们根据每个神经网络层的不同角色转换风格代码。例如,早期层可能控制人脸图像的头发风格(例如,波浪形、直发),而后面的层可能涉及光照和颜色。此外,我们观察到在SEAN的输入中添加噪声可以提高合成图像的质量。这种噪声的规模通过在训练过程中学习的每个通道的缩放因子B进行调整,类似于StyleGAN\cite{ref25}。
4.2 训练和推理
训练 我们将训练过程表述为一个图像重建问题。也就是说,风格编码器被训练以根据它们相应的分割掩模从输入图像中提取每个区域的风格代码。生成器网络被训练以用提取的每个区域的风格代码和相应的分割掩模作为输入来重建输入图像。遵循SPADE\cite{ref38}和Pix2PixHD\cite{ref44},输入图像和重建图像之间的差异通过一个总体损失函数来度量,该函数由三个损失项组成:条件对抗损失、特征匹配损失\cite{ref44}和感知损失\cite{ref23}。损失函数的详细信息包含在补充材料中。
推理 在推理过程中,我们采用任意的分割掩模作为掩模输入,并实现每个区域的风格控制,通过为每个语义区域选择一个单独的512维的风格代码作为风格输入。这使得能够进行各种高质量的图像合成应用,这些将在下一节中介绍。
5. 结果
在以下部分中,我们将讨论我们框架的定量和定性结果。
5.1 实施细节
按照SPADE\cite{ref38},我们在生成器和鉴别器中都应用了谱归一化\cite{ref36}。额外的归一化由生成器中的SEAN进行。我们将学习率分别设置为生成器0.0001和鉴别器0.0004\cite{ref17}。对于优化器,我们选择ADAM\cite{ref26},其中 β 1 = 0 \beta_1 = 0 β1=0, β 2 = 0.999 \beta_2 = 0.999 β2=0.999。所有实验都在4个Tesla V100 GPU上训练。为了获得更好的性能,我们在SEAN归一化块中使用了同步版本的批量归一化\cite{ref49}。
5.2 使用的数据集
我们在实验中使用了以下数据集:1) CelebAMask-HQ\cite{ref28,ref24,ref32},包含30,000个CelebAHQ面部图像数据集的分割掩模。有19个不同的区域类别。2) ADE20K\cite{ref50}包含22,210张图片,注释有150个不同的区域标签。3) Cityscapes\cite{ref10}包含3500张图片,注释有35个不同的区域标签。4) Fac¸ades数据集,我们使用从Google街景视图\cite{ref3}收集的30,000张fac¸ade图像数据集。我们没有手动注释,而是使用预训练的DeepLabV3+网络\cite{ref7}自动计算分割掩模。我们遵循每个数据集的推荐拆分,并注意到论文中的所有图像仅来自测试集。分割掩模或风格图像在训练过程中都未见过。
5.3 使用的指标
我们采用了以下建立的指标来将我们的结果与最新技术进行比较:1) 通过平均交并比(mIoU)和像素精度(accu)测量的语义分割精度,2) FID\cite{ref17},3) 峰值信噪比(PSNR),4) 结构相似性(SSIM)\cite{ref45},5) 均方根误差(RMSE)。
5.4 定量比较
为了与SPADE\cite{ref38}进行公平比较,我们报告了只使用单个风格图像的重建性能。我们为四个数据集训练了一个网络,并在表1和表2中报告了前面描述的指标。我们选择SPADE\cite{ref38}作为当前最好的最新技术方法,并将Pix2PixHD\cite{ref44}作为第二好的方法进行比较。基于对结果的视觉检查,我们发现FID得分最能反映结果的视觉质量,并且较低的FID得分通常(尽管并非总是)对应于更好的视觉结果。一般来说,我们可以观察到我们的SEAN框架在所有数据集上都明显优于最新技术。
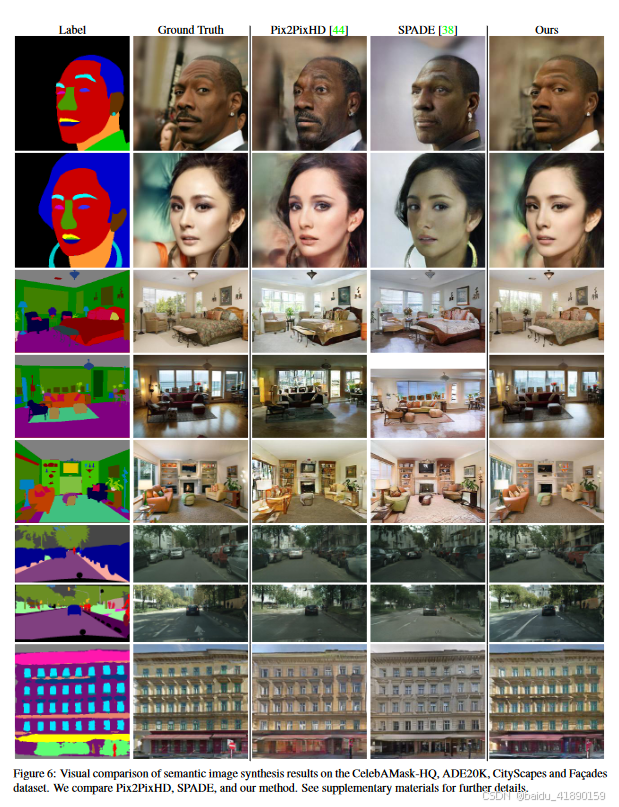
5.5 定性结果
我们在图6中展示了四个数据集的视觉比较。我们可以观察到我们工作与最新技术之间的质量差异可能非常显著。例如,我们注意到SPADE和Pix2Pix无法处理更极端的姿势和老年人。我们推测,由于我们改进的风格编码,我们的网络更适合学习数据中的可变性。由于对生成建模结果的视觉检查非常重要,我们希望读者参考补充材料和附带的视频以获取更多结果。我们的每个区域风格编码还实现了新的图像编辑操作:迭代图像编辑,每个区域的风格控制(见图1和2),风格插值和风格交叉(见图5和7)。
5.6 海量实验
表3中,我们在CelebAMask-HQ数据集上比较了许多我们架构的变体与先前的工作。根据我们的分析,Pix2PixHD具有比SPADE更好的风格提取子网络(因为PSNR重建值更好),但SPADE具有更好的生成器子网络(因为FID得分更好)。因此,我们构建了另一个网络,将Pix2PixHD中的风格编码器与SPADE中的生成器结合起来,并将这个架构称为SPADE++。我们可以观察到SPADE++略微改进了SPADE,但我们的所有架构变体仍然具有更好的FID和PSNR得分。为了评估我们的设计选择,我们报告了我们编码器的变体的性能。首先,我们比较了三种风格编码变体:SEAN级编码器、ResBlk级编码器和统一编码器。一个基本的设计选择是如何将风格计算分成两部分:风格编码器中的共享计算和每个SEAN块中的每层计算。前两个变体每层都执行所有风格提取,而统一编码器是本文主要部分描述的架构。虽然其他两个编码器具有更好的重建性能,但它们导致了更低的FID得分。基于视觉检查,我们也确认了统一编码器导致了更好的视觉质量。这在困难输入中尤为明显(见补充材料)。其次,我们评估了风格编码器中下采样是否是个好主意,并评估了一个具有瓶颈(具有下采样)的风格编码器与另一个使用较少下采样的编码器。这个测试证实了在风格编码器中引入瓶颈是个好主意。最后,我们测试了可学习噪声的效果。我们发现可学习噪声可以帮助相似性(PSNR)和FID性能。更多关于替代架构的细节在补充材料中提供。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









