







突然心血来潮想着,之前爬虫学习也可以爬取一些数据和图片了,那么视频呢?是不是也是找到一个 url 然后直接写入文件保存就可以呢?事实证明没那么容易,四处查资料还是折腾了一天,最后终于可以了。在众多博文中帮助最大的就是如下这篇,非常感谢。
https://blog.csdn.net/a33445621/article/details/80377424
总的来说,根据我看的博文中介绍,m3u8 是一种视频的播放格式,与传统的MP4不同(依稀记得以前如果想要下载一个视频,只需要将一个视频从头播放到尾,然后就可以在系统的某处找到缓存文件),它是将一个完整的视频切割成多个 ts 后缀的视频,然后当我们的进度条被移动或者按时间顺序移动的时候,就会下载对应的片段来加载。
使用抓包工具 Fiddler,可以看到当网页中的视频开始播放时,首先会向一个另外的地址发起请求,获取一个后缀为 index.m3u8 的文件。我所查看的网站,会在这个后缀为 index.m3u8 的文件之后再去获取一个 1000kb/hls/index.m3u8 的资源,而这个才是真正的 m3u8 文件。里面的内容指定了,我们即将获取的 m3u8 资源的 url 是什么、排列顺序,加密方式以及密钥的 url。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:10
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-KEY:METHOD=AES-128,URI="key.key"
#EXTINF:10.000000,
mYexOkq6386000.ts
#EXTINF:10.000000,
mYexOkq6386001.ts
上面就是一个 m3u8 文件的前一部分,我们爬虫需要关注的是加密方式是 AES-128 。然后去把 index.m3u8 替换成 key.key,即可获取到加密的密钥,这个密钥 key 将会是我们后续解码文件的关键,没了它下载得到的文件是没有意义的。
下载的方法与以往的爬虫程序相同,额外不同的在于写入文件的瞬间。首先因为需要解码 AES 这种加密方式需要用到特殊的模块 AES,所以我们要去安装 Crypto,按照如下的方法导入类来使用。注意有个坑就是,安装 Crypto 的同时需要安装 PyCryptodome(pycrypto 根据开发者的说法已经不再维护,这个是新的库,功能和接口基本一致),才可以顺利导入。如果发生了 ImportError,显示没有 Crypro 库,那么就去 site-packages 里面看看文件名是不是 crypto,改成 Crypto 应该就没问题了。
from Crypto.Cipher import AES
data = ......
key = ......
cryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC)
with open(filepath, 'ab') as file:
file.write(cryptor.decrypt(data))如果没有在把类型为 str 的 key 改成 bytes 类型的话会报 TypeError。然后似乎 open 的地方打开方式 'ab' 或者 'ab+' 都没什么区别,只要是二进制写已经就可以。
没意外的话就可以在指定的文件夹中看到下载的一系列 ts 文件,而且是可以播放的。但是每一个片段的时间都很短,所以我们需要把所有的片段拼接成一个完整的视频,查到可以用一句 cmd 命令来合并,加 /b 的目的就是直接拼接而不做其他多余的操作否则会影响视频的解码播放。
copy /b D:\download_video\111\*.ts D:\download_video\111.ts
可是如果写完程序抓取完视频还得手动去打一个 cmd 命令就很麻烦,os 模块的 system 函数就可以帮助我们解决这个问题。但似乎其中接受的字符串的要求,尤其是对路径的解读,对 \ 和 / 这两个字符的认知似乎不同于直接在 cmd 命令行中输入的。在 python 中我们是以 \ 反斜杠作为转义字符,然后以 / 正斜杠作为路径之间的分隔;但是在 cmd 命令中是相反的,并且如果我们使用 os.path.join 来帮助我们构建路径的时候它也是使用 \ 反斜杠来拼接的。请忽略那个覆盖,因为不想删掉之后重新再跑一次哈哈。
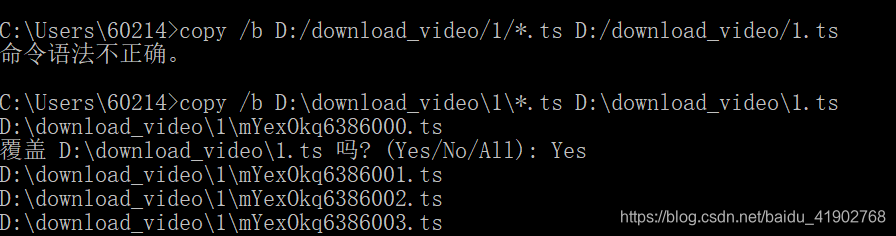
总结的说,如果我们所构建的路径只需要在 python 中使用,例如 open 一个指定路径的文件,就是用 python 对路径的规范;但是如果需要执行 cmd 命令,推荐使用 os.path.join,既方便又不会出错。我的代码就是一句话:
os.system("copy /b {} {}".format(os.path.join(download_file, filename, "*.ts"), os.path.join(download_file,filename + ".ts")))
那么既然完成了任务,原先那些琐碎的小的 ts 文件就要删掉啦~用 os.remove 一个一个删除,因为 os.removedirs 只能删除空的文件夹。
for i in os.listdir(os.path.join(download_file, filename)):
os.remove(os.path.join(download_file, filename, i))
os.removedirs(os.path.join(os.path.join(download_file,filename)))但是下载的速度很缓慢,整个视频文件一共才 250M 我却需要下载超过5 分钟。想尝试用多线程来处理队列任务,看看能不能加快速度!具体内容留待下一篇博文!
#encoding = gb2312
import requests
import os
import re
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
from my_quant.time_function import progressbar
import time
def progressbar(tot, pre):
'''
max_bar means the total number of tasks.
i means the number of finished tasks.
'''
max_bar = 20
finish = int(pre*max_bar/tot)
unfinish = (max_bar - finish)
bar = "[{}{}]".format(finish * "-", unfinish * " ")
percent = str(int(pre/tot * 100)) + "%"
if pre < tot:
sys.stdout.write(bar + percent + "\r")
else:
sys.stdout.write(bar + percent + "\n")
sys.stdout.flush()
def cal_time(fun):
def inner_wrapper(*args):
start = time.time()
fun(*args)
end = time.time()
print('Time spent is ' + str(round(end - start,1)))
return inner_wrapper
@cal_time
def video_downlowner(url):
download_file = "D:\\download_video"
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50'}
result = requests.get(url, headers = headers)
soup = BeautifulSoup(result.text, 'html.parser')
filename = soup.find('div', class_ = 'tit')
filename = filename.find_all('a')[-1].string
filename = re.sub(" ", "", filename)#remove the blank in the string.
#filename = "111"
folder = os.path.exists(download_file + '/' + filename)
if not folder:
os.makedirs(download_file + '/' + filename)
folder = download_file + '/' + filename
pattern = re.compile(r'var vHLSurl = "(.*)";')
script = soup.find_all('script', type = "text/javascript")
s = script[3].text
s_after = re.sub(" +", " ", s)
res = pattern.findall(s_after)[0]
new_result = requests.get(res, headers)
res = re.sub('index.m3u8', '1000kb/hls/index.m3u8', res)
nn_result = requests.get(res, headers)
#print(nn_result.text)
pattern1 = re.compile(r",(.*?)#")
lis = pattern1.findall(re.sub('\n', '', nn_result.text))
res = re.sub('index.m3u8', 'key.key', res)
nnn_result = requests.get(res, headers)
key = nnn_result.text
print('key is ' + key)
i = 0
for item in lis[1:]:
download_url = re.sub('key.key', item, res)
r = requests.get(download_url ,headers = headers).content
cryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC)
i += 1
#print(i)
progressbar(len(lis[1:]), i)
if os.path.exists(folder + '/' + item):
continue
with open(folder + '/' + item, 'ab+') as file:
r = requests.get(download_url ,headers = headers).content
file.write(cryptor.decrypt(r))
'''
Merge ts files.
'''
if not os.path.exists(os.path.join(download_file,filename + ".ts")):
os.system("copy /b {} {}".format(os.path.join(download_file, filename, "*.ts"), os.path.join(download_file,filename + ".ts")))
'''
Start to delete ts files.
'''
for i in os.listdir(os.path.join(download_file, filename)):
os.remove(os.path.join(download_file, filename, i))
os.removedirs(os.path.join(os.path.join(download_file,filename)))
if __name__ == "__main__":
url = ...
video_downlowner(url)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









