







 HGSM算法通过分析用户的历史GPS记录,考虑序列性和地理空间层次性来计算用户间的相似度。它首先检测停留点,然后进行层次聚类形成层级结构图,利用最长相似序列来衡量用户位置序列的相似性,最终通过加权求和得到总体相似性得分。
HGSM算法通过分析用户的历史GPS记录,考虑序列性和地理空间层次性来计算用户间的相似度。它首先检测停留点,然后进行层次聚类形成层级结构图,利用最长相似序列来衡量用户位置序列的相似性,最终通过加权求和得到总体相似性得分。
HGSM算法(Hierarchical-graph-based Similarity Measurement),基于层级结构图的相似度分析:主要是基于用户的历史位置信息挖掘用户之间的相似度。与其他关于位置信息的算法不同的地方在于它考虑了人们运动行为的序列性质和地理空间的层次性。
GPS记录:一系列GPS数据点的有序集合, P={
p1,p2,…,pn} 。每个GPS数据点 pi=(Lati,Lngti,Ti) 。图一左边是一个GPS记录,将这些点描绘在一个二维平面内,得到一个GPS轨迹,如右图。
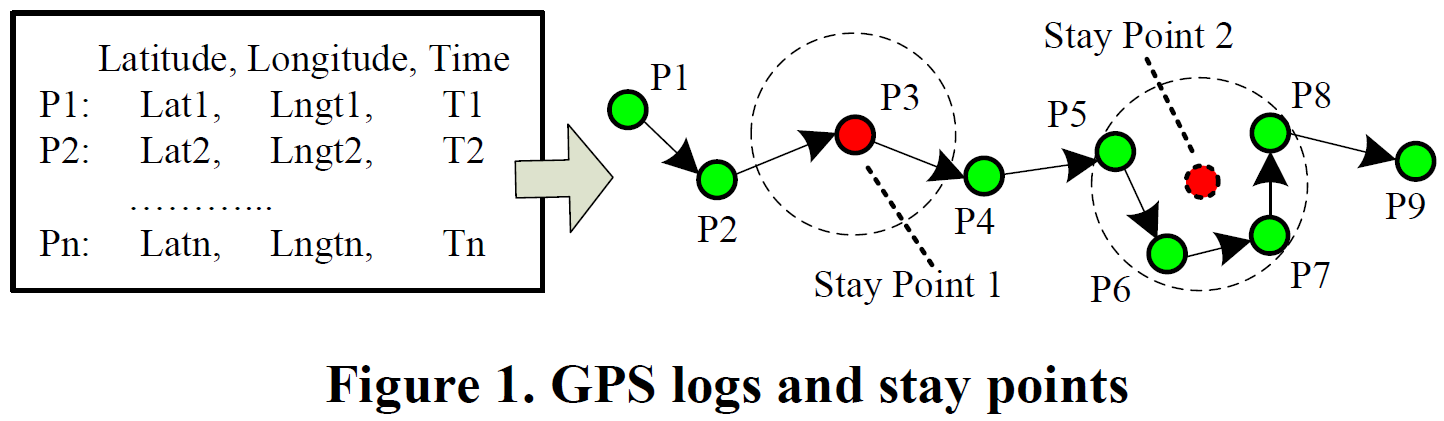
根据GPS记录提取停留点
1、GPS记录是由很多个GPS数据点组成的,其中有很多不带有什么意义;
2、每一个GPS数据点都或多或少地存在着误差;
3、当用户进入室内场所时,可能得不到当时的GPS数据,直到重新到达室外。
图一右图中有两种类型的停留点:
停留点1:在某一段时间内,用户的位置信息是静止不动的,可能用户进了一个没有信号的房子里。
停留点2:在某一段时间内,用户一直在一个特定的区域内徘徊,产生了很多GPS数据点,因此我们需要把这些数据点取平均位置作为一个停留点。
定义:如果在一定范围(D<200m)内,用户停留超过一定时间(T>30min),则认为用户在这一地点进行了停留,取这一部分GPS点的平均值作为停留点坐标,取第一个GPS点的时间戳作为到达时间(arvT),取最后一个GPS点的作为离开时间(levT),记作:
范围D、时间T的选取可以根据不同情况进行调整,选择合适的数值就可以避免一些无意义的停留点的出现,比如交通堵塞。
下面是检测停留点的算法:

根据GPS轨迹和检测出的停留点,用户的历史位置记录可以表示成一系列带有到达时间和离开时间的地点。由于不同的用户的停留点很多都是不同的,很难对其进行比较,用停留点之间的距离来度量用户相似度也会误差很大。
为了解决这个问题提出了层级结构图。将所有用户的停留点放在一个数据集内,再对这个数据集进行层次聚类,得到几个不相交的空间区域。所以不同用户相似的停留点在每一层中将会被分在同一个区域内。
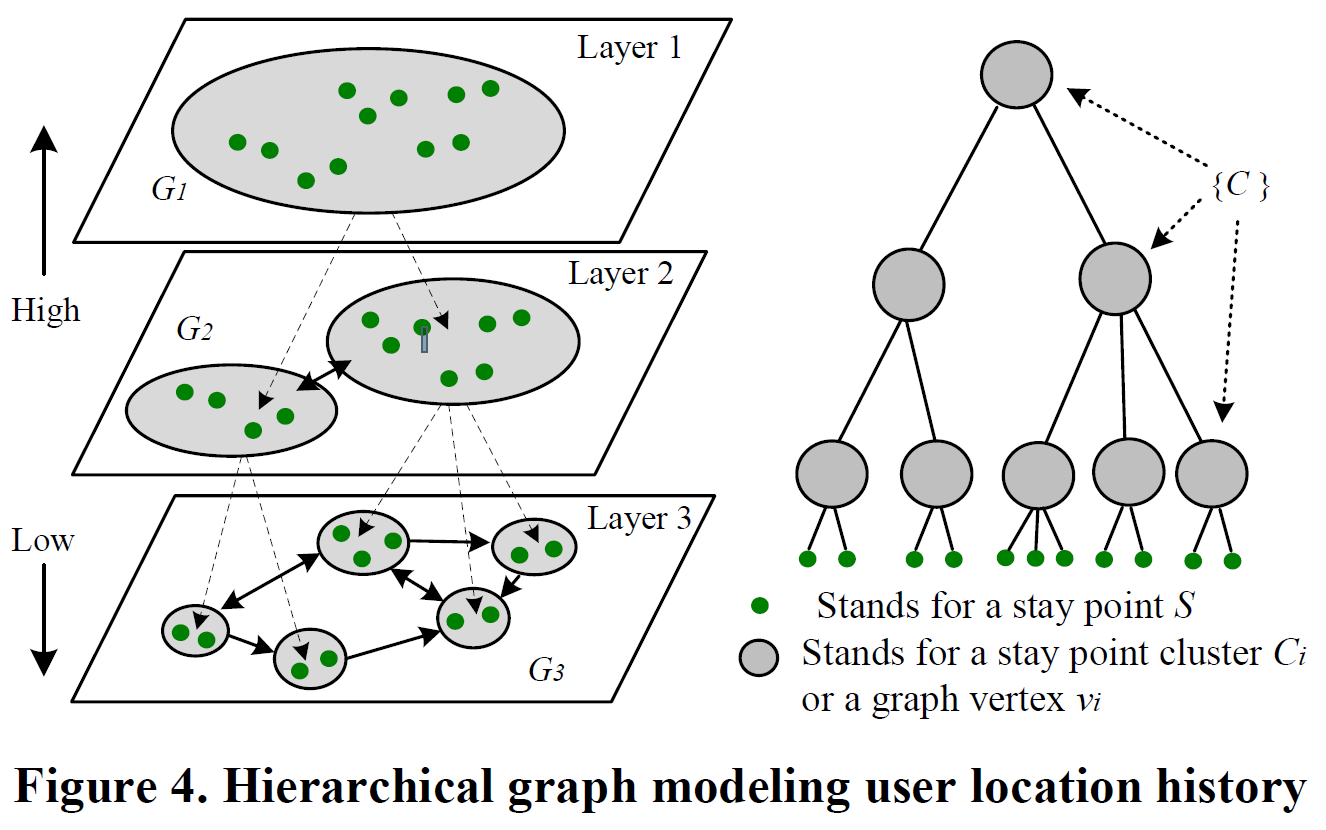
随着层级降低,空间区域的个数变多,每个空间区域的规模变小,在更低层级上有相同历史位置记录的用户比高层级上相同历史位置记录的用户更相似。
聚类之后我们用层级结构图来表示用户的历史位置信息,比如:
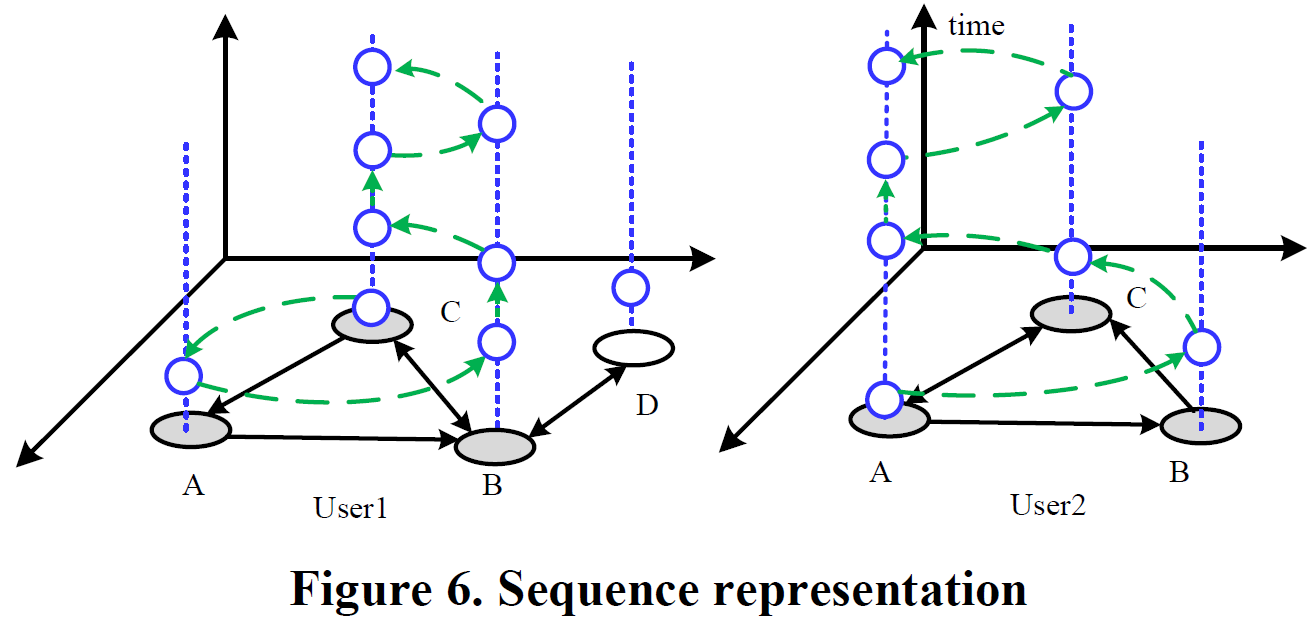
首先找到两个用户共有的区域,这里是A,B和C区域,用户1的位置序列为 <C,A,B,B,C,C,B,C> <script type="math/tex" id="MathJax-Element-114"> </script>,用户2的位置序列为 <A,B,C,A,A,C,A> <script type="math/tex" id="MathJax-Element-115"> </script>,更进一步,我们把位置序列表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









