









关于线程、多线程、线程与进程的概念就不在赘述了。只记录一下python中多线程以及thread、threading模块的使用的使用。
1、线程和Python
在pyhon中使用线程,需要先了解一下python的全局解释器锁。
Python代码的执行是通过Python虚拟机(又名解释器主循环)进行控制的。在主循环中同时只能有一个控制线程在执行,就像单核CPU系统中的多进程一样。内存中可以有许多程序,但是在任意给定时刻只能有一个程序在运行。同理,在Python解释器中,尽管可以运行多个线程,但是在任意给定时刻只有一个线程会被解释器执行。
对Python虚拟机的访问是有全局解释器锁(GIL)控制的。这个锁就是用来保证同时只能有一个线程运行。在多线程环境中,Python虚拟机将按照下面所属方式运行:1)、设置GIL;2)、切换一个线程去运行;3)、执行下面操作之一:指定数量的字节码指令\线程主动让出控制权(可调用time.sleep(0)来完成);4)、把线程设置回睡眠状态(切换出线程);5)、解锁GIL;6)、重复上述步骤。
所以由于GIL的限制,Python中的多线程更适合于I/O密集型应用(I/O释放了GIL,可以允许更多的并发),而不是计算密集型应用。
2、thread模块
thread模块在Python3中重命名为_thread。thread模块除了派生线程外,还提供了基本的同步数据结构,称为锁对象(lock object,也叫原语锁、简单锁、互斥锁等)
2.1、thread模块的简单使用
# 使用thread模块
import _thread #python3.0重命名为_thread
from time import sleep, ctime
def loop0():
print('start loop0 at:', ctime())
sleep(4)
print('end loop0 at: ', ctime())
def loop1():
print('start loop1 at:', ctime())
sleep(2)
print('end loop1 at: ', ctime())
def main():
print('start at:', ctime())
_thread.start_new_thread(loop0, ())
_thread.start_new_thread(loop1, ())
sleep(6) # 如果没有此语句,则main函数直接执行结束,loop0和loop1线程也就直接结束了
print('all DONE at: ', ctime())
if __name__=='__main__':
main()
在上述代码中,有一sleep(6)语句,该语句是用来是线程同步的, 如果没有此语句,则main函数继续执行下一条语句,直至执行结束,loop0和loop1线程也就直接结束了。但是,使用sleep()进行线程同步是不可靠的: 如果循环有独立且不同的执行时间怎么办?我们可能过早或过晚退出主线程,这就是引出锁的原因。
通过使用锁,我们可以在所有线程全部完成执行后立即退出。
2.2、thread模块使用锁
# 使用thread模块
import _thread # python3.0重命名为_thread
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec, lock):
print('start', nloop, ' at:', ctime())
sleep(nsec)
print('end', nloop, ' at:', ctime())
lock.release() # 线程执行完,释放锁对象
def main():
print('start at:', ctime())
locks = []
nloops = range(len(loops))
for i in nloops: # 先创建锁并保存,因为创建锁以及获取锁都是需要时间的
lock = _thread.allocate_lock()
lock.acquire()
locks.append(lock)
for i in nloops: # 尽可能的保证线程的同步启动,
_thread.start_new_thread(loop, (i, loops[i], locks[i]))
for i in nloops: # 等待,直到所有锁被释放后才会继续执行
while locks[i].locked():
pass
print('all DONE at: ', ctime())
if __name__=='__main__':
main()在上述代码中使用了锁(lock)。代码并没有把sleep(4)和sleep(2)硬编码到不同的函数中,而是使用了唯一的loop()函数,通过传递不同的参数执行不同的sleep()。
程序执行时,先统一的创建锁对象,因为锁对象的创建与获取(上锁)是需要一定时间的,之所以不在上锁的时候启动线程,有两个原因:一是同步线程,就是想要让所有的线程能够同时启动;二是获取锁需要时间,如果线程执行的太快,有可能会出现获取锁之前线程就执行结束的情况。
最后一个for循环,则是在进行等待,等待所有的线程的锁都被释放之后才会继续执行。
3、threading模块
threading模块更高级,除了Thread类以外,该模块还包含了非常好用的同步机制。
守护线程:守护线程一般是一个等待客户端请求服务的服务器,如果没有客户端请求,守护线程就是空闲的,如果把一个线程设置为守护线程,就表示这个线程是不重要的,进程退出时不需要等待这个线程执行完成。
threading模块的Thread类是主要的执行对象。使用Thread类可以有多种方法创建线程,常用的有一下三种:
1)、创建Thread的实例,传给它一个函数;
2)、创建Thread的实例,传给它一个可调用的类实例;
3)、派生Thread的子类,并创建子类的实例;
其中1)和3)是最常用的。
3.1、创建Thread的实例,传给它一个函数
# 使用 threading 模块
import threading
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec):
print('start', nloop, ' at:', ctime())
sleep(nsec)
print('end', nloop, ' at:', ctime())
def main():
print('start at:', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = threading.Thread(target=loop, args=(i, loops[i]))
threads.append(t)
for i in nloops: # 尽可能的保证线程的同步启动,
threads[i].start()
for i in nloops: # wait for all threads to finish
threads[i].join() # 直至启动的线程结束前一直挂起,除非给出参数,否则会一直阻塞
print('all DONE at: ', ctime())
if __name__=='__main__':
main()上面代码中,实例化了一个Thread的 的对象来创建线程,实例化Thread和滴啊用thread.start_new_tgread()的最大区别就是新线程不会立即开始执行。这是一个非常有用的同步功能,尤其是不希望线程立即开始执行时。
当所有线程分配完成之后,通过调用每个线程的start()方法开始让它们执行。相比于管理一组锁(分配、获取、释放、检查锁状态)而言,这里只需要为每个线程调用join()方法即可。join()方法将等待线程结束,或者在提供了超时时间的情况下,达到超时时间,然后退出。使用join()方法要比等待所释放的无限循环更加清晰(这也是这种锁又称为自旋锁的原因)。
3.2、派生Thread的子类,并创建子类的实例
# 使用 threading 模块
import threading
from time import sleep, ctime
loops = [4, 2]
class MyThread(threading.Thread): # Thread派生类
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
def run(self):
self.func(*self.args)
def loop(nloop, nsec):
print('start loop', nloop, ' at:', ctime())
sleep(nsec)
print('end loop', nloop, ' at:', ctime())
def main():
print('start at:', ctime())
threads = []
nloops = range(len(loops))
for i in nloops:
t = MyThread(loop, (i, loops[i]), loop.__name__)
threads.append(t)
for i in nloops: # 尽可能的保证线程的同步启动,
threads[i].start()
for i in nloops: # wait for all threads to finish
threads[i].join() # 直至启动的线程结束前一直挂起,除非给出参数,否则会一直阻塞
print('all DONE at: ', ctime())
if __name__=='__main__':
main()上述代码中,MyThread派生了threading.Thread类,并重写了run()函数。
3.3、without lock
当使用threading模块创建线程而没有使用锁时,可能会出现当多个线程访问 同一个变量时数据混乱的问题。如下代码:
from atexit import register
from random import randrange
from threading import Thread, current_thread
from time import sleep, ctime
class CleanOutputSet(set):
def __str__(self):
return ','.join(x for x in self)
loops = (randrange(2, 5) for x in range(randrange(3, 7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = current_thread().name
remaining.add(myname)
print('[%s] Startted %s' % (ctime(), myname))
sleep(nsec)
remaining.remove(myname)
print('[%s] Completed %s (%d secs)' % (ctime(), myname, nsec))
print(' remaining:%s' % (remaining or 'NONE'))
def _main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register
def _atexit():
print('all DONE at: ', ctime())
if __name__=='__main__':
_main()在上述代码中,
loops = (randrange(2, 5) for x in range(randrange(3, 7))) 语句的意思是: 生成3-6个(个数由randrange(3,7)控制)随机数,随机数的值为2-4(由randrange(2,5)控制);
_main():_main()函数是一个特殊的函数,只有这个模块从命令行直接运行时才会执行该函数(不能被其他模块导入);
_atexit(): 这个函数(装饰器的方式)会在python解释器中注册一个退出函数,也就是说,它会在脚本退出之前请求调用这个特殊函数;
CleanOutputSet:派生自set类,重写了__str__函数,可以将默认输出改变为将所有元素按照逗号分隔的字符串;
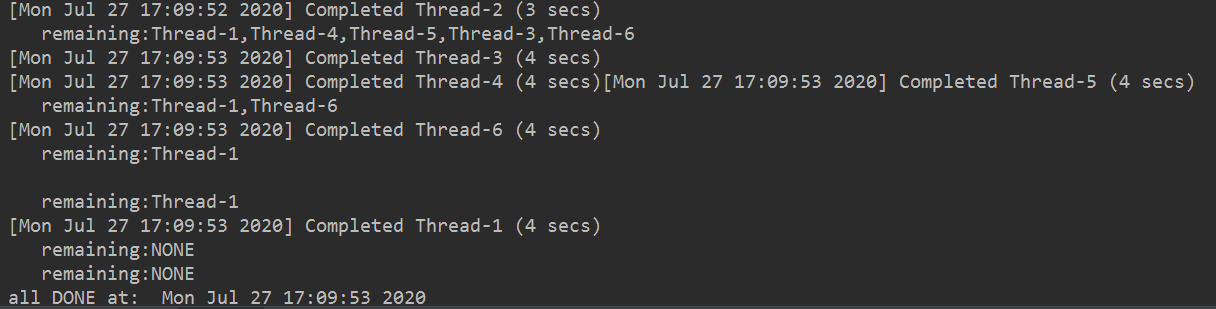
输出可能会混乱;多个线程同时访问一个变量(剩余线程名集合remaining),可能会出现以下输出结果:
3.4、with lock
引入线程锁:
from atexit import register
from random import randrange
from threading import Thread, Lock, current_thread
from time import sleep, ctime
class CleanOutputSet(set):
def __str__(self): # 重写了输出函数
return ','.join(x for x in self)
lock = Lock() # 创建锁
loops = (randrange(2, 5) for x in range(randrange(3, 7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = current_thread().name
lock.acquire() # 获得锁
remaining.add(myname)
print('[%s] Startted %s' % (ctime(), myname))
lock.release() # 释放锁
sleep(nsec)
lock.acquire() # 获得锁
remaining.remove(myname)
print('[%s] Completed %s (%d secs)' % (ctime(), myname, nsec))
print(' remaining:%s' % (remaining or 'NONE'))
lock.release() # 释放锁
def _main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register
def _atexit():
print('all DONE at: ', ctime())
if __name__=='__main__':
_main()引入锁之后当多个线程同时访问同一个变量时,也不会出现输出混乱的情况。
3.5、with lock context
使用lock对象时,还要手动的获取锁与释放锁,这是可以采用lock上下文的方式管理锁(Python2.5以上版本)。使用with语句,此时每一个对象的上下文管理器负责在进入该套件之前调用acquire()并在完成执行后调用realease()。
threading模块的对象Lock、RLock、Condition、Semaphore和BoundedSemaphore都包含上下文管理器,都可以使用with语句,使用with优化后代码如下所示:
def loop(nsec):
myname = current_thread().name
'''
锁的申请和释放交给with上下文管理器
'''
with lock:
remaining.add(myname)
print('[%s] Startted %s' % (ctime(), myname))
sleep(nsec)
with lock:
remaining.remove(myname)
print('[%s] Completed %s (%d secs)' % (ctime(), myname, nsec))
print(' remaining:%s' % (remaining or 'NONE'))loop()函数更加简洁和美观了。
4、thread和threading模块
推荐使用threading模块。
一、threading模块更加先进,有更好的线程支持,而且thread模块中的一些属性会和threading模块有冲突;
二、thread模块(低级别)拥有的同步原语很少(实际上只有一个),而threading模块的同步原语则有多个;
三、thread模块对线程何时退出没有控制,当主线程结束时,所有线程也都强制结束,不会发出警告或者进行适当的清理,threading模块则能确保重要的子线程在进程退出前结束。(重要的:守护线程标记)。
四、threading模块支持守护进程,其工作方式为:守护线程一般是一个等待客户端请求服务的服务器,如果没有客户端请求,守护线程就是空闲的,如果把一个线程设置为守护线程,就表示这个线程是不重要的,进程退出时不需要等待这个线程执行完成















 3244
3244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









