










Deep Reinforcement Learning for List-wise Recommendations
文章目录
1. 论文所解决的问题
- 构建了一个在线的用户-Agent交互环境模拟器,该模拟器适用于模拟在线推荐系统,以在离线的情况下对参数进行预训练和评估;
- 提出了一个基于深度强化学习推荐框架:LIRD(LIst-wise Recommendation framework based on
Deep reinforcement learning),该框架适用于具有大型动态项空间的推荐场景,并可显著地降低计算量; - 在真实的电子商务数据集中验证了所提出框架的有效性,并验证了列表式推荐对精准推荐的重要性。
2. 交互模型
LIRD算法中用户与推荐系统的交互模型是基于MDP模型建立的: M D P = ( S , A , P , R , γ ) MDP=(S,A,P,R,\gamma) MDP=(S,A,P,R,γ)主要包含以下几个参数变量:
-
S
S
S: State space
S = { s 1 , s 2 , . . . , s t , . . . , s T } , s t = { s t 1 , s t 2 , . . . , s t N } S=\{s_1,s_2,...,s_t,...,s_T\},s_t=\{s_t^1,s_t^2,...,s_t^N\} S={s1,s2,...,st,...,sT},st={st1,st2,...,stN},即状态空间,定义为用户的历史浏览记录,即用户在时间 t t t之前浏览的前 N N N个项目。 s t s_t st(session)中的浏览项按时间顺序排序; -
A
A
A: Action space
A = { a 1 , a 2 , . . . , a t , . . . , a T } , a t = { a t 1 , a t 2 , . . . , a t K } A=\{a_1,a_2,...,a_t,...,a_T\},a_t=\{a_t^1,a_t^2,...,a_t^K\} A={a1,a2,...,at,...,aT},at={at1,at2,...,atK},即动作空间,是当前状态 s t s_t st向用户推荐的推荐列表,其中 K K K是RA(Recommender Agent)每次推荐用户的项的数量; -
R
R
R: Reward
R = r ( s t , a t ) R=r(s_t,a_t) R=r(st,at),即立即反馈值,RA在 s t s_t st时推荐了项目列表 a t a_t at后,即向用户推荐项目列表后,用户会浏览这些其中的项目并提供反馈。用户可以跳过(不点击)、点击或订购其中的项目,RA将根据用户的反馈获得立即反馈。 -
P
P
P: Transition probability
P = p ( s t + 1 ∣ s t , a t ) P=p(s_{t+1}|s_t,a_t) P=p(st+1∣st,at),即状态转移概率,定义为RA推荐项目列表 a t a_t at后从状态 s t s_t st转移到 s t + 1 s_{t+1} st+1的概率。 P P P满足MDP的定义,即: P = p ( s t + 1 ∣ s t , a t , s t − 1 , a t − 1 . . . , s 1 , a 1 ) = p ( s t + 1 ∣ s t , a t ) P=p(s_{t+1}|s_t,a_t,s_{t-1},a_{t-1}...,s_1,a_1)=p(s_{t+1}|s_t,a_t) P=p(st+1∣st,at,st−1,at−1...,s1,a1)=p(st+1∣st,at)如果用户在状态 s t s_t st时不点击任何 a t a_t at中的项目,则下一个状态 s t + 1 = s t s_{t+1}=s_t st+1=st;如果用户点击、订购项目列表 a t a_t at中的项目,则下一个状态 s t + 1 s_{t+1} st+1将进行更新。 -
γ
\gamma
γ: Discount factor
γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1],即折扣因子,定义为对未来奖励的现值的折扣系数。当 γ = 0 \gamma=0 γ=0时,RA只计算立即反馈;当 γ = 1 \gamma=1 γ=1时,未来所有的反馈都被完全计入在 a t a_t at中。
3. 交互模拟器
说明:
交互模拟器用于模拟在线状态时的用户与推荐系统的交互数据。在线情况时,给定当前状态
s
t
s_t
st,RA(Recommender Agent)向用户推荐一个项目列表
a
t
a_t
at,用户浏览对
a
t
a_t
at中的项目
a
t
i
a_t^i
ati做出反馈(跳过、点击、订购等)。RA会根据用户的反馈获得立即反馈
r
(
s
t
,
a
t
)
r(s_t,a_t)
r(st,at)。模拟在线情况时,可以根据当前状态和选定的行动来预测奖励,然后将
s
t
,
a
t
,
r
t
s_t,a_t,r_t
st,at,rt存储起来。
3.1. 用在线数据构建存储
算法1 构建在线模拟器的存储
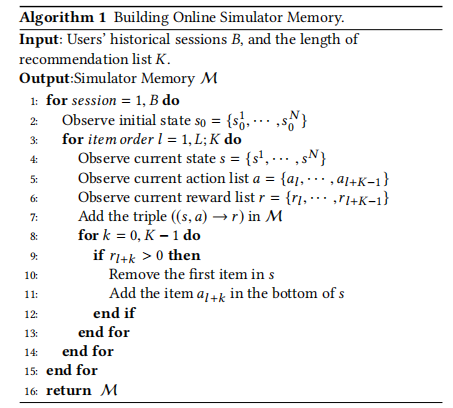
符号解释:
- M M M: M = { m 1 , m 2 , . . . , m i , . . . } M=\{m_1,m_2,...,m_i,...\} M={m1,m2,...,mi,...},存储。来存储用户的历史浏览历史,每一个 m i m_i mi都代表了一个交互元组 ( ( s i , a i ) → r i ) ((s_i,a_i)\to r_i) ((si,ai)→ri);
- B B B: B = { a 1 , a 2 , . . . , a l , . . . , a L } B=\{a_1,a_2,...,a_l,...,a_L\} B={a1,a2,...,al,...,aL},用户会话记录集合,即推荐项集合;
- s 0 s_0 s0: s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0={s01,s02,...,s0N},用户过去的会话记录,即用户在过去会话中曾经浏览、点击、购买过的物品,可能为空(如果是新用户),也可能已经有记录(之前会话留下的记录)。理论上来说,当前状态 s s s之前的所有状态全部可以视作初始状态 s 0 s_0 s0;但实际上,由于 s s s的大小是固定的,因此 s 0 s_0 s0实际是指当前状态 s s s的前一状态,例如当前状态是 s t s_t st,则 s 0 = s t − 1 s_0=s_{t-1} s0=st−1;
- s s s: s = { s 1 , s 2 , . . . , s L } s=\{s^1,s^2,...,s^L\} s={s1,s2,...,sL},用户当前的会话记录,即用户在当前会话浏览、点击、购买过的物品。大小固定为 L L L,只能存储近期的记录。在会话开始时, s = s 0 s=s_0 s=s0,随着用户与系统的交互逐渐更新;
- K K K:即推荐列表长度,它在 s s s中以滑动窗口的形式读取用户历史会话记录;
- a a a: a = { a l , a l + 1 , . . . , a l + k , . . . a l + K − 1 } ∈ B a=\{a_l,a_{l+1},...,a_{l+k},...a_{l+K-1}\}\in B a={al,al+1,...,al+k,...al+K−1}∈B,推荐列表。其中 a l + k a_{l+k} al+k代表推荐列表中的一个推荐项,用户可以对它做出浏览、点击、购买等行为,同时会产生对应的反馈值,之所以是从 a L a_L aL开始是因为在过去的会话。随着用户与推荐列表 a a a中推荐项的交互, a l + k a_{l+k} al+k会逐个追加到 s s s中;
- r r r: r = { r l , r l + 1 , . . . r l + k , . . . r l + K − 1 } r=\{r_l,r_{l+1},...r_{l+k},...r_{l+K-1}\} r={rl,rl+1,...rl+k,...rl+K−1},反馈值列表。其中 r l + k r_{l+k} rl+k代表对应推荐项 a l + k a_{l+k} al+k的反馈值。
输入:
- 用户的历史会话 B B B
- 推荐列表的长度 K K K
输出:
- 在线数据存储 M M M
流程:
- 循环 取出 B B B中的每一个会话 s e s s i o n = 1 , . . . , B session=1,...,B session=1,...,B:
- \qquad 观测先前会话的初始状态 s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0={s01,s02,...,s0N}
- \qquad 循环 按时间顺序观测 K K K个项目, K K K是 l l l上的滑动窗口:
- \qquad\qquad 观测当前状态列表 s = { s 1 , s 2 , . . . , s N } s=\{s^1,s^2,...,s^N\} s={s1,s2,...,sN}
- \qquad\qquad 观测当前的项目 a = { a l , a l + 1 , . . . , a l + K − 1 } a=\{a_l,a_{l+1},...,a_{l+K-1}\} a={al,al+1,...,al+K−1}
- \qquad\qquad 观测当前项目的反馈值 r = { r l , r l + 1 , . . . , r l + K − 1 } r=\{r_l,r_{l+1},...,r_{l+K-1}\} r={rl,rl+1,...,rl+K−1}
- \qquad\qquad 将元组 ( ( s , a ) → r ) ((s,a)\to r) ((s,a)→r)存储在 M M M中
- \qquad\qquad 循环 获取每一个推荐项 a l + k a_{l+k} al+k和对应反馈项 r l + k r_{l+k} rl+k , k = 1 , , , . K − 1 ,k=1,,,.K-1 ,k=1,,,.K−1:
- \qquad\qquad\qquad 若 r l + k > 0 r_{l+k}>0 rl+k>0,即用户对推荐项 a l + k a_{l+k} al+k产生了行为:
- \qquad\qquad\qquad\qquad 移除 s s s的第一个元素
- \qquad\qquad\qquad\qquad 向 s s s的末尾追加项目 a l + k a_{l+k} al+k
- 返回 M M M
3.2. 生成模拟数据
(1)直接映射法
在线环境下,RA可以直接从用户与推荐列表的交互中获取反馈值,但是在模拟数据中如何获取反馈值呢?一个简单办法是通过计算模拟生成的“状态-动作对”与存储 M M M中已存在的“状态-动作对”的相似度来选取的。
为了计算模拟生成的 ( s t , a t ) (s_t,a_t) (st,at)对与 M M M中的每对 ( s i , a i ) (s_i,a_i) (si,ai)对的相似性 模拟生成的“状态-动作对”: p t ( s t , a t ) \text{模拟生成的“状态-动作对”:}p_t(s_t,a_t) 模拟生成的“状态-动作对”:pt(st,at) 在线存储的“状态-动作对”: m i ( ( s i , a i ) → r i ) \text{在线存储的“状态-动作对”:}m_i((s_i,a_i)\to r_i) 在线存储的“状态-动作对”:mi((si,ai)→ri)采用余弦相似度对 p t p_t pt和 m i m_i mi的相似度进行计算: C o s i n e ( p t , m i ) = α s t s i T ∥ s t ∥ ∥ s i ∥ + ( 1 − α ) a t a i T ∥ a t ∥ ∥ a i ∥ Cosine(p_t,m_i)=\alpha\frac{s_ts_i^T}{\Vert s_t\Vert\Vert s_i \Vert}+(1-\alpha)\frac{a_ta_i^T}{\Vert a_t\Vert\Vert a_i \Vert} Cosine(pt,mi)=α∥st∥∥si∥stsiT+(1−α)∥at∥∥ai∥ataiT前一项评估状态相似度,后一项评估动作相似度,参数 α \alpha α控制两个相似度的权重。 p t p_t pt与 m i m_i mi越相似, p t p_t pt能获得对应反馈值 r t r_t rt的概率越高,可以用以下公式将 p t p_t pt映射到 r i r_i ri: P ( p t → r i ) = C o s i n e ( p t , m i ) ∑ m j ∈ M C o s i n e ( p t , m j ) P(p_t\to r_i)=\frac{Cosine(p_t,m_i)}{\sum_{m_j\in M}Cosine(p_t,m_j)} P(pt→ri)=∑mj∈MCosine(pt,mj)Cosine(pt,mi)
要注意的是,这里的映射概率并不是独立的,而是合并的,也就是说,计算出所有的 P = { P ( p 1 → r 1 ) , . . . , P ( p t → r i ) , . . . } P=\{P(p_1\to r_1),...,P(p_t\to r_i),...\} P={P(p1→r1),...,P(pt→ri),...}后,其和 ∑ P = 1 \sum P=1 ∑P=1(想象一个饼状图),总有一个 r i r_i ri会被选到, P ( p t → r i ) P(p_t\to r_i) P(pt→ri)越大越容易被选到。
直接映射法依概率选取反馈值后,得到的是与推荐列表 a t a_t at对应的反馈值向量 r i r_i ri(记录了每个推荐项的反馈值)。
(2)分组映射法
为了降低 P ( p t → r i ) P(p_t\to r_i) P(pt→ri)的计算复杂度,论文不直接把 p t p_t pt映射到单个 m i m_i mi的反馈值,而是映射到反馈值的分组 U x \mathcal{U}_x Ux。
这样做的好处显而易见,例如现在有有一个大小为2的推荐列表,用户跳过/点击/订购推荐项的奖励分别为0、1、5,如果每次都向具体的反馈值映射,则映射的总数为 2 M 2 M 2M,而向分组映射时映射的总数为 9 9 9, 9 < < 2 M 9<<2M 9<<2M: U = { U 1 , U 2 , . . . U x , . . . U 9 } = { ( 0 , 0 ) , ( 1 , 0 ) , ( 0 , 1 ) , ( 1 , 1 ) , ( 5 , 0 ) , ( 0 , 5 ) , ( 1 , 5 ) , ( 5 , 1 ) , ( 5 , 5 ) } \mathcal{U}=\{\mathcal{U}_1,\mathcal{U}_2,...\mathcal{U}_x,...\mathcal{U}_9\}=\{(0,0),(1,0),(0,1),(1,1),(5,0),(0,5),(1,5),(5,1),(5,5)\} U={U1,U2,...Ux,...U9}={(0,0),(1,0),(0,1),(1,1),(5,0),(0,5),(1,5),(5,1),(5,5)}
将 p t p_t pt映射到 U x \mathcal{U}_x Ux的计算公式为: P ( p t → U x ) = ∑ r i = U x C o s i n e ( p t , m i ) ∑ m j ∈ M C o s i n e ( p t , m j ) = N x ( α s t s x − T ∥ s t ∥ + ( 1 − α ) a t a x − T ∥ a t ∥ ) ∑ U y ∈ U N y ( α s t s y − T ∥ s t ∥ + ( 1 − α ) a t a y − T ∥ a t ∥ ) P(p_t\to \mathcal{U}_x)=\frac{\sum_{r_i= \mathcal{U}_x}Cosine(p_t,m_i)}{\sum_{m_j\in M}Cosine(p_t,m_j)}=\frac{\mathcal{N}_x(\alpha\frac{s_t{s^-_x}^T}{\Vert s_t\Vert}+(1-\alpha)\frac{a_t{a^-_x}^T}{\Vert a_t\Vert})}{\sum_{\mathcal{U}_y\in\mathcal{U}}\mathcal{N}_y(\alpha\frac{s_t{s^-_y}^T}{\Vert s_t\Vert}+(1-\alpha)\frac{a_t{a^-_y}^T}{\Vert a_t\Vert})} P(pt→Ux)=∑mj∈MCosine(pt,mj)∑ri=UxCosine(pt,mi)=∑Uy∈UNy(α∥st∥stsy−T+(1−α)∥at∥atay−T)Nx(α∥st∥stsx−T+(1−α)∥at∥atax−T)
其中, N x \mathcal{N}_x Nx是指具有 r = U x r=\mathcal{U}_x r=Ux的用户的历史浏览历史记录组的大小; s x − s^-_x sx−和 a x − a^-_x ax−是 r = U x r=\mathcal{U}_x r=Ux的平均状态向量和平均动作向量: s x − = 1 N x ∑ r i = U x s i ∥ s i ∥ , a x − = 1 N x ∑ r i = U x a i ∥ a i ∥ s^-_x=\frac{1}{\mathcal{N}_x}\sum_{r_i=\mathcal{U}_x}\frac{s_i}{\Vert s_i\Vert},\quad a^-_x=\frac{1}{\mathcal{N}_x}\sum_{r_i=\mathcal{U}_x}\frac{a_i}{\Vert a_i\Vert} sx−=Nx1ri=Ux∑∥si∥si,ax−=Nx1ri=Ux∑∥ai∥ai在实际操作中, N x \mathcal{N}_x Nx、 s x − s^-_x sx−和 a x − a^-_x ax−每1000个episodes更新一次。
之后,依概率 P ( p t → U x ) P(p_t\to \mathcal{U}_x) P(pt→Ux)就可以得到一个反馈值向量 U x \mathcal{U}_x Ux(记录了每个推荐项的反馈值)。
(3)推荐列表的整体反馈值
为了把反馈值向量
a
i
a_i
ai或
U
x
\mathcal{U}_x
Ux转换为对推荐列表
a
t
a_t
at的反馈值
r
t
r_t
rt,可以用下列公式进行计算:
r
t
=
∑
k
=
1
K
Γ
k
−
1
U
x
k
r_t=\sum_{k=1}^{K}\Gamma^{k-1}\mathcal{U}_x^k
rt=k=1∑KΓk−1Uxk其中,
k
k
k是推荐列表中推荐项的顺序;
Γ
∈
(
0
,
1
]
\Gamma\in(0,1]
Γ∈(0,1]。显然,由于
Γ
\Gamma
Γ的存在,推荐列表前部的推荐项对整体的反馈值会有更高的贡献,这使得RA更容易在推荐列表的前部向用户推荐高反馈值的推荐项。
到此,由 p t ( s t , a t ) → r t p_t(s_t,a_t)\to r_t pt(st,at)→rt就可以组成一条模拟数据 ( s t , a t , r t ) (s_t,a_t,r_t) (st,at,rt)了。
4. Actor-Critic框架

4.1. Actor网络
说明:
Actor网络是一个列表型的项推荐程序,它括两个部分,即:
- 生成特定状态的评分函数参数
评分函数用于根据用户当前的特定状态(有过动作的推荐项记录,例如点击、购买等)对推荐项进行评分,Actor网络用于生成评分函数的参数。 - 生成推荐动作。
算法2 列表型项推荐算法

符号解释:
- f θ π f_{\theta^\pi} fθπ: f θ π : s t → w t f_{\theta^\pi}:s_t\to w_t fθπ:st→wt,即Actor,是一个神经网络,用于根据用户当前的特定状态 s t s_t st生成评分函数的权重参数 w t w_t wt向量( w t w_t wt就是 s t s_t st中每一个元素的Q值向量); θ π \theta^\pi θπ是神经网络的参数;
- s o c r e i socre_i socrei: s o c r e i = w t k e i T socre_i=w_t^ke_i^T socrei=wtkeiT,项 i i i的评分。 w t k w_t^k wtk是指状态 s t s_t st时推荐项 i i i对应的第 k k k个权重参数(由 f θ π f_{\theta^\pi} fθπ生成); e i e_i ei是项空间 I I I中第 i i i个推荐项的嵌入值( e i e_i ei的维度与 s t s_t st相同); T T T是转置的意思。
输入:
- 当前的特定状态 s t s_t st
- 项空间(动作空间) I I I
- 推荐列表的长度 K K K
输出:
- 特定状态 s t s_t st时的推荐列表 a t a_t at
流程:
- 由 f θ π f_{\theta^\pi} fθπ根据 s t s_t st生成权重向量列表 w t = { w t 1 , . . . , w t K } w_t=\{w_t^1,...,w_t^K\} wt={wt1,...,wtK}
- 循环 k = 1 , . . . , K k=1,...,K k=1,...,K:
- \qquad 对 I I I中的所有项 i i i进行评分
- \qquad 选择评分 s o c r e i socre_i socrei最高的项目 a l k a_l^k alk
- \qquad 将项目 a l k a_l^k alk追加到推荐列表 a t a_t at中
- \qquad 从 I I I中去除 a l k a_l^k alk
- 返回 推荐列表 a t a_t at
4.2. Critic网络
Critic网络用于学习 Q ( s t , a t ) Q(s_t,a_t) Q(st,at),该Q值用于判断Actor产生的动作 a t a_t at是否与当前状态 s t s_t st相匹配。然后,根据Q值更新Actor的参数,改进Actor以生成更佳的动作。
由于Actor网络已经提供了确定性的 a t a_t at,因此Critic网络计算Q值的公式为: Q ( s t , a t ) = E s t + 1 [ r t + γ Q ( s t + 1 , a t + 1 ) ∣ s t , a t ] Q(s_t,a_t)=\mathbb{E}_{s_{t+1}}[r_t+\gamma Q(s_{t+1},a_{t+1})|s_t,a_t] Q(st,at)=Est+1[rt+γQ(st+1,at+1)∣st,at]即Q值为持续利用Actor生成 a t a_t at所获得的 r t r_t rt的折扣期望值,该Q值将用于 f θ π f_{\theta^\pi} fθπ的参数更新。
在论文中,用神经网络来拟合Q值(DQN),即有: Q ( s t , a t ) ≈ Q ( s t , a t ; θ μ ) = = E s t + 1 [ r t + γ Q ( s t + 1 , a t + 1 ; θ μ ) ∣ s t , a t ] Q(s_t,a_t)\approx Q(s_t,a_t;\theta^\mu)==\mathbb{E}_{s_{t+1}}[r_t+\gamma Q(s_{t+1},a_{t+1};\theta^\mu)|s_t,a_t] Q(st,at)≈Q(st,at;θμ)==Est+1[rt+γQ(st+1,at+1;θμ)∣st,at]其中, θ μ \theta^\mu θμ是DQN神经网络的参数。DQN的损失函数定义如下: L ( θ μ ) = E s t , a t , r t , s t + 1 [ ( y t − Q ( s t , a t ; θ μ ) 2 ) ] L(\theta^\mu)=\mathbb{E}_{s_t,a_t,r_t,s_{t+1}}[(y_t-Q(s_t,a_t;\theta^\mu)^2)] L(θμ)=Est,at,rt,st+1[(yt−Q(st,at;θμ)2)]在实践中使用随机梯度下降法来优化损失函数 L ( θ μ ) L(\theta^\mu) L(θμ),在优化损失函数的时候,参数 θ μ \theta^\mu θμ会被更新。
在 L ( θ μ ) L(\theta^\mu) L(θμ)中, y t y_t yt是每次迭代时的目标价值(目标Critic网络的Q值): y t = E s t + 1 [ r t + γ Q ′ ( s t + 1 , a t + 1 ; θ μ ′ ) ∣ s t , a t ] y_t=\mathbb{E}_{s_{t+1}}[r_t+\gamma Q'(s_{t+1},a_{t+1};{\theta^\mu}')|s_t,a_t] yt=Est+1[rt+γQ′(st+1,at+1;θμ′)∣st,at]之所以 y t y_t yt选用目标网络进行计算,是因为 Q ′ Q' Q′网络由 Q Q Q网络更新而来,在计算损失函数时参数 θ μ \theta^\mu θμ的差异不至于过大,可以让 Q Q Q网络的更新更加稳定,使得收敛方向更加确定。
6. 训练过程
6.1. 整体流程
算法3. 使用DDPG算法对所提出的DEV框架进行参数训练的过程

符号解释:
- M M M: M = { m 1 , m 2 , . . . , m i , . . . } M=\{m_1,m_2,...,m_i,...\} M={m1,m2,...,mi,...},存储。来存储用户的历史浏览历史,每一个 m i m_i mi都代表了一个交互元组 ( ( s i , a i ) → r i ) ((s_i,a_i)\to r_i) ((si,ai)→ri);
- s 0 s_0 s0: s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0={s01,s02,...,s0N},用户过去的会话记录,即用户在过去会话中曾经浏览、点击、购买过的物品,可能为空(如果是新用户),也可能已经有记录(之前会话留下的记录)。简单来说,当前状态 s s s之前的所有状态全部可以视作初始状态 s 0 s_0 s0;
- T T T:会话内所经历的时间步;
- K K K:推荐列表的长度;
- N N N:是minibatch中数据量的大小,也指时间步的数量,也指训练时episode的数量;
- τ \tau τ: τ = 0.001 \tau=0.001 τ=0.001,是更新目标Actor和Critic网络时平衡之前网络参数与更新参数之间的权重
初始化:
- 随机初始化actor网络 f θ π f_{\theta^\pi} fθπ和critic网络 Q ( s , a ∣ θ μ ) Q(s,a|\theta^\mu) Q(s,a∣θμ)的权重;
- 使用 f θ π f_{\theta^\pi} fθπ和 Q ( s , a ∣ θ μ ) Q(s,a|\theta^\mu) Q(s,a∣θμ)的权值初始化目标网络 f ′ f' f′和 Q ′ Q' Q′;
- 初始化回放池 D D D的容量
流程:
- 循环 获取 M M M中的每一个会话, s e s s i o n = 1 , M session=1,M session=1,M:
- \qquad 重置项空间 I I I
- \qquad 从先前的会话中初始化初始状态 s 0 s_0 s0
- \qquad 循环 获取会话中的每一个时间步 t = 1 , T t=1,T t=1,T:
- \qquad\qquad 阶段1:状态转移生成阶段
- \qquad\qquad 根据算法二选择动作(推荐列表) a t = { a t 1 , . . . , a t K } a_t=\{a_t^1,...,a_t^K\} at={at1,...,atK}
- \qquad\qquad 向用户展示推荐列表 a t a_t at,并且获得其中每一个推荐项的反馈值,组成反馈列表 { r t 1 , . . . , r t K } \{r_t^1,...,r_t^K\} {rt1,...,rtK}。该反馈值列表只用于选取 a l k a_l^k alk,不是推荐列表 a t a_t at的反馈值。
- \qquad\qquad 初始化下一个状态的值 s t + 1 = s t s_{t+1}=s_t st+1=st
- \qquad\qquad 循环 获取每一个推荐项 a t k a_t^k atk和对应反馈项 r t k r_t^k rtk,k=1,K:
- \qquad\qquad\qquad 若 反馈值 r t k > 0 r_t^k>0 rtk>0,即用户对推荐项 a t k a_t^k atk产生了行为
- \qquad\qquad\qquad\qquad 在 s t + 1 s_{t+1} st+1中追加 a t k a_t^k atk
- \qquad\qquad\qquad\qquad 移除 s t + 1 s_{t+1} st+1的首位元素
- \qquad\qquad 根据 s t s_t st和 a t a_t at计算推荐列表的反馈值 r t r_t rt
- \qquad\qquad 在 D D D中存储状态转移 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- \qquad\qquad 转移到下一个状态 s t = s t + 1 s_t=s_{t+1} st=st+1
- \qquad\qquad 阶段2:参数更新阶段
- \qquad\qquad 从 D D D中采样含有 N N N个转移 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)的minibatch(经验回放)
- \qquad\qquad 根据算法2通过目标Actor网络在状态 s ′ s' s′时生成推荐列表 a ′ a' a′
- \qquad\qquad 设定目标价值 y = r + γ Q ′ ( s ′ , a ′ ; θ μ ′ ) y=r+\gamma Q'(s',a';{\theta^\mu}') y=r+γQ′(s′,a′;θμ′)
- \qquad\qquad 用梯度下降法最小化损失 ( y − Q ( s , a ; θ μ ) ) (y-Q(s,a;{\theta^\mu})) (y−Q(s,a;θμ))以更新Critic网络: ∇ θ μ L ( θ μ ) ≈ 1 N [ ( y − Q ( s , a ; θ μ ) ) ∇ θ μ Q ( s , a ; θ μ ) ] \nabla_{\theta^\mu}L(\theta^\mu)\approx \frac{1}{N}[(y-Q(s,a;{\theta^\mu}))\nabla_{\theta^\mu}Q(s,a;{\theta^\mu})] ∇θμL(θμ)≈N1[(y−Q(s,a;θμ))∇θμQ(s,a;θμ)]
- \qquad\qquad 用采样策略梯度法更新Actor网络: ∇ θ π f θ π ≈ 1 N ∑ i ∇ a Q ( s , a ; θ μ ) ∇ θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\approx \frac{1}{N}\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ∇θπfθπ≈N1i∑∇aQ(s,a;θμ)∇θπfθπ(s)
- \qquad\qquad 更新目标Critic网络: θ μ ′ = τ θ μ + ( 1 − τ ) θ μ ′ {\theta^\mu}'=\tau {\theta^\mu}+(1-\tau){\theta^\mu}' θμ′=τθμ+(1−τ)θμ′
- \qquad\qquad 更新目标Actor网络: θ π ′ = τ θ π + ( 1 − τ ) θ π ′ {\theta^\pi}'=\tau {\theta^\pi}+(1-\tau){\theta^\pi}' θπ′=τθπ+(1−τ)θπ′
在训练完成之后,RA就可以得到训练好的参数,即 θ μ \theta^\mu θμ和 θ π \theta^\pi θπ,之后就可以在模拟环境中进行模型测试了。模型测试的方法也是算法3,即参数在测试阶段也可以被不断更新,与训练阶段的主要区别是测试阶段会在每次获取会话之前重置 θ μ \theta^\mu θμ和 θ π \theta^\pi θπ,以便在每个推荐阶段之间进行公平比较。
6.2. 对Actor网络更新的说明
采用策略梯度法更新Actor网络的思路是 Q ( s , a ; θ μ ) Q(s,a;{\theta^\mu}) Q(s,a;θμ)中输入的 a a a与 f θ π ( s ) f_{\theta^\pi}(s) fθπ(s)(经评分后)输出的是一致的, Q ( s , a ; θ μ ) Q(s,a;{\theta^\mu}) Q(s,a;θμ)中输入的 s s s与 f θ π ( s ) f_{\theta^\pi}(s) fθπ(s)的输入 s s s是一致的,因此有 f θ π ( s ) f_{\theta^\pi}(s) fθπ(s)的梯度为: ∇ f θ π ( s ) = ∑ i ∇ a Q ( s , a ; θ μ ) f θ π ( s ) \nabla f_{\theta^\pi}(s)=\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})f_{\theta^\pi}(s) ∇fθπ(s)=i∑∇aQ(s,a;θμ)fθπ(s)其中 i i i代表一个时间步的 ( s , a ) (s,a) (s,a)。再进一步求参数 θ π \theta^\pi θπ的梯度得: ∇ θ π f θ π ∝ ∑ i ∇ a Q ( s , a ; θ μ ) ∇ θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\propto\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ∇θπfθπ∝i∑∇aQ(s,a;θμ)∇θπfθπ(s)再对 N N N个episode的梯度求平均得: ∇ θ π f θ π ≈ 1 N ∑ i ∇ a Q ( s , a ; θ μ ) ∇ θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\approx \frac{1}{N}\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ∇θπfθπ≈N1i∑∇aQ(s,a;θμ)∇θπfθπ(s)



















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











