







文章目录
摘要
推荐系统通过向用户推荐个性化的商品或服务,在缓解信息超载问题上起到了至关重要的作用。目前绝大多数传统的推荐系统都将推荐过程看作是一个静态的过程,并根据一个固定的策略进行推荐。
在本文中,我们提出了一种新的推荐系统,该系统能够在与用户的交互过程中不断改进策略。我们将用户与推荐系统之间的顺序交互建模为马尔可夫决策过程(MDP),并利用强化学习(RL)自动学习最优策略,方法是推荐试错项( trial-and-error),并从用户反馈中获得这些项的强化。
特别地,我们介绍了一个在线的用户-代理交互环境模拟器,它可以在在线应用模型之前离线地对模型参数进行预训练和评估。此外,我们在用户和代理之间的交互过程中验证了列表明智的建议的重要性,并开发了一种新的方法来将它们合并到建议的框架LIRD中,以实现列表范围的推荐。基于真实电子商务数据集的实验结果验证了该框架的有效性。
一、Introduction
1、基本介绍
这部分先是说明了一下推荐系统的重要性,然后讲述了现有推荐系统存在的两个问题:
- 现有的推荐系统大多将推荐过程看作一个静态的过程,并采用一种固定的贪婪策略进行推荐。无法建模用户兴趣的动态变化。
- 大多数现有的推荐系统都是为了最大限度地提高推荐的即时(短期)回报。忽略了长期收益。
然后介绍了基于强化学习的推荐系统的两个优点。
3. 首先,它们能够在交互过程中不断更新策略,直到系统收敛到最优策略,生成最适合用户动态偏好的建议。
4. 其次,通过最大化用户期望的长期累积奖励来制定最优策略。因此,系统可以识别出即时奖励少但对未来推荐的奖励有很大贡献的项目。
目前已经有利用POMDP和Q-learning等推荐系统进行了强化学习的研究。但是,随着建议项目的增加,这些方法可能变得不灵活。这阻止了它们被实际的推荐系统所采用,也就是工业应用不太行。
因此,我们利用深度强化学习和(自适应)人工神经网络作为非线性逼近器来估计RL中的动作值函数。这种无模型强化学习方法不估计转移概率,不存储Qvalue表。这使得它可以灵活地支持推荐系统中的大量项目。
2、List-wise Recommendations
以前的RL算法如DQN可以单独计算所有被召回物品的q值,并推荐q值最高的物品列表。但是,这些方法基于相同的状态推荐项目,忽略了推荐项目之间的关系。因此,推荐的项目是相似的(比如你买了个游泳圈,就会疯狂给你推荐各种游泳圈)。
于是本文提出了List-wise,计算的是一整个推荐列表的Q-value,可以充分考虑列表中物品的相关性,从而提升推荐的性能。这样更能提供给用户多样性的选择(比如你买了游泳圈,会再给你推荐游泳眼镜、游泳衣等)。
3、Architecture Selection(结构选择)

如上图所示,左边的两个是经典的DQN结构:
- (a)这种结构只需要输入一个state,然后输出是所有动作的Q-value。该体系结构适用于状态空间大、动作空间小的场景,不能处理像推荐系统那样的大型动态动作空间场景。
- (b)的输入时state和一个具体的action,然后模型的输出是一个具体的Q-value,但对于这个模型结构来说,时间复杂度非常高。
因此本文选择的深度强化学习结构是(c),即Actor-Critic结构。
Actor输入一个具体的state,输出一个action,然后Critic输入这个state和Actor输出的action,得到一个Q-value,Actor根据Critic的反馈来更新自身的策略。(注意,Critic与上图中(b)的DQN架构是相同的。)该结构适用于大的动作空间,同时可以减少冗余计算。
4、Online Environment Simulator(在线环境模拟器)
不像网络游戏中使用的深度Q-learning方法,采取任意的行动,都能获得及时的反馈,而在推荐系统上线之前是很难获得在线奖励的。
因此在实际应用中,需要离线对参数进行预训练并对模型进行评估,为了解决这一问题,我们提出了一个在线环境模拟器,它输入当前状态和一个选择的动作,并输出一个模拟的在线奖励,使框架能够根据模拟奖励离线训练参数。
更具体地说,我们是根据用户的历史记录来构建模拟器的。这样构建的理由是无论推荐系统采用何种算法,给定相同的状态(或用户的历史记录)和相同的操作(向用户推荐相同的商品),用户对商品的反馈都是相同的。
5、简单总结
本文的贡献主要有以下三点:
- 构建了一个线上环境仿真器,可以在线下对AC网络参数进行训练。
- 构建了基于强化学习的List-wise推荐系统。
- 在真实的电商环境中,本文提出的推荐系统框架的性能得到了证明。
本文的其余部分组织如下:
在第二部分,我们首先通过强化学习对推荐系统问题进行了形式化的定义。然后,我们提供了将推荐过程建模为连续的用户-代理交互的方法,并详细介绍了如何使用actor -critic框架通过在线模拟器自动学习最优推荐策略。
第三部分基于realword电子商务网站进行了实验,并给出了实验结果。
第四部分简要回顾了相关工作。
最后,第五部分对本文进行了总结,并对今后的工作进行了讨论。
二、THE PROPOSED FRAMEWORK(系统框架)
在这一节中,首先通过强化学习来正式定义符号和推荐系统的问题。然后构建了一个在线的用户-代理交互环境模拟器。在此基础上,我们提出了一个基于actor -critic的强化学习框架。最后,我们讨论了如何通过用户的行为日志来训练这个框架,以及如何利用这个框架来进行列表推荐。
1、问题建模
我们研究了recommender agent(RA)与环境E(或用户)交互的推荐任务,通过在时间步长序列上选择推荐项,使其累积奖励最大化。把这个问题建模为一个马尔可夫决策过程(MDP),它包括一系列的状态、行为和奖励。MDP由五个元素的元组(S,A, P, R,γ)组成,其在推荐系统中的定义如下:
- 状态空间S:定义为用户的浏览历史,即在推荐之前,用户点击或购买过的最新的N个物品。
- 动作空间A:动作定义为要推荐给用户的商品列表。
- 奖励R: agent根据当前的state,采取相应的action即推荐K个物品列表给用户之后,根据用户对推荐列表的反馈(忽略、点击或购买)来得到当前state-action的即时奖励reward。
- 转移概率P: 在本文中,状态的转移定义如下定义,当前的state是用户最近浏览的N个物品,action是新推荐给用户的K个商品,如果用户忽略了全部的这些商品,那么下一个时刻的state和当前的state是一样的,如果用户点击了其中的两个物品,那么下一个时刻的state是在当前state的基础上,从前面剔除两个商品同时将点击的这两个物品放在最后得到的。
- 折扣因子γ: γ∈[0,1]
在实践中,仅使用离散索引无法了解不同项目之间的关系。一种常见的方法是使用额外的信息来表示项。例如,我们可以使用属性信息,如品牌、价格、每月销售额等。在本文中没有使用额外的item信息,而是使用user-agent交互信息,即用户浏览历史记录。我们将每个项目视为一个单词,而在一个推荐会话中单击的项目视为一个句子。然后,我们可以通过字嵌入得到项目的稠密低维向量表示。
也就是说,本文中将物品当作一个单词,通过embedding的方式表示每一个物品,因此每一个state和action都是通过word embedding来表示的。

图2说明了MDP中的agent与user的交互。 通过与环境(用户)互动,推荐系统的agent对用户推荐item,而且不是乱推荐的,这份推荐结果要使预期收益最大化,其中包括延迟的回报。 我们遵循以下标准假设:延迟奖励在每个时间步长上被折除γ倍。
通过上面的符号和定义,列表项推荐的问题可以正式定义如下:给定历史MDP,即(S,A,P,R,γ),目标是找到推荐策略π :S→A,可以最大化推荐系统的累积奖励。
2、User-Agent交互环境模拟器
为了应对训练我们的框架和离线评估框架性能的挑战,在本小节中,我们提出了一个在线的user-agent交互环境模拟器。
在线推荐过程中,给定当前状态st,RA向用户推荐项目列表,并且用户浏览这些项目并提供她的反馈,即跳过/单击/订购部分推荐项目。 RA根据用户的反馈立即收到奖励r(st,at)。 为了模拟上述在线交互过程,模拟器的任务是基于当前状态和所选择的动作,即f:(st,at)→rt来预测奖励。
根据协作过滤技术,具有共同历史记录的人类将对同一项目做出类似的决定。 有了这个假设,我们将state和action总结成state-action对,并随机生成模拟奖励。
更具体地说,我们首先建立一个内存M = {m1,m2,···}存储用户的历史浏览历史记录,其中mi是user-agent交互三元组((si,ai)→ri)。

算法1中建立的在线仿真内存,给出来一些历史推荐反馈的case {a1,···,aL},我们可以从历史的session中观察到初始会话的初始状态s0 = {s1,···,sN}(第2行)。每次我们按时间顺序观察K个item(第3行),其中“ l = 1,L; K”表示每次迭代将向前移动K大小的窗口。我们可以观察到当前状态(第4行),当前K项(第5行),以及用户对这些项的反馈(第6行),然后我们将三元组((s,a)→r)存储在内存中(第7行)。最后,我们更新状态(第8-13行) ,然后移至下K个项目。由于我们保持固定长度的状态s = {s1,···,sN},因此,每次用户单击/购买推荐列表中的某些item时,我们都将这些item添加到状态集中,并在该状态的头部删除相同数量的项目,就相当于一个先进先出的队列。例如,RA建议使用以下列表向用户提供五个项目{a1,···,a5},如果用户单击a1、购买a5,则更新为{s3,···,sN,a1,a5}。
有了历史记忆之后,仿真器就可以输出没有见过的(state,action)对的奖励,该(state,action)定义为pt。首先需要计算pt和历史中状态-动作对的相似性,在这项工作中,我们采用余弦相似度:
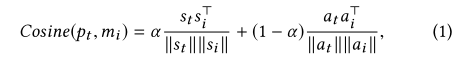
第一项测量状态相似性,第二项评估动作相似性。 参数α控制两个相似度的权重,达到平衡的状态。
直观地说,随着相似度在pt和mi之间的增加,将pt映射到奖励ri的机会更高。 因此,可以将pt→ri的概率定义如下:
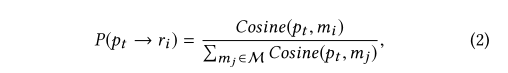
但是这样的计算复杂度太高了,我们必须计算pt与每个mi∈M之间的成对相似度。
为解决这一挑战,我们首先根据奖励将用户的历史浏览进行分组。 请注意,奖励排列的数量通常受到限制。 例如,RA每次向用户推荐两项,用户跳过/点击/订购一项的奖励为0/1/5,则两项奖励的排列有9,即U = {U1, ···,U9} = {(0,0),(0,1),(0,5),(1,0),(1,1),(1,5),(5,0), (5,1),(5,5)},比历史记录的总数小得多。
这九种情况就是我们刚才所说的奖励序列,定义为:
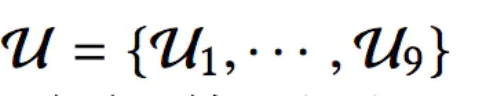
因此,将历史记忆按照奖励序列进行分组,pt所能获得某个奖励序列的概率是:

我们假定ri是我们推荐给用户items后,用户给我们的反馈状态的奖励列表。比如 ri的取值是(1,5)也就是说用户对这次的两个推荐结果是一次点击、一次购买。N(x)是用户浏览历史行为分成的组的size。
r=u(x)*s(x)。s(x)是state的平均向量,a(x)是推荐列表的平均向量,我们只需要预计算 U(x)、s(x)、a(x)这三个变量的相似度,还可以根据上面公式3中的概率把 pt 分发到 U(x) 这个列表中去逐个计算。在训练模型的时候,RA会每1000个迭代步就更新一次 N(x)、s(x)、a(x)。因为|U|比整个的历史记录中的记录要远小。公式3可以很有效率的把pt分发到奖励列表U(x)中
基于上面的公式,我们只是得到了pt所能获得的奖励序列的概率,就可以进行采样得到具体的奖励序列。得到奖励序列还没完事,实际中我们的奖励都是一个具体的值,而不是一个vector,那么按照如下的公式将奖励序列转化为一个具体的奖励值:
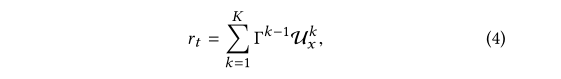
其中k是推荐列表中的顺序,K是推荐列表的长度,并且Γ∈(0,1]。等式(4)的推荐对推荐列表的顶部有更高的贡献,这迫使RA更专注于推荐列表的顶部排序
3、模型结构
使用强化学习里的AC模型结合刚才提到的仿真器,模型框架如下所示:

下面就来分别解释一下:
1、Actor部分
在上一节中,我们将状态s定义为整个浏览历史,它可以是无限的且效率低下。 更好的方法是只考虑点击、购买的项目,例如最近10个被点击/订购的项目。 一个好的推荐系统应该推荐用户最喜欢的项目。 用户给与正反馈的item代表着有关用户偏好的关键信息,即用户喜欢哪些项。 因此,我们仅将它们用于state-specific的评分功能。
我们的 state-specific 在计算的时候,会把当前 state st 中的每一个元素都设置一个权重,就像公式5中说到的那样。
即,对Actor部分来说,输入是一个具体的state,输出一个K维的向量w,K对应推荐列表的长度:
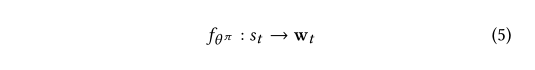
其中fθπ是由θπ参数化的函数,从状态空间映射到权重表示空间。 在这里,我们选择深度神经网络作为参数生成函数。
接下来,我们介绍基于上述评分函数参数的动作生成步骤。 在不损失一般性的前提下,我们假设得分函数参数wkt和项目空间I中第i个项目的嵌入ei是线性相关的。
即,用w和每个item对应的embedding进行线性相乘,计算每个item的得分,根据得分选择k个最高的物品作为推荐结果:
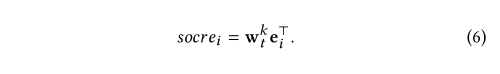
实现过程见下图算法2:
Actor首先生成权重向量列表(第1行)。 对于每个权重向量,RA对项目空间中的所有项目进行评分(第3行),选择得分最高的项目(第4行),然后将此项目添加到推荐列表的末尾。 最终,RA从项目空间中删除了该项目,这阻止了将同一项目推荐给推荐列表。

2、Critic部分
Critic部分建模的是state-action对应的Q值,需要有Q-eval 和 Q-target来指导模型的训练。
Q-eval通过Critic得到,在实际的推荐系统中,状态和动作空间很大,因此无法为每个state-action对估计action-value函数Q(s,a)。 此外,许多state-action对可能不会出现在实际情况中,因此很难更新其值。 因此,使用近似函数来估计动作值函数(即,Q(s,a)≈Q(s,a;θμ))更加灵活和实用。 实际上,action-value函数通常是高度非线性的。 深度神经网络被称为非线性函数的出色近似器。 在本文中,我们将参数为θ μ的神经网络函数逼近器称为深度Q网络(DQN)。 可以通过将损失函数L(θμ)的序列最小化来训练DQN
其损失函数为:
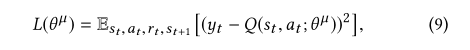
其中,
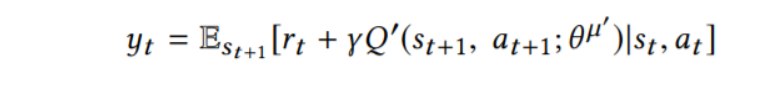
yt是每次迭代的目标值,当优化损失函数的时候,上一次迭代时候的参数是可以被修改的。在实践中,为了计算的效率,通常来通过随机梯度下降来优化损失函数,而不是计算上述梯度中的全部期望。
而Q-target值通过下面的式子得到:
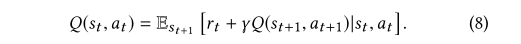
4、训练和测试
1、训练过程

在每次的迭代,都会有两个阶段。(1):过渡时期,lines 8-20,(2):参数更新阶段,lines 21-28。在过渡时期(line 8),给定一个状态 st,RA首先会根据算法2中提出的方法,推荐出来一个列表的 item at={at1,…,atk}。然后智能体从仿真器(line10)获取到用户的反馈 rt,然后更新状态到 st+1,接下来就是算法1中提出来的状态,然后整个程序把 (st,at,rt,st+1)这几个变量储存到内存D中,然后把st=st+1。在参数更新阶段:我们拿出来一个batch的上面 (st,at,rt,st+1),然后更新 Actor、Critic。
在算法中,我们引入了广泛使用的技术来训练我们的框架。 例如,我们利用一种称为“experirnce replay”的技术(第3,22行),并引入了独立的评估和目标网络第2,23行),这有助于平滑学习并避免差异参数。 对于目标网络的软目标更新(第27,28行),我们使用τ= 0.001。 此外,我们利用优先采样策略帮助框架从最重要的历史转变中学习。
2、测试过程
在框架训练阶段之后,RA获得训练有素的参数,即Θπ和Θμ。 然后我们可以在模拟器环境上进行框架测试。 模型测试也遵循算法3,即参数在测试阶段不断更新,而与训练阶段的主要区别是在每次推荐session之前,我们将参数重置回Θπ和Θμ,以便在每个推荐阶段之间进行公平比较。 我们可以人为地控制推荐效果的时长,以研究短期和长期绩效。
三、实验和总结
1、实验部分
1、实验设置
- 数据集:京东2017年7月线上数据,100,000 recommendation sessions (1,156,675 items)
- 评价指标:MAP和NDCG
- baselines: CF, FM, DNN, RNN, DQN
2、实验结果
LIRD是本文提出的算法

2、总结
1、目前优势
提出了一种新颖的框架LIRD,该模型将推荐会话建模为马尔可夫决策过程,并利用深度强化学习自动学习最佳推荐策略。基于强化学习的推荐系统具有两个优点:(1)它们可以在交互过程中不断更新策略,(2)他们能够学习一种策略,该策略可以最大化用户的长期累积奖励。
2、未来方向
有几个有趣的研究方向。 首先,除了我们在这项工作中使用的物品的位置顺序外,我们还想研究更多的顺序,例如时间顺序。
其次,我们想通过更多的座席与用户交互模式进行验证,例如,将项目添加到购物车中,并研究如何对它们进行数学建模以获得建议。
最后,在工作中提出的框架是相当笼统的,我们想研究提出的框架的更多应用,特别是对于具有正(负)信号的应用。
3、代码
https://github.com/luozachary/drl-rec
参考:
https://www.jianshu.com/p/b9113332e33e
https://blog.csdn.net/a1066196847/article/details/104041757















 2209
2209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









