







 本文介绍了如何使用Apache Solr构建全文检索搜索引擎,以满足电商网站商品搜索功能。通过对比数据库的Like模糊搜索和全文索引,选择Solr作为解决方案,并详细阐述了Lucene的工作原理。在实践中,利用IKAnalyzer解决中文分词问题,最后演示了在Linux上搭建Solr服务和使用SolrJ管理索引库的过程。
本文介绍了如何使用Apache Solr构建全文检索搜索引擎,以满足电商网站商品搜索功能。通过对比数据库的Like模糊搜索和全文索引,选择Solr作为解决方案,并详细阐述了Lucene的工作原理。在实践中,利用IKAnalyzer解决中文分词问题,最后演示了在Linux上搭建Solr服务和使用SolrJ管理索引库的过程。
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档。全文检索是目前搜索引擎,大数据搜索的关键技术。全文检索系统可实现亚秒级的检索速度以及每秒上百次的并发检索支持。
需求:
实现淘宝京东等电商网站中商品信息搜索功能,可以根据关键词(分词)、分类、商品简介,详情等搜索商品信息,可以根据相关度,价格,销量等做排序。
比如,我们搜索“实惠的老人机”

要求:
分词检索:比如我们输入:“实惠的老人机”,有效分词: “实惠” ,“老人机”,"“老人", "机”, 无效分词:“的“, 默认按照商品标题,描述,详情,分类等相关度的高低进行排序(我们不学百度高竞价,以搜索关键词相关度为默认排序),并可以按照用户所选条件进行排序。
解决方案:
1.数据库的Like模糊搜索。(不采用)
数据库Like模糊搜索是典型的顺序扫描方法,数据量大就搜索得特别慢。最重要的是无法进行分词检索。
2.数据库的全文索引。(不推荐)
目前各大数据库的全文索引支持性还不是很好。以MySQL为例子:MySQL不支持中文全文检索。虽然支持英文的全文检索但表的存储引擎要是MyISAM,默认存储引擎InnoDB不支持全文索引(MYSQL5.6以上的InnoDB支持全文索引)。但不支持中文分词,所以我们需要自行扩展。
3.采用Apache的顶级开源项目Solr构建索引库构建全文检索引擎,它是基于Lucene的全文搜索服务器。为了扩容和应对高并发,我们还要搭建SolrCloud集群,这里我们搭建最小的集群模块:2台Solr,各有1台备份机,需要4台Servlet服务容器。
什么是lucene?
Lucene是Apache的一个全文检索引擎工具包,通过lucene可以让程序员快速开发一个全文检索功能。
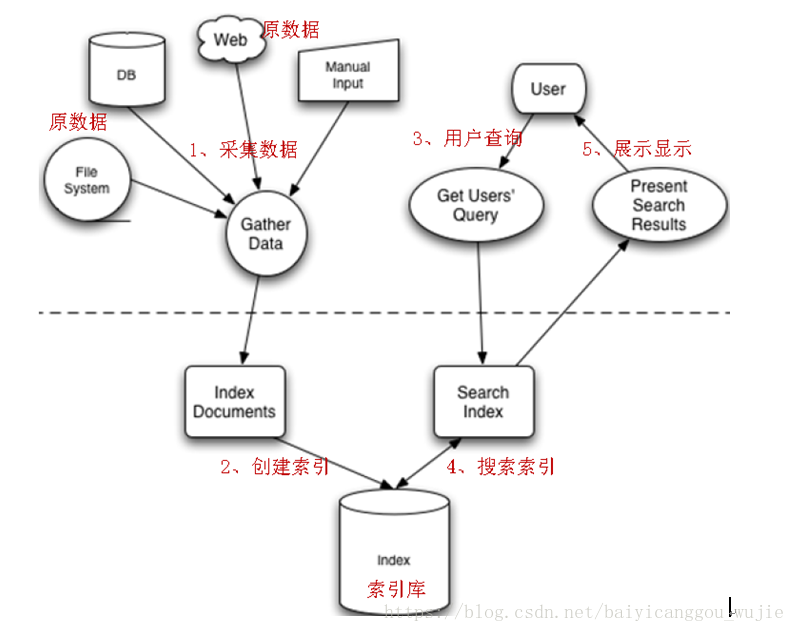
Lucene实现全文检索的流程
想必小伙伴们都用过下面这个Everything文件搜索工具,接下来我们先用Lucene来实现一个"乞丐版的Everything"文件检索系统。
乞丐版的Everything
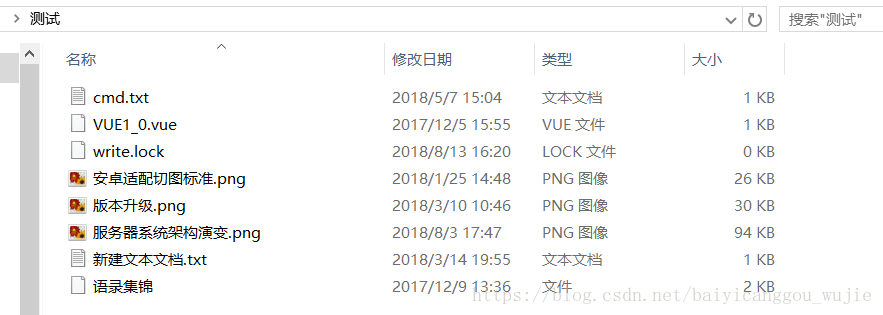
我在”C:\Users\hp\Desktop\测试“下放置了以下文件,现在让我们用Lucene进行文件检索,要求检索文件标题和文件内容中含有相关分词的文件并按照搜索关键词出现的频次降序排列。
// 创建索引
@Test
public void testIndex() throws Exception {
// 创建一个indexwriter对象
Directory directory = FSDirectory.open(new File("C:\\Users\\hp\\Desktop\\index")); //索引库存储路径
// Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库)
Analyzer analyzer = new StandardAnalyzer();// 官方推荐的标准分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 1)指定索引库的存放位置Directory对象
// 2)指定一个分析器,对文档内容进行分析
// 第三步:创建field对象,将field添加到document对象中。
File f = new File("C:\\Users\\hp\\Desktop\\测试"); //源文件目录
File[] listFiles = f.listFiles();
for (File file : listFiles) {
// 创建document对象
Document document = new Document();
// 文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
// 文件大小
long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize", file_size, Store.YES);
// 文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
// 文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent", file_content, Store.YES);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
// 使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库
indexWriter.addDocument(document);
}
// 关闭IndexWriter对象。
indexWriter.close();
}运行结果:成功创建了索引库。
我们搜索文件名有"apache"的相关文件:
// 搜索索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\hp\\Desktop\\index"));
// 第二步:创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词
Query query = new TermQuery(new Term("fileName", "apache"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("搜索到相关文件数:" + topDocs.scoreDocs.length);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println("文件名称:" + fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println("文件内容:" + fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println("文件大小:" + fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println("文件路 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









