






任务目标
通过deepseek的数据集,蒸馏Qwen等模型,使其输出具有<think>标签,也就是说使得其他模型能够有思考能力
解决方案:
- 通过将批量带有<think>标签的answer作为数据集,对模型进行微调
- 将<think>作为一个特殊的token输入模型中(此方案目前还未进行尝试,之后补充)
下面文章将阐述第一种解决方案,第二种由于时间原因待定。
1. 处理数据集
将R1数据集处理为如下格式,使得LLmfactory微调时可以识别
其中LLamaFactory可以识别两种风格的数据集:
alpaca风格
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
sharegpt风格
[
{
"conversations": [
{
"from": "human",
"value": "用户指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
按照指定的内容准备好数据集,之后需要将数据集插入/data/dataset_info.json文件中
Dataset_info定义
alpaca风格的数据参考一下写法:
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的 SHA-1 哈希值(可选,留空不影响训练)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system 列)"
}
}
常用的方法为简便写法:
"bbbb": {
"file_name": "aaaa.json"
}file_name为数据集的文件名,其中数据集要放在data目录下
bbbb为数据集联络名,在微调的配置文件中将dataset的名字修改为bbbb
2. 修改微调文件
参考/examples/train_lora/llama3_lora_sft.yaml文件,将其修改为你自己需要的内容
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
其中主要修改的部分为:
-
model_name_or_path:模型路径
-
dataset:数据集链路名,即上文中的bbbb
-
output_dir:保存的路径
之后就是针对于进行调参,大部分为学习率和epoch,也可以将eval打开,在训练之后也进行评估,方便进一步证明微调的可靠性
注:save_steps和eval_steps需保持一致,否则会报错找不到已保存的模型路径
3. 查看评估结果
在对应的保存文件中,查看training_loss和eval_loss查看曲线并进行评估,如果曲线相对平稳则可以进行下一步调用,如果曲线波动较为明显,则针对性调参
4. 推理
1. 使用webui格式推理
GRADIO_SERVER_PORT=xxxx CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 GRADIO_SHARE=1 llamafactory-cli webui该命令含义为,使用8张卡,通过webui的方式在xxxx端口中进行访问,具体配置在具体场景中修改,打开的页面如下
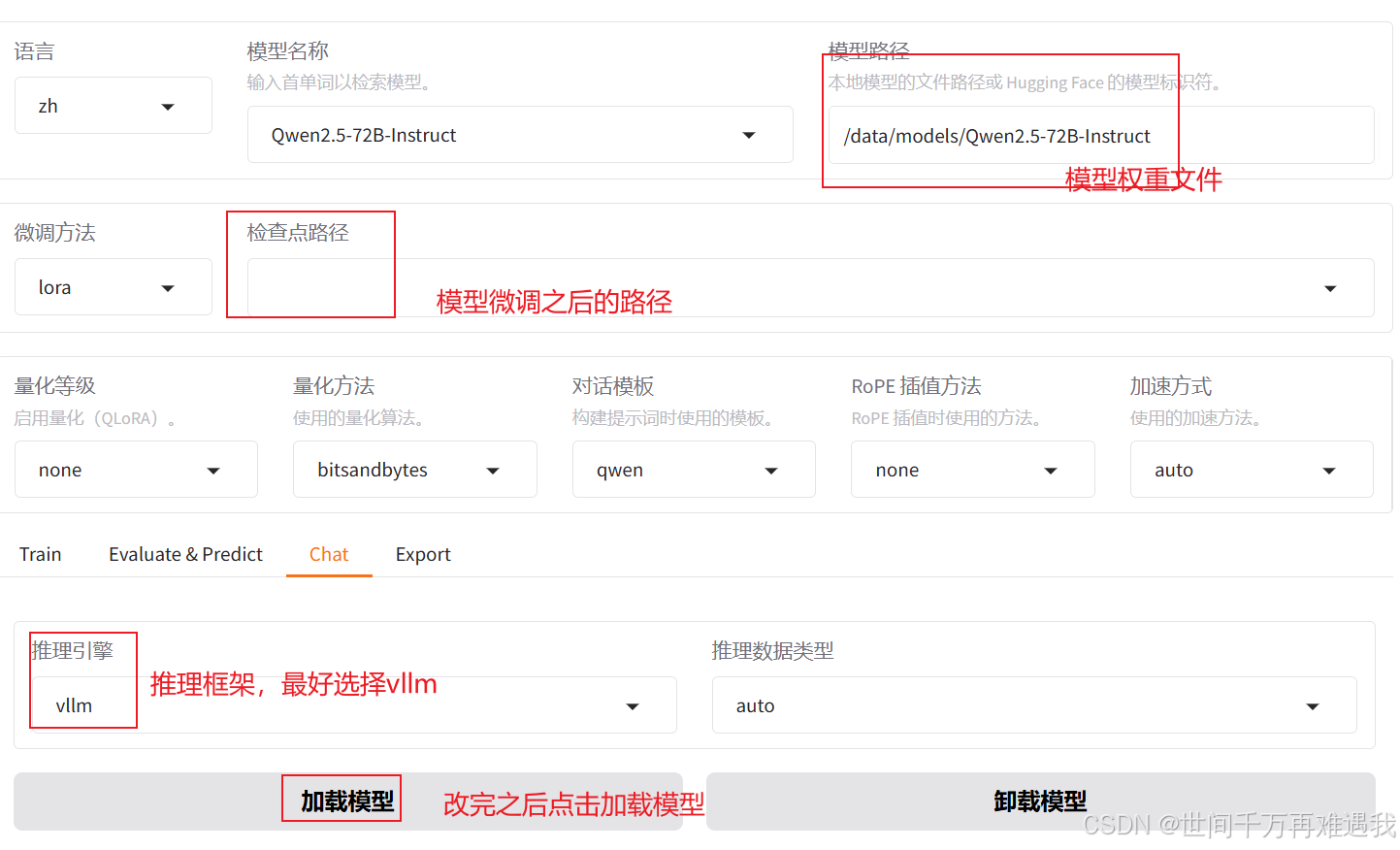
之后正常提问即可
2. 使用chat进行推理
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml使用该命令进行推理,修改相应的配置文件能够不需要合并模型就可以直接使用
参考配置文件如下:
model_name_or_path: /data/models/Qwen2.5-72B-Instruct
adapter_name_or_path: /data/project/LLaMA-Factory/saves/qwen2.5-72b_deepv2/checkpoint-200
template: qwen
infer_backend: vllm # choices: [huggingface, vllm]
trust_remote_code: true
temperature: 0.95需要修改的地方为:
- model_name_or_path:此处为模型权重路径
- adapter_name_or_path:此处为模型微调之后生成的路径
- teplate:此处为模型权重对应的模板,如Qwen2.5的template是qwen
之后等待结果
3. 使用模型合并
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml目的是将微调之后的和原本的模型权重进行合并,然后生成一个新的模型权重文件
参考配置如下:
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: /data/models/Qwen2.5-72B-Instruct
adapter_name_or_path: /data/project/LLaMA-Factory/saves/qwen2.5-72b_deepv4
template: qwen
trust_remote_code: true
### export
export_dir: output/qwen2.5_deepv4_merge
export_size: 5
export_device: auto
export_legacy_format: false
需要修改的地方为:
- model_name_or_path:此处为原本的模型权重路径
- adapter_name_or_path:此处为模型微调之后生成的路径
- teplate:此处为模型权重对应的模板,如Qwen2.5的template是qwen
- export_dir:此处为合并之后的模型权重存放路径
- export_size:此处为模型权重文件分为几个
合并完成之后可以按照上述第一步的方式进行推理,也可以使用其他方法如vllm启动OpenAI服务,见下文:
4. vllm推理
在上述模型合并之后可以直接使用vllm进行推理
API_PORT=8000 llamafactory-cli api examples/inference/llama3_vllm.yaml通过8000端口进行API访问
参考配置如下:
model_name_or_path: /data/project/LLaMA-Factory/saves/qwen2.5
template: qwen
infer_backend: vllm
vllm_enforce_eager: true
trust_remote_code: true
将model_name_or_path修改为合并之后的权重文件路径即可
在运行时还有一些其他的参数需要配置见下方链接:
如可以通过vllm_maxlen可以设置最大序列长度(包括输入文本和生成文本)。
之后可以使用openai进行调用:
from openai import OpenAI
api_base = "http://localhost:xxxx/v1"
model_name = "aaa"
api_key = "xxxxxxxxxx"
client = OpenAI(base_url=api_base, api_key=api_key)
def chat_with_gpt_internal(item):
global cur_capter_num
system_content= '''xxxxx'''
content = item
completion = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": system_content},
{"role": "user", "content": content}
],
stream=False
)
result = completion.choices[0].message.content
return result
if __name__ == "__main__":
text = "你是谁"
out = chat_with_gpt_internal(text)
print(out)此处的api_key可以随便填写,之后便可以通过API访问
5. 遇到的问题
在安装vllm的时候发生报错解决办法:
export LD_LIBRARY_PATH=/data/home/user/anaconda3/envs/vllm/lib/python3.10/site-packages/nvidia/nvjitlink/lib:$LD_LIBRARY_PATH具体原因为当安装vllm以后会有多个cuda版本进行冲突,conda环境中并没有办法去主动找到对应的cuda因此需要设置一下,具体的报错信息目前没办法重现,之后补充

















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









