







1、项目简介
这个代码实现了一个基于深度确定性策略梯度(DDPG)算法的强化学习智能体,并应用于一个名为 Pendulum-v1 的控制任务中。DDPG 是一种适用于连续动作空间的强化学习算法,结合了深度 Q 网络(DQN)和策略梯度方法的优点,通过两个神经网络(Actor 和 Critic)分别生成动作和评估动作的价值。
1.1 功能和作用
-
智能体类(RLAgent):
-
功能:负责选择动作、存储经验、更新 Actor 和 Critic 网络。
-
作用:通过与环境交互学习最优策略,改善智能体在给定任务中的表现。
-
-
Actor 和 Critic 网络(ActorNetwork 和 CriticNetwork):
-
功能:Actor 网络根据当前状态生成动作,Critic 网络评估给定状态-动作对的价值。
-
作用:Actor 网络引导智能体选择动作,Critic 网络提供反馈以指导 Actor 网络的改进。
-
-
经验回放缓冲区(ExperienceBuffer):
-
功能:存储智能体与环境交互的经验,并在训练时从中随机抽样。
-
作用:通过打破数据相关性,提高训练效率和稳定性。
-
-
训练管理器(TrainingManager):
-
功能:管理训练过程,包括环境交互、经验存储、网络更新和结果可视化。
-
作用:协调各部分工作,确保训练顺利进行并记录训练结果。
-
1.2 应用场景
-
自动驾驶:训练智能体在模拟环境中学会驾驶策略,以实现无人驾驶汽车的自主决策。
-
机器人控制:通过训练智能体学会控制机器人关节的动作,实现机器人的自主运动和任务执行。
-
游戏 AI:在复杂的游戏环境中,训练智能体学会最佳策略,提高游戏 AI 的智能水平。
-
金融交易:在模拟市场环境中,训练智能体学会买卖策略,优化投资组合收益。
1.3 环境依赖
conda create -n qlearning01 python=3.11
conda activate qlearning01
pip install gymnasium==0.28.1
pip install torch==2.1.1
pip install numpy==1.26.3
pip install matplotlib==3.7.1
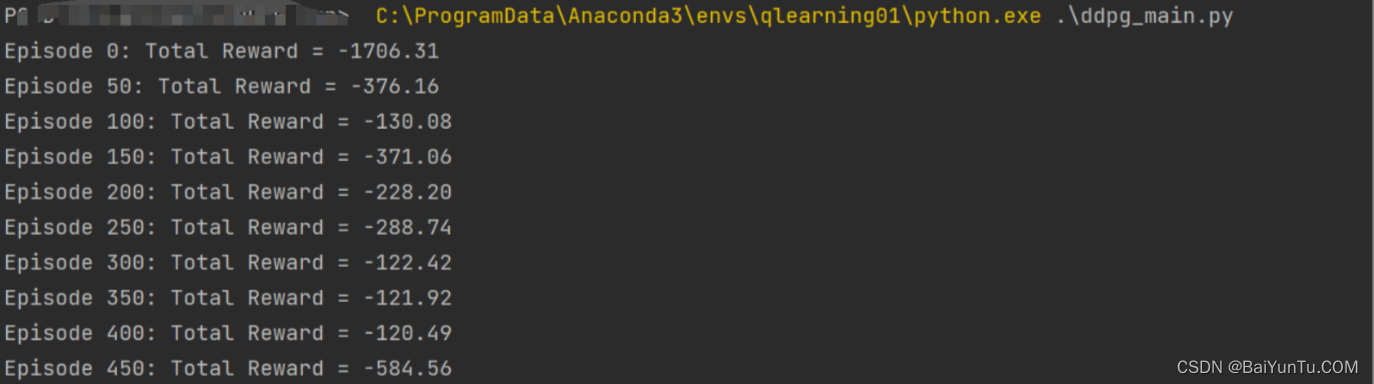
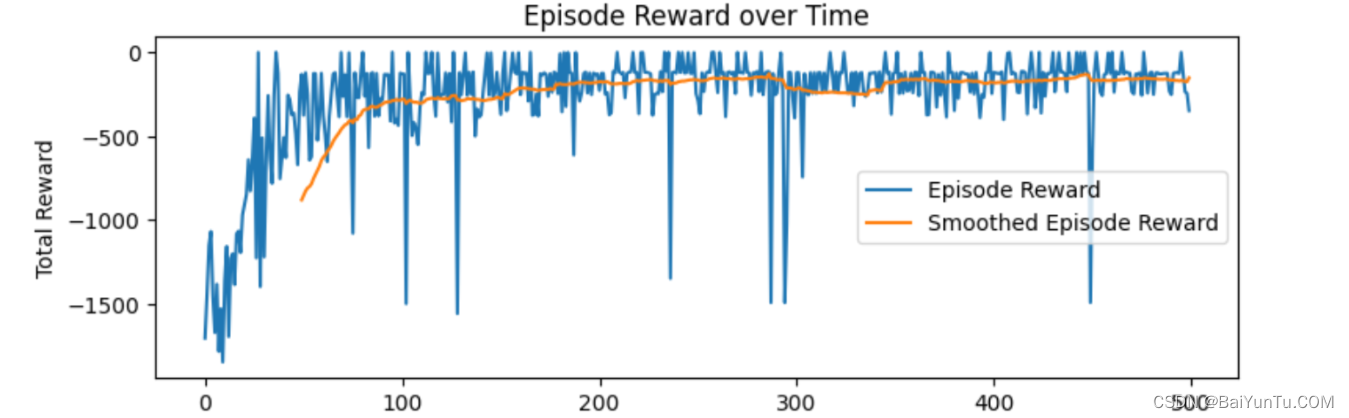
pip install pandas==1.5.32、效果截图
3、代码实现
3.1 初始化环境和训练管理器
import gymnasium as gym
# 创建环境
env = gym.make('Pendulum-v1')
# 初始化训练管理器
manager = TrainingManager(env=env,
episodes=500,
actor_lr=1e-3,
critic_lr=1e-2,
discount_factor=0.95,
noise_std_dev=0.01,
buffer_size=10000,
initial_memory_size=1000,
actor_update_frequency=1,
tau=5e-3,
batch_size=64,
seed=0,
device_type="cpu"
)3.2 训练智能体
# 开始训练
manager.train()3.3 可视化训练结果
# 绘制奖励随时间变化的曲线
manager.plot_rewards()3.4 智能体类
#智能体类(RLAgent)
#负责智能体的主要功能,包括选择动作、存储经验和更新网络。
class RLAgent():
def __init__(self, action_scale_factor, action_upper_limit, action_lower_limit, memory_buffer, initial_memory_size, batch_sample_size, actor_update_frequency, tau, actor_net, critic_net, actor_opt, critic_opt, discount_factor=0.9, noise_std_dev=0.2, device=torch.device("cpu")):
self.device = device
self.experience_counter = 0
self.memory_buffer = memory_buffer
self.initial_memory_size = initial_memory_size
self.batch_sample_size = batch_sample_size
self.actor_update_frequency = actor_update_frequency
self.tau = tau
self.primary_critic_net = critic_net.to(self.device)
self.target_critic_net = copy.deepcopy(critic_net).to(self.device)
self.primary_actor_net = actor_net.to(self.device)
self.target_actor_net = copy.deepcopy(actor_net).to(self.device)
self.critic_opt = critic_opt
self.actor_opt = actor_opt
self.discount_factor = discount_factor
self.noise_std_dev = noise_std_dev
self.action_scale_factor = action_scale_factor
self.action_upper_limit = action_upper_limit
self.action_lower_limit = action_lower_limit
def select_action(self, observation):
observation = torch.tensor(observation, dtype=torch.float32).to(self.device)
action = self.primary_actor_net(observation)
action += torch.normal(0, self.action_scale_factor * self.noise_std_dev)
action = action.cpu().detach().numpy().clip(self.action_lower_limit, self.action_upper_limit)
return action
def soft_update(self, primary_net, target_net):
for target_param, primary_param in zip(target_net.parameters(), primary_net.parameters()):
target_param.data.copy_(self.tau * primary_param.data + (1.0 - self.tau) * target_param.data)
def update_critic(self, observation_batch, action_batch, reward_batch, next_observation_batch, done_batch):
current_Q = self.primary_critic_net(observation_batch, action_batch).squeeze(1)
TD_target = reward_batch + (1 - done_batch) * self.discount_factor * self.target_critic_net(next_observation_batch, self.target_actor_net(next_observation_batch)).squeeze(1)
critic_loss = torch.mean(F.mse_loss(current_Q, TD_target.detach()))
self.critic_opt.zero_grad()
critic_loss.backward()
self.critic_opt.step()
def update_actor(self, observation_batch):
for param in self.primary_critic_net.parameters():
param.requires_grad = False
actor_loss = torch.mean(-self.primary_critic_net(observation_batch, self.primary_actor_net(observation_batch)))
self.actor_opt.zero_grad()
actor_loss.backward()
self.actor_opt.step()
for param in self.primary_critic_net.parameters():
param.requires_grad = True
def store_experience(self, observation, action, reward, next_observation, done):
self.experience_counter += 1
self.memory_buffer.append((observation, action, reward, next_observation, done))
if len(self.memory_buffer) > self.initial_memory_size:
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = self.memory_buffer.sample(self.batch_sample_size)
self.update_critic(obs_batch, action_batch, reward_batch, next_obs_batch, done_batch)
if self.experience_counter % self.actor_update_frequency == 0:
self.update_actor(obs_batch)
self.soft_update(self.primary_critic_net, self.target_critic_net)
self.soft_update(self.primary_actor_net, self.target_actor_net)
3.5 Actor 和 Critic 网络
定义了两个神经网络,用于生成动作和评估动作价值。
class ActorNetwork(torch.nn.Module):
def __init__(self, obs_dim, action_dim, action_scale_factor, action_bias):
super(ActorNetwork, self).__init__()
self.fc1 = torch.nn.Linear(obs_dim, 64)
self.fc2 = torch.nn.Linear(64, action_dim)
self.action_scale_factor = action_scale_factor
self.action_bias = action_bias
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.tanh(x)
return x * self.action_scale_factor + self.action_bias
class CriticNetwork(torch.nn.Module):
def __init__(self, obs_dim, action_dim):
super(CriticNetwork, self).__init__()
self.fc1 = torch.nn.Linear(obs_dim + action_dim, 64)
self.fc2 = torch.nn.Linear(64, 1)
def forward(self, obs, action):
x = torch.cat([obs, action], dim=1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x3.6 经验回放缓冲区
用于存储和随机抽取经验数据,提高训练效率和稳定性。
class ExperienceBuffer():
def __init__(self, capacity, device=torch.device("cpu")):
self.device = device
self.buffer = collections.deque(maxlen=capacity)
def append(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = zip(*mini_batch)
obs_batch = torch.tensor(np.array(obs_batch), dtype=torch.float32, device=self.device)
action_batch = torch.tensor(np.array(action_batch), dtype=torch.float32, device=self.device)
reward_batch = torch.tensor(reward_batch, dtype=torch.float32, device=self.device)
next_obs_batch = torch.tensor(np.array(next_obs_batch), dtype=torch.float32, device=self.device)
done_batch = torch.tensor(done_batch, dtype=torch.float32, device=self.device)
return obs_batch, action_batch, reward_batch, next_obs_batch, done_batch
def __len__(self):
return len(self.buffer)
3.7 训练管理器
管理整个训练过程,包括与环境的交互和网络的更新。
class TrainingManager():
def __init__(self, env, episodes=1000, actor_lr=1e-3, critic_lr=1e-3, discount_factor=0.95, noise_std_dev=0.2, buffer_size=2000, initial_memory_size=200, actor_update_frequency=2, tau=1e-3, batch_size=32, seed=0, device_type="cpu"):
self.seed = seed
random.seed(self.seed)
torch.manual_seed(self.seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(self.seed)
torch.backends.cudnn.deterministic = True
self.device = torch.device(device_type)
self.env = env
_, _ = self.env.reset(seed=self.seed)
self.episodes = episodes
obs_dim = gym.spaces.utils.flatdim(env.observation_space)
action_dim = gym.spaces.utils.flatdim(env.action_space)
action_upper_limit = env.action_space.high
action_lower_limit = env.action_space.low
action_bias = (action_upper_limit + action_lower_limit) / 2.0
action_bias = torch.tensor(action_bias, dtype=torch.float32).to(self.device)
action_scale_factor = (action_upper_limit - action_lower_limit) / 2.0
action_scale_factor = torch.tensor(action_scale_factor, dtype=torch.float32).to(self.device)
self.buffer = ExperienceBuffer(capacity=buffer_size, device=self.device)
actor_net = ActorNetwork(obs_dim, action_dim, action_scale_factor, action_bias).to(self.device)
actor_opt = torch.optim.Adam(actor_net.parameters(), lr=actor_lr)
critic_net = CriticNetwork(obs_dim, action_dim).to(self.device)
critic_opt = torch.optim.Adam(critic_net.parameters(), lr=critic_lr)
self.agent = RLAgent(action_scale_factor=action_scale_factor, action_upper_limit=action_upper_limit, action_lower_limit=action_lower_limit, memory_buffer=self.buffer, initial_memory_size=initial_memory_size, batch_sample_size=batch_size, actor_update_frequency=actor_update_frequency, tau=tau, actor_net=actor_net, critic_net=critic_net, actor_opt=actor_opt, critic_opt=critic_opt, discount_factor=discount_factor, noise_std_dev=noise_std_dev, device=self.device)
self.episode_rewards = np.zeros(episodes)
self.current_episode = 0
def run_episode(self):
total_reward = 0
observation, _ = self.env.reset()
while True:
action = self.agent.select_action(observation)
next_observation, reward, terminated, truncated, _ = self.env.step(action)
done = terminated or truncated
total_reward += reward
self.agent.store_experience(observation, action, reward, next_observation, done)
observation = next_observation
if done:
self.episode_rewards[self.current_episode] = total_reward
self.current_episode += 1
break
return total_reward
def train(self):
for episode in range(self.episodes):
episode_reward = self.run_episode()
if episode % 50 == 0:
print('Episode %d: Total Reward = %.2f' % (episode, episode_reward))
def plot_rewards(self, smoothing_window=50):
plt.figure(figsize=(10, 5))
plt.plot(self.episode_rewards, label="Episode Reward")
rewards_smoothed = pd.Series(self.episode_rewards).rolling(smoothing_window, min_periods=smoothing_window).mean()
plt.plot(rewards_smoothed, label="Smoothed Episode Reward")
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title("Episode Reward over Time")
plt.legend()
plt.show()














 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









