






1. 什么是网络爬虫?
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。
网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
2.大数据时代,可以让我们获取更多的数据源
在进行大数据分析或者进行数据挖掘的时候,需要有数据源进行分析。我们可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,再进行更深层次的数据分析,并获得更多有价值的信息。
3. 可以更好地进行搜索引擎优化(SEO)
对于很多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理非常清楚,同时也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
3.网络爬虫如何使用?
爬虫底层两大核心:
(1).HttpClient:网络爬虫就是用程序帮助我们访问网络上的资源,我们一直以来都是使用HTTP协议访问互联网的网页,网络爬虫需要编写程序,在这里使用同样的HTTP协议访问网页,这里我们使用Java的HTTP协议客户端 HttpClient这个技术,来实现抓取网页数据。(在Java程序中通过HttpClient技术进行远程访问,抓取网页数据.)
注:如果每次请求都要创建HttpClient, 会有频繁创建和销毁的问题, 可以使用HttpClient连接池来解决这个问题。
(2). Jsoup:我们抓取到页面之后,还需要对页面进行解析。可以使用字符串处理工具解析页面,也可以使用正则表达式,但是这些方法都会带来很大的开发成本,所以我们需要使用一款专门解析html页面的技术。(将获取到的页面数据转化为Dom对象进行解析)
Jsoup介绍:Jsoup 是一款Java 的HTML、XML解析器,可直接解析某个URL地址、HTML文本、文件解析为DOM对象, 同时它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数
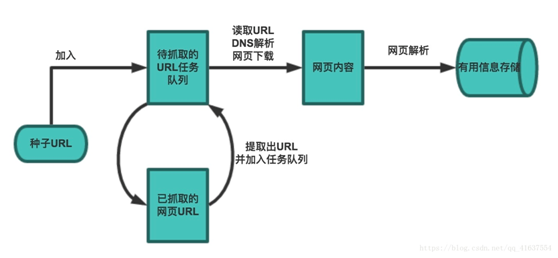
- 设定抓取目标(种子页面)并获取网页.
- 当服务器无法访问时, 设置重试次数.
- 在需要的时候设置用户代理(否则无法访问页面)
- 对获取的页面进行必要的解码操作
- 通过正则表达式获取页面中的链接
- 对链接进行进一步的处理(获取页面并重复上面的操作)
- 将有用的信息进行持久化(以备后续的处理)
5. WebMagic介绍
WebMagic是一款爬虫框架,其底层用到了上文所介绍使用的HttpClient和Jsoup,让我们能够更方便的开发爬虫。WebMagic的设计目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫。
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分(webmagic-extension)则包括一些便利的、实用性的功能, 例如注解模式编写爬虫等,同时内置了一些常用的组件,便于爬虫开发。
1).架构介绍
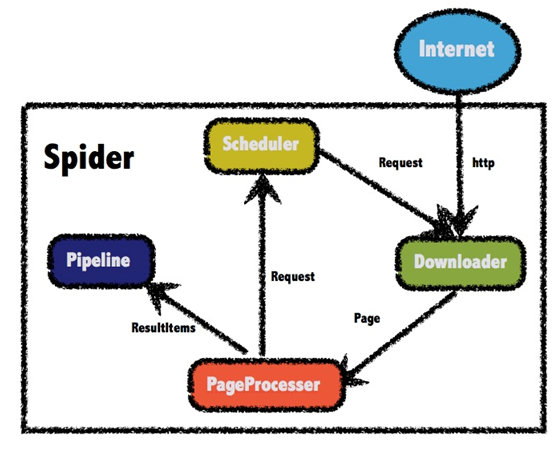
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能.
Spider将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
WebMagic总体架构图如下:
2).WebMagic的四个组件
①.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
②.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
③.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
④.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
3).用于数据流转的对象
①. Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
②. Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
③. ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
6.WebMagic如何使用
1). PageProcessor组件的功能
①.抽取元素Selectable
Selectable相关的抽取元素链式API是WebMagic的一个核心功能。使用Selectable接口,可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。page.getHtml()返回的是一个Html对象,它实现了Selectable接口。这部分抽取API返回的都是一个Selectable接口,意思是说,是支持链式调用的。这个接口包含的方法分为两类:抽取部分和获取结果部分。
| 方法 | 说明 | 示例 |
| xpath(String xpath) | 使用XPath选择 | html.xpath("//div[@class='title']") |
| $(String selector) | 使用Css选择器选择 | html.$("div.title") |
| $(String selector,String attr) | 使用Css选择器选择 | html.$("div.title","text") |
| css(String selector) | 功能同$(),使用Css选择器选择 | html.css("div.title") |
| links() | 选择所有链接 | html.links() |
| regex(String regex) | 使用正则表达式抽取 | html.regex("\(.\*?)\") |
PageProcessor里主要使用了三种抽取技术:XPath、CSS选择器和正则表达式。对于JSON格式的内容,可使用JsonPath进行解析.
1. XPath
以上是获取属性class=mt的div标签,里面的h1标签的内容

2.CSS选择器
CSS选择器是与XPath类似的语言。
div.mt>h1表示class为mt的div标签下的直接子元素h1标签

可是使用:nth-child(n)选择第几个元素,如下选择第一个元素

注意:需要使用 > 就是直接子元素才可以选择第几个元素
3.正则表达式
正则表达式则是一种通用的文本抽取语言。在这里一般用于获取url地址。
②.获取结果
当链式调用结束时,我们一般都想要拿到一个字符串类型的结果。这时候就需要用到获取结果的API了。
我们知道,一条抽取规则,无论是XPath、CSS选择器或者正则表达式,总有可能抽取到多条元素。WebMagic对这些进行了统一,可以通过不同的API获取到一个或者多个元素。
| 方法 | 说明 | 示例 |
| get() | 返回一条String类型的结果 | String link= html.links().get() |
| toString() | 同get(),返回一条String类型的结果 | String link= html.links().toString() |
| all() | 返回所有抽取结果 | List links= html.links().all() |
当有多条数据的时候,使用get()和toString()都是获取第一个url地址。
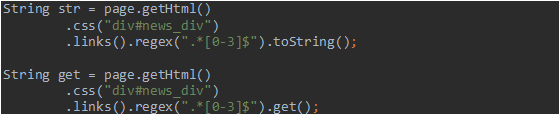
测试结果:
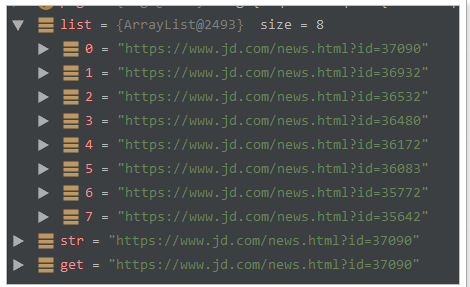
selectable.toString()在输出以及和一些框架结合的时候,更加方便。因为一般情况下,我们都只采用此方法获取一个元素!
③. 获取链接
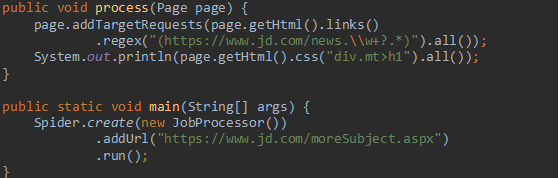
一个站点的页面是很多的,一开始我们不可能全部列举出来,于是如何发现后续的链接,是一个爬虫不可缺少的一部分。
下面的例子就是获取https://www.jd.com/moreSubject.aspx这个页面中
所有符合https://www.jd.com/news.\\w+?.*正则表达式的url地址
并将这些链接加入到待抓取的队列中去。
2). Scheduler组件的使用
在解析页面的时候,很可能会解析出相同的url地址(例如商品标题和商品图片超链接,而且url一样),如果不进行处理,同样的url会解析处理多次,浪费资源。所以我们需要有一个url去重的功能。
Scheduler可以帮助我们解决以上问题。Scheduler是WebMagic中进行URL管理的组件。一般来说,Scheduler包括两个作用:
❶对待抓取的URL队列进行管理。
❷对已抓取的URL进行去重。
WebMagic内置了几个常用的Scheduler。如果只是在本地执行规模比较小的爬虫,那么基本无需定制Scheduler,但是了解一下已经提供的几个Scheduler还是有意义的。
| 类 | 说明 | 备注 |
| DuplicateRemovedScheduler | 抽象基类,提供一些模板方法 | 继承它可以实现自己的功能 |
| QueueScheduler | 使用内存队列保存待抓取URL | |
| PriorityScheduler | 使用带有优先级的内存队列保存待抓取URL | 耗费内存较QueueScheduler更大,但是当设置了request.priority之后,只能使用PriorityScheduler才可使优先级生效 |
| FileCacheQueueScheduler | 使用文件保存抓取URL,可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取 | 需指定路径,会建立.urls.txt和.cursor.txt两个文件 |
| RedisScheduler | 使用Redis保存抓取队列,可进行多台机器同时合作抓取 | 需要安装并启动redis |
去除重复链接部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。
| 类 | 说明 |
| HashSetDuplicateRemover | 使用HashSet来进行去重,占用内存较大 |
| BloomFilterDuplicateRemover | 使用BloomFilter来进行去重,占用内存较小,但是可能漏抓页面 |
RedisScheduler是使用Redis的set进行去重,其他的Scheduler默认都使用HashSetDuplicateRemover来进行去重。
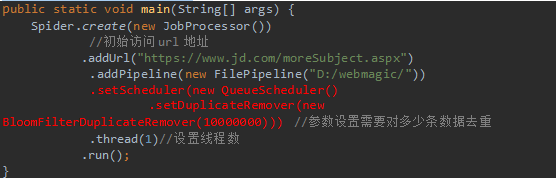
如果要使用BloomFilter,必须要加入以下依赖:

修改代码,添加布隆过滤器
三种去重方式的对比
❶ HashSetDuplicateRemover
使用java中的HashSet不能重复的特点去重。优点是容易理解。使用方便。
缺点:占用内存大,性能较低。
❷.RedisScheduler的set进行去重。
优点是速度快(Redis本身速度就很快),而且去重不会占用爬虫服务器的资源,可以处理更大数据量的数据爬取。
缺点:需要准备Redis服务器,增加开发和使用成本。
❸.BloomFilterDuplicateRemover
使用布隆过滤器也可以实现去重。优点是占用的内存要比使用HashSet要小的多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会判定重复,但是重复数据一定会判定重复。
*网页内容去重
上文我们研究了对下载的url地址进行了去重的解决方案,避免同样的url下载多次。其实不只是url需要去重,我们对下载的网页内容也需要去重。在网上我们可以找到许多内容相似的文章。但是实际我们只需要其中一个即可,同样的内容没有必要下载多次,那么如何进行去重就需要进行处理了
去重方案介绍
❶.指纹码对比
最常见的去重方案是生成文档的指纹门。例如对一篇文章进行MD5加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是重复的,这种方式并不合理。
❷.BloomFilter
这种方式就是我们之前对url进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法1是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
❸.KMP算法
KMP算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一样的,哪些不一样。这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的时空复杂度太高了,不适合大数据量的重复比对。
❹. Simhash签名
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前Google搜索引擎所目前所使用的网页去重算法。
(1).SimHash流程介绍
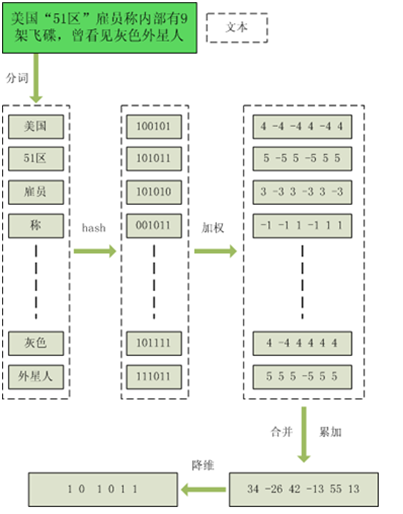
simhash是由 Charikar 在2002年提出来的,为了便于理解尽量不使用数学公式,分为这几步:
1、分词,把需要判断文本分词形成这个文章的特征单词。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”
“51区”计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。
“美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”
把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,把算出来的 “9 -9 1 -1 1 9”变成 0 1 串,形成最终的simhash签名。
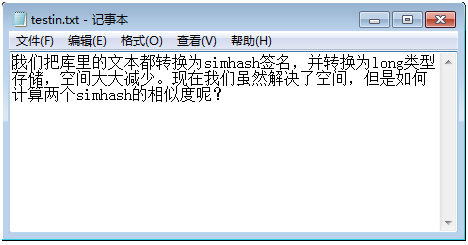
(2).签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?
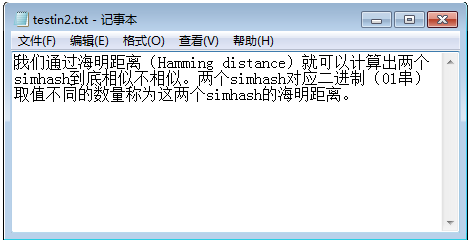
我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。
(3).测试simhash
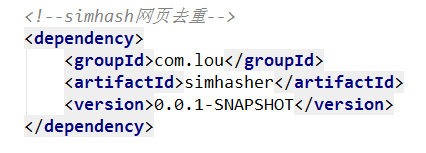
这个项目不能直接使用,因为jar包的问题,需要导入工程simhash,并进行install。
导入对应的依赖:
测试用例:
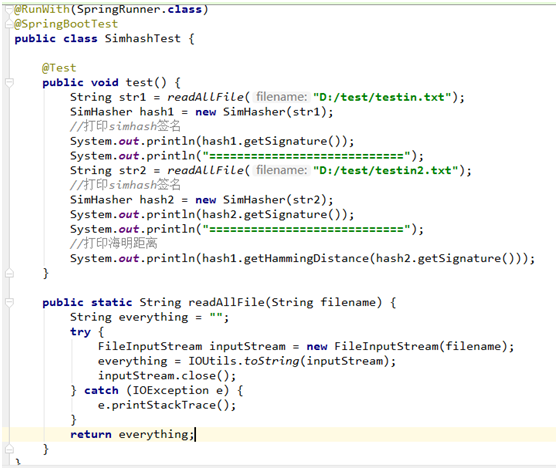
测试结果:

3). Pipeline组件的使用
Pipeline组件的作用用于保存结果。我们现在通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。
那么,我现在想要把结果用保存到文件中,怎么做呢?只将Pipeline的实现换成"FilePipeline"就可以了。
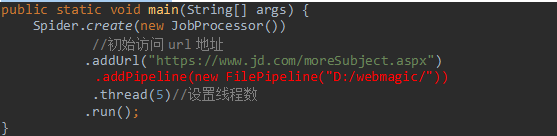
7.网络爬虫的配置、启动和终止
1).Spider
Spider是网络爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。
Spider的其他组件(Downloader、Scheduler)可以通过set方法来进行设置,
Pipeline组件通过add方法进行设置。
| 方法 | 说明 | 示例 |
| create(PageProcessor) | 创建Spider | Spider.create(new GithubRepoProcessor()) |
| addUrl(String…) | 添加初始的URL | spider .addUrl("http://webmagic.io/docs/") |
| thread(n) | 开启n个线程 | spider.thread(5) |
| run() | 启动,会阻塞当前线程执行 | spider.run() |
| start()/runAsync() | 异步启动,当前线程继续执行 | spider.start() |
| stop() | 停止爬虫 | spider.stop() |
| addPipeline(Pipeline) | 添加一个Pipeline,一个Spider可以有多个Pipeline | spider .addPipeline(new ConsolePipeline()) |
| setScheduler(Scheduler) | 设置Scheduler,一个Spider只能有个一个Scheduler | spider.setScheduler(new RedisScheduler()) |
| setDownloader(Downloader) | 设置Downloader,一个Spider只能有个一个Downloader | spider .setDownloader( new SeleniumDownloader()) |
| get(String) | 同步调用,并直接取得结果 | ResultItems result = spider .get("http://webmagic.io/docs/") |
| getAll(String…) | 同步调用,并直接取得一堆结果 | List<ResultItems> results = spider .getAll("http://webmagic.io/docs/", "http://webmagic.io/xxx") |
2). 爬虫配置Site
Site.me()可以对爬虫进行一些配置配置,包括编码、抓取间隔、超时时间、重试次数等。在这里我们先简单设置一下:重试次数为3次,抓取间隔为一秒。

站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置。
| 方法 | 说明 | 示例 |
| setCharset(String) | 设置编码 | site.setCharset("utf-8") |
| setUserAgent(String) | 设置UserAgent | site.setUserAgent("Spider") |
| setTimeOut(int) | 设置超时时间, 单位是毫秒 | site.setTimeOut(3000) |
| setRetryTimes(int) | 设置重试次数 | site.setRetryTimes(3) |
| setCycleRetryTimes(int) | 设置循环重试次数 | site.setCycleRetryTimes(3) |
| addCookie(String,String) | 添加一条cookie | site.addCookie("dotcomt_user","code4craft") |
| setDomain(String) | 设置域名,需设置域名后,addCookie才可生效 | site.setDomain("github.com") |
| addHeader(String,String) | 添加一条addHeader | site.addHeader("Referer","https://github.com") |
| setHttpProxy(HttpHost) | 设置Http代理 | site.setHttpProxy(new HttpHost("127.0.0.1",8080)) |
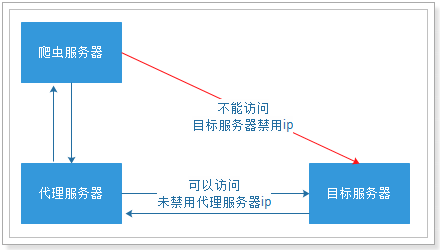
8.代理服务器
有些网站不允许网络爬虫进行数据爬取,因为会加大服务器的压力。解决此障碍其中一种最有效的方式是通过ip+访问时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的WebMagic可以很方便的设置爬取数据的时间,但是这样会大大降低我们爬取数据的效率,如果不小心ip被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
1).代理服务器介绍
网络代理(internet Proxy)是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
注: 网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的效果还不错。
2).代理服务器的使用
WebMagic使用的代理APIProxyProvider。因为相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
| API | 说明 |
| HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider) | 设置代理 |
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
如果需要根据实际使用情况对代理服务器进行管理(例如校验是否可用,定期清理、添加代理服务器等),只需要自己实现APIProxyProvider即可。
使用代理服务器之前,通过查询可以获取ip信息的网站得到如下结果:
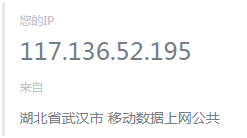
未使用代理服务器之前,利用爬虫程序抓取此页面获得的结果为本地ip地址:
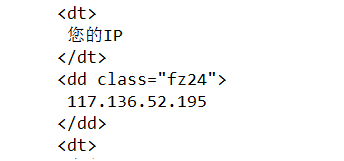
使用代理服务器:

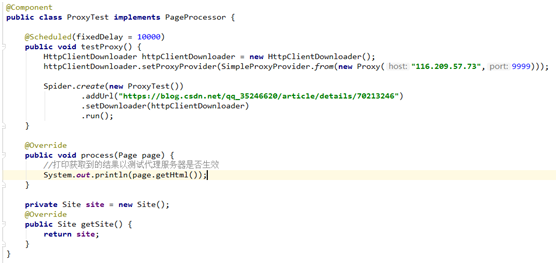
使用代理服务器之后,用爬虫程序获取的结果为代理服务器ip地址:
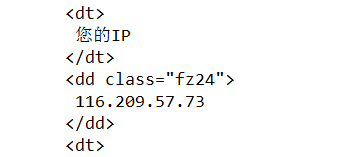
由此看出使用代理服务成功,并且访问的ip改为代理服务器的ip.















 1580
1580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









