






https://github.com/datawhalechina/team-learning/blob/master/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E5%9F%BA%E7%A1%80/Task3%20EM.ipynb
看这里!!!! 代码是没有的!!! 需要代码的请看上方!!
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础。
https://mp.weixin.qq.com/s?src=11×tamp=1587628798&ver=2295&signature=Aoo6OBNW86BTmEof3PaUjncRz6O7-oWXgfAJPMPt-70O5OzHJiddRXh0s8YyxGzp5Wa2CUPSQeaGDcYM2pgAZnTXjN8ZmWM1GKuW-BqvlC0cLOEYkGqNRtDuuoqoH3KW&new=1
以下内容,参考的是上方链接。
一、初步了解
首先用通俗化语言形容下EM算法,分水果。你有一堆水果,种类、大小都不同。需要你分成两堆,两堆的大小和种类尽量相同。这个时候一般人会先从这对水果中分出一部分,然后与后一部分进行比较慢慢调整使两者满足要求。
上面的例子三个主要的步骤:初始化参数,观察预期和重新估计。实际上就是期望步骤(Expectation)简称E步。如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)简称M步。这两个步骤加起来也就是 EM 算法的过程。
二、详细了解
想清晰的了解EM算法推导过程和其原理,我们需要知道两个基础知识:“极大似然估计”和“Jensen不等式”。
1.极大似然估计
什么是最大似然呢?
假如我们需要调查学校的男生和女生的身高分布 ,我们抽取100个男生和100个女生,将他们按照性别划分为两组。然后,统计抽样得到100个男生的身高数据和100个女生的身高数据。如果我们知道他们的身高服从正态分布,但是这个分布的均值和方差是不知道,这两个参数就是我们需要估计的。
指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的。
最大似然估计是一种通过已知结果,估计参数的方法。
EM 算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。
https://mp.weixin.qq.com/s?src=11×tamp=1587628798&ver=2295&signature=gW3wyHdAHpXuJsV7WT5RVLITEL30pvAMQAOLz9QNe372mY3wUWDDwBJY8Lo6TIUMzlYZGVqGSQvpSiENWL4ritiOG7a-a-OE6sigIAdTOsPpFQ9RD03O*72AQMZRb8&new=1
下方内容来自上方链接。
1)创建模型
我们已知的条件有两个:
样本服从的分布模型、随机抽取的样本。我们需要求解模型的参数。根据已知条件,通过极大似然估计,求出未知参数。总的来说:极大似然估计就是用来估计模型参数的统计学方法。

2)用数学知识解决现实问题
问题数学化:样本集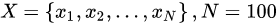 概率密度是:抽到第i个男生身高的概率。由于100个样本之间独立同分布,所以同时抽到这100个男生的概率是它们各自概率的乘积,就是从分布是p(X|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
概率密度是:抽到第i个男生身高的概率。由于100个样本之间独立同分布,所以同时抽到这100个男生的概率是它们各自概率的乘积,就是从分布是p(X|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
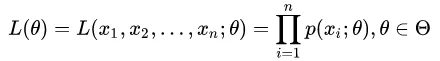
这个概率反映了在概率密度函数的参数是θ时,得到X这组样本的概率。 我们需要找到一个参数θ,使得抽到X这组样本的概率最大,也就是说需要其对应的似然函数L(θ)最大。满足条件的θ叫做θ的最大似然估计值,记为:
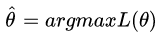
3)最大似然函数估计值的求解步骤
首先,写出似然函数:
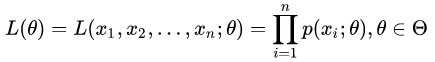 其次,对似然函数取对数:
其次,对似然函数取对数:
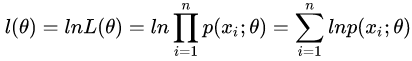
然后,对上式求导,另导数为0,得到似然方程。
最后,解似然方程,得到的参数值即为所求。
多数情况下,我们是根据已知条件来推算结果,而极大似然估计是已知结果,寻求使该结果出现的可能性最大的条件,以此作为估计值。
2.Jensen不等式
设f是定义域为实数的函数,如果对所有的实数x,f(x)的二阶导数都大于0,那么f是凸函数。
Jensen不等式定义如下:
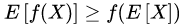
如果f是凸函数,X是随机变量,那么: 。当且仅当X是常量时,该式取等号。其中,E(X)表示X的数学期望。
注:Jensen不等式应用于凹函数时,不等号方向反向。当且仅当x是常量时,该不等式取等号。
三、EM算法详解
我们目前有100个男生和100个女生的身高,但是我们不知道这200个数据中哪个是男生的身高,哪个是女生的身高,即抽取得到的每个样本都不知道是从哪个分布中抽取的。这个时候,对于每个样本,就有两个未知量需要估计:
(1)这个身高数据是来自于男生数据集合还是来自于女生?
(2)男生、女生身高数据集的正态分布的参数分别是多少?

那么,对于具体的身高问题使用EM算法求解步骤下图所示。

(1)初始化参数:先初始化男生身高的正态分布的参数:如均值=1.65,方差=0.15
(2)计算每一个人更可能属于男生分布或者女生分布;
(3)通过分为男生的n个人来重新估计男生身高分布的参数(最大似然估计),女生分布也按照相同的方式估计出来,更新分布。
(4)这时候两个分布的概率也变了,然后重复步骤(1)至(3),直到参数不发生变化为止。















 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









